-
 Building Snipd: The AI Podcast App for Learning
Building Snipd: The AI Podcast App for LearningFrom 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2025-03-14 21:38
We are working with Amplify on the 2025 State of AI Engineering Survey to be presented at the AIE World’s Fair in SF! Join the survey to shape the future of AI Eng!We first met Snipd (affiliate link! we get a free month, you get a free month. but this is not a sponsored pod, we’ve never done one) over a year ago, and were immediately impressed by the design, but were doubtful about the behavior of snipping as the title behavior:Podcast apps are enormously sticky - Spotify spent almost $1b in podcast acquisitions and exclusive content just to get an 8% bump in market share among normies.However, after a disappointing Overcast 2.0 rewrite with no AI features in the last 3 years, I finally bit the bullet and switched to Snipd. It’s 2025, your podcast app should be able to let you search transcripts of your podcasts. Snipd is the best implementation of this so far.And yet they keep shipping:What impressed us wasn’t just how this tiny team of 4 was able to bootstrap a consumer AI app against massive titans and do so well; but also how seriously they think about learning through podcasts and improving retention of knowledge over time, aka “Duolingo for podcasts”. As an educational AI podcast, that’s a mission we can get behind.Full Video PodFind us on YouTube! This was the first pod we’ve ever shot outdoors!Show Notes* How does Shazam work?* Flutter/FlutterFlow* wav2vec paper* Perplexity Online LLM* Google Search Grounding* Comparing Snipd transcription with our Bee episode* NIPS 2017 Flo Rida* Gustav Söderström - Background AudioTimestamps* [00:00:03] Takeaways from AI Engineer NYC* [00:00:17] Weather in New York.* [00:00:26] Swyx and Snipd.* [00:01:01] Kevin's AI summit experience.* [00:01:31] Zurich and AI.* [00:03:25] SigLIP authors join OpenAI.* [00:03:39] Zurich is very costly.* [00:04:06] The Snipd origin story.* [00:05:24] Introduction to machine learning.* [00:09:28] Snipd and user knowledge extraction.* [00:13:48] App's tech stack, Flutter, Python.* [00:15:11] How speakers are identified.* [00:18:29] The concept of "backgroundable" video.* [00:29:05] Voice cloning technology.* [00:31:03] Using AI agents.* [00:34:32] Snipd's future is multi-modal AI.* [00:36:37] Snipd and existing user behaviour.* [00:42:10] The app, summary, and timestamps.* [00:55:25] The future of AI and podcasting.* [1:14:55] Voice AITranscriptswyx [00:00:03]: Hey, I'm here in New York with Kevin Ben-Smith of Snipd. Welcome.Kevin [00:00:07]: Hi. Hi. Amazing to be here.swyx [00:00:09]: Yeah. This is our first ever, I think, outdoors podcast recording.Kevin [00:00:14]: It's quite a location for the first time, I have to say.swyx [00:00:18]: I was actually unsure because, you know, it's cold. It's like, I checked the temperature. It's like kind of one degree Celsius, but it's not that bad with the sun. No, it's quite nice. Yeah. Especially with our beautiful tea. With the tea. Yeah. Perfect. We're going to talk about Snips. I'm a Snips user. I'm a Snips user. I had to basically, you know, apart from Twitter, it's like the number one use app on my phone. Nice. When I wake up in the morning, I open Snips and I, you know, see what's new. And I think in terms of time spent or usage on my phone, I think it's number one or number two. Nice. Nice. So I really had to talk about it also because I think people interested in AI want to think about like, how can we, we're an AI podcast, we have to talk about the AI podcast app. But before we get there, we just finished. We just finished the AI Engineer Summit and you came for the two days. How was it?Kevin [00:01:07]: It was quite incredible. I mean, for me, the most valuable was just being in the same room with like-minded people who are building the future and who are seeing the future. You know, especially when it comes to AI agents, it's so often I have conversations with friends who are not in the AI world. And it's like so quickly it happens that you, it sounds like you're talking in science fiction. And it's just crazy talk. It was, you know, it's so refreshing to talk with so many other people who already see these things and yeah, be inspired then by them and not always feel like, like, okay, I think I'm just crazy. And like, this will never happen. It really is happening. And for me, it was very valuable. So day two, more relevant, more relevant for you than day one. Yeah. Day two. So day two was the engineering track. Yeah. That was definitely the most valuable for me. Like also as a producer. Practitioner myself, especially there were one or two talks that had to do with voice AI and AI agents with voice. Okay. So that was quite fascinating. Also spoke with the speakers afterwards. Yeah. And yeah, they were also very open and, and, you know, this, this sharing attitudes that's, I think in general, quite prevalent in the AI community. I also learned a lot, like really practical things that I can now take away with me. Yeah.swyx [00:02:25]: I mean, on my side, I, I think I watched only like half of the talks. Cause I was running around and I think people saw me like towards the end, I was kind of collapsing. I was on the floor, like, uh, towards the end because I, I needed to get, to get a rest, but yeah, I'm excited to watch the voice AI talks myself.Kevin [00:02:43]: Yeah. Yeah. Do that. And I mean, from my side, thanks a lot for organizing this conference for bringing everyone together. Do you have anything like this in Switzerland? The short answer is no. Um, I mean, I have to say the AI community in, especially Zurich, where. Yeah. Where we're, where we're based. Yeah. It is quite good. And it's growing, uh, especially driven by ETH, the, the technical university there and all of the big companies, they have AI teams there. Google, like Google has the biggest tech hub outside of the U S in Zurich. Yeah. Facebook is doing a lot in reality labs. Uh, Apple has a secret AI team, open AI and then SwapBit just announced that they're coming to Zurich. Yeah. Um, so there's a lot happening. Yeah.swyx [00:03:23]: So, yeah, uh, I think the most recent notable move, I think the entire vision team from Google. Uh, Lucas buyer, um, and, and all the other authors of Siglip left Google to join open AI, which I thought was like, it's like a big move for a whole team to move all at once at the same time. So I've been to Zurich and it just feels expensive. Like it's a great city. Yeah. It's great university, but I don't see it as like a business hub. Is it a business hub? I guess it is. Right.Kevin [00:03:51]: Like it's kind of, well, historically it's, uh, it's a finance hub, finance hub. Yeah. I mean, there are some, some large banks there, right? Especially UBS, uh, the, the largest wealth manager in the world, but it's really becoming more of a tech hub now with all of the big, uh, tech companies there.swyx [00:04:08]: I guess. Yeah. Yeah. And, but we, and research wise, it's all ETH. Yeah. There's some other things. Yeah. Yeah. Yeah.Kevin [00:04:13]: It's all driven by ETH. And then, uh, it's sister university EPFL, which is in Lausanne. Okay. Um, which they're also doing a lot, but, uh, it's, it's, it's really ETH. Uh, and otherwise, no, I mean, it's a beautiful, really beautiful city. I can recommend. To anyone. To come, uh, visit Zurich, uh, uh, let me know, happy to show you around and of course, you know, you, you have the nature so close, you have the mountains so close, you have so, so beautiful lakes. Yeah. Um, I think that's what makes it such a livable city. Yeah.swyx [00:04:42]: Um, and the cost is not, it's not cheap, but I mean, we're in New York city right now and, uh, I don't know, I paid $8 for a coffee this morning, so, uh, the coffee is cheaper in Zurich than the New York city. Okay. Okay. Let's talk about Snipt. What is Snipt and, you know, then we'll talk about your origin story, but I just, let's, let's get a crisp, what is Snipt? Yeah.Kevin [00:05:03]: I always see two definitions of Snipt, so I'll give you one really simple, straightforward one, and then a second more nuanced, um, which I think will be valuable for the rest of our conversation. So the most simple one is just to say, look, we're an AI powered podcast app. So if you listen to podcasts, we're now providing this AI enhanced experience. But if you look at the more nuanced, uh, podcast. Uh, perspective, it's actually, we, we've have a very big focus on people who like your audience who listened to podcasts to learn something new. Like your audience, you want, they want to learn about AI, what's happening, what's, what's, what's the latest research, what's going on. And we want to provide a, a spoken audio platform where you can do that most effectively. And AI is basically the way that we can achieve that. Yeah.swyx [00:05:53]: Means to an end. Yeah, exactly. When you started. Was it always meant to be AI or is it, was it more about the social sharing?Kevin [00:05:59]: So the first version that we ever released was like three and a half years ago. Okay. Yeah. So this was before ChatGPT. Before Whisper. Yeah. Before Whisper. Yeah. So I think a lot of the features that we now have in the app, they weren't really possible yet back then. But we already from the beginning, we always had the focus on knowledge. That's the reason why, you know, we in our team, why we listen to podcasts, but we did have a bit of a different approach. Like the idea in the very beginning was, so the name is Snips and you can create these, what we call Snips, which is basically a small snippet, like a clip from a, from a podcast. And we did envision sort of like a, like a social TikTok platform where some people would listen to full episodes and they would snip certain, like the best parts of it. And they would post that in a feed and other users would consume this feed of Snips. And use that as a discovery tool or just as a means to an end. And yeah, so you would have both people who create Snips and people who listen to Snips. So our big hypothesis in the beginning was, you know, it will be easy to get people to listen to these Snips, but super difficult to actually get them to create them. So we focused a lot of, a lot of our effort on making it as seamless and easy as possible to create a Snip. Yeah.swyx [00:07:17]: It's similar to TikTok. You need CapCut for there to be videos on TikTok. Exactly.Kevin [00:07:23]: And so for, for Snips, basically whenever you hear an amazing insight, a great moment, you can just triple tap your headphones. And our AI actually then saves the moment that you just listened to and summarizes it to create a note. And this is then basically a Snip. So yeah, we built, we built all of this, launched it. And what we found out was basically the exact opposite. So we saw that people use the Snips to discover podcasts, but they really, you know, they don't. You know, really love listening to long form podcasts, but they were creating Snips like crazy. And this was, this was definitely one of these aha moments when we realized like, hey, we should be really doubling down on the knowledge of learning of, yeah, helping you learn most effectively and helping you capture the knowledge that you listen to and actually do something with it. Because this is in general, you know, we, we live in this world where there's so much content and we consume and consume and consume. And it's so easy to just at the end of the podcast. You just start listening to the next podcast. And five minutes later, you've forgotten everything. 90%, 99% of what you've actually just learned. Yeah.swyx [00:08:31]: You don't know this, but, and most people don't know this, but this is my fourth podcast. My third podcast was a personal mixtape podcast where I Snipped manually sections of podcasts that I liked and added my own commentary on top of them and published them as small episodes. Nice. So those would be maybe five to 10 minute Snips. Yeah. And then I added something that I thought was a good story or like a good insight. And then I added my own commentary and published it as a separate podcast. It's cool. Is that still live? It's still live, but it's not active, but you can go back and find it. If you're, if, if you're curious enough, you'll see it. Nice. Yeah. You have to show me later. It was so manual because basically what my process would be, I hear something interesting. I note down the timestamp and I note down the URL of the podcast. I used to use Overcast. So it would just link to the Overcast page. And then. Put in my note taking app, go home. Whenever I feel like publishing, I will take one of those things and then download the MP3, clip out the MP3 and record my intro, outro and then publish it as a, as a podcast. But now Snips, I mean, I can just kind of double click or triple tap.Kevin [00:09:39]: I mean, those are very similar stories to what we hear from our users. You know, it's, it's normal that you're doing, you're doing something else while you're listening to a podcast. Yeah. A lot of our users, they're driving, they're working out, walking their dog. So in those moments when you hear something amazing, it's difficult to just write them down or, you know, you have to take out your phone. Some people take a screenshot, write down a timestamp, and then later on you have to go back and try to find it again. Of course you can't find it anymore because there's no search. There's no command F. And, um, these, these were all of the issues that, that, that we encountered also ourselves as users. And given that our background was in AI, we realized like, wait, hey, this is. This should not be the case. Like podcast apps today, they're still, they're basically repurposed music players, but we actually look at podcasts as one of the largest sources of knowledge in the world. And once you have that different angle of looking at it together with everything that AI is now enabling, you realize like, hey, this is not the way that we, that podcast apps should be. Yeah.swyx [00:10:41]: Yeah. I agree. You mentioned something that you said your background is in AI. Well, first of all, who's the team and what do you mean your background is in AI?Kevin [00:10:48]: Those are two very different things. I'm going to ask some questions. Yeah. Um, maybe starting with, with my backstory. Yeah. My backstory actually goes back, like, let's say 12 years ago or something like that. I moved to Zurich to study at ETH and actually I studied something completely different. I studied mathematics and economics basically with this specialization for quant finance. Same. Okay. Wow. All right. So yeah. And then as you know, all of these mathematical models for, um, asset pricing, derivative pricing, quantitative trading. And for me, the thing that, that fascinates me the most was the mathematical modeling behind it. Uh, mathematics, uh, statistics, but I was never really that passionate about the finance side of things.swyx [00:11:32]: Oh really? Oh, okay. Yeah. I mean, we're different there.Kevin [00:11:36]: I mean, one just, let's say symptom that I noticed now, like, like looking back during that time. Yeah. I think I never read an academic paper about the subject in my free time. And then it was towards the end of my studies. I was already working for a big bank. One of my best friends, he comes to me and says, Hey, I just took this course. You have to, you have to do this. You have to take this lecture. Okay. And I'm like, what, what, what is it about? It's called machine learning and I'm like, what, what, what kind of stupid name is that? Uh, so you sent me the slides and like over a weekend I went through all of the slides and I just, I just knew like freaking hell. Like this is it. I'm, I'm in love. Wow. Yeah. Okay. And that was then over the course of the next, I think like 12 months, I just really got into it. Started reading all about it, like reading blog posts, starting building my own models.swyx [00:12:26]: Was this course by a famous person, famous university? Was it like the Andrew Wayne Coursera thing? No.Kevin [00:12:31]: So this was a ETH course. So a professor at ETH. Did he teach in English by the way? Yeah. Okay.swyx [00:12:37]: So these slides are somewhere available. Yeah. Definitely. I mean, now they're quite outdated. Yeah. Sure. Well, I think, you know, reflecting on the finance thing for a bit. So I, I was, used to be a trader, uh, sell side and buy side. I was options trader first and then I was more like a quantitative hedge fund analyst. We never really use machine learning. It was more like a little bit of statistical modeling, but really like you, you fit, you know, your regression.Kevin [00:13:03]: No, I mean, that's, that's what it is. And, uh, or you, you solve partial differential equations and have then numerical methods to, to, to solve these. That's, that's for you. That's your degree. And that's, that's not really what you do at work. Right. Unless, well, I don't know what you do at work. In my job. No, no, we weren't solving the partial differential. Yeah.swyx [00:13:18]: You learn all this in school and then you don't use it.Kevin [00:13:20]: I mean, we, we, well, let's put it like that. Um, in some things, yeah, I mean, I did code algorithms that would do it, but it was basically like, it was the most basic algorithms and then you just like slightly improve them a little bit. Like you just tweak them here and there. Yeah. It wasn't like starting from scratch, like, Oh, here's this new partial differential equation. How do we know?swyx [00:13:43]: Yeah. Yeah. I mean, that's, that's real life, right? Most, most of it's kind of boring or you're, you're using established things because they're established because, uh, they tackle the most important topics. Um, yeah. Portfolio management was more interesting for me. Um, and, uh, we, we were sort of the first to combine like social data with, with quantitative trading. And I think, uh, I think now it's very common, but, um, yeah. Anyway, then you, you went, you went deep on machine learning and then what? You quit your job? Yeah. Yeah. Wow.Kevin [00:14:12]: I quit my job because, uh, um, I mean, I started using it at the bank as well. Like try, like, you know, I like desperately tried to find any kind of excuse to like use it here or there, but it just was clear to me, like, no, if I want to do this, um, like I just have to like make a real cut. So I quit my job and joined an early stage, uh, tech startup in Zurich where then built up the AI team over five years. Wow. Yeah. So yeah, we built various machine learning, uh, things for, for banks from like models for, for sales teams to identify which clients like which product to sell to them and with what reasons all the way to, we did a lot, a lot with bank transactions. One of the actually most fun projects for me was we had an, an NLP model that would take the booking text of a transaction, like a credit card transaction and pretty fired. Yeah. Because it had all of these, you know, like numbers in there and abbreviations and whatnot. And sometimes you look at it like, what, what is this? And it was just, you know, it would just change it to, I don't know, CVS. Yeah.swyx [00:15:15]: Yeah. But I mean, would you have hallucinations?Kevin [00:15:17]: No, no, no. The way that everything was set up, it wasn't like, it wasn't yet fully end to end generative, uh, neural network as what you would use today. Okay.swyx [00:15:30]: Awesome. And then when did you go like full time on Snips? Yeah.Kevin [00:15:33]: So basically that was, that was afterwards. I mean, how that started was the friend of mine who got me into machine learning, uh, him and I, uh, like he also got me interested into startups. He's had a big impact on my life. And the two of us were just a jam on, on like ideas for startups every now and then. And his background was also in AI data science. And we had a couple of ideas, but given that we were working full times, we were thinking about, uh, so we participated in Hack Zurich. That's, uh, Europe's biggest hackathon, um, or at least was at the time. And we said, Hey, this is just a weekend. Let's just try out an idea, like hack something together and see how it works. And the idea was that we'd be able to search through podcast episodes, like within a podcast. Yeah. So we did that. Long story short, uh, we managed to do it like to build something that we realized, Hey, this actually works. You can, you can find things again in podcasts. We had like a natural language search and we pitched it on stage. And we actually won the hackathon, which was cool. I mean, we, we also, I think we had a good, um, like a good, good pitch or a good example. So we, we used the famous Joe Rogan episode with Elon Musk where Elon Musk smokes a joint. Okay. Um, it's like a two and a half hour episode. So we were on stage and then we just searched for like smoking weed and it would find that exact moment. It will play it. And it just like, come on with Elon Musk, just like smoking. Oh, so it was video as well? No, it was actually completely based on audio. But we did have the video for the presentation. Yeah. Which had a, had of course an amazing effect. Yeah. Like this gave us a lot of activation energy, but it wasn't actually about winning the hackathon. Yeah. But the interesting thing that happened was after we pitched on stage, several of the other participants, like a lot of them came up to us and started saying like, Hey, can I use this? Like I have this issue. And like some also came up and told us about other problems that they have, like very adjacent to this with a podcast. Where's like, like this. Like, could, could I use this for that as well? And that was basically the, the moment where I realized, Hey, it's actually not just us who are having these issues with, with podcasts and getting to the, making the most out of this knowledge. Yeah. The other people. Yeah. That was now, I guess like four years ago or something like that. And then, yeah, we decided to quit our jobs and start, start this whole snip thing. Yeah. How big is the team now? We're just four people. Yeah. Just four people. Yeah. Like four. We're all technical. Yeah. Basically two on the, the backend side. So one of my co-founders is this person who got me into machine learning and startups. And we won the hackathon together. So we have two people for the backend side with the AI and all of the other backend things. And two for the front end side, building the app.swyx [00:18:18]: Which is mostly Android and iOS. Yeah.Kevin [00:18:21]: It's iOS and Android. We also have a watch app for, for Apple, but yeah, it's mostly iOS. Yeah.swyx [00:18:27]: The watch thing, it was very funny because in the, in the Latent Space discord, you know, most of us have been slowly adopting snips. You came to me like a year ago and you introduced snip to me. I was like, I don't know. I'm, you know, I'm very sticky to overcast and then slowly we switch. Why watch?Kevin [00:18:43]: So it goes back to a lot of our users, they do something else while, while listening to a podcast, right? Yeah. And one of the, us giving them the ability to then capture this knowledge, even though they're doing something else at the same time is one of the killer features. Yeah. Maybe I can actually, maybe at some point I should maybe give a bit more of an overview of what the, all of the features that we have. Sure. So this is one of the killer features and for one big use case that people use this for is for running. Yeah. So if you're a big runner, a big jogger or cycling, like really, really cycling competitively and a lot of the people, they don't want to take their phone with them when they go running. So you load everything onto the watch. So you can download episodes. I mean, if you, if you have an Apple watch that has internet access, like with a SIM card, you can also directly stream. That's also possible. Yeah. So of course it's a, it's basically very limited to just listening and snipping. And then you can see all of your snips later on your phone. Let me tell you this error I just got.swyx [00:19:47]: Error playing episode. Substack, the host of this podcast, does not allow this podcast to be played on an Apple watch. Yeah.Kevin [00:19:52]: That's a very beautiful thing. So we found out that all of the podcasts hosted on Substack, you cannot play them on an Apple watch. Why is this restriction? What? Like, don't ask me. We try to reach out to Substack. We try to reach out to some of the bigger podcasters who are hosting the podcast on Substack to also let them know. Substack doesn't seem to care. This is not specific to our app. You can also check out the Apple podcast app. Yeah. It's the same problem. It's just that we actually have identified it. And we tell the user what's going on.swyx [00:20:25]: I would say we host our podcast on Substack, but they're not very serious about their podcasting tools. I've told them before, I've been very upfront with them. So I don't feel like I'm shitting on them in any way. And it's kind of sad because otherwise it's a perfect creative platform. But the way that they treat podcasting as an afterthought, I think it's really disappointing.Kevin [00:20:45]: Maybe given that you mentioned all these features, maybe I can give a bit of a better overview of the features that we have. Let's do that. Let's do that. So I think we're mostly in our minds. Maybe for some of the listeners.swyx [00:20:55]: I mean, I'll tell you my version. Yeah. They can correct me, right? So first of all, I think the main job is for it to be a podcast listening app. It should be basically a complete superset of what you normally get on Overcast or Apple Podcasts or anything like that. You pull your show list from ListenNotes. How do you find shows? You've got to type in anything and you find them, right?Kevin [00:21:18]: Yeah. We have a search engine that is powered by ListenNotes. Yeah. But I mean, in the meantime, we have a huge database of like 99% of all podcasts out there ourselves. Yeah.swyx [00:21:27]: What I noticed, the default experience is you do not auto-download shows. And that's one very big difference for you guys versus other apps, where like, you know, if I'm subscribed to a thing, it auto-downloads and I already have the MP3 downloaded overnight. For me, I have to actively put it onto my queue, then it auto-downloads. And actually, I initially didn't like that. I think I maybe told you that I was like, oh, it's like a feature that I don't like. Like, because it means that I have to choose to listen to it in order to download and not to... It's like opt-in. There's a difference between opt-in and opt-out. So I opt-in to every episode that I listen to. And then, like, you know, you open it and depends on whether or not you have the AI stuff enabled. But the default experience is no AI stuff enabled. You can listen to it. You can see the snips, the number of snips and where people snip during the episode, which roughly correlates to interest level. And obviously, you can snip there. I think that's the default experience. I think snipping is really cool. Like, I use it to share a lot on Discord. I think we have tons and tons of just people sharing snips and stuff. Tweeting stuff is also like a nice, pleasant experience. But like the real features come when you actually turn on the AI stuff. And so the reason I got snipped, because I got fed up with Overcast not implementing any AI features at all. Instead, they spent two years rewriting their app to be a little bit faster. And I'm like, like, it's 2025. I should have a podcast that has transcripts that I can search. Very, very basic thing. Overcast will basically never have it.Kevin [00:22:49]: Yeah, I think that was a good, like, basic overview. Maybe I can add a bit to it with the AI features that we have. So one thing that we do every time a new podcast comes out, we transcribe the episode. We do speaker diarization. We identify the speaker names. Each guest, we extract a mini bio of the guest, try to find a picture of the guest online, add it. We break the podcast down into chapters, as in AI generated chapters. That one. That one's very handy. With a quick description per title and quick description per each chapter. We identify all books that get mentioned on a podcast. You can tell I don't use that one. It depends on the podcast. There are some podcasts where the guests often recommend like an amazing book. So later on, you can you can find that again.swyx [00:23:42]: So you literally search for the word book or I just read blah, blah, blah.Kevin [00:23:46]: No, I mean, it's all LLM based. Yeah. So basically, we have we have an LLM that goes through the entire transcript and identifies if a user mentions a book, then we use perplexity API together with various other LLM orchestration to go out there on the Internet, find everything that there is to know about the book, find the cover, find who or what the author is, get a quick description of it for the author. We then check on which other episodes the author appeared on.swyx [00:24:15]: Yeah, that is killer.Kevin [00:24:17]: Because that for me, if. If there's an interesting book, the first thing I do is I actually listen to a podcast episode with a with a writer because he usually gives a really great overview already on a podcast.swyx [00:24:28]: Sometimes the podcast is with the person as a guest. Sometimes his podcast is about the person without him there. Do you pick up both?Kevin [00:24:37]: So, yes, we pick up both in like our latest models. But actually what we show you in the app, the goal is to currently only show you the guest to separate that. In the future, we want to show the other things more.swyx [00:24:47]: For what it's worth, I don't mind. Yeah, I don't think like if I like if I like somebody, I'll just learn about them regardless of whether they're there or not.Kevin [00:24:55]: Yeah, I mean, yes and no. We we we have seen there are some personalities where this can break down. So, for example, the first version that we released with this feature, it picked up much more often a person, even if it was not a guest. Yeah. For example, the best examples for me is Sam Altman and Elon Musk. Like they're just mentioned on every second podcast and it has like they're not on there. And if you're interested in it, you can go to Elon Musk. And actually like learning from them. Yeah, I see. And yeah, we updated our our algorithms, improved that a lot. And now it's gotten much better to only pick it up if they're a guest. And yeah, so this this is maybe to come back to the features, two more important features like we have the ability to chat with an episode. Yes. Of course, you can do the old style of searching through a transcript with a keyword search. But I think for me, this is this is how you used to do search and extracting knowledge in the in the past. Old school. And the A.I. Web. Way is is basically an LLM. So you can ask the LLM, hey, when do they talk about topic X? If you're interested in only a certain part of the episode, you can ask them for four to give a quick overview of the episode. Key takeaways afterwards also to create a note for you. So this is really like very open, open ended. And yeah. And then finally, the snipping feature that we mentioned just to reiterate. Yeah. I mean, here the the feature is that whenever you hear an amazing idea, you can trip. It's up your headphones or click a button in the app and the A.I. summarizes the insight you just heard and saves that together with the original transcript and audio in your knowledge library. I also noticed that you you skip dynamic content. So dynamic content, we do not skip it automatically. Oh, sorry. You detect. But we detect it. Yeah. I mean, that's one of the thing that most people don't don't actually know that like the way that ads get inserted into podcasts or into most podcasts is actually that every time you listen. To a podcast, you actually get access to a different audio file and on the server, a different ad is inserted into the MP3 file automatically. Yeah. Based on IP. Exactly. And that's what that means is if we transcribe an episode and have a transcript with timestamps like words, word specific timestamps, if you suddenly get a different audio file, like the whole time says I messed up and that's like a huge issue. And for that, we actually had to build another algorithm that would dynamically on the floor. I re sync the audio that you're listening to the transcript that we have. Yeah. Which is a fascinating problem in and of itself.swyx [00:27:24]: You sync by matching up the sound waves? Or like, or do you sync by matching up words like you basically do partial transcription?Kevin [00:27:33]: We are not matching up words. It's happening on the basically a bytes level matching. Yeah. Okay.swyx [00:27:40]: It relies on this. It relies on the exact match at some point.Kevin [00:27:46]: So it's actually. We're actually not doing exact matches, but we're doing fuzzy matches to identify the moment. It's basically, we basically built Shazam for podcasts. Just as a little side project to solve this issue.swyx [00:28:02]: Actually, fun fact, apparently the Shazam algorithm is open. They published the paper, it's talked about it. I haven't really dived into the paper. I thought it was kind of interesting that basically no one else has built Shazam.Kevin [00:28:16]: Yeah, I mean, well, the one thing is the algorithm. If you now talk about Shazam, the other thing is also having the database behind it and having the user mindset that if they have this problem, they come to you, right?swyx [00:28:29]: Yeah, I'm very interested in the tech stack. There's a big data pipeline. Could you share what is the tech stack?Kevin [00:28:35]: What are the most interesting or challenging pieces of it? So the general tech stack is our entire backend is, or 90% of our backend is written in Python. Okay. Hosting everything on Google Cloud Platform. And our front end is written with, well, we're using the Flutter framework. So it's written in Dart and then compiled natively. So we have one code base that handles both Android and iOS. You think that was a good decision? It's something that a lot of people are exploring. So up until now, yes. Okay. Look, it has its pros and cons. Some of the, you know, for example, earlier, I mentioned we have a Apple Watch app. Yeah. I mean, there's no Flutter for that, right? So that you build native. And then of course you have to sort of like sync these things together. I mean, I'm not the front end engineer, so I'm not just relaying this information, but our front end engineers are very happy with it. It's enabled us to be quite fast and be on both platforms from the very beginning. And when I talk with people and they hear that we are using Flutter, usually they think like, ah, it's not performant. It's super junk, janky and everything. And then they use it. They use our app and they're always super surprised. Or if they've already used our app, I couldn't tell them. They're like, what? Yeah. Um, so there is actually a lot that you can do with it.swyx [00:29:51]: The danger, the concern, there's a few concerns, right? One, it's Google. So when were they, when are they going to abandon it? Two, you know, they're optimized for Android first. So iOS is like a second, second thought, or like you can feel that it is not a native iOS app. Uh, but you guys put a lot of care into it. And then maybe three, from my point of view, JavaScript, as a JavaScript guy, React Native was supposed to be there. And I think that it hasn't really fulfilled that dream. Um, maybe Expo is trying to do that, but, um, again, it is not, does not feel as productive as Flutter. And I've, I spent a week on Flutter and dot, and I'm an investor in Flutter flow, which is the local, uh, Flutter, Flutter startup. That's doing very, very well. I think a lot of people are still Flutter skeptics. Yeah. Wait. So are you moving away from Flutter?Kevin [00:30:41]: I don't know. We don't have plans to do that. Yeah.swyx [00:30:43]: You're just saying about that. What? Yeah. Watch out. Okay. Let's go back to the stack.Kevin [00:30:47]: You know, that was just to give you a bit of an overview. I think the more interesting things are, of course, on the AI side. So we, like, as I mentioned earlier, when we started out, it was before chat GPT for the chat GPT moment before there was the GPT 3.5 turbo, uh, API. So in the beginning, we actually were running everything ourselves, open source models, try to fine tune them. They worked. There was us, but let's, let's be honest. They weren't. What was the sort of? Before Whisper, the transcription. Yeah, we were using wave to work like, um, there was a Google one, right? No, it was a Facebook, Facebook one. That was actually one of the papers. Like when that came out for me, that was one of the reasons why I said we, we should try something to start a startup in the audio space. For me, it was a bit like before that I had been following the NLP space, uh, quite closely. And as, as I mentioned earlier, we, we did some stuff at the startup as well, that I was working up. But before, and wave to work was the first paper that I had at least seen where the whole transformer architecture moved over to audio and bit more general way of saying it is like, it was the first time that I saw the transformer architecture being applied to continuous data instead of discrete tokens. Okay. And it worked amazingly. Ah, and like the transformer architecture plus self-supervised learning, like these two things moved over. And then for me, it was like, Hey, this is now going to take off similarly. It's the text space has taken off. And with these two things in place, even if some features that we want to build are not possible yet, they will be possible in the near term, uh, with this, uh, trajectory. So that was a little side, side note. No, it's in the meantime. Yeah. We're using whisper. We're still hosting some of the models ourselves. So for example, the whole transcription speaker diarization pipeline, uh,swyx [00:32:38]: You need it to be as cheap as possible.Kevin [00:32:40]: Yeah, exactly. I mean, we're doing this at scale where we have a lot of audio.swyx [00:32:44]: We're what numbers can you disclose? Like what, what are just to give people an idea because it's a lot. So we have more than a million podcasts that we've already processed when you say a million. So processing is basically, you have some kind of list of podcasts that you will auto process and others where a paying pay member can choose to press the button and transcribe it. Right. Is that the rough idea? Yeah, exactly.Kevin [00:33:08]: Yeah. And if, when you press that button or we also transcribe it. Yeah. So first we do the, we do the transcription. We do the. The, the speaker diarization. So basically you identify speech blocks that belong to the same speaker. This is then all orchestrated within, within LLM to identify which speech speech block belongs to which speaker together with, you know, we identify, as I mentioned earlier, we identify the guest name and the bio. So all of that comes together with an LLM to actually then assign assigned speaker names to, to each block. Yeah. And then most of the rest of the, the pipeline we've now used, we've now migrated to LLM. So we use mainly open AI, Google models, so the Gemini models and the open AI models, and we use some perplexity basically for those things where we need, where we need web search. Yeah. That's something I'm still hoping, especially open AI will also provide us an API. Oh, why? Well, basically for us as a consumer, the more providers there are.swyx [00:34:07]: The more downtime.Kevin [00:34:08]: The more competition and it will lead to better, better results. And, um, lower costs over time. I don't, I don't see perplexity as expensive. If you use the web search, the price is like $5 per a thousand queries. Okay. Which is affordable. But, uh, if you compare that to just a normal LLM call, um, it's, it's, uh, much more expensive. Have you tried Exa? We've, uh, looked into it, but we haven't really tried it. Um, I mean, we, we started with perplexity and, uh, it works, it works well. And if I remember. Correctly, Exa is also a bit more expensive.swyx [00:34:45]: I don't know. I don't know. They seem to focus on the search thing as a search API, whereas perplexity, maybe more consumer-y business that is higher, higher margin. Like I'll put it like perplexity is trying to be a product, Exa is trying to be infrastructure. Yeah. So that, that'll be my distinction there. And then the other thing I will mention is Google has a search grounding feature. Yeah. Which you, which you might want. Yeah.Kevin [00:35:07]: Yeah. We've, uh, we've also tried that out. Um, not as good. So we, we didn't, we didn't go into. Too much detail in like really comparing it, like quality wise, because we actually already had the perplexity one and it, and it's, and it's working. Yeah. Um, I think also there, the price is actually higher than perplexity. Yeah. Really? Yeah.swyx [00:35:26]: Google should cut their prices.Kevin [00:35:29]: Maybe it was the same price. I don't want to say something incorrect, but it wasn't cheaper. It wasn't like compelling. And then, then there was no reason to switch. So, I mean, maybe like in general, like for us, given that we do work with a lot of content, price is actually something that we do look at. Like for us, it's not just about taking the best model for every task, but it's really getting the best, like identifying what kind of intelligence level you need and then getting the best price for that to be able to really scale this and, and provide us, um, yeah, let our users use these features with as many podcasts as possible. Yeah.swyx [00:36:03]: I wanted to double, double click on diarization. Yeah. Uh, it's something that I don't think people do very well. So you know, I'm, I'm a, I'm a B user. I don't have it right now. And, and they were supposed to speak, but they dropped out last minute. Um, but, uh, we've had them on the podcast before and it's not great yet. Do you use just PI Anode, the default stuff, or do you find any tricks for diarization?Kevin [00:36:27]: So we do use the, the open source packages, but we have tweaked it a bit here and there. For example, if you mentioned the BAI guys, I actually listened to the podcast episode was super nice. Thank you. And when you started talking about speaker diarization, and I just have to think about, uh, I don't know.Kevin [00:36:49]: Is it possible? I don't know. I don't know. F**k this. Yeah, no, I don't know.Kevin [00:36:55]: Yeah. We are the best. This is a.swyx [00:37:07]: I don't know. This is the best. I don't know. This is the best. Yeah. Yeah. Yeah. You're doing good.Kevin [00:37:12]: So, so yeah. This is great. This is good. Yeah. No, so that of course helps us. Another thing that helps us is that we know certain structural aspects of the podcast. For example, how often does someone speak? Like if someone, like let's say there's a one hour episode and someone speaks for 30 seconds, that person is most probably not the guest and not the host. It's probably some ad, like some speaker from an ad. So we have like certain of these heuristics that we can use and we leverage to improve things. And in the past, we've also changed the clustering algorithm. So basically how a lot of the speaker diarization works is you basically create an embedding for the speech that's happening. And then you try to somehow cluster these embeddings and then find out this is all one speaker. This is all another speaker. And there we've also tweaked a couple of things where we again used heuristics that we could apply from knowing how podcasts function. And that's also actually why I was feeling so much with the BAI guys, because like all of these heuristics, like for them, it's probably almost impossible to use any heuristics because it can just be any situation, anything.Kevin [00:38:34]: So that's one thing that we do. Yeah, another thing is that we actually combine it with LLM. So the transcript, LLMs and the speaker diarization, like bringing all of these together to recalibrate some of the switching points. Like when does the speaker stop? When does the next one start?swyx [00:38:51]: The LLMs can add errors as well. You know, I wouldn't feel safe using them to be so precise.Kevin [00:38:58]: I mean, at the end of the day, like also just to not give a wrong impression, like the speaker diarization is also not perfect that we're doing, right? I basically don't really notice it.swyx [00:39:08]: Like I use it for search.Kevin [00:39:09]: Yeah, it's not perfect yet, but it's gotten quite good. Like, especially if you compare, if you look at some of the, like if you take a latest episode and you compare it to an episode that came out a year ago, we've improved it quite a bit.swyx [00:39:23]: Well, it's beautifully presented. Oh, I love that I can click on the transcript and it goes to the timestamp. So simple, but you know, it should exist. Yeah, I agree. I agree. So this, I'm loading a two hour episode of Detect Me Right Home, where there's a lot of different guests calling in and you've identified the guest name. And yeah, so these are all LLM based. Yeah, it's really nice.Kevin [00:39:49]: Yeah, like the speaker names.swyx [00:39:50]: I would say that, you know, obviously I'm a power user of all these tools. You have done a better job than Descript. Okay, wow. Descript is so much funding. They had their open AI invested in them and they still suck. So I don't know, like, you know, keep going. You're doing great. Yeah, thanks. Thanks.Kevin [00:40:12]: I mean, I would, I would say that, especially for anyone listening who's interested in building a consumer app with AI, I think the, like, especially if your background is in AI and you love working with AI and doing all of that, I think the most important thing is just to keep reminding yourself of what's actually the job to be done here. Like, what does actually the consumer want? Like, for example, you now were just delighted by the ability to click on this word and it jumps there. Yeah. Like, this is not, this is not rocket science. This is, like, you don't have to be, like, I don't know, Android Kapathi to come up with that and build that, right? And I think that's, that's something that's super important to keep in mind.swyx [00:40:52]: Yeah, yeah. Amazing. I mean, there's so many features, right? It's, it's so packed. There's quotes that you pick up. There's summarization. Oh, by the way, I'm going to use this as my official feature request. I want to customize what, how it's summarized. I want to, I want to have a custom prompt. Yeah. Because your summarization is good, but, you know, I have different preferences, right? Like, you know.Kevin [00:41:14]: So one thing that you can already do today, I completely get your feature request. And I think it just.swyx [00:41:18]: I'm sure people have asked it.Kevin [00:41:19]: I mean, maybe just in general as a, as a, how I see the future, you know, like in the future, I think all, everything will be personalized. Yeah, yeah. Like, not, this is not specific to us. Yeah. And today we're still in a, in a phase where the cost of LLMs, at least if you're working with, like, such long context windows. As us, I mean, there's a lot of tokens in, if you take an entire podcast, so you still have to take that cost into consideration. So if for every single user, we regenerate it entirely, it gets expensive. But in the future, this, you know, cost will continue to go down and then it will just be personalized. So that being said, you can already today, if you go to the player screen. Okay. And open up the chat. Yeah. You can go to the, to the chat. Yes. And just ask for a summary in your style.swyx [00:42:13]: Yeah. Okay. I mean, I, I listen to consume, you know? Yeah. Yeah. I, I've never really used this feature. I don't know. I think that's, that's me being a slow adopter. No, no. I mean, that's. It has, when does the conversation start? Okay.Kevin [00:42:26]: I mean, you can just type anything. I think what you're, what you're describing, I mean, maybe that is also an interesting topic to talk about. Yes. Where, like, basically I told you, like, look, we have this chat. You can just ask for it. Yeah. And this is, this is how ChatGPT works today. But if you're building a consumer app, you have to move beyond the chat box. People do not want to always type out what they want. So your feature request was, even though theoretically it's already possible, what you are actually asking for is, hey, I just want to open up the app and it should just be there in a nicely formatted way. Beautiful way such that I can read it or consume it without any issues. Interesting. And I think that's in general where a lot of the, the. Opportunities lie currently in the market. If you want to build a consumer app, taking the capability and the intelligence, but finding out what the actual user interface is the best way how a user can engage with this intelligence in a natural way.swyx [00:43:24]: Is this something I've been thinking about as kind of like AI that's not in your face? Because right now, you know, we like to say like, oh, use Notion has Notion AI. And we have the little thing there. And there's, or like some other. Any other platform has like the sparkle magic wand emoji, like that's our AI feature. Use this. And it's like really in your face. A lot of people don't like it. You know, it should just kind of become invisible, kind of like an invisible AI.Kevin [00:43:49]: 100%. I mean, the, the way I see it as AI is, is the electricity of, of the future. And like no one, like, like we don't talk about, I don't know, this, this microphone uses electricity, this phone, you don't think about it that way. It's just in there, right? It's not an electricity enabled product. No, it's just a product. Yeah. It will be the same with AI. I mean, now. It's still a, something that you use to market your product. I mean, we do, we do the same, right? Because it's still something that people realize, ah, they're doing something new, but at some point, no, it'll just be a podcast app and it will be normal that it has all of this AI in there.swyx [00:44:24]: I noticed you do something interesting in your chat where you source the timestamps. Yeah. Is that part of this prompt? Is there a separate pipeline that adds source sources?Kevin [00:44:33]: This is, uh, actually part of the prompt. Um, so this is all prompt engine. Engineering, um, uh, you should be able to click on it. Yeah, I clicked on it. Um, this is all prompt engineering with how to provide the, the context, you know, we, because we provide all of the transcript, how to provide the context and then, yeah, I get them all to respond in a correct way with a certain format and then rendering that on the front end. This is one of the examples where I would say it's so easy to create like a quick demo of this. I mean, you can just go to chat to be deep, paste this thing in and say like, yeah, do this. Okay. Like 15 minutes and you're done. Yeah. But getting this to like then production level that it actually works 99% of the time. Okay. This is then where, where the difference lies. Yeah. So, um, for this specific feature, like we actually also have like countless regexes that they're just there to correct certain things that the LLM is doing because it doesn't always adhere to the format correctly. And then it looks super ugly on the front end. So yeah, we have certain regexes that correct that. And maybe you'd ask like, why don't you use an LLM for that? Because that's sort of the, again, the AI native way, like who uses regexes anymore. But with the chat for user experience, it's very important that you have the streaming because otherwise you need to wait so long until your message has arrived. So we're streaming live the, like, just like ChatGPT, right? You get the answer and it's streaming the text. So if you're streaming the text and something is like incorrect. It's currently not easy to just like pipe, like stream this into another stream, stream this into another stream and get the stream back, which corrects it, that would be amazing. I don't know, maybe you can answer that. Do you know of any?swyx [00:46:19]: There's no API that does this. Yeah. Like you cannot stream in. If you own the models, you can, uh, you know, whatever token sequence has, has been emitted, start loading that into the next one. If you fully own the models, uh, I don't, it's probably not worth it. That's what you do. It's better. Yeah. I think. Yeah. Most engineers who are new to AI research and benchmarking actually don't know how much regexing there is that goes on in normal benchmarks. It's just like this ugly list of like a hundred different, you know, matches for some criteria that you're looking for. No, it's very cool. I think it's, it's, it's an example of like real world engineering. Yeah. Do you have a tooling that you're proud of that you've developed for yourself?Kevin [00:47:02]: Is it just a test script or is it, you know? I think it's a bit more, I guess the term that has come up is, uh, vibe coding, uh, vibe coding, some, no, sorry, that's actually something else in this case, but, uh, no, no, yes, um, vibe evals was a term that in one of the talks actually on, on, um, I think it might've been the first, the first or the first day at the conference, someone brought that up. Yeah. Uh, because yeah, a lot of the talks were about evals, right. Which is so important. And yeah, I think for us, it's a bit more vibe. Evals, you know, that's also part of, you know, being a startup, we can take risks, like we can take the cost of maybe sometimes it failing a little bit or being a little bit off and our users know that and they appreciate that in return, like we're moving fast and iterating and building, building amazing things, but you know, a Spotify or something like that, half of our features will probably be in a six month review through legal or I don't know what, uh, before they could sell them out.swyx [00:48:04]: Let's just say Spotify is not very good at podcasting. Um, I have a documented, uh, dislike for, for their podcast features, just overall, really, really well integrated any other like sort of LLM focused engineering challenges or problems that you, that you want to highlight.Kevin [00:48:20]: I think it's not unique to us, but it goes again in the direction of handling the uncertainty of LLMs. So for example, with last year, at the end of the year, we did sort of a snipped wrapped. And one of the things we thought it would be fun to, just to do something with, uh, with an LLM and something with the snips that, that a user has. And, uh, three, let's say unique LLM features were that we assigned a personality to you based on the, the snips that, that you have. It was, I mean, it was just all, I guess, a bit of a fun, playful way. I'm going to look up mine. I forgot mine already.swyx [00:48:57]: Um, yeah, I don't know whether it's actually still in the, in the, we all took screenshots of it.Kevin [00:49:01]: Ah, we posted it in the, in the discord. And the, the second one, it was, uh, we had a learning scorecard where we identified the topics that you snipped on the most, and you got like a little score for that. And the third one was a, a quote that stood out. And the quote is actually a very good example of where we would run that for user. And most of the time it was an interesting quote, but every now and then it was like a super boring quotes that you think like, like how, like, why did you select that? Like, come on for there. The solution was actually just to say, Hey, give me five. So it extracted five quotes as a candidate, and then we piped it into a different model as a judge, LLM as a judge, and there we use a, um, a much better model because with the, the initial model, again, as, as I mentioned also earlier, we do have to look at the, like the, the costs because it's like, we have so much text that goes into it. So we, there we use a bit more cheaper model, but then the judge can be like a really good model to then just choose one out of five. This is a practical example.swyx [00:50:03]: I can't find it. Bad search in discord. Yeah. Um, so, so you do recommend having a much smarter model as a judge, uh, and that works for you. Yeah. Yeah. Interesting. I think this year I'm very interested in LM as a judge being more developed as a concept, I think for things like, you know, snips, raps, like it's, it's fine. Like, you know, it's, it's, it's, it's entertaining. There's no right answer.Kevin [00:50:29]: I mean, we also have it. Um, we also use the same concept for our books feature where we identify the, the mention. Books. Yeah. Because there it's the same thing, like 90% of the time it, it works perfectly out of the box one shot and every now and then it just, uh, starts identifying books that were not really mentioned or that are not books or made, yeah, starting to make up books. And, uh, they are basically, we have the same thing of like another LLM challenging it. Um, yeah. And actually with the speakers, we do the same now that I think about it. Yeah. Um, so I'm, I think it's a, it's a great technique. Interesting.swyx [00:51:05]: You run a lot of calls.Kevin [00:51:07]: Yeah.swyx [00:51:08]: Okay. You know, you mentioned costs. You move from self hosting a lot of models to the, to the, you know, big lab models, open AI, uh, and Google, uh, non-topic.Kevin [00:51:18]: Um, no, we love Claude. Like in my opinion, Claude is the, the best one when it comes to the way it formulates things. The personality. Yeah. The personality. Okay. I actually really love it. But yeah, the cost is. It's still high.swyx [00:51:36]: So you cannot, you tried Haiku, but you're, you're like, you have to have Sonnet.Kevin [00:51:40]: Uh, like basically we like with Haiku, we haven't experimented too much. We obviously work a lot with 3.5 Sonnet. Uh, also, you know, coding. Yeah. For coding, like in cursor, just in general, also brainstorming. We use it a lot. Um, I think it's a great brainstorm partner, but yeah, with, uh, with, with a lot of things that we've done done, we opted for different models.swyx [00:52:00]: What I'm trying to drive at is how much cheaper can you get if you go from cloud to cloud? Closed models to open models. And maybe it's like 0% cheaper, maybe it's 5% cheaper, or maybe it's like 50% cheaper. Do you have a sense?Kevin [00:52:13]: It's very difficult to, to judge that. I don't really have a sense, but I can, I can give you a couple of thoughts that have gone through our minds over the time, because obviously we do realize like, given that we, we have a couple of tasks where there are just so many tokens going in, um, at some point it will make sense to, to offload some of that. Uh, to an open source model, but going back to like, we're, we're a startup, right? Like we're not an AI lab or whatever, like for us, actually the most important thing is to iterate fast because we need to learn from our users, improve that. And yeah, just this velocity of this, these iterations. And for that, the closed models hosted by open AI, Google is, uh, and swapping, they're just unbeatable because you just, it's just an API call. Yeah. Um, so you don't need to worry about. Yeah. So much complexity behind that. So this is, I would say the biggest reason why we're not doing more in this space, but there are other thoughts, uh, also for the future. Like I see two different, like we basically have two different usage patterns of LLMs where one is this, this pre-processing of a podcast episode, like this initial processing, like the transcription, speaker diarization, chapterization. We do that once. And this, this usage pattern it's, it's quite predictable. Because we know how many podcasts get released when, um, so we can sort of have a certain capacity and we can, we, we're running that 24 seven, it's one big queue running 24 seven.swyx [00:53:44]: What's the queue job runner? Uh, is it a Django, just like the Python one?Kevin [00:53:49]: No, that, that's just our own, like our database and the backend talking to the database, picking up jobs, finding it back. I'm just curious in orchestration and queues. I mean, we, we of course have like, uh, a lot of other orchestration where we're, we're, where we use, uh, the Google pub sub, uh, thing, but okay. So we have this, this, this usage pattern of like very predictable, uh, usage, and we can max out the, the usage. And then there's this other pattern where it's, for example, the snippet where it's like a user, it's a user action that triggers an LLM call and it has to be real time. And there can be moments where it's by usage and there can be moments when there's very little usage for that. There. So that's, that's basically where these LLM API calls are just perfect because you don't need to worry about scaling this up, scaling this down, um, handling, handling these issues. Serverless versus serverful.swyx [00:54:44]: Yeah, exactly. Okay.Kevin [00:54:45]: Like I see them a bit, like I see open AI and all of these other providers, I see them a bit as the, like as the Amazon, sorry, AWS of, of AI. So it's a bit similar how like back before AWS, you would have to have your, your servers and buy new servers or get rid of servers. And then with AWS, it just became so much easier to just ramp stuff up and down. Yeah. And this is like the taking it even, even, uh, to the next level for AI. Yeah.swyx [00:55:18]: I am a big believer in this. Basically it's, you know, intelligence on demand. Yeah. We're probably not using it enough in our daily lives to do things. I should, we should be able to spin up a hundred things at once and go through things and then, you know, stop. And I feel like we're still trying to figure out how to use LLMs in our lives effectively. Yeah. Yeah.Kevin [00:55:38]: 100%. I think that goes back to the whole, like that, that's for me where the big opportunity is for, if you want to do a startup, um, it's not about, but you can let the big labs handleswyx [00:55:48]: the challenge of more intelligence, but, um, it's the... Existing intelligence. How do you integrate? How do you actually incorporate it into your life? AI engineering. Okay, cool. Cool. Cool. Cool. Um, the one, one other thing I wanted to touch on was multimodality in frontier models. Dwarcash had a interesting application of Gemini recently where he just fed raw audio in and got diarized transcription out or timestamps out. And I think that will come. So basically what we're saying here is another wave of transformers eating things because right now models are pretty much single modality things. You know, you have whisper, you have a pipeline and everything. Yeah. You can't just say, Oh, no, no, no, we only fit like the raw, the raw files. Do you think that will be realistic for you? I 100% agree. Okay.Kevin [00:56:38]: Basically everything that we talked about earlier with like the speaker diarization and heuristics and everything, I completely agree. Like in the, in the future that would just be put everything into a big multimodal LLM. Okay. And it will output, uh, everything that you want. Yeah. So I've also experimented with that. Like just... With, with Gemini 2? With Gemini 2.0 Flash. Yeah. Just for fun. Yeah. Yeah. Because the big difference right now is still like the cost difference of doing speaker diarization this way or doing transcription this way is a huge difference to the pipeline that we've built up. Huh. Okay.swyx [00:57:15]: I need to figure out what, what that cost is because in my mind 2.0 Flash is so cheap. Yeah. But maybe not cheap enough for you.Kevin [00:57:23]: Uh, no, I mean, if you compare it to, yeah, whisper and speaker diarization and especially self-hosting it and... Yeah. Yeah. Yeah.swyx [00:57:30]: Yeah.Kevin [00:57:30]: Okay. But we will get there, right? Like this is just a question of time.swyx [00:57:33]: And, um, at some point, as soon as that happens, we'll be the first ones to switch. Yeah. Awesome. Anything else that you're like sort of eyeing on the horizon as like, we are thinking about this feature, we're thinking about incorporating this new functionality of AI into our, into our app? Yeah.Kevin [00:57:50]: I mean, we, there's so many areas that we're thinking about, like our challenge is a bit more... Choosing. Yeah. Choosing. Yeah. So, I mean, I think for me, like looking into like the next couple of years, like the big areas that interest us a lot, basically four areas, like one is content. Um, right now it's, it's podcasts. I mean, you did mention, I think you mentioned like you can also upload audio books and YouTube videos. YouTube. I actually use the YouTube one a fair amount. But in the future, we, we want to also have audio books natively in the app. And, uh, we want to enable AI generated content. Like just think of, take deep research and notebook analysis. Like put these together. That should be, that should be in our app. The second area is discovery. I think in general. Yeah.swyx [00:58:38]: I noticed that you don't have, so you have download counts and most snips. Right. Something like that. Yeah. Yeah.Kevin [00:58:45]: On the discovery side, we want to do much, much more. I think in general, discovery as a paradigm in all apps is, will undergo a change thanks Thanks to AI. You know, there has been a lot of talk. Before Elon bought Twitter, there was a lot of talk about bring your own algorithm to Twitter. And that was Jack Dorsey's big thing. He talked a lot about that. And I actually think this is coming, but with a bit of a twist. So I think what actually AI will enable is not that you bring your own algorithm, but you will be able to talk. You will be able to communicate with the algorithm. So you can just tell the algorithm, like, hey, you keep showing me cat videos. And I know I freaking love them. And that's why you keep showing them to me. But please, for the next two hours, I really want to get more into AI stuff. Do not show me cat videos. And then it will just adapt. And of course, the question is, you know, like big platforms like, I don't know, let's say TikTok. They do not have the incentive to offer that.swyx [00:59:49]: Exactly. That's what I was going to say.Kevin [00:59:50]: But we actually, we are driven by helping you learn, get the most, like achieve your goals. And so for us, it's actually very much our incentive. Like, hey, you know, you should be able to guide it. Yeah. So that was a long way of saying that I think there will happen a lot in recommendations. Order by.swyx [01:00:12]: The most popular. Yeah. I think collaborative filtering will be the first step, right? For Rexis and then some LLM fancy stuff.Kevin [01:00:20]: Yeah. Maybe to go back to the question that you had before. So the other, like these were the first two areas. Yeah. The two are voice, voices and interfaces and voice AI. Well, how is this going to exist? Yeah. So maybe I can tell you a bit first, like why I find it so interesting for us. Yeah. Because voice as an interface, like historically, there has been so much talk about it and it always fell flat. The reason why I'm excited about it this time around is with any consumer app, I like to ask myself, what is the... moment in my life, what is the trigger in my life that gets me to open this app and start using it? So, for example, I don't know, take Airbnb. It's the trigger is like, ah, you want to travel and then and then you, you do that and then you open up the app. Apps that do not have this already existing natural trigger in your life, it's very difficult for a consumer app to then get the user to open the app again. You need a hook. Yeah. There's basically only one app. One super successful app that has been able to do that without this natural trigger, and that is Duolingo. So Duolingo, like everyone wants to learn a language, but there's, you don't have this natural moment during your day where it's like, ah, now I need to open up this app. You have the notifications. Exactly. The owl memes. Exactly. So they, I mean, they gamified the s**t super successful, super beautiful. They are the GOATs in this arena. But the much easier is actually... No, there is already this trigger and then you don't have to do all of the streaks and leaderboards and everything. Okay. That's a bit of a context. Now, if you look at what we're doing and our goal of getting people to really maximize what they get out of their listening, we are interested in, there are a couple of features where we know we can sort of 10x the value that people get out of a podcast. Okay. But we need them to do something for that. There is friction involved. Because it's all about learning, right? It's about thinking for yourself. Like, those are the moments when you actually start, yeah, really 10x-ing the value that you got out of the podcast instead of just consuming it.swyx [01:02:37]: Applying the knowledge. Yeah. Okay.Kevin [01:02:39]: Basically, being forced to think about like, what was actually the main takeaway for you from this episode? Okay. Like, there's something that I like doing myself for every episode that I listen to, I try to boil it down to, like, try to decide one single takeaway. Yeah. Even though there might have been 10. Yeah. There might have been 10 amazing things. Pick one. One most important one. Yeah. And this is an active process that is like a forcing function in your brain to challenge all of the insights and really come up with the one thing that is applicable to you and your life and what you might want to do with it. So it also helps you to turn it into action. This is basically a feature that we're interested in, but you have to get the user to use that, right? So when do you get the user to use that? Yeah. So if this is all text-based, then we're basically playing the same game as Duolingo, where at some point you're going to get a notification from Snip and be like, hey, Swyx, come on, you know you should do this. Maybe there's a blue owl.Kevin [01:03:40]: But if you have voice, you can basically hook into the existing habits that the user already has. So you already have this habit that you listen to a podcast. You're already doing that. Yeah. And once an episode ends, instead of just jumping into the next episode, you can now actually have your AI companion come on and you can have a quick conversation. You can go through these things. And how that looks like in detail, we need to figure that out. But just this paradigm of you're staying in the flow. This also relates to what you were saying, like AI that is invisible. You're staying in the flow of what you're already doing. But now we can insert a completely new experience. That helps you get the most out of real estate. Yeah.swyx [01:04:27]: I think your framing of this is very powerful. Because I think this is where you are a product person more than an engineer. Because an engineer would just be like, oh, it's just chat with your podcast. It's like chat with PDF, chat with podcast. Okay, cool. But you're framing it in a different light that actually makes sense to me now, as opposed to previously. I don't chat with my podcast. Why? I just listen to the podcast. But for you, it's more about retention and learning and all that. And because you're very serious about it, that's why you started the company. So you're focused on that. Whereas I'm still stuck in that consume, consume, consume mentality. And I know it's not good, but this is my default. Which is why I was a little bit lost when you were saying all the things about Duolingo. And you're saying the things about the trigger. This is my trigger for listening to the podcast is I'm by myself. That's my trigger. But you're saying the trigger is not about listening to the podcast. The trigger is remembering and retaining and processing the podcast I just listened to.Kevin [01:05:41]: So what I meant, you already have this trigger that gets you to start listening to a podcast. Yes. This you already have. And so do, I don't know. Millions of people. Yeah. So there are more than half a billion monthly active podcast listeners. Okay. So you already have this trigger that gets you to start listening. But you do not have this trigger. As you just said yourself, basically, you do not have this trigger that gets you to regularly process this information. And voice basically for me is the ability to hook into your existing trigger with the trigger that I was talking about is basically your podcast. And you're just still listening. So we just continue and we can now spend, you know, this can be two minutes. Like I'm not saying now this is like a 60 minute process. I think like two minutes, three minutes that can just come on completely naturally. And if we manage to do that and you start noticing as a user, like freaking hell, like I'm just now spending three minutes with this AI companion. But like. Your retention is more. I'm taking this much away. And it's not. And like retention is one thing. But you're like. Yeah. You start to take what you've learned and apply it to what's important to you. Like you're thinking. Yeah. And if we get you to notice that feeling, then yeah, then we've won. Yeah.swyx [01:07:05]: I would say like a lot of people rely on Anki, Anki notes like flashcards and all that to do that. But making the notes is also a chore. And I think this could be very, very interesting. I think that I'm just noticing that it's kind of like a different usage mode. Like you already talked about this. You know, the name of Snips is very Snip centric. And I actually originally also resisted adopting Snip because of that. But now you're like, you know, you observe that people are listening to long form episodes and you're talking at the end. Like the ideal implementation of this is I browse through a bunch of Snips of the things that I'm subscribed to. I listen to the Snips. I talk with it. And then maybe it double clicks on the podcast and it goes and finds other timestamps that are relevant to the thing that I want to talk about. Just. I don't know that. I don't know if that's interesting.Kevin [01:07:53]: I think these are all areas that we should explore. Yeah.swyx [01:07:57]: Like we're still quite open about how this will look like in detail. What are your thoughts on voice cloning? Everyone wants to continue. I have had my voice clones and people have talked to me, the AI version of me. Is that too creepy?Kevin [01:08:13]: I don't think it's too creepy in the future. Okay. With a lot of these things in our society is going through a change. And things seem quite weird now that in the future will seem normal. I think already voice cloning has become much more normalized. I remember I was at the, I think it was 2017 Nips conference. San Diego?swyx [01:08:42]: No, LA. LA. It was the Flo Rida one? Yeah. Yeah. Flo Rida. Yeah.Kevin [01:08:47]: So everyone says that was peak Nips. Yeah. I remember there was this talk or workshop by Liar Bird. They actually got acquired by Descript later. They were doing voice cloning and they were showing off their tech. And there was this huge discussion later on, like all of the moral implications and ethical implications. And it really felt like this would never be accepted by society. And you look now, you have 11 labs and just anyone can just clone their voice. And no one really talks about it as like, oh my God, the world is going to end. Yeah. So I think society will get used to that. In our case, I think there are some interesting applications where we'd also be super interested in working together with creators, like podcast creators, to play a bit around with this concept. I think that would be super cool if someone can come onto Snipped, go to the Latent Spaceswyx [01:09:42]: podcast and start chatting with AI Swyx. Yeah. No, I think we'd be there. Yeah. We want to, obviously, I think as an AI podcast, we should be first consumers of these things. Yeah. I would say that one observation I've made about podcasting, this is the general state of the market. And you can ask me your questions, things you want to ask about podcasters. We are focusing a lot more on YouTube this year. YouTube is the best podcasting platform. It is not MP3s. It is not Apple Podcasts. It is not Spotify. It's YouTube. And it's just the social layer of recommendations and the existing habit that people have of logging onto YouTube and getting that. That's my observation. You can riff on that. The only thing I would just say is like, when you were listing your list of priorities, you said audio books first over YouTube.Kevin [01:10:26]: And I would switch that if I were you. Yeah. Like as in YouTube, video, video podcasts. I mean, it's obvious that video podcasts are here to stay. Not just here to stay, bigger. Yeah. What I want to do with Snipped is obviously also add video to the platform. Oh, yeah. The way I see video is I do believe it's... Yeah. I like this concept of backgroundable video. I didn't come up with this concept. It was actually Gustav Söderström. The CPO of Spotify. Exactly. Exactly. When I speak with people, it remains true that they listen to podcasts when they do something else at the same time. Like this is like 90% of their consumption. Also if they listen to on YouTube. But every now and then it's nice to have the video. It's nice if you're, for example, just watching a clip. It's nice if they sometimes mention something, like they show some slides or they show something where you need to have the visual with it. It helps you connect much more with the host as a listener. But the biggest benefit I see with video is discovery. I think that is also why YouTube has become the biggest podcast player out there because they have the discovery. And discovery in video is just so much easier and so much better. And so much more engaging. So this is the area where I'm most interested about when it comes to video and snips. That we can provide a much better, much more engaging and much more fun discovery experience. For consumers? Yeah, for consumers.swyx [01:12:01]: Okay. I think that you almost have like three different audiences. The vast majority of people for you is the people listening to podcasts. Right? Of course. Then there's a second layer of people who create snips. Right? Who add extra data, annotation value to your platform. By the way, we use the snip count as a proxy for popularity, right? Because we have download counts, but for example, platforms like Spotify re-host our MP3 file. So we don't get any download count for Spotify. Snip count is active, like I opt in to listen to you and I shared this. Those are really, really good metrics. But the third audience that you haven't really touched is the podcast creators like myself. And for me, discovery from that point of view, not from your point of view, discovery for me is like, I want to be discovered. And I think YouTube is still there. Twitter, obviously for me, Substack, Hacker News. I really try very hard to rank on Hacker News. I think when TikTok took this very seriously, they prioritized the creators of the content. And for you, the creator of the content was the snips. But there may be a world for you in which you prioritize the creators of the podcast.Kevin [01:13:10]: Yeah. Interesting observation. What are some of your ideas or thoughts? Do you have some specific?swyx [01:13:18]: Riverside is the closest that has come to it. Descript is number two. Descript bought a Riverside competitor and as far as I can tell, it's not been very successful. Descript just has a very, very good niche, very, very good editing angle and then just hasn't done anything interesting since then. Although Underlord is good, it's not great. Your chapterization is better than Descript's. Again, they should be able to beat you. They're not. And Riverside is good also. Very, very good. Very, very, very good. So we actually recently started a second series of podcasts within Latent Space that is YouTube only because you only find it on YouTube. And it's also shorter. So this is like a one and a half hour, two hour thing. Remote only, 30 minutes, chop, chop. Send it on to Riverside. Riverside, pretty good for that. Not great. It doesn't do good thumbnails. It doesn't do good. The editing is still a little bit rough. It has this auto editor where whoever's actively speaking, it focuses on the editor, on the active speaker. And then sometimes it goes back to the multi-speaker view, that kind of stuff. People like that. Okay. But the shorts are still not great. I still need to manually download it and then republish it to YouTube. The shorts I still need to pick. They mostly suck. There's still a lot of rough edges there that ideally, me as a creator, you know what I want. You definitely know what I want. I sit down, record, press a button, done. We're still not there.Kevin [01:14:46]: I think you guys could do it. Okay. So if I can translate that for you, it's really about the simplifying the creation process of the podcast. Yeah.swyx [01:14:55]: And I'll tell you what, this will increase the quality because the reason that most podcasts or YouTube videos are s**t is they are made by people who don't have life experience, who are not that important in the world. They're not doing important jobs. And so what you want to actually enable is CEOs to each of them make their own podcasts who are busy. They're not going to sit there and figure out Riverside. A lot of the reason that people like Latent Space is it takes an idiot like me who could be doing a lot more with my life, making a lot more money, having a real job somewhere else. I just choose to do this because I like it. But otherwise, they will never get access to me and the access to the people that I have access to. So that's my pitch. Cool.swyx [01:15:44]: Anything else that you normally want to talk to podcasters about?Kevin [01:15:46]: I think we've covered everything. I guess like last messages, you know, go try out Snipped. Yeah. It's a premium version so you can use and try out everything for free. Also happy to provide you with a link that you can add to the show notes. Try out the premium version also for free for a month if people want to do that. Yeah. Give it a shot.swyx [01:16:08]: I would say. Yeah. Thanks for coming on. I would say that after you demoed me, I did not convert for another four to six months because I found it very challenging to switch over. And I think that's the main thing. Like you basically had you have import OPML. Right. But there's no way to import like all the existing like half listened to episodes or like my rankings or whatever. And for that, for listeners who are. I have a blog post where I talked about my switch. Just treat it as a chance to clean house.swyx [01:16:45]: That's a good point. Do things and, you know, just refocus here. First start. 2025. Yeah. Great. Well, thank you for working on Snipped. Thank you for coming on. You know, we usually spend a lot of time talking to like big companies like venture startups, B2B, SaaS, you know, that kind of stuff. But I think your journey is like, you know, it's a small team building a B2C consumer app. It's the kind of stuff that we like to also feature because a lot of people want to build what you're doing. And they don't see role models that are successful, that are confidence, that are like having success in this market, which is very challenging. So, yeah, thanks for thanks for sharing some of your thoughts. Thanks.Kevin [01:17:26]: Yeah, thanks. Thanks for having me. And thank you for creating an amazing podcast and an amazing conference as well.swyx [01:17:32]: Thank you. Get full access to Latent.Space at www.latent.space/subscribe
-
 ⚡️The new OpenAI Agents Platform
⚡️The new OpenAI Agents PlatformFrom 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2025-03-11 17:39
While everyone is now repeating that 2025 is the “Year of the Agent”, OpenAI is heads down building towards it. In the first 2 months of the year they released Operator and Deep Research (arguably the most successful agent archetype so far), and today they are bringing a lot of those capabilities to the API:* Responses API* Web Search Tool* Computer Use Tool* File Search Tool* A new open source Agents SDK with integrated Observability ToolsWe cover all this and more in today’s lightning pod on YouTube!More details here:Responses APIIn our Michelle Pokrass episode we talked about the Assistants API needing a redesign. Today OpenAI is launching the Responses API, “a more flexible foundation for developers building agentic applications”. It’s a superset of the chat completion API, and the suggested starting point for developers working with OpenAI models. One of the big upgrades is the new set of built-in tools for the responses API: Web Search, Computer Use, and Files. Web Search ToolWe previously had Exa AI on the podcast to talk about web search for AI. OpenAI is also now joining the race; the Web Search API is actually a new “model” that exposes two 4o fine-tunes: gpt-4o-search-preview and gpt-4o-mini-search-preview. These are the same models that power ChatGPT Search, and are priced at $30/1000 queries and $25/1000 queries respectively. The killer feature is inline citations: you do not only get a link to a page, but also a deep link to exactly where your query was answered in the result page. Computer Use ToolThe model that powers Operator, called Computer-Using-Agent (CUA), is also now available in the API. The computer-use-preview model is SOTA on most benchmarks, achieving 38.1% success on OSWorld for full computer use tasks, 58.1% on WebArena, and 87% on WebVoyager for web-based interactions.As you will notice in the docs, `computer-use-preview` is both a model and a tool through which you can specify the environment. Usage is priced at $3/1M input tokens and $12/1M output tokens, and it’s currently only available to users in tiers 3-5.File Search ToolFile Search was also available in the Assistants API, and it’s now coming to Responses too. OpenAI is bringing search + RAG all under one umbrella, and we’ll definitely see more people trying to find new ways to build all-in-one apps on OpenAI. Usage is priced at $2.50 per thousand queries and file storage at $0.10/GB/day, with the first GB free.Agent SDK: Swarms++!https://github.com/openai/openai-agents-pythonTo bring it all together, after the viral reception to Swarm, OpenAI is releasing an officially supported agents framework (which was previewed at our AI Engineer Summit) with 4 core pieces:* Agents: Easily configurable LLMs with clear instructions and built-in tools.* Handoffs: Intelligently transfer control between agents.* Guardrails: Configurable safety checks for input and output validation.* Tracing & Observability: Visualize agent execution traces to debug and optimize performance.Multi-agent workflows are here to stay!OpenAI is now explicitly designs for a set of common agentic patterns: Workflows, Handoffs, Agents-as-Tools, LLM-as-a-Judge, Parallelization, and Guardrails. OpenAI previewed this in part 2 of their talk at NYC:Further coverage of the launch from Kevin Weil, WSJ, and OpenAIDevs, AMA here.Show Notes* Assistants API* Swarm (OpenAI)* Fine-Tuning in AI* 2024 OpenAI DevDay Recap with Romain* Michelle Pokrass episode (API lead)Timestamps* 00:00 Intros* 02:31 Responses API * 08:34 Web Search API * 17:14 Files Search API * 18:46 Files API vs RAG * 20:06 Computer Use / Operator API * 22:30 Agents SDKAnd of course you can catch up with the full livestream here:TranscriptAlessio [00:00:03]: Hey, everyone. Welcome back to another Latent Space Lightning episode. This is Alessio, partner and CTO at Decibel, and I'm joined by Swyx, founder of Small AI.swyx [00:00:11]: Hi, and today we have a super special episode because we're talking with our old friend Roman. Hi, welcome.Romain [00:00:19]: Thank you. Thank you for having me.swyx [00:00:20]: And Nikunj, who is most famously, if anyone has ever tried to get any access to anything on the API, Nikunj is the guy. So I know your emails because I look forward to them.Nikunj [00:00:30]: Yeah, nice to meet all of you.swyx [00:00:32]: I think that we're basically convening today to talk about the new API. So perhaps you guys want to just kick off. What is OpenAI launching today?Nikunj [00:00:40]: Yeah, so I can kick it off. We're launching a bunch of new things today. We're going to do three new built-in tools. So we're launching the web search tool. This is basically chat GPD for search, but available in the API. We're launching an improved file search tool. So this is you bringing your data to OpenAI. You upload it. We, you know, take care of parsing it, chunking it. We're embedding it, making it searchable, give you this like ready vector store that you can use. So that's the file search tool. And then we're also launching our computer use tool. So this is the tool behind the operator product in chat GPD. So that's coming to developers today. And to support all of these tools, we're going to have a new API. So, you know, we launched chat completions, like I think March 2023 or so. It's been a while. So we're looking for an update over here to support all the new things that the models can do. And so we're launching this new API. It is, you know, it works with tools. We think it'll be like a great option for all the future agentic products that we build. And so that is also launching today. Actually, the last thing we're launching is the agents SDK. We launched this thing called Swarm last year where, you know, it was an experimental SDK for people to do multi-agent orchestration and stuff like that. It was supposed to be like educational experimental, but like people, people really loved it. They like ate it up. And so we are like, all right, let's, let's upgrade this thing. Let's give it a new name. And so we're calling it the agents SDK. It's going to have built-in tracing in the OpenAI dashboard. So lots of cool stuff going out. So, yeah.Romain [00:02:14]: That's a lot, but we said 2025 was the year of agents. So there you have it, like a lot of new tools to build these agents for developers.swyx [00:02:20]: Okay. I guess, I guess we'll just kind of go one by one and we'll leave the agents SDK towards the end. So responses API, I think the sort of primary concern that people have and something I think I've voiced to you guys when, when, when I was talking with you in the, in the planning process was, is chat completions going away? So I just wanted to let it, let you guys respond to the concerns that people might have.Romain [00:02:41]: Chat completion is definitely like here to stay, you know, it's a bare metal API we've had for quite some time. Lots of tools built around it. So we want to make sure that it's maintained and people can confidently keep on building on it. At the same time, it was kind of optimized for a different world, right? It was optimized for a pre-multi-modality world. We also optimized for kind of single turn. It takes two problems. It takes prompt in, it takes response out. And now with these agentic workflows, we, we noticed that like developers and companies want to build longer horizon tasks, you know, like things that require multiple returns to get the task accomplished. And computer use is one of those, for instance. And so that's why the responses API came to life to kind of support these new agentic workflows. But chat completion is definitely here to stay.swyx [00:03:27]: And assistance API, we've, uh, has a target sunset date of first half of 2020. So this is kind of like, in my mind, there was a kind of very poetic mirroring of the API with the models. This, I kind of view this as like kind of the merging of assistance API and chat completions, right. Into one unified responses. So it's kind of like how GPT and the old series models are also unifying.Romain [00:03:48]: Yeah, that's exactly the right, uh, that's the right framing, right? Like, I think we took the best of what we learned from the assistance API, especially like being able to access tools very, uh, very like conveniently, but at the same time, like simplifying the way you have to integrate, like, you no longer have to think about six different objects to kind of get access to these tools with the responses API. You just get one API request and suddenly you can weave in those tools, right?Nikunj [00:04:12]: Yeah, absolutely. And I think we're going to make it really easy and straightforward for assistance API users to migrate over to responsive. Right. To the API without any loss of functionality or data. So our plan is absolutely to add, you know, assistant like objects and thread light objects to that, that work really well with the responses API. We'll also add like the code interpreter tool, which is not launching today, but it'll come soon. And, uh, we'll add async mode to responses API, because that's another difference with, with, uh, assistance. I will have web hooks and stuff like that, but I think it's going to be like a pretty smooth transition. Uh, once we have all of that in place. And we'll be. Like a full year to migrate and, and help them through any issues they, they, they face. So overall, I feel like assistance users are really going to benefit from this longer term, uh, with this more flexible, primitive.Alessio [00:05:01]: How should people think about when to use each type of API? So I know that in the past, the assistance was maybe more stateful, kind of like long running, many tool use kind of like file based things. And the chat completions is more stateless, you know, kind of like traditional completion API. Is that still the mental model that people should have? Or like, should you buy the.Nikunj [00:05:20]: So the responses API is going to support everything that it's at launch, going to support everything that chat completion supports, and then over time, it's going to support everything that assistance supports. So it's going to be a pretty good fit for anyone starting out with open AI. Uh, they should be able to like go to responses responses, by the way, also has a stateless mode, so you can pass in store false and they'll make the whole API stateless, just like chat completions. You're really trying to like get this unification. A story in so that people don't have to juggle multiple endpoints. That being said, like chat completions, just like the most widely adopted API, it's it's so popular. So we're still going to like support it for years with like new models and features. But if you're a new user, you want to or if you want to like existing, you want to tap into some of these like built in tools or something, you should feel feel totally fine migrating to responses and you'll have more capabilities and performance than the tech completions.swyx [00:06:16]: I think the messaging that I agree that I think resonated the most. When I talked to you was that it is a strict superset, right? Like you should be able to do everything that you could do in chat completions and with assistants. And the thing that I just assumed that because you're you're now, you know, by default is stateful, you're actually storing the chat logs or the chat state. I thought you'd be charging me for it. So, you know, to me, it was very surprising that you figured out how to make it free.Nikunj [00:06:43]: Yeah, it's free. We store your state for 30 days. You can turn it off. But yeah, it's it's free. And the interesting thing on state is that it just like makes particularly for me, it makes like debugging things and building things so much simpler, where I can like create a responses object that's like pretty complicated and part of this more complex application that I've built, I can just go into my dashboard and see exactly what happened that mess up my prompt that is like not called one of these tools that misconfigure one of the tools like the visual observability of everything that you're doing is so, so helpful. So I'm excited, like about people trying that out and getting benefits from it, too.swyx [00:07:19]: Yeah, it's a it's really, I think, a really nice to have. But all I'll say is that my friend Corey Quinn says that anything that can be used as a database will be used as a database. So be prepared for some abuse.Romain [00:07:34]: All right. Yeah, that's a good one. Some of that I've tried with the metadata. That's some people are very, very creative at stuffing data into an object. Yeah.Nikunj [00:07:44]: And we do have metadata with responses. Exactly. Yeah.Alessio [00:07:48]: Let's get through it. All of these. So web search. I think the when I first said web search, I thought you were going to just expose a API that then return kind of like a nice list of thing. But the way it's name is like GPD for all search preview. So I'm guessing you have you're using basically the same model that is in the chat GPD search, which is fine tune for search. I'm guessing it's a different model than the base one. And it's impressive the jump in performance. So just to give an example, in simple QA, GPD for all is 38% accuracy for all search is 90%. But we always talk about. How tools are like models is not everything you need, like tools around it are just as important. So, yeah, maybe give people a quick review on like the work that went into making this special.Nikunj [00:08:29]: Should I take that?Alessio [00:08:29]: Yeah, go for it.Nikunj [00:08:30]: So firstly, we're launching web search in two ways. One in responses API, which is our API for tools. It's going to be available as a web search tool itself. So you'll be able to go tools, turn on web search and you're ready to go. We still wanted to give chat completions people access to real time information. So in that. Chat completions API, which does not support built in tools. We're launching the direct access to the fine tuned model that chat GPD for search uses, and we call it GPD for search preview. And how is this model built? Basically, we have our search research team has been working on this for a while. Their main goal is to, like, get information, like get a bunch of information from all of our data sources that we use to gather information for search and then pick the right things and then cite them. As accurately as possible. And that's what the search team has really focused on. They've done some pretty cool stuff. They use like synthetic data techniques. They've done like all series model distillation to, like, make these four or fine tunes really good. But yeah, the main thing is, like, can it remain factual? Can it answer questions based on what it retrieves and get cited accurately? And that's what this like fine tune model really excels at. And so, yeah, so we're excited that, like, it's going to be directly available in chat completions along with being available as a tool. Yeah.Alessio [00:09:49]: Just to clarify, if I'm using the responses API, this is a tool. But if I'm using chat completions, I have to switch model. I cannot use 01 and call search as a tool. Yeah, that's right. Exactly.Romain [00:09:58]: I think what's really compelling, at least for me and my own uses of it so far, is that when you use, like, web search as a tool, it combines nicely with every other tool and every other feature of the platform. So think about this for a second. For instance, imagine you have, like, a responses API call with the web search tool, but suddenly you turn on function calling. You also turn on, let's say, structure. So you can have, like, the ability to structure any data from the web in real time in the JSON schema that you need for your application. So it's quite powerful when you start combining those features and tools together. It's kind of like an API for the Internet almost, you know, like you get, like, access to the precise schema you need for your app. Yeah.Alessio [00:10:39]: And then just to wrap up on the infrastructure side of it, I read on the post that people, publisher can choose to appear in the web search. So are people by default in it? Like, how can we get Latent Space in the web search API?Nikunj [00:10:53]: Yeah. Yeah. I think we have some documentation around how websites, publishers can control, like, what shows up in a web search tool. And I think you should be able to, like, read that. I think we should be able to get Latent Space in for sure. Yeah.swyx [00:11:10]: You know, I think so. I compare this to a broader trend that I started covering last year of online LLMs. Actually, Perplexity, I think, was the first. It was the first to say, to offer an API that is connected to search, and then Gemini had the sort of search grounding API. And I think you guys, I actually didn't, I missed this in the original reading of the docs, but you even give like citations with like the exact sub paragraph that is matching, which I think is the standard nowadays. I think my question is, how do we take what a knowledge cutoff is for something like this, right? Because like now, basically there's no knowledge cutoff is always live, but then there's a difference between what the model has sort of internalized in its back propagation and what is searching up its rag.Romain [00:11:53]: I think it kind of depends on the use case, right? And what you want to showcase as the source. Like, for instance, you take a company like Hebbia that has used this like web search tool. They can combine like for credit firms or law firms, they can find like, you know, public information from the internet with the live sources and citation that sometimes you do want to have access to, as opposed to like the internal knowledge. But if you're building something different, well, like, you just want to have the information. If you want to have an assistant that relies on the deep knowledge that the model has, you may not need to have these like direct citations. So I think it kind of depends on the use case a little bit, but there are many, uh, many companies like Hebbia that will need that access to these citations to precisely know where the information comes from.swyx [00:12:34]: Yeah, yeah, uh, for sure. And then one thing on the, on like the breadth, you know, I think a lot of the deep research, open deep research implementations have this sort of hyper parameter about, you know, how deep they're searching and how wide they're searching. I don't see that in the docs. But is that something that we can tune? Is that something you recommend thinking about?Nikunj [00:12:53]: Super interesting. It's definitely not a parameter today, but we should explore that. It's very interesting. I imagine like how you would do it with the web search tool and responsive API is you would have some form of like, you know, agent orchestration over here where you have a planning step and then each like web search call that you do like explicitly goes a layer deeper and deeper and deeper. But it's not a parameter that's available out of the box. But it's a cool. It's a cool thing to think about. Yeah.swyx [00:13:19]: The only guidance I'll offer there is a lot of these implementations offer top K, which is like, you know, top 10, top 20, but actually don't really want that. You want like sort of some kind of similarity cutoff, right? Like some matching score cuts cutoff, because if there's only five things, five documents that match fine, if there's 500 that match, maybe that's what I want. Right. Yeah. But also that might, that might make my costs very unpredictable because the costs are something like $30 per a thousand queries, right? So yeah. Yeah.Nikunj [00:13:49]: I guess you could, you could have some form of like a context budget and then you're like, go as deep as you can and pick the best stuff and put it into like X number of tokens. There could be some creative ways of, of managing cost, but yeah, that's a super interesting thing to explore.Alessio [00:14:05]: Do you see people using the files and the search API together where you can kind of search and then store everything in the file so the next time I'm not paying for the search again and like, yeah, how should people balance that?Nikunj [00:14:17]: That's actually a very interesting question. And let me first tell you about how I've seen a really cool way I've seen people use files and search together is they put their user preferences or memories in the vector store and so a query comes in, you use the file search tool to like get someone's like reading preferences or like fashion preferences and stuff like that, and then you search the web for information or products that they can buy related to those preferences and you then render something beautiful to show them, like, here are five things that you might be interested in. So that's how I've seen like file search, web search work together. And by the way, that's like a single responses API call, which is really cool. So you just like configure these things, go boom, and like everything just happens. But yeah, that's how I've seen like files and web work together.Romain [00:15:01]: But I think that what you're pointing out is like interesting, and I'm sure developers will surprise us as they always do in terms of how they combine these tools and how they might use file search as a way to have memory and preferences, like Nikum says. But I think like zooming out, what I find very compelling and powerful here is like when you have these like neural networks. That have like all of the knowledge that they have today, plus real time access to the Internet for like any kind of real time information that you might need for your app and file search, where you can have a lot of company, private documents, private details, you combine those three, and you have like very, very compelling and precise answers for any kind of use case that your company or your product might want to enable.swyx [00:15:41]: It's a difference between sort of internal documents versus the open web, right? Like you're going to need both. Exactly, exactly. I never thought about it doing memory as well. I guess, again, you know, anything that's a database, you can store it and you will use it as a database. That sounds awesome. But I think also you've been, you know, expanding the file search. You have more file types. You have query optimization, custom re-ranking. So it really seems like, you know, it's been fleshed out. Obviously, I haven't been paying a ton of attention to the file search capability, but it sounds like your team has added a lot of features.Nikunj [00:16:14]: Yeah, metadata filtering was like the main thing people were asking us for for a while. And I'm super excited about it. I mean, it's just so critical once your, like, web store size goes over, you know, more than like, you know, 5,000, 10,000 records, you kind of need that. So, yeah, metadata filtering is coming, too.Romain [00:16:31]: And for most companies, it's also not like a competency that you want to rebuild in-house necessarily, you know, like, you know, thinking about embeddings and chunking and, you know, how of that, like, it sounds like very complex for something very, like, obvious to ship for your users. Like companies like Navant, for instance. They were able to build with the file search, like, you know, take all of the FAQ and travel policies, for instance, that you have, you, you put that in file search tool, and then you don't have to think about anything. Now your assistant becomes naturally much more aware of all of these policies from the files.swyx [00:17:03]: The question is, like, there's a very, very vibrant RAG industry already, as you well know. So there's many other vector databases, many other frameworks. Probably if it's an open source stack, I would say like a lot of the AI engineers that I talk to want to own this part of the stack. And it feels like, you know, like, when should we DIY and when should we just use whatever OpenAI offers?Nikunj [00:17:24]: Yeah. I mean, like, if you're doing something completely from scratch, you're going to have more control, right? Like, so super supportive of, you know, people trying to, like, roll up their sleeves, build their, like, super custom chunking strategy and super custom retrieval strategy and all of that. And those are things that, like, will be harder to do with OpenAI tools. OpenAI tool has, like, we have an out-of-the-box solution. We give you the tools. We use some knobs to customize things, but it's more of, like, a managed RAG service. So my recommendation would be, like, start with the OpenAI thing, see if it, like, meets your needs. And over time, we're going to be adding more and more knobs to make it even more customizable. But, you know, if you want, like, the completely custom thing, you want control over every single thing, then you'd probably want to go and hand roll it using other solutions. So we're supportive of both, like, engineers should pick. Yeah.Alessio [00:18:16]: And then we got computer use. Which I think Operator was obviously one of the hot releases of the year. And we're only two months in. Let's talk about that. And that's also, it seems like a separate model that has been fine-tuned for Operator that has browser access.Nikunj [00:18:31]: Yeah, absolutely. I mean, the computer use models are exciting. The cool thing about computer use is that we're just so, so early. It's like the GPT-2 of computer use or maybe GPT-1 of computer use right now. But it is a separate model that has been, you know, the computer. The computer use team has been working on, you send it screenshots and it tells you what action to take. So the outputs of it are almost always tool calls and you're inputting screenshots based on whatever computer you're trying to operate.Romain [00:19:01]: Maybe zooming out for a second, because like, I'm sure your audience is like super, super like AI native, obviously. But like, what is computer use as a tool, right? And what's operator? So the idea for computer use is like, how do we let developers also build agents that can complete tasks for the users, but using a computer? Okay. Or a browser instead. And so how do you get that done? And so that's why we have this custom model, like optimized for computer use that we use like for operator ourselves. But the idea behind like putting it as an API is that imagine like now you want to, you want to automate some tasks for your product or your own customers. Then now you can, you can have like the ability to spin up one of these agents that will look at the screen and act on the screen. So that means able, the ability to click, the ability to scroll. The ability to type and to report back on the action. So that's what we mean by computer use and wrapping it as a tool also in the responses API. So now like that gives a hint also at the multi-turned thing that we were hinting at earlier, the idea that like, yeah, maybe one of these actions can take a couple of minutes to complete because there's maybe like 20 steps to complete that task. But now you can.swyx [00:20:08]: Do you think a computer use can play Pokemon?Romain [00:20:11]: Oh, interesting. I guess we tried it. I guess we should try it. You know?swyx [00:20:17]: Yeah. There's a lot of interest. I think Pokemon really is a good agent benchmark, to be honest. Like it seems like Claude is, Claude is running into a lot of trouble.Romain [00:20:25]: Sounds like we should make that a new eval, it looks like.swyx [00:20:28]: Yeah. Yeah. Oh, and then one more, one more thing before we move on to agents SDK. I know you have a hard stop. There's all these, you know, blah, blah, dash preview, right? Like search preview, computer use preview, right? And you see them all like fine tunes of 4.0. I think the question is, are we, are they all going to be merged into the main branch or are we basically always going to have subsets? Of these models?Nikunj [00:20:49]: Yeah, I think in the early days, research teams at OpenAI like operate with like fine tune models. And then once the thing gets like more stable, we sort of merge it into the main line. So that's definitely the vision, like going out of preview as we get more comfortable with and learn about all the developer use cases and we're doing a good job at them. We'll sort of like make them part of like the core models so that you don't have to like deal with the bifurcation.Romain [00:21:12]: You should think of it this way as exactly what happened last year when we introduced vision capabilities, you know. Yes. Vision capabilities were in like a vision preview model based off of GPT-4 and then vision capabilities now are like obviously built into GPT-4.0. You can think about it the same way for like the other modalities like audio and those kind of like models, like optimized for search and computer use.swyx [00:21:34]: Agents SDK, we have a few minutes left. So let's just assume that everyone has looked at Swarm. Sure. I think that Swarm has really popularized the handoff technique, which I thought was like, you know, really, really interesting for sort of a multi-agent. What is new with the SDK?Nikunj [00:21:50]: Yeah. Do you want to start? Yeah, for sure. So we've basically added support for types. We've made this like a lot. Yeah. Like we've added support for types. We've added support for guard railing, which is a very common pattern. So in the guardrail example, you basically have two things happen in parallel. The guardrail can sort of block the execution. It's a type of like optimistic generation that happens. And I think we've added support for tracing. So I think that's really cool. So you can basically look at the traces that the Agents SDK creates in the OpenAI dashboard. We also like made this pretty flexible. So you can pick any API from any provider that supports the ChatCompletions API format. So it supports responses by default, but you can like easily plug it in to anyone that uses the ChatCompletions API. And similarly, on the tracing side, you can support like multiple tracing providers. By default, it sort of points to the OpenAI dashboard. But, you know, there's like so many tracing providers. There's so many tracing companies out there. And we'll announce some partnerships on that front, too. So just like, you know, adding lots of core features and making it more usable, but still centered around like handoffs is like the main, main concept.Romain [00:22:59]: And by the way, it's interesting, right? Because Swarm just came to life out of like learning from customers directly that like orchestrating agents in production was pretty hard. You know, simple ideas could quickly turn very complex. Like what are those guardrails? What are those handoffs, et cetera? So that came out of like learning from customers. And it was initially shipped. It was not as a like low-key experiment, I'd say. But we were kind of like taken by surprise at how much momentum there was around this concept. And so we decided to learn from that and embrace it. To be like, okay, maybe we should just embrace that as a core primitive of the OpenAI platform. And that's kind of what led to the Agents SDK. And I think now, as Nikuj mentioned, it's like adding all of these new capabilities to it, like leveraging the handoffs that we had, but tracing also. And I think what's very compelling for developers is like instead of having one agent to rule them all and you stuff like a lot of tool calls in there that can be hard to monitor, now you have the tools you need to kind of like separate the logic, right? And you can have a triage agent that based on an intent goes to different kind of agents. And then on the OpenAI dashboard, we're releasing a lot of new user interface logs as well. So you can see all of the tracing UIs. Essentially, you'll be able to troubleshoot like what exactly happened. In that workflow, when the triage agent did a handoff to a secondary agent and the third and see the tool calls, et cetera. So we think that the Agents SDK combined with the tracing UIs will definitely help users and developers build better agentic workflows.Alessio [00:24:28]: And just before we wrap, are you thinking of connecting this with also the RFT API? Because I know you already have, you kind of store my text completions and then I can do fine tuning of that. Is that going to be similar for agents where you're storing kind of like my traces? And then help me improve the agents?Nikunj [00:24:43]: Yeah, absolutely. Like you got to tie the traces to the evals product so that you can generate good evals. Once you have good evals and graders and tasks, you can use that to do reinforcement fine tuning. And, you know, lots of details to be figured out over here. But that's the vision. And I think we're going to go after it like pretty hard and hope we can like make this whole workflow a lot easier for developers.Alessio [00:25:05]: Awesome. Thank you so much for the time. I'm sure you'll be busy on Twitter tomorrow with all the developer feedback. Yeah.Romain [00:25:12]: Thank you so much for having us. And as always, we can't wait to see what developers will build with these tools and how we can like learn as quickly as we can from them to make them even better over time.Nikunj [00:25:21]: Yeah.Romain [00:25:22]: Thank you, guys.Nikunj [00:25:23]: Thank you.Romain [00:25:23]: Thank you both. Awesome. Get full access to Latent.Space at www.latent.space/subscribe
-
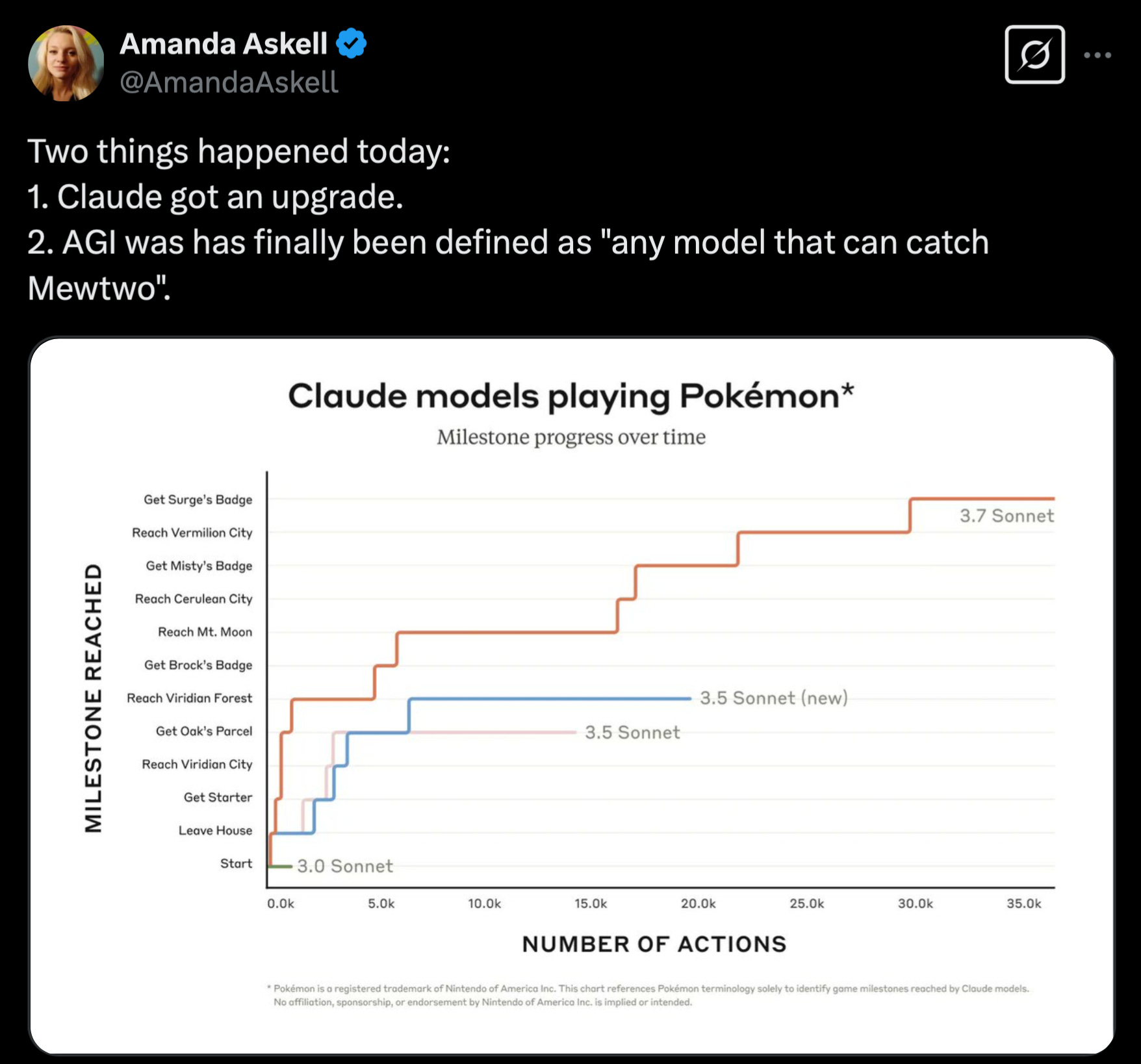 ⚡️How Claude 3.7 Plays Pokémon
⚡️How Claude 3.7 Plays PokémonFrom 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2025-03-04 01:00
Special lightning pod with David Hershey from Anthropic, the person behind Claude Plays Pokémon. Sonnet 3.7 is currently trying to complete Pokémon Red live on Twitch thanks to a special harness that David built so that it can see the screen, navigate through it, remember facts about the game, and more. (Since recording, it has successfully escaped Mt Moon! You can follow along on Twitch: https://www.twitch.tv/claudeplayspokemon) Get full access to Latent.Space at www.latent.space/subscribe
-
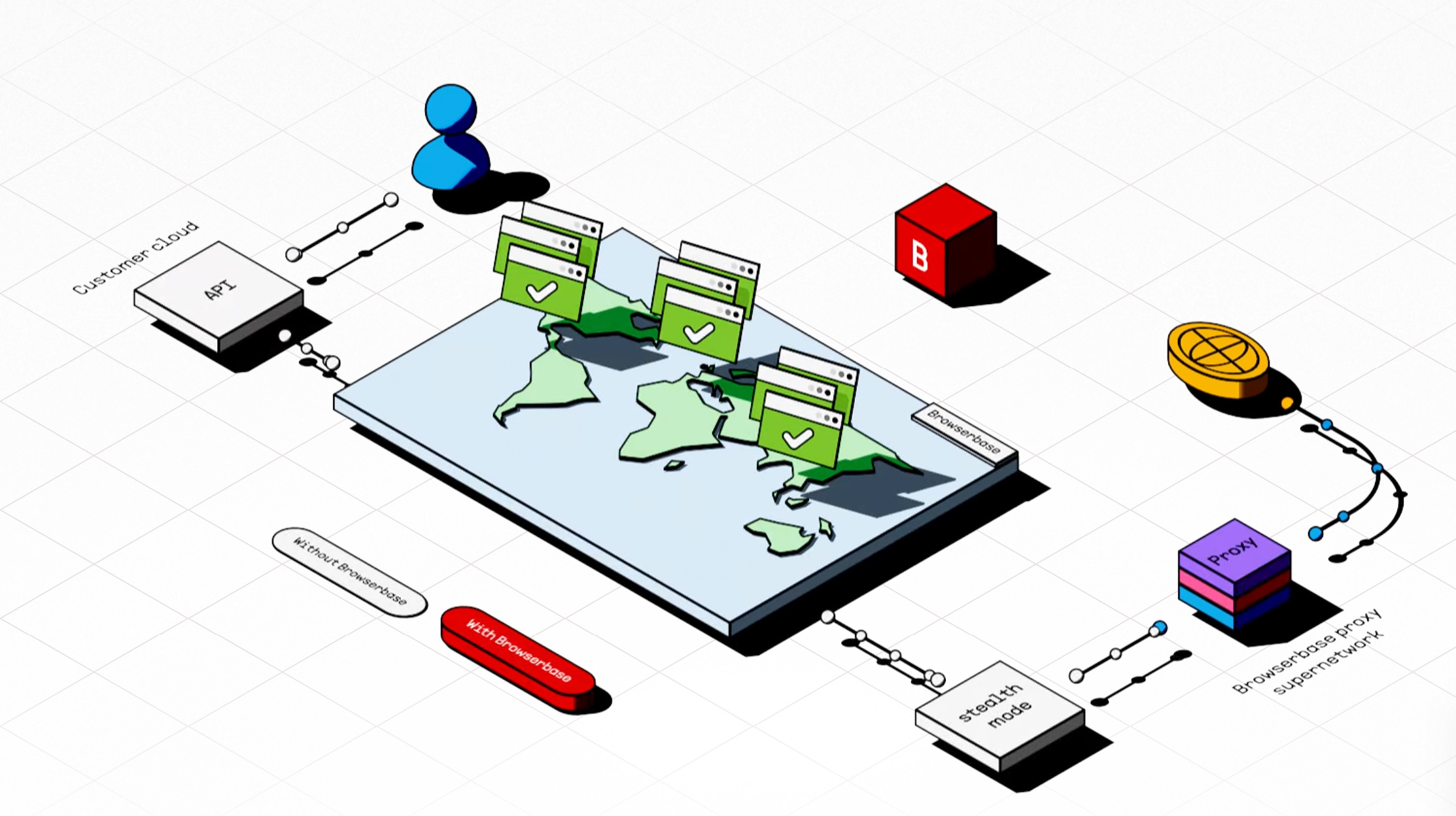 Open Operator, Serverless Browsers and the Future of Computer-Using Agents
Open Operator, Serverless Browsers and the Future of Computer-Using AgentsFrom 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2025-02-28 18:31
Today's episode is with Paul Klein, founder of Browserbase. We talked about building browser infrastructure for AI agents, the future of agent authentication, and their open source framework Stagehand.* [00:00:00] Introductions* [00:04:46] AI-specific challenges in browser infrastructure* [00:07:05] Multimodality in AI-Powered Browsing* [00:12:26] Running headless browsers at scale* [00:18:46] Geolocation when proxying* [00:21:25] CAPTCHAs and Agent Auth* [00:28:21] Building “User take over” functionality* [00:33:43] Stagehand: AI web browsing framework* [00:38:58] OpenAI's Operator and computer use agents* [00:44:44] Surprising use cases of Browserbase* [00:47:18] Future of browser automation and market competition* [00:53:11] Being a solo founderTranscriptAlessio [00:00:04]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol.ai.swyx [00:00:12]: Hey, and today we are very blessed to have our friends, Paul Klein, for the fourth, the fourth, CEO of Browserbase. Welcome.Paul [00:00:21]: Thanks guys. Yeah, I'm happy to be here. I've been lucky to know both of you for like a couple of years now, I think. So it's just like we're hanging out, you know, with three ginormous microphones in front of our face. It's totally normal hangout.swyx [00:00:34]: Yeah. We've actually mentioned you on the podcast, I think, more often than any other Solaris tenant. Just because like you're one of the, you know, best performing, I think, LLM tool companies that have started up in the last couple of years.Paul [00:00:50]: Yeah, I mean, it's been a whirlwind of a year, like Browserbase is actually pretty close to our first birthday. So we are one years old. And going from, you know, starting a company as a solo founder to... To, you know, having a team of 20 people, you know, a series A, but also being able to support hundreds of AI companies that are building AI applications that go out and automate the web. It's just been like, really cool. It's been happening a little too fast. I think like collectively as an AI industry, let's just take a week off together. I took my first vacation actually two weeks ago, and Operator came out on the first day, and then a week later, DeepSeat came out. And I'm like on vacation trying to chill. I'm like, we got to build with this stuff, right? So it's been a breakneck year. But I'm super happy to be here and like talk more about all the stuff we're seeing. And I'd love to hear kind of what you guys are excited about too, and share with it, you know?swyx [00:01:39]: Where to start? So people, you've done a bunch of podcasts. I think I strongly recommend Jack Bridger's Scaling DevTools, as well as Turner Novak's The Peel. And, you know, I'm sure there's others. So you covered your Twilio story in the past, talked about StreamClub, you got acquired to Mux, and then you left to start Browserbase. So maybe we just start with what is Browserbase? Yeah.Paul [00:02:02]: Browserbase is the web browser for your AI. We're building headless browser infrastructure, which are browsers that run in a server environment that's accessible to developers via APIs and SDKs. It's really hard to run a web browser in the cloud. You guys are probably running Chrome on your computers, and that's using a lot of resources, right? So if you want to run a web browser or thousands of web browsers, you can't just spin up a bunch of lambdas. You actually need to use a secure containerized environment. You have to scale it up and down. It's a stateful system. And that infrastructure is, like, super painful. And I know that firsthand, because at my last company, StreamClub, I was CTO, and I was building our own internal headless browser infrastructure. That's actually why we sold the company, is because Mux really wanted to buy our headless browser infrastructure that we'd built. And it's just a super hard problem. And I actually told my co-founders, I would never start another company unless it was a browser infrastructure company. And it turns out that's really necessary in the age of AI, when AI can actually go out and interact with websites, click on buttons, fill in forms. You need AI to do all of that work in an actual browser running somewhere on a server. And BrowserBase powers that.swyx [00:03:08]: While you're talking about it, it occurred to me, not that you're going to be acquired or anything, but it occurred to me that it would be really funny if you became the Nikita Beer of headless browser companies. You just have one trick, and you make browser companies that get acquired.Paul [00:03:23]: I truly do only have one trick. I'm screwed if it's not for headless browsers. I'm not a Go programmer. You know, I'm in AI grant. You know, browsers is an AI grant. But we were the only company in that AI grant batch that used zero dollars on AI spend. You know, we're purely an infrastructure company. So as much as people want to ask me about reinforcement learning, I might not be the best guy to talk about that. But if you want to ask about headless browser infrastructure at scale, I can talk your ear off. So that's really my area of expertise. And it's a pretty niche thing. Like, nobody has done what we're doing at scale before. So we're happy to be the experts.swyx [00:03:59]: You do have an AI thing, stagehand. We can talk about the sort of core of browser-based first, and then maybe stagehand. Yeah, stagehand is kind of the web browsing framework. Yeah.What is Browserbase? Headless Browser Infrastructure ExplainedAlessio [00:04:10]: Yeah. Yeah. And maybe how you got to browser-based and what problems you saw. So one of the first things I worked on as a software engineer was integration testing. Sauce Labs was kind of like the main thing at the time. And then we had Selenium, we had Playbrite, we had all these different browser things. But it's always been super hard to do. So obviously you've worked on this before. When you started browser-based, what were the challenges? What were the AI-specific challenges that you saw versus, there's kind of like all the usual running browser at scale in the cloud, which has been a problem for years. What are like the AI unique things that you saw that like traditional purchase just didn't cover? Yeah.AI-specific challenges in browser infrastructurePaul [00:04:46]: First and foremost, I think back to like the first thing I did as a developer, like as a kid when I was writing code, I wanted to write code that did stuff for me. You know, I wanted to write code to automate my life. And I do that probably by using curl or beautiful soup to fetch data from a web browser. And I think I still do that now that I'm in the cloud. And the other thing that I think is a huge challenge for me is that you can't just create a web site and parse that data. And we all know that now like, you know, taking HTML and plugging that into an LLM, you can extract insights, you can summarize. So it was very clear that now like dynamic web scraping became very possible with the rise of large language models or a lot easier. And that was like a clear reason why there's been more usage of headless browsers, which are necessary because a lot of modern websites don't expose all of their page content via a simple HTTP request. You know, they actually do require you to run this type of code for a specific time. JavaScript on the page to hydrate this. Airbnb is a great example. You go to airbnb.com. A lot of that content on the page isn't there until after they run the initial hydration. So you can't just scrape it with a curl. You need to have some JavaScript run. And a browser is that JavaScript engine that's going to actually run all those requests on the page. So web data retrieval was definitely one driver of starting BrowserBase and the rise of being able to summarize that within LLM. Also, I was familiar with if I wanted to automate a website, I could write one script and that would work for one website. It was very static and deterministic. But the web is non-deterministic. The web is always changing. And until we had LLMs, there was no way to write scripts that you could write once that would run on any website. That would change with the structure of the website. Click the login button. It could mean something different on many different websites. And LLMs allow us to generate code on the fly to actually control that. So I think that rise of writing the generic automation scripts that can work on many different websites, to me, made it clear that browsers are going to be a lot more useful because now you can automate a lot more things without writing. If you wanted to write a script to book a demo call on 100 websites, previously, you had to write 100 scripts. Now you write one script that uses LLMs to generate that script. That's why we built our web browsing framework, StageHand, which does a lot of that work for you. But those two things, web data collection and then enhanced automation of many different websites, it just felt like big drivers for more browser infrastructure that would be required to power these kinds of features.Alessio [00:07:05]: And was multimodality also a big thing?Paul [00:07:08]: Now you can use the LLMs to look, even though the text in the dome might not be as friendly. Maybe my hot take is I was always kind of like, I didn't think vision would be as big of a driver. For UI automation, I felt like, you know, HTML is structured text and large language models are good with structured text. But it's clear that these computer use models are often vision driven, and they've been really pushing things forward. So definitely being multimodal, like rendering the page is required to take a screenshot to give that to a computer use model to take actions on a website. And it's just another win for browser. But I'll be honest, that wasn't what I was thinking early on. I didn't even think that we'd get here so fast with multimodality. I think we're going to have to get back to multimodal and vision models.swyx [00:07:50]: This is one of those things where I forgot to mention in my intro that I'm an investor in Browserbase. And I remember that when you pitched to me, like a lot of the stuff that we have today, we like wasn't on the original conversation. But I did have my original thesis was something that we've talked about on the podcast before, which is take the GPT store, the custom GPT store, all the every single checkbox and plugin is effectively a startup. And this was the browser one. I think the main hesitation, I think I actually took a while to get back to you. The main hesitation was that there were others. Like you're not the first hit list browser startup. It's not even your first hit list browser startup. There's always a question of like, will you be the category winner in a place where there's a bunch of incumbents, to be honest, that are bigger than you? They're just not targeted at the AI space. They don't have the backing of Nat Friedman. And there's a bunch of like, you're here in Silicon Valley. They're not. I don't know.Paul [00:08:47]: I don't know if that's, that was it, but like, there was a, yeah, I mean, like, I think I tried all the other ones and I was like, really disappointed. Like my background is from working at great developer tools, companies, and nothing had like the Vercel like experience. Um, like our biggest competitor actually is partly owned by private equity and they just jacked up their prices quite a bit. And the dashboard hasn't changed in five years. And I actually used them at my last company and tried them and I was like, oh man, like there really just needs to be something that's like the experience of these great infrastructure companies, like Stripe, like clerk, like Vercel that I use in love, but oriented towards this kind of like more specific category, which is browser infrastructure, which is really technically complex. Like a lot of stuff can go wrong on the internet when you're running a browser. The internet is very vast. There's a lot of different configurations. Like there's still websites that only work with internet explorer out there. How do you handle that when you're running your own browser infrastructure? These are the problems that we have to think about and solve at BrowserBase. And it's, it's certainly a labor of love, but I built this for me, first and foremost, I know it's super cheesy and everyone says that for like their startups, but it really, truly was for me. If you look at like the talks I've done even before BrowserBase, and I'm just like really excited to try and build a category defining infrastructure company. And it's, it's rare to have a new category of infrastructure exists. We're here in the Chroma offices and like, you know, vector databases is a new category of infrastructure. Is it, is it, I mean, we can, we're in their office, so, you know, we can, we can debate that one later. That is one.Multimodality in AI-Powered Browsingswyx [00:10:16]: That's one of the industry debates.Paul [00:10:17]: I guess we go back to the LLMOS talk that Karpathy gave way long ago. And like the browser box was very clearly there and it seemed like the people who were building in this space also agreed that browsers are a core primitive of infrastructure for the LLMOS that's going to exist in the future. And nobody was building something there that I wanted to use. So I had to go build it myself.swyx [00:10:38]: Yeah. I mean, exactly that talk that, that honestly, that diagram, every box is a startup and there's the code box and then there's the. The browser box. I think at some point they will start clashing there. There's always the question of the, are you a point solution or are you the sort of all in one? And I think the point solutions tend to win quickly, but then the only ones have a very tight cohesive experience. Yeah. Let's talk about just the hard problems of browser base you have on your website, which is beautiful. Thank you. Was there an agency that you used for that? Yeah. Herb.paris.Paul [00:11:11]: They're amazing. Herb.paris. Yeah. It's H-E-R-V-E. I highly recommend for developers. Developer tools, founders to work with consumer agencies because they end up building beautiful things and the Parisians know how to build beautiful interfaces. So I got to give prep.swyx [00:11:24]: And chat apps, apparently are, they are very fast. Oh yeah. The Mistral chat. Yeah. Mistral. Yeah.Paul [00:11:31]: Late chat.swyx [00:11:31]: Late chat. And then your videos as well, it was professionally shot, right? The series A video. Yeah.Alessio [00:11:36]: Nico did the videos. He's amazing. Not the initial video that you shot at the new one. First one was Austin.Paul [00:11:41]: Another, another video pretty surprised. But yeah, I mean, like, I think when you think about how you talk about your company. You have to think about the way you present yourself. It's, you know, as a developer, you think you evaluate a company based on like the API reliability and the P 95, but a lot of developers say, is the website good? Is the message clear? Do I like trust this founder? I'm building my whole feature on. So I've tried to nail that as well as like the reliability of the infrastructure. You're right. It's very hard. And there's a lot of kind of foot guns that you run into when running headless browsers at scale. Right.Competing with Existing Headless Browser Solutionsswyx [00:12:10]: So let's pick one. You have eight features here. Seamless integration. Scalability. Fast or speed. Secure. Observable. Stealth. That's interesting. Extensible and developer first. What comes to your mind as like the top two, three hardest ones? Yeah.Running headless browsers at scalePaul [00:12:26]: I think just running headless browsers at scale is like the hardest one. And maybe can I nerd out for a second? Is that okay? I heard this is a technical audience, so I'll talk to the other nerds. Whoa. They were listening. Yeah. They're upset. They're ready. The AGI is angry. Okay. So. So how do you run a browser in the cloud? Let's start with that, right? So let's say you're using a popular browser automation framework like Puppeteer, Playwright, and Selenium. Maybe you've written a code, some code locally on your computer that opens up Google. It finds the search bar and then types in, you know, search for Latent Space and hits the search button. That script works great locally. You can see the little browser open up. You want to take that to production. You want to run the script in a cloud environment. So when your laptop is closed, your browser is doing something. The browser is doing something. Well, I, we use Amazon. You can see the little browser open up. You know, the first thing I'd reach for is probably like some sort of serverless infrastructure. I would probably try and deploy on a Lambda. But Chrome itself is too big to run on a Lambda. It's over 250 megabytes. So you can't easily start it on a Lambda. So you maybe have to use something like Lambda layers to squeeze it in there. Maybe use a different Chromium build that's lighter. And you get it on the Lambda. Great. It works. But it runs super slowly. It's because Lambdas are very like resource limited. They only run like with one vCPU. You can run one process at a time. Remember, Chromium is super beefy. It's barely running on my MacBook Air. I'm still downloading it from a pre-run. Yeah, from the test earlier, right? I'm joking. But it's big, you know? So like Lambda, it just won't work really well. Maybe it'll work, but you need something faster. Your users want something faster. Okay. Well, let's put it on a beefier instance. Let's get an EC2 server running. Let's throw Chromium on there. Great. Okay. I can, that works well with one user. But what if I want to run like 10 Chromium instances, one for each of my users? Okay. Well, I might need two EC2 instances. Maybe 10. All of a sudden, you have multiple EC2 instances. This sounds like a problem for Kubernetes and Docker, right? Now, all of a sudden, you're using ECS or EKS, the Kubernetes or container solutions by Amazon. You're spending up and down containers, and you're spending a whole engineer's time on kind of maintaining this stateful distributed system. Those are some of the worst systems to run because when it's a stateful distributed system, it means that you are bound by the connections to that thing. You have to keep the browser open while someone is working with it, right? That's just a painful architecture to run. And there's all this other little gotchas with Chromium, like Chromium, which is the open source version of Chrome, by the way. You have to install all these fonts. You want emojis working in your browsers because your vision model is looking for the emoji. You need to make sure you have the emoji fonts. You need to make sure you have all the right extensions configured, like, oh, do you want ad blocking? How do you configure that? How do you actually record all these browser sessions? Like it's a headless browser. You can't look at it. So you need to have some sort of observability. Maybe you're recording videos and storing those somewhere. It all kind of adds up to be this just giant monster piece of your project when all you wanted to do was run a lot of browsers in production for this little script to go to google.com and search. And when I see a complex distributed system, I see an opportunity to build a great infrastructure company. And we really abstract that away with Browserbase where our customers can use these existing frameworks, Playwright, Publisher, Selenium, or our own stagehand and connect to our browsers in a serverless-like way. And control them, and then just disconnect when they're done. And they don't have to think about the complex distributed system behind all of that. They just get a browser running anywhere, anytime. Really easy to connect to.swyx [00:15:55]: I'm sure you have questions. My standard question with anything, so essentially you're a serverless browser company, and there's been other serverless things that I'm familiar with in the past, serverless GPUs, serverless website hosting. That's where I come from with Netlify. One question is just like, you promised to spin up thousands of servers. You promised to spin up thousands of browsers in milliseconds. I feel like there's no real solution that does that yet. And I'm just kind of curious how. The only solution I know, which is to kind of keep a kind of warm pool of servers around, which is expensive, but maybe not so expensive because it's just CPUs. So I'm just like, you know. Yeah.Browsers as a Core Primitive in AI InfrastructurePaul [00:16:36]: You nailed it, right? I mean, how do you offer a serverless-like experience with something that is clearly not serverless, right? And the answer is, you need to be able to run... We run many browsers on single nodes. We use Kubernetes at browser base. So we have many pods that are being scheduled. We have to predictably schedule them up or down. Yes, thousands of browsers in milliseconds is the best case scenario. If you hit us with 10,000 requests, you may hit a slower cold start, right? So we've done a lot of work on predictive scaling and being able to kind of route stuff to different regions where we have multiple regions of browser base where we have different pools available. You can also pick the region you want to go to based on like lower latency, round trip, time latency. It's very important with these types of things. There's a lot of requests going over the wire. So for us, like having a VM like Firecracker powering everything under the hood allows us to be super nimble and spin things up or down really quickly with strong multi-tenancy. But in the end, this is like the complex infrastructural challenges that we have to kind of deal with at browser base. And we have a lot more stuff on our roadmap to allow customers to have more levers to pull to exchange, do you want really fast browser startup times or do you want really low costs? And if you're willing to be more flexible on that, we may be able to kind of like work better for your use cases.swyx [00:17:44]: Since you used Firecracker, shouldn't Fargate do that for you or did you have to go lower level than that? We had to go lower level than that.Paul [00:17:51]: I find this a lot with Fargate customers, which is alarming for Fargate. We used to be a giant Fargate customer. Actually, the first version of browser base was ECS and Fargate. And unfortunately, it's a great product. I think we were actually the largest Fargate customer in our region for a little while. No, what? Yeah, seriously. And unfortunately, it's a great product, but I think if you're an infrastructure company, you actually have to have a deeper level of control over these primitives. I think it's the same thing is true with databases. We've used other database providers and I think-swyx [00:18:21]: Yeah, serverless Postgres.Paul [00:18:23]: Shocker. When you're an infrastructure company, you're on the hook if any provider has an outage. And I can't tell my customers like, hey, we went down because so-and-so went down. That's not acceptable. So for us, we've really moved to bringing things internally. It's kind of opposite of what we preach. We tell our customers, don't build this in-house, but then we're like, we build a lot of stuff in-house. But I think it just really depends on what is in the critical path. We try and have deep ownership of that.Alessio [00:18:46]: On the distributed location side, how does that work for the web where you might get sort of different content in different locations, but the customer is expecting, you know, if you're in the US, I'm expecting the US version. But if you're spinning up my browser in France, I might get the French version. Yeah.Paul [00:19:02]: Yeah. That's a good question. Well, generally, like on the localization, there is a thing called locale in the browser. You can set like what your locale is. If you're like in the ENUS browser or not, but some things do IP, IP based routing. And in that case, you may want to have a proxy. Like let's say you're running something in the, in Europe, but you want to make sure you're showing up from the US. You may want to use one of our proxy features so you can turn on proxies to say like, make sure these connections always come from the United States, which is necessary too, because when you're browsing the web, you're coming from like a, you know, data center IP, and that can make things a lot harder to browse web. So we do have kind of like this proxy super network. Yeah. We have a proxy for you based on where you're going, so you can reliably automate the web. But if you get scheduled in Europe, that doesn't happen as much. We try and schedule you as close to, you know, your origin that you're trying to go to. But generally you have control over the regions you can put your browsers in. So you can specify West one or East one or Europe. We only have one region of Europe right now, actually. Yeah.Alessio [00:19:55]: What's harder, the browser or the proxy? I feel like to me, it feels like actually proxying reliably at scale. It's much harder than spending up browsers at scale. I'm curious. It's all hard.Paul [00:20:06]: It's layers of hard, right? Yeah. I think it's different levels of hard. I think the thing with the proxy infrastructure is that we work with many different web proxy providers and some are better than others. Some have good days, some have bad days. And our customers who've built browser infrastructure on their own, they have to go and deal with sketchy actors. Like first they figure out their own browser infrastructure and then they got to go buy a proxy. And it's like you can pay in Bitcoin and it just kind of feels a little sus, right? It's like you're buying drugs when you're trying to get a proxy online. We have like deep relationships with these counterparties. We're able to audit them and say, is this proxy being sourced ethically? Like it's not running on someone's TV somewhere. Is it free range? Yeah. Free range organic proxies, right? Right. We do a level of diligence. We're SOC 2. So we have to understand what is going on here. But then we're able to make sure that like we route around proxy providers not working. There's proxy providers who will just, the proxy will stop working all of a sudden. And then if you don't have redundant proxying on your own browsers, that's hard down for you or you may get some serious impacts there. With us, like we intelligently know, hey, this proxy is not working. Let's go to this one. And you can kind of build a network of multiple providers to really guarantee the best uptime for our customers. Yeah. So you don't own any proxies? We don't own any proxies. You're right. The team has been saying who wants to like take home a little proxy server, but not yet. We're not there yet. You know?swyx [00:21:25]: It's a very mature market. I don't think you should build that yourself. Like you should just be a super customer of them. Yeah. Scraping, I think, is the main use case for that. I guess. Well, that leads us into CAPTCHAs and also off, but let's talk about CAPTCHAs. You had a little spiel that you wanted to talk about CAPTCHA stuff.Challenges of Scaling Browser InfrastructurePaul [00:21:43]: Oh, yeah. I was just, I think a lot of people ask, if you're thinking about proxies, you're thinking about CAPTCHAs too. I think it's the same thing. You can go buy CAPTCHA solvers online, but it's the same buying experience. It's some sketchy website, you have to integrate it. It's not fun to buy these things and you can't really trust that the docs are bad. What Browserbase does is we integrate a bunch of different CAPTCHAs. We do some stuff in-house, but generally we just integrate with a bunch of known vendors and continually monitor and maintain these things and say, is this working or not? Can we route around it or not? These are CAPTCHA solvers. CAPTCHA solvers, yeah. Not CAPTCHA providers, CAPTCHA solvers. Yeah, sorry. CAPTCHA solvers. We really try and make sure all of that works for you. I think as a dev, if I'm buying infrastructure, I want it all to work all the time and it's important for us to provide that experience by making sure everything does work and monitoring it on our own. Yeah. Right now, the world of CAPTCHAs is tricky. I think AI agents in particular are very much ahead of the internet infrastructure. CAPTCHAs are designed to block all types of bots, but there are now good bots and bad bots. I think in the future, CAPTCHAs will be able to identify who a good bot is, hopefully via some sort of KYC. For us, we've been very lucky. We have very little to no known abuse of Browserbase because we really look into who we work with. And for certain types of CAPTCHA solving, we only allow them on certain types of plans because we want to make sure that we can know what people are doing, what their use cases are. And that's really allowed us to try and be an arbiter of good bots, which is our long term goal. I want to build great relationships with people like Cloudflare so we can agree, hey, here are these acceptable bots. We'll identify them for you and make sure we flag when they come to your website. This is a good bot, you know?Alessio [00:23:23]: I see. And Cloudflare said they want to do more of this. So they're going to set by default, if they think you're an AI bot, they're going to reject. I'm curious if you think this is something that is going to be at the browser level or I mean, the DNS level with Cloudflare seems more where it should belong. But I'm curious how you think about it.Paul [00:23:40]: I think the web's going to change. You know, I think that the Internet as we have it right now is going to change. And we all need to just accept that the cat is out of the bag. And instead of kind of like wishing the Internet was like it was in the 2000s, we can have free content line that wouldn't be scraped. It's just it's not going to happen. And instead, we should think about like, one, how can we change? How can we change the models of, you know, information being published online so people can adequately commercialize it? But two, how do we rebuild applications that expect that AI agents are going to log in on their behalf? Those are the things that are going to allow us to kind of like identify good and bad bots. And I think the team at Clerk has been doing a really good job with this on the authentication side. I actually think that auth is the biggest thing that will prevent agents from accessing stuff, not captchas. And I think there will be agent auth in the future. I don't know if it's going to happen from an individual company, but actually authentication providers that have a, you know, hidden login as agent feature, which will then you put in your email, you'll get a push notification, say like, hey, your browser-based agent wants to log into your Airbnb. You can approve that and then the agent can proceed. That really circumvents the need for captchas or logging in as you and sharing your password. I think agent auth is going to be one way we identify good bots going forward. And I think a lot of this captcha solving stuff is really short-term problems as the internet kind of reorients itself around how it's going to work with agents browsing the web, just like people do. Yeah.Managing Distributed Browser Locations and Proxiesswyx [00:24:59]: Stitch recently was on Hacker News for talking about agent experience, AX, which is a thing that Netlify is also trying to clone and coin and talk about. And we've talked about this on our previous episodes before in a sense that I actually think that's like maybe the only part of the tech stack that needs to be kind of reinvented for agents. Everything else can stay the same, CLIs, APIs, whatever. But auth, yeah, we need agent auth. And it's mostly like short-lived, like it should not, it should be a distinct, identity from the human, but paired. I almost think like in the same way that every social network should have your main profile and then your alt accounts or your Finsta, it's almost like, you know, every, every human token should be paired with the agent token and the agent token can go and do stuff on behalf of the human token, but not be presumed to be the human. Yeah.Paul [00:25:48]: It's like, it's, it's actually very similar to OAuth is what I'm thinking. And, you know, Thread from Stitch is an investor, Colin from Clerk, Octaventures, all investors in browser-based because like, I hope they solve this because they'll make browser-based submission more possible. So we don't have to overcome all these hurdles, but I think it will be an OAuth-like flow where an agent will ask to log in as you, you'll approve the scopes. Like it can book an apartment on Airbnb, but it can't like message anybody. And then, you know, the agent will have some sort of like role-based access control within an application. Yeah. I'm excited for that.swyx [00:26:16]: The tricky part is just, there's one, one layer of delegation here, which is like, you're authoring my user's user or something like that. I don't know if that's tricky or not. Does that make sense? Yeah.Paul [00:26:25]: You know, actually at Twilio, I worked on the login identity and access. Management teams, right? So like I built Twilio's login page.swyx [00:26:31]: You were an intern on that team and then you became the lead in two years? Yeah.Paul [00:26:34]: Yeah. I started as an intern in 2016 and then I was the tech lead of that team. How? That's not normal. I didn't have a life. He's not normal. Look at this guy. I didn't have a girlfriend. I just loved my job. I don't know. I applied to 500 internships for my first job and I got rejected from every single one of them except for Twilio and then eventually Amazon. And they took a shot on me and like, I was getting paid money to write code, which was my dream. Yeah. Yeah. I'm very lucky that like this coding thing worked out because I was going to be doing it regardless. And yeah, I was able to kind of spend a lot of time on a team that was growing at a company that was growing. So it informed a lot of this stuff here. I think these are problems that have been solved with like the SAML protocol with SSO. I think it's a really interesting stuff with like WebAuthn, like these different types of authentication, like schemes that you can use to authenticate people. The tooling is all there. It just needs to be tweaked a little bit to work for agents. And I think the fact that there are companies that are already. Providing authentication as a service really sets it up. Well, the thing that's hard is like reinventing the internet for agents. We don't want to rebuild the internet. That's an impossible task. And I think people often say like, well, we'll have this second layer of APIs built for agents. I'm like, we will for the top use cases, but instead of we can just tweak the internet as is, which is on the authentication side, I think we're going to be the dumb ones going forward. Unfortunately, I think AI is going to be able to do a lot of the tasks that we do online, which means that it will be able to go to websites, click buttons on our behalf and log in on our behalf too. So with this kind of like web agent future happening, I think with some small structural changes, like you said, it feels like it could all slot in really nicely with the existing internet.Handling CAPTCHAs and Agent Authenticationswyx [00:28:08]: There's one more thing, which is the, your live view iframe, which lets you take, take control. Yeah. Obviously very key for operator now, but like, was, is there anything interesting technically there or that the people like, well, people always want this.Paul [00:28:21]: It was really hard to build, you know, like, so, okay. Headless browsers, you don't see them, right. They're running. They're running in a cloud somewhere. You can't like look at them. And I just want to really make, it's a weird name. I wish we came up with a better name for this thing, but you can't see them. Right. But customers don't trust AI agents, right. At least the first pass. So what we do with our live view is that, you know, when you use browser base, you can actually embed a live view of the browser running in the cloud for your customer to see it working. And that's what the first reason is the build trust, like, okay, so I have this script. That's going to go automate a website. I can embed it into my web application via an iframe and my customer can watch. I think. And then we added two way communication. So now not only can you watch the browser kind of being operated by AI, if you want to pause and actually click around type within this iframe that's controlling a browser, that's also possible. And this is all thanks to some of the lower level protocol, which is called the Chrome DevTools protocol. It has a API called start screencast, and you can also send mouse clicks and button clicks to a remote browser. And this is all embeddable within iframes. You have a browser within a browser, yo. And then you simulate the screen, the click on the other side. Exactly. And this is really nice often for, like, let's say, a capture that can't be solved. You saw this with Operator, you know, Operator actually uses a different approach. They use VNC. So, you know, you're able to see, like, you're seeing the whole window here. What we're doing is something a little lower level with the Chrome DevTools protocol. It's just PNGs being streamed over the wire. But the same thing is true, right? Like, hey, I'm running a window. Pause. Can you do something in this window? Human. Okay, great. Resume. Like sometimes 2FA tokens. Like if you get that text message, you might need a person to type that in. Web agents need human-in-the-loop type workflows still. You still need a person to interact with the browser. And building a UI to proxy that is kind of hard. You may as well just show them the whole browser and say, hey, can you finish this up for me? And then let the AI proceed on afterwards. Is there a future where I stream my current desktop to browser base? I don't think so. I think we're very much cloud infrastructure. Yeah. You know, but I think a lot of the stuff we're doing, we do want to, like, build tools. Like, you know, we'll talk about the stage and, you know, web agent framework in a second. But, like, there's a case where a lot of people are going desktop first for, you know, consumer use. And I think cloud is doing a lot of this, where I expect to see, you know, MCPs really oriented around the cloud desktop app for a reason, right? Like, I think a lot of these tools are going to run on your computer because it makes... I think it's breaking out. People are putting it on a server. Oh, really? Okay. Well, sweet. We'll see. We'll see that. I was surprised, though, wasn't I? I think that the browser company, too, with Dia Browser, it runs on your machine. You know, it's going to be...swyx [00:30:50]: What is it?Paul [00:30:51]: So, Dia Browser, as far as I understand... I used to use Arc. Yeah. I haven't used Arc. But I'm a big fan of the browser company. I think they're doing a lot of cool stuff in consumer. As far as I understand, it's a browser where you have a sidebar where you can, like, chat with it and it can control the local browser on your machine. So, if you imagine, like, what a consumer web agent is, which it lives alongside your browser, I think Google Chrome has Project Marina, I think. I almost call it Project Marinara for some reason. I don't know why. It's...swyx [00:31:17]: No, I think it's someone really likes the Waterworld. Oh, I see. The classic Kevin Costner. Yeah.Paul [00:31:22]: Okay. Project Marinara is a similar thing to the Dia Browser, in my mind, as far as I understand it. You have a browser that has an AI interface that will take over your mouse and keyboard and control the browser for you. Great for consumer use cases. But if you're building applications that rely on a browser and it's more part of a greater, like, AI app experience, you probably need something that's more like infrastructure, not a consumer app.swyx [00:31:44]: Just because I have explored a little bit in this area, do people want branching? So, I have the state. Of whatever my browser's in. And then I want, like, 100 clones of this state. Do people do that? Or...Paul [00:31:56]: People don't do it currently. Yeah. But it's definitely something we're thinking about. I think the idea of forking a browser is really cool. Technically, kind of hard. We're starting to see this in code execution, where people are, like, forking some, like, code execution, like, processes or forking some tool calls or branching tool calls. Haven't seen it at the browser level yet. But it makes sense. Like, if an AI agent is, like, using a website and it's not sure what path it wants to take to crawl this website. To find the information it's looking for. It would make sense for it to explore both paths in parallel. And that'd be a very, like... A road not taken. Yeah. And hopefully find the right answer. And then say, okay, this was actually the right one. And memorize that. And go there in the future. On the roadmap. For sure. Don't make my roadmap, please. You know?Alessio [00:32:37]: How do you actually do that? Yeah. How do you fork? I feel like the browser is so stateful for so many things.swyx [00:32:42]: Serialize the state. Restore the state. I don't know.Paul [00:32:44]: So, it's one of the reasons why we haven't done it yet. It's hard. You know? Like, to truly fork, it's actually quite difficult. The naive way is to open the same page in a new tab and then, like, hope that it's at the same thing. But if you have a form halfway filled, you may have to, like, take the whole, you know, container. Pause it. All the memory. Duplicate it. Restart it from there. It could be very slow. So, we haven't found a thing. Like, the easy thing to fork is just, like, copy the page object. You know? But I think there needs to be something a little bit more robust there. Yeah.swyx [00:33:12]: So, MorphLabs has this infinite branch thing. Like, wrote a custom fork of Linux or something that let them save the system state and clone it. MorphLabs, hit me up. I'll be a customer. Yeah. That's the only. I think that's the only way to do it. Yeah. Like, unless Chrome has some special API for you. Yeah.Paul [00:33:29]: There's probably something we'll reverse engineer one day. I don't know. Yeah.Alessio [00:33:32]: Let's talk about StageHand, the AI web browsing framework. You have three core components, Observe, Extract, and Act. Pretty clean landing page. What was the idea behind making a framework? Yeah.Stagehand: AI web browsing frameworkPaul [00:33:43]: So, there's three frameworks that are very popular or already exist, right? Puppeteer, Playwright, Selenium. Those are for building hard-coded scripts to control websites. And as soon as I started to play with LLMs plus browsing, I caught myself, you know, code-genning Playwright code to control a website. I would, like, take the DOM. I'd pass it to an LLM. I'd say, can you generate the Playwright code to click the appropriate button here? And it would do that. And I was like, this really should be part of the frameworks themselves. And I became really obsessed with SDKs that take natural language as part of, like, the API input. And that's what StageHand is. StageHand exposes three APIs, and it's a super set of Playwright. So, if you go to a page, you may want to take an action, click on the button, fill in the form, etc. That's what the act command is for. You may want to extract some data. This one takes a natural language, like, extract the winner of the Super Bowl from this page. You can give it a Zod schema, so it returns a structured output. And then maybe you're building an API. You can do an agent loop, and you want to kind of see what actions are possible on this page before taking one. You can do observe. So, you can observe the actions on the page, and it will generate a list of actions. You can guide it, like, give me actions on this page related to buying an item. And you can, like, buy it now, add to cart, view shipping options, and pass that to an LLM, an agent loop, to say, what's the appropriate action given this high-level goal? So, StageHand isn't a web agent. It's a framework for building web agents. And we think that agent loops are actually pretty close to the application layer because every application probably has different goals or different ways it wants to take steps. I don't think I've seen a generic. Maybe you guys are the experts here. I haven't seen, like, a really good AI agent framework here. Everyone kind of has their own special sauce, right? I see a lot of developers building their own agent loops, and they're using tools. And I view StageHand as the browser tool. So, we expose act, extract, observe. Your agent can call these tools. And from that, you don't have to worry about it. You don't have to worry about generating playwright code performantly. You don't have to worry about running it. You can kind of just integrate these three tool calls into your agent loop and reliably automate the web.swyx [00:35:48]: A special shout-out to Anirudh, who I met at your dinner, who I think listens to the pod. Yeah. Hey, Anirudh.Paul [00:35:54]: Anirudh's a man. He's a StageHand guy.swyx [00:35:56]: I mean, the interesting thing about each of these APIs is they're kind of each startup. Like, specifically extract, you know, Firecrawler is extract. There's, like, Expand AI. There's a whole bunch of, like, extract companies. They just focus on extract. I'm curious. Like, I feel like you guys are going to collide at some point. Like, right now, it's friendly. Everyone's in a blue ocean. At some point, it's going to be valuable enough that there's some turf battle here. I don't think you have a dog in a fight. I think you can mock extract to use an external service if they're better at it than you. But it's just an observation that, like, in the same way that I see each option, each checkbox in the side of custom GBTs becoming a startup or each box in the Karpathy chart being a startup. Like, this is also becoming a thing. Yeah.Paul [00:36:41]: I mean, like, so the way StageHand works is that it's MIT-licensed, completely open source. You bring your own API key to your LLM of choice. You could choose your LLM. We don't make any money off of the extract or really. We only really make money if you choose to run it with our browser. You don't have to. You can actually use your own browser, a local browser. You know, StageHand is completely open source for that reason. And, yeah, like, I think if you're building really complex web scraping workflows, I don't know if StageHand is the tool for you. I think it's really more if you're building an AI agent that needs a few general tools or if it's doing a lot of, like, web automation-intensive work. But if you're building a scraping company, StageHand is not your thing. You probably want something that's going to, like, get HTML content, you know, convert that to Markdown, query it. That's not what StageHand does. StageHand is more about reliability. I think we focus a lot on reliability and less so on cost optimization and speed at this point.swyx [00:37:33]: I actually feel like StageHand, so the way that StageHand works, it's like, you know, page.act, click on the quick start. Yeah. It's kind of the integration test for the code that you would have to write anyway, like the Puppeteer code that you have to write anyway. And when the page structure changes, because it always does, then this is still the test. This is still the test that I would have to write. Yeah. So it's kind of like a testing framework that doesn't need implementation detail.Paul [00:37:56]: Well, yeah. I mean, Puppeteer, Playwright, and Slenderman were all designed as testing frameworks, right? Yeah. And now people are, like, hacking them together to automate the web. I would say, and, like, maybe this is, like, me being too specific. But, like, when I write tests, if the page structure changes. Without me knowing, I want that test to fail. So I don't know if, like, AI, like, regenerating that. Like, people are using StageHand for testing. But it's more for, like, usability testing, not, like, testing of, like, does the front end, like, has it changed or not. Okay. But generally where we've seen people, like, really, like, take off is, like, if they're using, you know, something. If they want to build a feature in their application that's kind of like Operator or Deep Research, they're using StageHand to kind of power that tool calling in their own agent loop. Okay. Cool.swyx [00:38:37]: So let's go into Operator, the first big agent launch of the year from OpenAI. Seems like they have a whole bunch scheduled. You were on break and your phone blew up. What's your just general view of computer use agents is what they're calling it. The overall category before we go into Open Operator, just the overall promise of Operator. I will observe that I tried it once. It was okay. And I never tried it again.OpenAI's Operator and computer use agentsPaul [00:38:58]: That tracks with my experience, too. Like, I'm a huge fan of the OpenAI team. Like, I think that I do not view Operator as the company. I'm not a company killer for browser base at all. I think it actually shows people what's possible. I think, like, computer use models make a lot of sense. And I'm actually most excited about computer use models is, like, their ability to, like, really take screenshots and reasoning and output steps. I think that using mouse click or mouse coordinates, I've seen that proved to be less reliable than I would like. And I just wonder if that's the right form factor. What we've done with our framework is anchor it to the DOM itself, anchor it to the actual item. So, like, if it's clicking on something, it's clicking on that thing, you know? Like, it's more accurate. No matter where it is. Yeah, exactly. Because it really ties in nicely. And it can handle, like, the whole viewport in one go, whereas, like, Operator can only handle what it sees. Can you hover? Is hovering a thing that you can do? I don't know if we expose it as a tool directly, but I'm sure there's, like, an API for hovering. Like, move mouse to this position. Yeah, yeah, yeah. I think you can trigger hover, like, via, like, the JavaScript on the DOM itself. But, no, I think, like, when we saw computer use, everyone's eyes lit up because they realized, like, wow, like, AI is going to actually automate work for people. And I think seeing that kind of happen from both of the labs, and I'm sure we're going to see more labs launch computer use models, I'm excited to see all the stuff that people build with it. I think that I'd love to see computer use power, like, controlling a browser on browser base. And I think, like, Open Operator, which was, like, our open source version of OpenAI's Operator, was our first take on, like, how can we integrate these models into browser base? And we handle the infrastructure and let the labs do the models. I don't have a sense that Operator will be released as an API. I don't know. Maybe it will. I'm curious to see how well that works because I think it's going to be really hard for a company like OpenAI to do things like support CAPTCHA solving or, like, have proxies. Like, I think it's hard for them structurally. Imagine this New York Times headline, OpenAI CAPTCHA solving. Like, that would be a pretty bad headline, this New York Times headline. Browser base solves CAPTCHAs. No one cares. No one cares. And, like, our investors are bored. Like, we're all okay with this, you know? We're building this company knowing that the CAPTCHA solving is short-lived until we figure out how to authenticate good bots. I think it's really hard for a company like OpenAI, who has this brand that's so, so good, to balance with, like, the icky parts of web automation, which it can be kind of complex to solve. I'm sure OpenAI knows who to call whenever they need you. Yeah, right. I'm sure they'll have a great partnership.Alessio [00:41:23]: And is Open Operator just, like, a marketing thing for you? Like, how do you think about resource allocation? So, you can spin this up very quickly. And now there's all this, like, open deep research, just open all these things that people are building. We started it, you know. You're the original Open. We're the original Open operator, you know? Is it just, hey, look, this is a demo, but, like, we'll help you build out an actual product for yourself? Like, are you interested in going more of a product route? That's kind of the OpenAI way, right? They started as a model provider and then…Paul [00:41:53]: Yeah, we're not interested in going the product route yet. I view Open Operator as a model provider. It's a reference project, you know? Let's show people how to build these things using the infrastructure and models that are out there. And that's what it is. It's, like, Open Operator is very simple. It's an agent loop. It says, like, take a high-level goal, break it down into steps, use tool calling to accomplish those steps. It takes screenshots and feeds those screenshots into an LLM with the step to generate the right action. It uses stagehand under the hood to actually execute this action. It doesn't use a computer use model. And it, like, has a nice interface using the live view that we talked about, the iframe, to embed that into an application. So I felt like people on launch day wanted to figure out how to build their own version of this. And we turned that around really quickly to show them. And I hope we do that with other things like deep research. We don't have a deep research launch yet. I think David from AOMNI actually has an amazing open deep research that he launched. It has, like, 10K GitHub stars now. So he's crushing that. But I think if people want to build these features natively into their application, they need good reference projects. And I think Open Operator is a good example of that.swyx [00:42:52]: I don't know. Actually, I'm actually pretty bullish on API-driven operator. Because that's the only way that you can sort of, like, once it's reliable enough, obviously. And now we're nowhere near. But, like, give it five years. It'll happen, you know. And then you can sort of spin this up and browsers are working in the background and you don't necessarily have to know. And it just is booking restaurants for you, whatever. I can definitely see that future happening. I had this on the landing page here. This might be a slightly out of order. But, you know, you have, like, sort of three use cases for browser base. Open Operator. Or this is the operator sort of use case. It's kind of like the workflow automation use case. And it completes with UiPath in the sort of RPA category. Would you agree with that? Yeah, I would agree with that. And then there's Agents we talked about already. And web scraping, which I imagine would be the bulk of your workload right now, right?Paul [00:43:40]: No, not at all. I'd say actually, like, the majority is browser automation. We're kind of expensive for web scraping. Like, I think that if you're building a web scraping product, if you need to do occasional web scraping or you have to do web scraping that works every single time, you want to use browser automation. Yeah. You want to use browser-based. But if you're building web scraping workflows, what you should do is have a waterfall. You should have the first request is a curl to the website. See if you can get it without even using a browser. And then the second request may be, like, a scraping-specific API. There's, like, a thousand scraping APIs out there that you can use to try and get data. Scraping B. Scraping B is a great example, right? Yeah. And then, like, if those two don't work, bring out the heavy hitter. Like, browser-based will 100% work, right? It will load the page in a real browser, hydrate it. I see.swyx [00:44:21]: Because a lot of people don't render to JS.swyx [00:44:25]: Yeah, exactly.Paul [00:44:26]: So, I mean, the three big use cases, right? Like, you know, automation, web data collection, and then, you know, if you're building anything agentic that needs, like, a browser tool, you want to use browser-based.Alessio [00:44:35]: Is there any use case that, like, you were super surprised by that people might not even think about? Oh, yeah. Or is it, yeah, anything that you can share? The long tail is crazy. Yeah.Surprising use cases of BrowserbasePaul [00:44:44]: One of the case studies on our website that I think is the most interesting is this company called Benny. So, the way that it works is if you're on food stamps in the United States, you can actually get rebates if you buy certain things. Yeah. You buy some vegetables. You submit your receipt to the government. They'll give you a little rebate back. Say, hey, thanks for buying vegetables. It's good for you. That process of submitting that receipt is very painful. And the way Benny works is you use their app to take a photo of your receipt, and then Benny will go submit that receipt for you and then deposit the money into your account. That's actually using no AI at all. It's all, like, hard-coded scripts. They maintain the scripts. They've been doing a great job. And they build this amazing consumer app. But it's an example of, like, all these, like, tedious workflows that people have to do to kind of go about their business. And they're doing it for the sake of their day-to-day lives. And I had never known about, like, food stamp rebates or the complex forms you have to do to fill them. But the world is powered by millions and millions of tedious forms, visas. You know, Emirate Lighthouse is a customer, right? You know, they do the O1 visa. Millions and millions of forms are taking away humans' time. And I hope that Browserbase can help power software that automates away the web forms that we don't need anymore. Yeah.swyx [00:45:49]: I mean, I'm very supportive of that. I mean, forms. I do think, like, government itself is a big part of it. I think the government itself should embrace AI more to do more sort of human-friendly form filling. Mm-hmm. But I'm not optimistic. I'm not holding my breath. Yeah. We'll see. Okay. I think I'm about to zoom out. I have a little brief thing on computer use, and then we can talk about founder stuff, which is, I tend to think of developer tooling markets in impossible triangles, where everyone starts in a niche, and then they start to branch out. So I already hinted at a little bit of this, right? We mentioned more. We mentioned E2B. We mentioned Firecrawl. And then there's Browserbase. So there's, like, all this stuff of, like, have serverless virtual computer that you give to an agent and let them do stuff with it. And there's various ways of connecting it to the internet. You can just connect to a search API, like SERP API, whatever other, like, EXA is another one. That's what you're searching. You can also have a JSON markdown extractor, which is Firecrawl. Or you can have a virtual browser like Browserbase, or you can have a virtual machine like Morph. And then there's also maybe, like, a virtual sort of code environment, like Code Interpreter. So, like, there's just, like, a bunch of different ways to tackle the problem of give a computer to an agent. And I'm just kind of wondering if you see, like, everyone's just, like, happily coexisting in their respective niches. And as a developer, I just go and pick, like, a shopping basket of one of each. Or do you think that you eventually, people will collide?Future of browser automation and market competitionPaul [00:47:18]: I think that currently it's not a zero-sum market. Like, I think we're talking about... I think we're talking about all of knowledge work that people do that can be automated online. All of these, like, trillions of hours that happen online where people are working. And I think that there's so much software to be built that, like, I tend not to think about how these companies will collide. I just try to solve the problem as best as I can and make this specific piece of infrastructure, which I think is an important primitive, the best I possibly can. And yeah. I think there's players that are actually going to like it. I think there's players that are going to launch, like, over-the-top, you know, platforms, like agent platforms that have all these tools built in, right? Like, who's building the rippling for agent tools that has the search tool, the browser tool, the operating system tool, right? There are some. There are some. There are some, right? And I think in the end, what I have seen as my time as a developer, and I look at all the favorite tools that I have, is that, like, for tools and primitives with sufficient levels of complexity, you need to have a solution that's really bespoke to that primitive, you know? And I am sufficiently convinced that the browser is complex enough to deserve a primitive. Obviously, I have to. I'm the founder of BrowserBase, right? I'm talking my book. But, like, I think maybe I can give you one spicy take against, like, maybe just whole OS running. I think that when I look at computer use when it first came out, I saw that the majority of use cases for computer use were controlling a browser. And do we really need to run an entire operating system just to control a browser? I don't think so. I don't think that's necessary. You know, BrowserBase can run browsers for way cheaper than you can if you're running a full-fledged OS with a GUI, you know, operating system. And I think that's just an advantage of the browser. It is, like, browsers are little OSs, and you can run them very efficiently if you orchestrate it well. And I think that allows us to offer 90% of the, you know, functionality in the platform needed at 10% of the cost of running a full OS. Yeah.Open Operator: Browserbase's Open-Source Alternativeswyx [00:49:16]: I definitely see the logic in that. There's a Mark Andreessen quote. I don't know if you know this one. Where he basically observed that the browser is turning the operating system into a poorly debugged set of device drivers, because most of the apps are moved from the OS to the browser. So you can just run browsers.Paul [00:49:31]: There's a place for OSs, too. Like, I think that there are some applications that only run on Windows operating systems. And Eric from pig.dev in this upcoming YC batch, or last YC batch, like, he's building all run tons of Windows operating systems for you to control with your agent. And like, there's some legacy EHR systems that only run on Internet-controlled systems. Yeah.Paul [00:49:54]: I think that's it. I think, like, there are use cases for specific operating systems for specific legacy software. And like, I'm excited to see what he does with that. I just wanted to give a shout out to the pig.dev website.swyx [00:50:06]: The pigs jump when you click on them. Yeah. That's great.Paul [00:50:08]: Eric, he's the former co-founder of banana.dev, too.swyx [00:50:11]: Oh, that Eric. Yeah. That Eric. Okay. Well, he abandoned bananas for pigs. I hope he doesn't start going around with pigs now.Alessio [00:50:18]: Like he was going around with bananas. A little toy pig. Yeah. Yeah. I love that. What else are we missing? I think we covered a lot of, like, the browser-based product history, but. What do you wish people asked you? Yeah.Paul [00:50:29]: I wish people asked me more about, like, what will the future of software look like? Because I think that's really where I've spent a lot of time about why do browser-based. Like, for me, starting a company is like a means of last resort. Like, you shouldn't start a company unless you absolutely have to. And I remain convinced that the future of software is software that you're going to click a button and it's going to do stuff on your behalf. Right now, software. You click a button and it maybe, like, calls it back an API and, like, computes some numbers. It, like, modifies some text, whatever. But the future of software is software using software. So, I may log into my accounting website for my business, click a button, and it's going to go load up my Gmail, search my emails, find the thing, upload the receipt, and then comment it for me. Right? And it may use it using APIs, maybe a browser. I don't know. I think it's a little bit of both. But that's completely different from how we've built software so far. And that's. I think that future of software has different infrastructure requirements. It's going to require different UIs. It's going to require different pieces of infrastructure. I think the browser infrastructure is one piece that fits into that, along with all the other categories you mentioned. So, I think that it's going to require developers to think differently about how they've built software for, you know, application level so far. And I am excited to kind of explore more what that means. And I think we've seen from, like, you know, the customers that use Browsway so far, some really innovative ways to, like, take software and really read it. And I think, like, re-imagine it for AI and build things that, like, have chat interfaces, build things that have human loop flows, build things that are more asynchronous because AI is slower. And those are patterns that are still emerging. And I don't think we have all the best practices yet.Key Use Cases for Browserbase: Automation, Agents, and Scrapingswyx [00:52:03]: I don't have much feedback on that. Like, that's true. Paul's right. Paul's right. You heard it here first. Quoted by Swyx. Yeah. Amazing. I'm framing that. It is not specific enough to be wrong.Paul [00:52:12]: That means Paul's right to me still.swyx [00:52:14]: I don't know if I'm hearing that wrong. I always try to prompt people for falsifiable problems. I think I'm just trying to make sure that I'm not making false predictions. Because, like, you can predict that things will be better generically, but how? And, like, those are the things where you, like, put a little skin in the game where…Paul [00:52:28]: Yeah. I mean, I can predict that Browsways will be a billion dollar company one day. So let's check back in five years and, you know, if I'm a PM at Coinbase, then something went wrong. Oh, boy.swyx [00:52:40]: Yeah. Yeah. We picked out a couple of your tweets about Foundry. Yeah. I think you're a pretty building public kind of guy. Yeah. I try to be. I think the main thing that I want to highlight as well is, you emphasized this at the start of your intro, which is you're a solo founder. I think that there's a movement towards more solo founders in the Valley more generally, but people who are hearing this for the first time have no idea. They're like, what do you mean? YC forces me to get a co-founder. Like, what is this? So I've heard you talk about this before, but maybe you want to recap your spiel for folks that haven't heard about it. Yeah. Yeah.Being a solo founderPaul [00:53:11]: I mean, I've had co-founders in my past company. I love my co-founders. They're my wedding. I think if you want to move extremely fast as a company, one of the hard parts about having co-founders is that there's like, you have to do the co-founder alignment and then the company alignment. And then there's people on the team that probably tell things to one co-founder because they have a favorite. And then like that co-founders represent their interests. Matt Brasway is a benevolent dictatorship. You know, like if I want to make a change, I work with the team and we all decide together. We move quickly. We don't have an extra layer of buy-in within the co-founder layer. Yeah. And frankly, like I think, especially with DevTools companies, if you're able to talk about your product and talk with customers and you can build product, you don't need to have a business guy or a business side. You know, I'm a developer first and foremost. I was raised by two salespeople, so I guess that's why I can talk to customers or something. But at my core- What kind of sales? I love, they did semiconductor and pharmaceutical sales. My mom and dad. Oh, very different. Yeah. Very different.swyx [00:54:08]: But also very enterprise. Good. Yeah.Paul [00:54:10]: Yeah. Yeah. Yeah. Yeah. I mean, like, it rubbed off on me in some way. I was just trying to play WoW as a kid and they made me play sports. So I don't know how it worked out the way it did, but it does all come back to like, as a solo founder, you need to be willing to like go out there and, you know, talk about your product, go talk to customers, go convince people to work for you, but then also have core principles of like how you want to build this company and like what product you want to build. And thankfully, if you can do all of that, you can be a solo founder. You just have to hire fast and put the right team around you. Yeah. And that's kind of the team that we do that's surrounding me and kind of lifting the whole company up.Alessio [00:54:44]: So there's kind of like the decision making and then there's like the culture of a company. Obviously as a solo founder, you have huge influence on everybody. Apple is maybe the usual example of like, you know, you have the Jobs and Wozniak. None of like, you can have two co-founders that are like each polarizing.Unexpected Use Cases of Browser Automationswyx [00:55:01]: There was a third co-founder, by the way.Alessio [00:55:02]: Who was the third co-founder?swyx [00:55:03]: I don't know. He sold his chairs very early on. Nobody talks about him, but he's like, he always has a, has a bit of a regret.Alessio [00:55:10]: Okay. But anyway. Yeah. How have you thought about building the culture? You know, obviously startups are like super intense, but you're also going to just run yourself to the ground all the time. Any insight doing it solo? Yeah.Paul [00:55:21]: I mean, like I talked about like how it's easier for me to make decisions being a solo founder. The real cheat code is like having a great team that you give a lot of agency and ownership to. A lot of people make the little tiny decisions that go into everything that makes Biospace great. Like the website, for example, I, I had some, like some involvement with that, but like a lot of that was the team. Right. And then the product. I think the team really has ownership of all, a lot of these day-to-day decisions that add up to make a cohesive product experience culturally, like we're fully in person. Maybe that's one crazy take that we do, but we're also like not too in person. Like our first meetings at 10 AM, people leave around five or six. We work Monday to Friday in person and those like, that's the, the expectation, right? I think people have gone too far with in-person where they're like seven days a week in the office, 9 AM to 9 PM.swyx [00:56:10]: That's too much. Just an anecdote. Yeah. I just visited an office. I'll keep them anonymous for now, but to my face, we are 9, 9, 6. Yeah. For those who don't know, 9, 9, 6 is 9 AM to 9 PM, six days a week.Paul [00:56:20]: I think we've taken it a little too far and for some teams, I know another anonymous company that does something like 9, 9, 6 and they're like crushing it right now. Right. So like, and like, it does get results, but like, I think for our culture, we gather in person, we put pants on every day and go to the office so that we can all work together. Or shorts, I guess. Right. And then like, we all know we're going to work outside of, out of the office. We're going to work at home sometimes. We might come in on a weekend. The weekends are for fun work and that's really where we get to let people work on stuff that's not on the roadmap. And that empowers them to build something and bring it back to the team on Monday and say, look what I built. This is cool. Culturally, we're a lot of like former YCCTOs and like ex-founders or future founders. And I've just found that those people tend to be just really great early hires for a company. They, they get it. And I think for them, especially kind of the ex-YCCTOs. I see people who maybe didn't find PMF coming in and being at a company with PMF, it's such a refreshing thing for them because they can just come in and execute. And there's just so many clear things we have to go build. And if you're a talented engineer, being able to go build and make an impact every single day is like super fulfilling.swyx [00:57:25]: My question on the other hand is you also talk a lot about recruiting, especially in the podcast that you talk about. How come there's no browser-based recruiting agent? That's a good question.Paul [00:57:34]: I think it's because I don't do that much outbound. I do message people. Yeah. But a lot of it's now through referral. It's very like targeted. Like if I see somebody working on something really cool, I just message them. So I don't want like something trawling the web and like messaging every Kubernetes firecracker expert. I try and like look for them in my passive web browsing. And when I find somebody, I just want to like take the time personally, like say, Hey, I love what you're doing. I think it's really cool. And let's have a conversation. Yeah.swyx [00:58:03]: Off of Hacker News and other stuff. Yeah.Paul [00:58:05]: I love to hire off of Hacker News. Yeah.swyx [00:58:07]: Let you plug at the end. My attempt at this failed, which is I really hate LinkedIn Sales Navigator. I think that it is just grifting on top of people doing data entry for LinkedIn. And I hope that browser-based will someday help to kill LinkedIn Sales Navigator at this point.Paul [00:58:21]: I don't know if we will directly, but one of our customers definitely is trying to do that. So I think there's a couple that are on it. These AISDR companies are crushing it. Yup.Alessio [00:58:30]: The 996 company was an AISDR company.swyx [00:58:33]: There we go.Alessio [00:58:34]: Yeah. Very classic. This was great. Anything? Yeah. You got the run clubs too. What other things do you mix in, like both in the company culture and like the community culture? I know you bring people together. Yeah.Paul [00:58:45]: I think like we, like we try and build in public and like, like you can see a lot of the browser based people on Twitter. Every Monday we have a run club. People go running together. We don't run very fast, but it's like a good way to spend time together. I just look back fondly on my time being in person at my first company. And we have people like with a mix of people like are just early in career. People have been in the business for a long time. They've been in, you know, the workforce for 20, 30 years. So it's not just like a young people company, like it's a huge mix. But when you make people make a polarizing decision of like, I will come to an office five days a week, people then end up making more decisions that are aligned with a culture. So it's almost like if you can make your culture binary or you're in or out, it becomes easier to assimilate and like keep a cohesive culture. And I think it starts with being an office for us, but for other people it could be like moving or like using discord versus slack or like other like. Yeah. The, the binary decisions that people may have to make.swyx [00:59:36]: One thing I like asking founders is, you know, you're famously not an AI company or, you know, you, you serve AI companies, but you're not yourself a LLM sort of consuming company. But if you were though, what company would you start? What's what's like obviously a good idea.The Competitive Landscape of AI-Powered Browsing and AutomationPaul [00:59:50]: Yeah, I, I had this tweet like forever ago, which is like, there's so much money to be made in taking like proprietary research and then turning that into like an automation, which is obviously like a very like browser based inspired one. Like. Like listening to all the city halls or town hall meetings in like little towns and then knowing when they're going to like approve a new Walmart or something and then like buying up real estate around the Walmart because that will go up when they install this thing. So it's like really interesting to think about like how can you find new channels for data that will allow you to make like high alpha decisions and benefit you financially. So I think it's like some interesting stuff there, like just a bunch of conversations that happen in real life that are recorded, that are online, that you can go find using, you know, a web browser, of course. And then like making some interesting like decisions off of that. So I don't know, like I like browser stuff, like it's on brand, right? Like I have to, I'm consistent at least.Alessio [01:00:45]: Do not look at it on your phone through a native app, only look at it through the browser.swyx [01:00:49]: My favorite part of one of his videos, they had these guys holding this bee behind them while they were doing the demo. So it was like a really Easter egg. Yeah, that was stagehand, right?Paul [01:00:58]: Yeah, the stagehand video. It's not, they're not holding it. They're actually wearing these bee boxes on their heads. And we shot it like five times and poor Sean and Samil are like bobbing their heads back and forth with these bee boxes on because we can't afford special effects, man. It's really serious.swyx [01:01:13]: Good detail. Good effort detail there. Yeah. Thank you so much. Congrats on all your success.Paul [01:01:17]: Thanks for having me, guys. It's been a really good time.swyx [01:01:20]: Yeah, I'm sure we'll have you back again.Paul [01:01:21]: Yeah, I'd love to come back. Get full access to Latent.Space at www.latent.space/subscribe
-
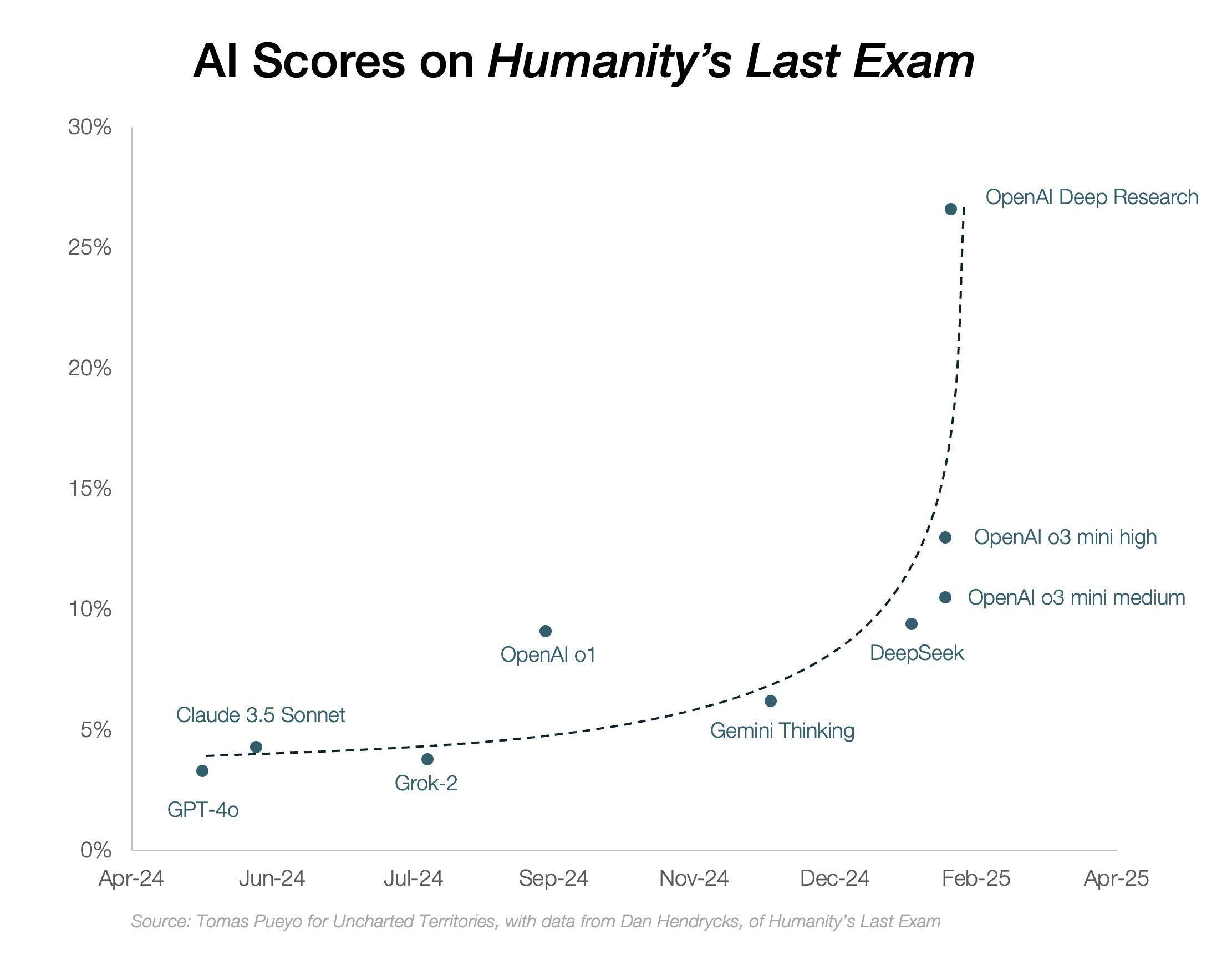 The Inventors of Deep Research
The Inventors of Deep ResearchFrom 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2025-02-18 15:51
While “LLM-powered Search” is as old as Perplexity and SearchGPT, and open source projects like GPTResearcher and clones like OpenDeepResearch exist, the difference with “Deep Research” products is they are both “agentic” (loosely meaning that an LLM decides the next step in a workflow, usually involving tools) and bundling custom-tuned frontier models (custom tuned o3 and Gemini 1.5 Flash).The reception to OpenAI’s Deep Research agent has been nothing short of breathless:"Deep Research is the best public-facing AI product Google has ever released. It's like having a college-educated researcher in your pocket." - Jason Calacanis“I have had [Deep Research] write a number of ten-page papers for me, each of them outstanding. I think of the quality as comparable to having a good PhD-level research assistant, and sending that person away with a task for a week or two, or maybe more. Except Deep Research does the work in five or six minutes.” - Tyler Cowen“Deep Research is one of the best bargains in technology.” - Ben Thompson“my very approximate vibe is that it can do a single-digit percentage of all economically valuable tasks in the world, which is a wild milestone.” - sama“Using Deep Research over the past few weeks has been my own personal AGI moment. It takes 10 mins to generate accurate and thorough competitive and market research (with sources) that previously used to take me at least 3 hours.” - OAI employee“It's like a bazooka for the curious mind” - Dan Shipper“Deep research can be seen as a new interface for the internet, in addition to being an incredible agent… This paradigm will be so powerful that in the future, navigating the internet manually via a browser will be "old-school", like performing arithmetic calculations by hand.” - Jason Wei“One notable characteristic of Deep Research is its extreme patience. I think this is rapidly approaching “superhuman patience”. One realization working on this project was that intelligence and patience go really well together.” - HyungWon“I asked it to write a reference Interaction Calculus evaluator in Haskell. A few exchanges later, it gave me a complete file, including a parser, an evaluator, O(1) interactions and everything. The file compiled, and worked on my test inputs. There are some minor issues, but it is mostly correct. So, in about 30 minutes, o3 performed a job that would take me a day or so.” - Victor Taelin“Can confirm OpenAI Deep Research is quite strong. In a few minutes it did what used to take a dozen hours. The implications to knowledge work is going to be quite profound when you just ask an AI Agent to perform full tasks for you and come back with a finished result.” - Aaron Levie“Deep Research is genuinely useful” - Gary MarcusWith the advent of “Deep Research” agents, we are now routinely asking models to go through 100+ websites and generate in-depth reports on any topic. The Deep Research revolution has hit the AI scene in the last 2 weeks:* Dec 11th: Gemini Deep Research (today’s guest!) rolls out with Gemini Advanced* Feb 2nd: OpenAI releases Deep Research* Feb 3rd: a dozen “Open Deep Research” clones launch* Feb 5th: Gemini 2.0 Flash GA* Feb 15th: Perplexity launches Deep Research* Feb 17th: xAI launches Deep SearchIn today’s episode, we welcome Aarush Selvan and Mukund Sridhar, the lead PM and tech lead for Gemini Deep Research, the originators of the entire category. We asked detailed questions from inspiration to implementation, why they had to finetune a special model for it instead of using the standard Gemini model, how to run evals for them, and how to think about the distribution of use cases. (We also have an upcoming Gemini 2 episode with our returning first guest Logan Kilpatrick so stay tuned 👀)Two Kinds of Inference Time ComputeIn just ~2 months since NeurIPS, we’ve moved from “scaling has hit a wall, LLMs might be over” to “is this AGI already?” thanks to the releases of o1, o3, and DeepSeek R1 (see our o3 post and R1 distillation lightning pod). This new jump in capabilities is now accelerating many other applications; you might remember how “needle in a haystack” was one of the benchmarks people often referenced when looking at model’s capabilities over long context (see our 1M Llama context window ep for more). It seems that we have broken through the “wall” by scaling “inference time” in two meaningful ways — one with more time spent in the model, and the other with more tool calls.Both help build better agents which are clearly more intelligent. But as we discuss on the podcast, we are currently in a “honeymoon” period of agent products where taking more time (or tool calls, or search results) is considered good, because 1) quality is hard to evaluate and 2) we don’t know the realistic upper bound to quality. We know that they’re correlated, but we don’t know to what extent and if the correlation breaks down over extended research periods (they may not).It doesn’t take a PhD to spot the perverse incentives here.Agent UX: From Sync to Async to HybridWe also discussed the technical challenges in moving from a synchronous “chat” paradigm to the “async” world where every agent builder needs to handroll their own orchestration framework in the background.For now, most simple, first-cut implementations including Gemini and OpenAI and Bolt tend to make “locking” async experiences — while the report is generating or the plan is being executed, you can’t continue chatting with the model or editing the plan. In this case we think the OG Agent here is Devin (now GA), which has gotten it right from the beginning.Full Episode on YouTubewith demo!Show Notes* Deep Research* Aarush Selvan* Mukund Sridhar* NotebookLM episode (Raiza / Usama)* Bolt* Bret TaylorChapters* [00:00:00] Introductions* [00:00:22] Overview + Demo of Deep Research* [00:04:31] Editable chain of thought* [00:08:18] Search ranking for sources* [00:09:31] Can you DIY Deep Research?* [00:15:52] UX and research plan editing* [00:16:21] Follow-up queries and context retention* [00:21:06] Evaluating Deep Research* [00:28:06] Ontology of use cases and research patterns* [00:32:56] User perceptions of latency in Deep Research* [00:40:59] Lessons from other AI products* [00:42:12] Multimodal capabilities* [00:45:02] Technical challenges in Deep Research* [00:51:56] Can Deep Research discover new insights?* [00:54:11] Open challenges in agents* [00:57:04] Wrap upTranscriptAlessio [00:00:04]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol AI.Swyx [00:00:13]: Hey, and today we're very honored to have in our studio Aarush and Mukund from the Deep Research team, the OG Deep Research team. Welcome.Aarush [00:00:20]: Thanks for having us.Swyx [00:00:22]: Yeah, thanks for making the trip up. I was fortunate enough to be one of the early beta testers of Deep Research when he came out. I would say I was very keen on, I think even at the end of last year, people were already saying it was one of the most exciting agents that was coming out of Google. You know that previously we had on Ryza and Usama from the Novoca LM team. And I think this is an increasing trend that Gemini and Google are shipping interesting user-facing products that use AI. So congrats on your success so far. Yeah, it's been great. Thanks so much for having us here. Yeah. Yeah, thanks for making the trip up. And I'm also excited for your talk that is happening next week. Obviously, we have to talk about what exactly it is, but I'll ask you towards the end. So basically, okay, you know, we have the screen up. Maybe we just start at a high level for people who don't yet know. Like, what is Deep Research? Sure.Aarush [00:01:10]: So Deep Research is a feature where Gemini can act as your personal research assistant to help you learn about any topic that you want more deeply. It's really helpful for those queries. So you want to go from zero to 50 really fast on a new thing. And the way it works is it takes your query, browses the web for about five minutes, and then outputs a research report for you to review and ask follow-up questions. This is one of the first times, you know, something takes about five, six minutes trying to perform your research. So there's a few challenges that brings. Like, you want to make sure you're spending that time in the computer doing what the user wants. So there's some ways of the UX design that we can talk about. As we go through an example, and then there's also challenges in the browsers, the web is super fragmented and being able to plan iteratively and as, as you pass through this noisy information is a challenge by itself.Swyx [00:02:11]: Yeah. This is like the first time sort of Google automating yourself as searching, like you're, you know, you're supposed to be the experts at search, but now you're like meta-searching and like determining the search strategy.Aarush [00:02:22]: Yeah, I think, at least we see it as two different use cases. There are things that, you know, you know exactly what you're looking for and there's a search is still probably, you know, a very, you know, probably one of the best places to go. I think when deep research really shines is there like multiple facets to your question and you spend like a weekend, you know, just opening like 50, 60 tabs and many times I just give up and we wanted to solve that problem and, and give a great starting point for those kinds of journeys.Alessio [00:02:53]: Do we want to start a query so that it runs in the meantime and then we can chat over it?Swyx [00:02:58]: Okay, here's one query that, that we like, we love to test like super niche, random things, like things where there's like no Wikipedia page already about this topic or something like that, right? Because that's where you'll see the most lift from, from a feature like this. So for this one, I've come, I've come, come up with this query. This is actually Mokun's query that he's, he loves to test is help me understand how milk and meat regulations differ between the US and Europe. What's nice is the first step is actually where it puts together a research plan. That you can review. And so this is sort of its guide for how it's going to go about and carry out the research, right? And so this was like a pretty decently well-specified query, but like, let's say you came to Gemini and we're like, tell me about batteries, right? That query, you could mean so many different things. You might want to know about the like latest innovations in battery tech. You might want to know about like a specific type of battery chemistry. And if we're going to spend like five to even 10 minutes researching something, we want to one, understand. What exactly are you trying to accomplish here and to give you an opportunity, like to steer where the research goes, right? Because like, if you had an intern and you ask them this question, the first thing they do is ask you like a bunch of follow-up questions and be like, okay, so like, help me figure out exactly what you want me to do. And so the way we approached it is, we thought like, why don't we just have the model produce its first stab at the, at the research query at, at how it would break this down. And then invite the user to come and kind of engage with how they would want to steer this. Yeah.Editable chain of thoughtAarush [00:04:31]: And many times when you try to use a product like this, you often don't know what questions to look for or the things to look for. So we kind of made this decision very deliberately that instead of asking the users just follow-up questions directly, we kind of lay out, hey, this is what I would do. Like, these are the different facets. For example, here it could be like what additives are allowed and how that differs or labeling. Uh, restrictions and so on in products. The aim of this is to kind of tell the user about the topic a little bit more and also get steer. At the same time, we elicit for like, uh, you know, a follow-up question and so on. So we kind of did that in a joint question.Swyx [00:05:09]: It's kind of like editable chain of thought. Right. Exactly. Exactly. Yeah. I think that, you know, we were talking to you about like your top tips for using deep research. Yeah. Your number one tip is to edit the page. Just edit it. Right. So like we actually, you can actually edit conversationally. We put in a button here just to like draw users' attention to the fact that you can edit. Oh, actually you don't need to click the button. You don't even need to click the button. Yeah. Actually, like in early rounds of testing, we saw no one was editing. And so we were just like, if we just put a button here, maybe people will like. I confess I just hit start a lot. I think like we see that too. Like most people hit start. Um, like it's like the, I'm feeling lucky. Yeah. Yeah. All right. So like I, I can just add a, add a step here and what you'll see is it should like refine the plan and show you a new thing to propose. Here we go. So it's added step seven, find information and milk and meat labeling requirements in the US and the EU, or you can just go ahead and hit start. I think it's still like a nice transparency mechanism. Even if users don't want to engage, like you still kind of know, okay, here's at least an understanding of why I'm getting the report I'm going to get, um, which is kind of nice. And then while it browses the web and Morgan, you should maybe explain kind of how it, how it browses. We show kind of the, the websites it's reading in real time. Yeah. I'll preface this with, I haven't, I forgot to explain the rules. You're a PM and you're a tech lead. Yes. Okay. Yeah.Aarush [00:06:29]: Just for people who, who don't know, we maybe should have started with that. I suppose. Yeah. Yeah. We do each other's work sometimes as well, but more or less that's the boundary. Yeah. Yeah. Um, yeah. So, so what's happening behind the scenes actually is we kind of give this research plan that is a contract and that, uh, you know, has been accepted, but then if you look at the plan, there are things that are obviously parallelizable, so the model figures out which of the sub steps that it can start exploring in parallel, and then it primarily uses like two tools. It has the ability to perform searches and it has abilities to go deeper within, you know, a particular webpage of interest, right? And oftentimes it'll start exploring things in parallel, but that's not sufficient. Many times it, it has to reason based on information found. So in this case, it, one of the searches could have led the EU commission has these additives, and it wants to go and check if the FDA does the same thing, right? So, uh, this notion of being able to read outputs from the previous turn, uh, ground on that to decide what to do next, I think was, was key. Otherwise you have like incomplete information and your report becomes a little bit of a, like a high level, uh, bullet points. So we wanted to go beyond that blueprint and actually figure out, you know, what are the key aspects here. So, yeah. So the, this happens iteratively until the model thinks it's finished. All its steps. And then we kind of entered this, uh, analysis mode and here there can be inconsistencies across sources. You kind of come up with an outline for the report, start generating a draft. The model tries to revise that by self critiquing itself, uh, you know, to find out to finalize the prompt, uh, finalize the report. And that's probably what's happening behind the scenes.Search ranking for sourcesAlessio [00:08:18]: What's the initial ranking of the websites? So when you first started it, there were 36. How do you decide where to start since it sounds like, you know, the initial websites kind of carry a lot of weight too, because then they inform the following. Yes.Aarush [00:08:32]: So what happens in the initial terms, again, this is not like a, it's not something we enforce. It's mostly the model making these choices. But typically we see the model exploring all the different aspects in the, in the research plan that was presented. So we kind of get like a breadth first idea of what are the different topics to explore. And in terms of which ones to double click. I think it really comes down to every time you search the model, get some idea of what the pages and then depending on what pieces of it, sometimes there's inconsistency. Sometimes there's just like partial information. Those are the ones that double clicks on and, uh, yeah, it can continually like iteratively search and browse until it feels like it's done. Yeah.Swyx [00:09:15]: I'm trying to think about how I would code this. Um, a simple question would be like, do you think that we could do this with the Gemini API? Or do you have some special access that we cannot replicate? You know, like is, if I model this with a so-called of like search, double click, whatever. Yeah.Aarush [00:09:31]: I don't think we have special access per se. It's pretty much the same model. We of course have our own, uh, post-training work that we do. And y'all can also like, you know, you can fine tune from the base model and so on. Uh, I don't know that we can do it.Swyx [00:09:45]: I don't know how to fine tuning.Aarush [00:09:47]: Well, if you use our Gemma open source models, uh, you could fine tune. Yeah. I don't think there's a special access per se, but a lot of the work for us is first defining these, oh, there needs to be a research plan and, and how do you go about presenting that? And then, uh, a bunch of post-training to make sure, you know, it's able to do this consistently well and, uh, with, with high reliability and power. Okay.Swyx [00:10:09]: So, so 1.5 pro with deep research is a special edition of 1.5 pro. Yes.Aarush [00:10:14]: Right.Swyx [00:10:14]: So it's not pure 1.5 pro. It's, it's, it's, it's a post-training version. This also explains why you haven't just, you can't just toggle on 2.0 flash and just, yeah. Right. Yeah. But I mean, I, I assume you have the data and you know, it's should be doable. Yup. There's still this like question of ranking. Yeah. Right. And like, oh, it looks like you're, you're already done. Yeah. Yeah. We're done. Okay. We can look at it. Yeah. So let's see. It's put together this report and what it's done is it's sort of broken, started with like milk regulation and then it looks like it goes into meat probably further down and then sort of covering how the U.S. approaches this problem of like how to regulate milk. Comparing and then, you know, covering the EU and then, yeah, like I said, like going into the meat production and then it'll also, what's nice is it kind of reasons over like why are there differences? And I think what's really cool here is like, it's, it's showing that there's like a difference in philosophy between how the U.S. and the EU regulate food. So the EU like adopts a precautionary approach. So even if there's inconclusive scientific evidence about something, it's still going to prefer to like ban it. Whereas the U.S. takes sort of the reactive approach where it's like allowing things until they can be proven to be harmful. Right. So like, this is kind of nice is that you, you also like get the second order insights from what it's being put, what it's putting together. So yeah, it's, it's kind of nice. It takes a few minutes to read and like understand everything, which makes for like a quiet period doing a podcast, I suppose. But yeah, this is, this is kind of how it, how it looks right now. Yeah.Alessio [00:11:47]: And then from here you can kind of keep the usual chat and iterate. So this is more, if you were to like, you know, compared to other platforms, it's kind of like a Anthropic Artifact or like a ChatGPT canvas where like you have the document on one side and like the chat on the other and you're working on it.Aarush: [00:12:04]: Yeah. This is something we thought a bit about. And one of the things we feel is like your learning journey shouldn't just stop after the first report. And so actually what you probably want to do is while reading, be able to ask follow-up questions without having to scroll back and forth. And there's like broadly. A few different kinds of follow-up questions. One type is like, maybe there's like a factoid that you want that isn't in here, but it's probably been already captured as part of the web browsing that it did. Right. So we actually keep everything in context, like all the sites that it's read remain in context. So if there's a piece of missing information, it can just fetch that. Then another kind is like, okay, this is nice, but you actually want to kick off more deep research. Or like, I also want to compare the EU and Asia. Let's say in how they regulate milk and meat for that. You'd actually want the model to be like, okay, this is sufficiently different that I want to go do more deep research to answer this question. I won't find this information in what I've already browsed. And the third is actually, maybe you just want to like change the report. Like maybe you want to like condense it, remove sections, add sections, and actually like iterate on the report that you got. So we broadly are basically trying to teach the model to be able to do all three and the kind of side-by-side format allows sort of for the user to do that more easily. Yeah.Alessio [00:13:24]: So as a PM, there's a open in docs button there, right? Yeah. How do you think about what you're supposed to build in here versus kind of sounds like the condensing and things should be a Google docs. Yeah.Aarush [00:13:35]: It's just like an amazing editor. Like sometimes you just want to direct edit things and now Google docs also has Gemini in the side panel. So the more we can kind of help this be part of your workflow throughout the rest of the Google ecosystem, the better, right? Like, and one thing that we've noticed is people really like that button and really like exporting it. It's also a nice way to just save it permanently. And when you do export all the citations, and in fact, I can just run it now, carry over, which is also really nice. Gemini extensions is a different feature. So that is really around Gemini being able to fetch content from other Google services in order to inform the answer. So that was actually the first feature that we both worked on on the team as well. It was actually building extensions in Gemini. And so I think right now we have a bunch of different Google apps as well as I think Spotify and a couple, I don't know if we have, and Samsung apps as well. Who wants Spotify? I have this whole thing about like who wants Spotify? Who wants that in their deep research? In deep research, I think less, but like the interesting thing is like we built extensions and we didn't, we weren't really sure how people were going to use it. And a ton of people are doing really creative things with them. And a ton of people are just doing things that they loved on the Google assistant. And Spotify is like a huge, like playing music on the go was like a huge, a huge value. Oh, it controls Spotify? Yeah. It's not deep research. For deep research. Yeah. Purely use. Yeah. But this is search. Otherwise, yeah. Like you can, you can have Gemini go. Yeah. You have YouTube maps and search for flash thinking experimental with apps. The newest. Yeah. Longest model name that has been launched. But like, yeah, I think Gmail is obvious one. Yeah. The calendar is obvious one. Exactly. Those I want. Yeah. Spotify. Yeah. Fair enough. Yeah. And obviously feel free to dive in on your other work. I know you're, you're not just doing deep research, right? But you know, we're just kind of focusing on, on deep research here. I actually have asked for modifications after this first run where I was like, oh, you, you stopped. Like, I actually want you to keep going. Like what about these other things? And then continue to modify it. So it really felt like a little bit of a co-pilot type experience, but more like an experience. Yeah, we're just that much more than an agent that would be research. I thought it was pretty cool.UX and research plan editingAarush [00:15:52]: Yeah. One of the challenges is currently we kind of let the model decide based on your query amongst the three categories. So some, there is, there is a boundary there. Like some of these things, depending on how deep you want to go, you might just want to quite g thermometer versus like kick off another deeper search. And even from a UX perspective, I think the, the panel allows for this notion of, you know, not every fall up is going to take you. Like five minutes. Right.Swyx [00:16:17]: Right now, it doesn't do any follow-up. Does it do follow-up search? It always does?Aarush [00:16:21]: It depends on your question. Since we have the liberty of really long context models, we actually hold all the research material across dance. So if it's able to find the answer in things that it's found, you're going to get a faster reply. Yeah. Otherwise, it's just going to go back to planning.Swyx [00:16:38]: Yeah, yeah. A bit of a follow-up on the, since you brought up context, I had two questions. One, do you have a HTML to markdown transform step? Or do you just consume raw HTML? There's no way you consume raw HTML, right?Aarush [00:16:50]: We have both versions, right? So there is, the models are getting, like every generation of models are getting much better at native understanding of these representations. I think the markdown step definitely helps in terms of, you know, there's a lot of noise, like as you can imagine with the pure HTML. JavaScript, WinCSS. Exactly. So yeah, when it makes sense to do it, we don't artificially try to make it hard for the model. But sometimes it depends on the kind of access of what we get as well. Like, for example, if there's an embedded snippet that's HTML, we want the model to, you know, to be able to work on that as well.Swyx [00:17:27]: And no vision yet, but. Currently no vision, yes. The reason I ask all these things is because I've done the same. Got it. Like I haven't done vision.Aarush [00:17:36]: Yeah. So the tricky thing about vision is I think the models are getting significantly better, especially if you look at the last six months, natively being able to do like VQA stuff, and so on. But the challenge is the trade-off between having to, you know, actually render it and so on. The gap, the trade-off between the added latency versus the value add you get.Swyx [00:17:57]: You have a latency budget of minutes. Yeah, yeah, yeah.Aarush [00:18:01]: It's true. In my opinion, the places you'll see a real difference is like, I don't know, a small part of the tail, especially in like this kind of an open domain setting. If you just look at what people ask, there's definitely some use cases where it makes a lot of sense. But I still feel it's not in the head cases. And we'll do it when we get there.Swyx [00:18:23]: The classic is like, it's a JPEG that has some important information and you can't touch it. Okay. And then the other technical follow-up was just, you have 1 million to 2 million token context. Has it ever exceeded 2 million? And what do you do there? Yeah.Aarush [00:18:39]: So we had this challenge sometime last year where we said, when we started like wiring up this multi-turn, where we said, hey, we're going to do this. Hey, let's see how long somebody in the team can take DR, you know? Yeah.Swyx [00:18:51]: What's the most challenging question you can ask that takes the longest? Yeah. No, we also keep asking follow-ups.Aarush [00:18:55]: Like for example, here you could say, hey, I also want to compare it with like how it's Okay.Swyx [00:19:00]: So you're guaranteed to bust it. Yeah.Aarush [00:19:02]: Yeah. We also have, we have retrieval mechanisms if required. So we natively try to use the context as much as it's available beyond which, you know, we have like a rack set up to figure. Okay.Alessio [00:19:16]: This is all in-house, in-house tech. Yes. Okay.Aarush [00:19:19]: Yes.Alessio [00:19:19]: What are some of the differences between putting things in context versus rag? And when I was in Singapore, I went to the Google cloud team and they talk about Gemini plus grounding is Gemini plus search kind of like Gemini plus grounding or like, how should people think about the different shades of like, I'm doing retrieval and data versus I'm using deep research versus I'm using grounding. Sometimes the labels can be different. Sometimes it can be hard too.Aarush [00:19:46]: Yeah. I can, let me try to answer the first part of the question. Uh, the, the second part, I'm not fully sure of, of the grounding offering. So, uh, uh, when I can at least, at least talk about the first part of the question. So I think, uh, you're asking like the difference between like being able to, when you, when would you do a rag versus rely on the long contact?Alessio [00:20:06]: I think we all, we all get that. I was more curious, like from a product perspective, when you decide to do a rag versus s**t like this, you didn't need to, you know? Yeah. Do you get better performance just putting everything in context or?Aarush [00:20:18]: So the tricky thing for rag, it really works well because a lot of these things are doing like cosine distance, like a dot product kind of a thing. And that kind of gets challenging when your query side has multiple different attributes. Uh, the dot product doesn't really work as well. I would say, at least for me, that's, that's my guiding principle on, uh, when to avoid rag. That's one. The second one is, I think every generation. Of these models are, uh, like the initial generations, even though they offered like long context, that performance as the context kept growing was, you would see some kind of a decline, but I think, uh, as the newer generation models came out, uh, they were really good. Even if you kept filling in the context in being able to piece out, uh, like these really fine-grained information.Evaluating Deep ResearchSwyx [00:21:06]: So I think these two, at least for me, are like guiding principles on when to. Just to add to that. I think like, just like a simple rule of thumb that we use. Is like, if it's the most recent set of research tasks where the user is likely to ask lots of follow-up questions that should be in context, but like as stuff gets 10 tasks ago, you know, it's fine. If that stuff is in rag, because it's less likely that the user needs to do, you need to do like very complex comparisons between what's currently being discussed and the stuff that you asked about, you know, 10 turns ago. Right. So that's just like a, a very, like the rule of thumb that we follow. Yeah.Alessio [00:21:44]: So from a user perspective, is it better to just start a new research instead of like extending the context? Yeah.Aarush [00:21:50]: I think that's a good question. I think if it's a related topic, I think there's benefit to continue with this thread, uh, because you could, the model, since it has this in memory could figure out, oh, I've found this niche thing, uh, about, uh, I don't know, milk regulation in this case in the U S let me check if you're in a follow-up country or place also has something like that. So these kinds of things you might have not caught up. But if you start a new thread. So I think it really depends on, on the use case, if there's a natural progression, uh, and you feel like this is like part of one cohesive kind of a project, you should just continue using it. My follow-up is going to be like, oh, I'm just going to look for summer camps or something then. Yeah. I don't think it should make a difference, but we haven't really, uh, you know, pushed that to, uh, and, and, and tested that, that aspect of it for us. Most of our tests are like more natural transitions. Yeah.Swyx [00:22:40]: How do you eval deep research? Oh boy.Aarush [00:22:43]: Uh, yeah. This is a hard one. I think the entropy of the output space is so high, like it's, uh, like people love auto raters, but it brings its own, own, own set of, uh, challenges. And so for us, we have some metrics that we can auto generate, right? So for example, as we move, uh, when we do post-training and have multiple, uh, models, we kind of want to make sure, uh, the distribution of like certain stats, like for example, how long is spent on planning? How many, how many iterative steps it does on like some dev set, if you see large changes in distribution, that's, that's kind of like a early, uh, signal of, of something has changed. It could be for better or worse. Uh, so we have some metrics like that, that we can auto compute. So every time you have a new version, you run it across a test suite of cases and you see how long it takes. Yeah. So we have like a dev set and we have like some kind of automatic metrics that we can detect in terms of like the behavior end to end. Like for example, how long is the research plan? Do we, do we have like a, do we have like a, do we have like a, do we have like a, do we have like a new model is like a new model, produce really longer, many more steps, number of characters, like number of steps in case of the plan in the plans, it could be like, like we spoke about how it iteratively plans based on like previous searches, how many steps does that go on an average or some dev set. So there are some things like this you can automate, but beyond that, there are all generators, but we definitely do a lot of human evals and that we have defined with product about certain things we care about. I've been super opinionated about, is it comprehensive, is it complete, like groundedness and these kind of things. So it's a mix of these two attributes. There's another challenge, but I'll...Swyx [00:24:26]: Is this where, the other challenge in that, sometimes you just have to have your PM review examples. Yeah, exactly.Aarush [00:24:34]: Yeah, and for latency... So you're the human reader. But broadly, what we tried to do is, for the eval question, is like, we tried to think about like, what are all the ways in which a person might use a feature like this? And we came up with what we call an ontology of use cases. Yes. And really what we tried to do is like, stay away from like verticals, like travel or shopping and things like that. But really try and go into like, what is the underlying research behavior type that a person is doing? So... Yeah. There's queries on one end that are just, you're going very broad, but shallow, right? Things like, shopping queries are an example of that, or like, I want to find the perfect summer camp, my kids love soccer and tennis. And really, you just want to find as many different options and explore all the different options that are available, and then synthesize, okay, what's the TLDR about each one? Kind of like those journeys where you open many, many Chrome tabs, but then like, need to take notes somewhere of the stuff that's appealing. On the other end of the spectrum... You know, you've got like, a specific topic, and you just want to go super deep on that and really, really understand that. And there's like, all sorts of points in the middle, right? Around like, okay, I have a few options, but I want to compare them, or like, yeah, I want to go not super deep on a topic, but I want to cover a slightly, slightly more topics. And so we sort of developed this ontology of different research patterns, and then for each one came up with queries that would fall within that, and then that's sort of the eval set, by way of saying, okay, what's the TLDR about each one? Which we then run human evals on, and make sure we're kind of doing well across the board on all of those. Yeah, you mentioned three things. Is it literally three, or is it three out of like, 20 things? How wide is the ontology? I basically just told the... The full set? Yeah, I told, no, no, no, I told you the like, extremes, right? Extremes, okay. Yeah, and then we had like, several midpoints. So basically, yeah, going from like, something super broad and shallow to something very specific and deep. We weren't actually sure which end of the spectrum users are going to really resonate with. And then on top of that, you have compounds of those, right? So you can have things where you want to make a plan, right? Like, a great one is like, I want to plan a wedding in, you know, Lisbon, and I, you know, I need you to help with like, these 10 things, right? And so... Oh, that becomes like a project with research enabled... Right. And so then it needs to research planners, and venues, and catering, right? And so there's sort of compounds of when you start combining these different underlying ontology types. And so that, we also thought about that when we... When we tried to put together our eval set.Swyx: What's the maximum conversation length that you allow or design for?Aarush: We don't have any hard limits on the... How many turns you can do. One thing I will say is most users don't go very deep right now. Yeah. It might just be that it takes a while to get comfortable. And then over time, you start pushing it further and further. But like, right now, we don't see a ton of users. I think the way that you visually present it suggests that you stop when the doc is created. Right. So you don't... You don't actually really encourage... The UI doesn't encourage ongoing chats as though it was like a project. Right. I think there's definitely some things we can do on the UX side to basically invite the user to be like, Hey, this is the starting point. Now let's keep going together. Like, where else would you like to explore? So I think there's definitely some explorations we could do there. I think the... In terms of sort of how deep... I don't know. We've seen people internally just really push this thing. Yeah. To quite...Ontology of use cases and research patternsAarush [00:28:06]: I think the other thing I think will change with time is people kind of uncovering different ways to use deep research as well. Like for the wedding planning thing, for example. It's not one of the, you know, first thing that comes to mind when we tell people about this product. So that's another thing I think as people explore and find that this can do these various different kinds of things. Some of this can naturally lead to longer conversations. And even for us, right? When we dogfooded this, we saw people use it in, like, ways we hadn't really thought of before. So that was because this was, like, a little new. Like, we didn't know, like, will users wait for five minutes? What kind of tasks will... Are they, you know, going to try for something like that takes five minutes? So our primary goal was not to specialize in a particular vertical or target one type of user. We just wanted to put this in the hands of, like... Like, we had, like... This busy parent persona and, like, various different user profiles and see, like, what people try to use it for and learn more from that.Alessio [00:29:11]: And how does the ontology of the DR use case tie back to, like, the Google main product use cases? So you mentioned shopping as one ontology, right? There's also Google Shopping. Yeah. To me, this sounds like a much better way to do shopping than going on Google Shopping and looking at the wall of items. How do you collaborate internally to figure out where AI goes?Swyx [00:29:32]: Yeah, that's a great question. So when I meant, like, shopping, I sort of tried to boil down underneath what exactly is the behavior. And that's really around, like, I called it, like, options exploration. Like, you just want to be able to see. And whether you're shopping for summer camps or shopping for a product or shopping for, like, scholarship opportunities, it's sort of the same action of just, like, I need to curate from a large... Like, I need to sift through a lot of information to curate a bunch of options for me. So that's kind of what we tried to distill down rather than, like, thinking about it. It was a vertical. But yeah, Google Search is, like, awesome if you want to have really fast answers. You've got high intent for, like, I know exactly what I want. And you want, like, super up-to-date information, right? And I still do kind of like Google Shop because it's, like, multimodal. You see the best prices and stuff like that. I think creating a good shopping experience is hard, especially, like, when you need to look at the thing. If I'm shopping for shoes and, like, I don't want to use deep research because I want... I don't want to look at how the shoes look. But if I'm shopping for, like, HVAC systems, great. Like, I don't care how it looks or I don't even know what it's supposed to look like. And I'm fine using deep research because I really want to understand the specs and, like, how exactly does this work and the voltage rating and stuff like that, right? So, like, and I need to also look at contractors who know how to install each HVAC system. So I would say, like, where we really shine when it comes to shopping is those... That kind of end of the spectrum of, like, it's more complex and it matters less what it... Like, it's maybe less on the consumery side of shopping. One thing I've also observed just about the, I guess, the metrics or, like, the communication of what value you provide. And also this goes into the latency budget, is that I think there's a perverse incentive for research agents to take longer and be perceived to be better. People are like, oh, you're searching, like, 70 websites for me, you know, but, like, 30 of them are irrelevant, you know? Like, I feel like right now we're in kind of a honeymoon phase where you get a pass for all this. But being inefficient is actually good for you because, you know, people just care about quantity and not quality, right? So they're like, oh, this thing took an hour for me, like, it's doing so much work, like, or it's slow. That was super counterintuitive for us. So actually, the first time I realized that, what you're saying is when I was talking to Jason Calacanis and he was like, do you actually just make the answer in 10 seconds and just make me wait for the balance? Yeah. Which we hadn't expected. That people would actually value the, like, work that it's putting in because... You were actually worried about it. We were really worried about it. We were like, I remember, we actually built two versions of deep research. We had, like, a hardcore mode that takes, like, 15 minutes. And then what we actually shipped is a thing that takes five minutes. And I even went to Eng and I was like, there has to be a hard stop, by the way. It can never take more than 10 minutes. Yep. Because I think at that point, like, users will just drop off. Nope. But what's been surprising is, like, that's not the case at all. And it's been going the other way. Because when we worked on Assistant, at least, and other Google products, the metric has always been, if you improve latency, like, all the other metrics go up. Like, satisfaction goes up, retention goes up, all of that, right? And so when we pitch this, it's like, hold on. In contrast to, like, all Google orthodoxy, we're actually going to slow everything right down. And we're going to hope that, like, users still stay... Not on purpose.User perceptions of latency in Deep ResearchAarush [00:32:56]: Not on purpose. Yeah, I think it comes down to the trade-off. Like, what are you getting in return? For the wait. And from an engineering-slash-modeling perspective, it's just trading off entrance, compute, and time to do two things, right? Either to explore more, to be, like, more complete, or to verify more on things that you probably know already. And since it's like a spectrum, and we don't claim to have found the perfect spot, we had to start somewhere. And we're trying to see where... Like, there's probably some cases where you actually care about verifying more. More than the others. In an ideal world, based on the query and conversation history, you know what that is. So I think, yeah, it basically boils down to these three things. From a user perspective, am I getting the right value add? From an engineering-slash-modeling perspective, are we using the compute to either explore effectively and also verify and go in-depth for things that are vague or uncertain in the initial steps? The other point about the more number of websites, I think, again, it comes down to the number of websites. Sometimes you want to explore more early on before you kind of narrow down on either the sources or the topics you want to go deep. So that's one of the... If you look at, like, the way, at least for most queries, the way deep research works here is initially it'll go broad. If you look at the kinds of websites, it's time to explore all the different topics that we measured in the research plan. And then you would see choices of websites getting a little bit narrower on a particular topic or a particular topic. So that's roughly how the number kind of fluctuates. So we don't do anything deliberate to either keep it low or, you know, try to...Swyx [00:34:44]: Would it be interesting to have an explicit toggle for amount of verification versus amount of search? I think so. I think, like, users would always just hit that toggle. I worry that, like... Max everything. Yeah, if you, like, give a max power button, users will always... You're just going to hit that button, right? So then the question comes, like, why don't you just decide from the product POV, where's the right balance? OpenAI has a preview of this, like... I think it's either Anthropic or OpenAI, and there's a preview of this model routing feature where you can choose intelligence, cheapness, and speed. But then they're all zero to one values. So then you just choose one for everything. Obviously, they're going to, like, do a normalization thing. But users are always going to want one, right?Aarush [00:35:30]: We've discussed this a bit. Like, if I wear my pure user hat, I don't want to say anything. Like, I come with a query, you figure it out. Like, sometimes I feel like there will be, based on the query... Like, for example, right? If I'm asking about, hey, how does rising rates from the Fed house old income for a middle class? And how has it traditionally happened? These kind of things, you want to be very accurate. And you want to be very precise on historical trends of this, and so on, and so on. Whereas there is... There's a little bit more leeway when you're saying, hey, I'm trying to find businesses near me to go celebrate my birthday or something like that. So in an ideal world, we kind of figure that trade-off based on the conversation history and the topic. I don't think we're there yet as a research community. And it's an interesting challenge by itself.Swyx [00:36:20]: So this reminds me a little bit of the notebook LM approach. Raiza, who also asked this thing to Raiza, and she was like, yeah, just people want to click a button and see magic. Yeah. Like you said, you just hit start every time, right? You don't, most people don't even want to add up the plan. So, okay. My feedback on this, if you want feedback, is that I am still kind of a champion for Devin. In a sense that Devin will show you the plan while it's working the plan. And you can say like, hey, the plan is wrong. And I can chat with it while it's still working. And you live update the plan and then pick off the next item on the plan. I think it's static, right? Like while you're working on a plan, I cannot chat. It's just normal. Bolt also has this, like, you know, that's the most default experience, but I think you should never lock the chat. You should always be able to chat with the plan and update the plan and the plan scheduler, whatever orchestration system you have under the hood should just pick off the next job on the list. That'll be my two cents. Especially if we spend more time researching, right? Cause like right now, if you watch that query we just did, it was done within a few minutes. So your chance, your opportunity to chime in was actually like, or it left the research phase after a few minutes. So your opportunity to chime in. To chime in and steer was less, but especially imagine you could imagine a world where these things take an hour, right? And you're doing something really complicated. Then yeah, like your intern would totally come check in with you. Be like, here's what I found. Here's like some hiccups I'm running into the plan. Give me some steer on how to change that or how to change direction. And you would, you would do that with them. So I totally would see, especially as these tasks get longer, we actually want the user to come engage way more to like create a good output. I guess Devin had to do this because some of these jobs like take hours. Right. So, yeah. And it's pervasive since it's where they charge by hour. Oh, so they make more money, the slower they are. Interesting. Have we thought about that before?Swyx [00:38:14]: I'm calling this out because everyone is like, oh my God, it takes hours for, it does hours of work autonomously for me. And then they are like, okay, it's good. But like, this is a honeymoon phase. Like at some point we're going to say like, okay, but you know, it's very slow.Swyx [00:38:29]: Yeah. Anything else? Anything else that like, I mean, obviously within Google, you have a lot of other initiatives, you, I'm sure you like sit close to the Nopal Galem team in any learnings that are coming from shipping AI products in general. They're really awesome people. Like they're really nice, friendly thought, just like as people, I'm sure you met them, you like realize this with Razer and stuff. So like, they've actually been really, really cool collaborators or just like people to bounce ideas off. I think one thing I found really inspiring is they just picked a problem and hindsight's 2020. But like in advance, just like, Hey, we just want to build like the perfect IDE for you to do work and like be able to upload documents and ask questions about it and just make that really, really good. And I think we were definitely really inspired by their ability, their vision of just like, let's pick up a simple problem, really go after it, do it really, really well and have be opinionated about how it should work and just hope that users also resonate with that. And that's definitely something that we tried to learn from separately. They've also been really good at, you know, and maybe more. If you want to chime in here, just extracting the most out of Gemini 1.5 Pro, and they were really friendly about just like sharing their ideas about how to do that.Aarush [00:39:38]: Yeah, I think, I think you, you, you learn a bit, like when you're trying to do the last, last mile off of these products and, and, and, and pitfalls of, of any, any given model and so on. So, yeah, we definitely have a healthy relationship and, and, and share notes and like you're doing the same for other, other products.Swyx [00:39:54]: You'll never merge, right? It's just different teams. They are different teams. So they're in like labs as an organization that. So the mission of that is to really explore kind of different bets and, and explore what's possible. Even though I think there's a paid plan for Nopal Galem now. Yeah. So I think, and it's the same plan as us actually. So it's like, it's more than just the labs is what I'm saying. It's more than just labs. Cause I mean, yeah, ideally you want things to graduate and into, and stick around, but hopefully one thing we've done is, uh, like not created different skews, but just being like, Hey, if you pay the AI premium school, yeah, whatever. You get, you get everything, everything.Alessio [00:40:30]: What about learning from others? Obviously, I mean, open AI is deep research literally as the same name. I'm sure. Yeah. I'm sure there's a lot of, you know, contention. Is there anything you've learned from other people trying to build similar tools? Like, do you have opinions on maybe what people are getting wrong that they should do differently? It seems like from the outside, a lot of these products look the same. Ask for a research, get back a research, but obviously when you're building them, you understand the nuances a lot more.Lessons from other AI productsAarush [00:40:59]: When we built deep research, I think there was a few things that we took a few different bets, uh, around how this, how it should work. And what's nice is some of that is actually where we feel like was the right way to go. So we felt like agents should be transparent around telling you upfront, especially if they're going to take some time, what they're going to do. So that's really where that research plan, we showed that in a card, we really wanted to be very publisher forward in this product. So while it's browsing, we wanted to show you like all the websites. It's reading in real time, make it super easy for you to like double-click into those while it's browsing. And the third thing is, you know, putting it into a side-by-side artifacts so that you could ideally easy for you to read and ask at the same time. And what's nice is you kind of, as other products come around, you see some of these ideas also appearing in, in other iterations of this product. So I definitely see this as a space where like everyone in the industry is learning from each other, good ideas get reproduced and built upon. And so, yeah, we'll, we'll definitely keep iterating. And, and kind of following our users and seeing, seeing how we can make, make our future better. But yeah, I think, I think like it's, it's like, this is the way the industry works is like, everyone's going to kind of see good ideas and want to replicate and build off of it.Alessio [00:42:12]: And on the model side, OpenAI is the O3 model, which is not available through the API, the full one. Have you tried already with the two model? Like, is it a big jump or is a lot of the work on the post-training?Aarush [00:42:25]: Yeah, I would say stay tuned. Definitely. It currently is running on, on 1.5, the, the new generation models, especially with these thinking models, they unlock a few things. So I think one is obviously the better capability in like analytical thinking, like in math, coding, and these type of things, but also this notion of, you know, as they produce thoughts and think before taking actions, they kind of inherently have this notion of being able to critique them, the partial steps that they take and so on. So yeah, we definitely expect that. And then there is a little bit of the, the interesting part, and the interesting thing with we're exploring multiple different options to make better value for the, for our users as we, as we treat.Swyx [00:43:03]: I feel like there's a little bit of a conflation of inference time compute here in a sense of like, one, you can infer算 compute with the model, the thinking model. And then two, you can infersin compute by searching and reasoning. I wonder if there that gets in the way, like when you presumably, you've tested thinking, plus deep research, if the thinking actually does a little bit of verification. And then there's a little bit of thinking, plus deep research. Maybe it saves you some time or it like tries to draw too much from its internal knowledge and then therefore searches less, you know, like does it step on each other?Aarush [00:43:36]: Yeah, no, I think that's a, that's a really nice call out. And this also goes back to the kind of use case. The reason I bring that up is there are certain things that I can tell you from model memory last year, the Fed did X number of updates and so on. But unless I sourced it, it's going to be hallucinated. Yeah, like one is the hallucination or even if I got it right, as a user, I'd be very wary of that number unless I'm able to like source the .gov website for it and so on. Right. So that's another challenge. Like, there are things that you might not optimally spend time verifying, even though the models like, like, this is a very common fact the model already knows and it's able to like reason over and balancing that out between trying to leverage the model memory versus being able to ground this in, is in, you know, some kind of a source is the challenging part. And I think as, as like you rightly called out with the thinking models, this is even more pronounced because the models know more, they're able to like draw second order insights more just by reasoning over.Swyx [00:44:44]: Technically, they don't know more, they just use their internal knowledge more. Right?Aarush [00:44:48]: Yes, but also like, for example, things like math.Swyx [00:44:52]: I see, they've been, they've been post trained to do better math.Aarush [00:44:55]: Yeah, I think they just, they probably do way better job and in, like in, in that, so in that sense, they.Technical challenges in Deep ResearchSwyx [00:45:02]: Yeah, I mean, obviously reasoning is a topic of huge interest and people want to know what a engineering best practice is. Like, we think we know, like, you know, how to prompt them better, but engineering with them, I think also very, very unknown. Again, you guys are going to be the first to figure it out.Aarush [00:45:19]: Yeah, definitely interesting times and yeah. No pressure, Mokka. If you have tips, let us know.Swyx [00:45:25]: While we're on the sort of technical, elements and technical bend, I'm interested in like other parts of the deep research tech stack that might be worth calling out. Any hard problems that you solved just more generally?Aarush [00:45:37]: Yeah, I think the iterative planning one to do it in a generalizable way. Yeah, that was the thing I was most wary about. Like, you don't want to go down the route of being able to teach how to plan iteratively per domain or like per type of problem. Like, like even in the outgoing back to the ontology, if, if you had to teach them all. For every single type of ontology, how to come up with these traces of planning, that would have been a nightmarish. So trying to do that in a super data efficient way by, you know, leveraging a lot of like things, model memory, as well as like, there's this very tricky balance when you work on like, on the product side of any of these models is knowing how to post in it just enough without losing things that it knows in pre training, basically not overfitting in the most trivial sense, I guess. But yeah, so the techniques, their data augmentations there and multiple experiments to tune this trade off. I think that's, that's one of the challenges. Yeah.Swyx [00:46:37]: On the orchestration side, this is basically you're spinning up a job. I'm an orchestration nerd. So how do you do that?Aarush [00:46:43]: Is like a sub internal tool? Yeah, so we built this asynchronous platform for deep research, which is basically to like most of our interactions before this were like sync in nature. Like, yeah. Yeah.Swyx [00:46:56]: All the chat things are sync, right? Exactly. And now, now you can leave the chat and come back. Exactly.Aarush [00:47:01]: And close your computer. And now it's on Android and rolling out on iOS.Mukund [00:47:06]: So I saw you say that.Swyx [00:47:10]: I told you we switch it on sometimes. Okay.Mukund [00:47:13]: Like you're reminding him, right?Swyx [00:47:14]: Yeah, we wrapped on all Android phones and then iOS is this week. But yeah, what's, what's neat though, is like, you can close your computer, get a notification on your phone. Right. And so on. So it's some kind of e-sync engine that you made.Aarush [00:47:29]: Yes, yes. So we, the other one is this notion of synchronicity and the user able to leave. But also if you're, if you build like five, six minute jobs, they're bound to be like failures and you don't want to like lose your progress and so on. So this notion of like keeping state, knowing what to retry and kind of keep the journey going. Is there a public name for this or just some internal thing?Swyx [00:47:52]: No, I don't think there's a public name for this.Aarush [00:47:54]: Yeah.Swyx [00:47:54]: All right. Data scientists would be like, this is a Spark job or, you know, it's like a Wraith, you know, thing or whatever in the old Google days might be like MapReduce or, you know, whatever, but like it's, it's a different scale and nature of work than those things. So we just, I'm trying to find a name for this. And right now, this is our opportunity to name it. We can name it now. The classic name is I used to work in this area. This is what I'm asking. So it's, it's workflows. Nice. Yeah. Sort of durable workflows.Aarush [00:48:24]: Like back when you were in AWS. Temporal.Swyx [00:48:26]: So Apache Airflow, Temporal. You guys were both at Amazon, by the way. Yeah. AWS Step Functions would be one of those where you define a graph of execution, but Step Functions are more static and would not be as able to accommodate deep research style backends. What's neat though, is we built this to be like quite flexible. So it's like, you can imagine once you start doing hour or multi-day jobs. Yeah. You have to model what the agent wants to do. Exactly. And, but also like ensure like it's stable, you know, for, for me. Like hundreds of LLM calls. Yeah. It's boring, but like, you know, this is the thing that makes it run autonomously, you know? Right. Yeah. So like it's, yeah. Anyway, I'm excited about it. Just to close up the opening eye thing. I would say opening eye easily beat you on marketing. And I think it's because you don't launch your benchmarks. And my question to you is, should you care about benchmarks? Should you care about humanities last exam or not MMLU, but whatever. The like, I think benchmarks are great. Yeah. The thing we wanted to avoid is like the day Kobe Bryant entered the league, who was the president's nephew and like weird, like He's a big Kobe fan. Okay. Just like these like weird things that like nobody talks that way. So like, why would we over-solve for like some sort of a benchmark that doesn't necessarily represent the product experience we want to build. Nevertheless, like benchmarks are great for the industry and like rally a community and help us like understand where we're at. I don't know. Do you have any?Aarush [00:49:51]: No, I think you kind of hit the points. I think the, for us, our primary goal is like solving the deep research user value for the user use case. The benchmarks, at least the ones that we are seeing, they don't directly translate to the product. There's definitely some technical challenges that you can benchmark against, but they don't really like if I do great on HLE, that doesn't really mean I'm a great deep researcher. So we want to avoid that. We want to avoid going into that rabbit hole a bit. But we also feel like, yeah, benchmarks are great, especially in the whole gen AI space with like models coming every other day and everybody claiming to be like soda. So it's tricky. The other big challenge with benchmarks, especially when it comes to like the models these days, is the output space entropy is like everything is like a text. And so there's a notion of verifying even if you got the right answer, different labs do it in like different ways. And, but we all come back to it. We all compare numbers. So there's a lot of, you know, art slash figuring out like how you verify this or how you run this in a level plane. But yeah, so I think the straight offs is definitely value to doing benchmarks.Swyx [00:51:05]: But at the same time, we also like a selfish PM perspective. Benchmarks are a really great way to motivate researchers. Like make number go up. Exactly. Or just like prove you're the best. Like it's like a really good way of like rallying the researchers within your company. Like I used to work on the MLPerf benchmarks and like that was like, yeah, you'd put like a bunch of engineers in a room and in a few days they do like amazing performance improvements on our TPU stack and things like that. Right. So just like having a competitive nature and a pressure like really motivates people. There's one benchmark that is impossible to benchmark, but I just want to leave you with it, which is that deep research. Most people are chasing this idea of discovering new ideas. And deep research right now will summarize the web in a way that. Yeah. Is much more readable, but it won't. You know, what will it take to discover new things from the things that you've searched?Can Deep Research discover new insights?Aarush [00:51:56]: First, I think the thinking style models definitely help here because they are significantly better on how they reason natively and being able to draw these second order insights, which is like very premise. Like if you can't do that, you can't think of doing what you mentioned. So that's that's one step in. The other thing is. I think it also depends on the domain. So sometimes you can drift with a model for like new hypothesis, but depending on the domain, you might not be able to verify that hypothesis. Right. So like coding math, there are reasonably good tools that the model already knows to interact with. And you can run a verifier, test the hypothesis and so on. Like even if you think about it from a purely agent perspective saying, hey, I have this hypothesis in this area. Go figure out and come back to me. Right. But let's say you're a chemist. Right. So what are you going to do that? We don't have like synthetic environments yet where the model is able to verify these hypotheses by playing in a playground and have this like a very accurate verifier or a reward signal. The computer uses another one where there are both in the open source research and so on. There's like nice playgrounds coming up. So I think for if you're talking about truly being able to come up with my personal opinion is the model doesn't have to do the second order thinking. And so on that we're seeing now with these new models, but also be able to play and test that out in an environment where you can verify and give it feedback so that it can continue trading. Yeah.Swyx [00:53:28]: So basically like code sandboxes for now.Aarush [00:53:32]: Yeah. Yeah. So in those kind of cases, I think, yeah, it's a little bit more easy to envision this like end to end, but not for all domains. Physics engines. Yeah.Alessio [00:53:42]: So if you think about agents more broadly, there's like a lot of things. Right. That go into it. What do you think are like the most valuable pieces that people should be spending time on? Like things that come to mind that I'm seeing a lot of early stage companies is like memory, you know, like we already touched on evals. We touched a little bit on a tool call. There's kind of like the odd piece, like should this agent be able to access this? If yes, how do you verify that? What are things that you want more people to work on that will be helpful to you?Open challenges in agentsMukund [00:54:11]: I can take a stab at this from the lens of like deep research. Right. Like I think some of the things that we're really interested in in how we can push this agent are one like similar to memories, like personalization. Right. Like if I'm giving you a research report, the way I would give it to you if you're a 15 year old in high school should be totally different to the way I give it to you if you're like a PhD or postdoc. Right. You can prompt it. You can prompt it. Right. But the second thing, though, is like it should like ideally know where you're at and like everything, you know, up to that point. Right. And kind of further customized. Right. Have this understanding of like where you are in your learning journeys. I think modality will be also really interesting. Like right now we're text in, text out. We should go multimodal in. Right. But also multimodal out. Right. Like I would love if my reports are not just text, but like charts, maps, images, like make it super interactive and multimodal. Right. And optimized for the type of consumption. Right. So the way in which I might put together an academic paper should be totally different to the way I'm trying to do like a learning program for a kid. Right. And just the way it's structured. Ideally, like you want to do things with generative UI and things like that to really customize reports. I think those are definitely things that I'm personally interested when it comes to like a research agent. I think the other part that's super important is just like we will reach the limits of the open web and you want to be able to like a lot of the things that people care about are things that are in their own documents. Their own corpuses, things that are within subscriptions that they personally really care about. Like especially as you go more niche into specific industries. And ideally, you want ways for people to be able to complement their deep research experience with that content in order to further customize their answers.Aarush [00:55:56]: There's two answers to this. So one is I feel in terms of like the approach for us, at least for me, rather trying to figure out the core mission for like an agent building that. I feel like it's still early days for us. Like to try to platformatize or like try to build these. Oh, there are these five horizontal pieces and you can plug and play and build your own agent. My personal opinion is we are not there yet. In order to build a super engaging agent, I would if I were to start thinking of a new idea, I would I would start from the idea and try to just just do that one thing really well. Yes, at some point there will be a time where like these common pieces can be pulled out. And then. Yeah. And, you know, platformatized. I know there's a lot of work across companies and in the open source community about providing these tools to really build agents very easily. I think those are super useful to start building agents. But at some point, once those tools enable you to build the basic layers, I think me as an individual would would, you know, try to focus on really curating one experience before going super broad. Yeah.Alessio [00:57:04]: We have Bret Taylor from Sierra and he said they mostly built everything.Swyx [00:57:08]: Which is very sad for VCs.Aarush [00:57:10]: I want to find the next great framework and tooling and all that. But the space is moving so fast. Like, like the problem I described might be obsolete six months from now. And I don't know. Like, we'll fix it with one more LLM ops platform.Mukund [00:57:25]: Yes. Yes.Swyx [00:57:26]: Okay. So just just a final final point on just plugging your talk. People will be hearing this before your talk. What are you going to talk about? What are you looking forward to in New York? I would love to, like, actually learn from you guys. Like, what would you like us to do? Talk about now that we've had this conversation with you? Yeah. Yeah. What would what do you think people would find most interesting? I think a little bit of implementation and a little bit of vision, like kind of 50 50. And I think both of you can can sort of fill those roles very well. Everyone, you know, looks at you. You're very polished Google products. And I think Google always does does polish very well. But everyone will have to want to want like deep research for their industry. He's invested in deep research for finance. Yeah. And they focus on their their thing. And there will be deep researches for everything. Right. Like you have created a category here that OpenAI has cloned. And so, like, OK, let's let's talk about, like, what are the hard problems in this brand of agent that is probably the first real product market fit agent? I would say more so than the computer use ones. This is the one where, like, yeah, people are like easily pays for $200 worth a month worth of stuff, probably 2000 once you get it really good. So I'm like, OK, let's talk about like how to do this right from the people who did it. And then where is this going? So, yeah. Yeah. Yeah. It's very simple.Aarush [00:58:37]: Happy to talk about that.Swyx [00:58:39]: Yeah. Thank Yeah. For me as well. You know, I'm also curious to see you interact with the other speakers because then, you know, there will be other sort of agent problems. And I'm very interested in personalization. Very interested in memory. I think those are related problems. Planning, orchestration, all those things. Often security, something that we haven't talked about. There's a lot of the web that's behind off walls. Can I how do I delegate to you my credentials so that you can go and search the things that I have access to? I don't think it's that hard. You know, it's just, you know, people have to get their protocols together. And that's what conferences like that is hopefully meant to achieve. Yeah.Aarush: No, I'm super excited. I think for us, like it's we often like live and breathe within Google and which is like a really big place. But it's really nice to like take a step back. Meet people like approaching this problem at other companies or totally different industries. Right. Like inevitably, at least where we work, we're very consumer focused space. I see. Right. Yeah.Swyx: I'm more B2B. It's also really great to understand, like, OK, what's going on within the B2B space and like within different verticals. Yeah. The first thing they want to do is do research for my own docs. Right. My company docs. Yeah. So, yeah, obviously, you're going to get asked for that. Yeah. I mean, there'll be there'll be more to discuss. I'm really looking forward to your talk. And yeah. Thanks for joining us. Get full access to Latent.Space at www.latent.space/subscribe
-
 Bee AI: The Wearable Ambient Agent
Bee AI: The Wearable Ambient AgentFrom 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2025-02-13 18:07
Bundle tickets for AIE Summit NYC have now sold out. You can now sign up for the livestream — where we will be making a big announcement soon. NYC-based readers and Summit attendees should check out the meetups happening around the Summit.2024 was a very challenging year for AI Hardware. After the buzz of CES last January, 2024 was marked by the meteoric rise and even harder fall of AI Wearables companies like Rabbit and Humane, with an assist from a pre-wallpaper-app MKBHD. Even Friend.com, the first to launch in the AI pendant category, and which spurred Rewind AI to rebrand to Limitless and follow in their footsteps, ended up delaying their wearable ship date and launching an experimental website chatbot version. We have been cautiously excited about this category, keeping tabs on most of the top entrants, including Omi and Compass. However, to date the biggest winner still standing from the AI Wearable wars is Bee AI, founded by today's guests Maria and Ethan. Bee is an always on hardware device with beamforming microphones, 7 day battery life and a mute button, that can be worn as a wristwatch or a clip-on pin, backed by an incredible transcription, diarization and very long context memory processing pipeline that helps you to remember your day, your todos, and even perform actions by operating a virtual cloud phone. This is one of the most advanced, production ready, personal AI agents we've ever seen, so we were excited to be their first podcast appearance. We met Bee when we ran the world's first Personal AI meetup in April last year.As a user of Bee (and not an investor! just a friend!) it’s genuinely been a joy to use, and we were glad to take advantage of the opportunity to ask hard questions about the privacy and legal/ethical side of things as much as the AI and Hardware engineering side of Bee. We hope you enjoy the episode and tune in next Friday for Bee’s first conference talk: Building Perfect Memory.Full YouTube Video VersionWatch this for the live demo!Show Notes* Bee Website* Ethan Sutin, Maria de Lourdes Zollo* Bee @ Personal AI Meetup* Buy Bee with Listener Discount Code!Timestamps* 00:00:00 Introductions and overview of Bee Computer* 00:01:58 Personal context and use cases for Bee* 00:03:02 Origin story of Bee and the founders' background* 00:06:56 Evolution from app to hardware device* 00:09:54 Short-term value proposition for users* 00:12:17 Demo of Bee's functionality* 00:17:54 Hardware form factor considerations* 00:22:22 Privacy concerns and legal considerations* 00:30:57 User adoption and reactions to wearing Bee* 00:35:56 CES experience and hardware manufacturing challenges* 00:41:40 Software pipeline and inference costs* 00:53:38 Technical challenges in real-time processing* 00:57:46 Memory and personal context modeling* 01:02:45 Social aspects and agent-to-agent interactions* 01:04:34 Location sharing and personal data exchange* 01:05:11 Personality analysis capabilities* 01:06:29 Hiring and future of always-on AITranscriptAlessio [00:00:04]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel Partners, and I'm joined by my co-host Swyx, founder of SmallAI.swyx [00:00:12]: Hey, and today we are very honored to have in the studio Maria and Ethan from Bee.Maria [00:00:16]: Hi, thank you for having us.swyx [00:00:20]: And you are, I think, the first hardware founders we've had on the podcast. I've been looking to have had a hardware founder, like a wearable hardware, like a wearable hardware founder for a while. I think we're going to have two or three of them this year. And you're the ones that I wear every day. So thank you for making Bee. Thank you for all the feedback and the usage. Yeah, you know, I've been a big fan. You are the speaker gift for the Engineering World's Fair. And let's start from the beginning. What is Bee Computer?Ethan [00:00:52]: Bee Computer is a personal AI system. So you can think of it as AI living alongside you in first person. So it can kind of capture your in real life. So with that understanding can help you in significant ways. You know, the obvious one is memory, but that's that's really just the base kind of use case. So recalling and reflective. I know, Swyx, that you you like the idea of journaling, but you don't but still have some some kind of reflective summary of what you experienced in real life. But it's also about just having like the whole context of a human being and understanding, you know, giving the machine the ability to understand, like, what's going on in your life. Your attitudes, your desires, specifics about your preferences, so that not only can it help you with recall, but then anything that you need it to do, it already knows, like, if you think about like somebody who you've worked with or lived with for a long time, they just know kind of without having to ask you what you would want, it's clear that like, that is the future that personal AI, like, it's just going to be very, you know, the AI is just so much more valuable with personal context.Maria [00:01:58]: I will say that one of the things that we are really passionate is really understanding this. Personal context, because we'll make the AI more useful. Think about like a best friend that know you so well. That's one of the things that we are seeing from the user. They're using from a companion standpoint or professional use cases. There are many ways to use B, but companionship and professional are the ones that we are seeing now more.swyx [00:02:22]: Yeah. It feels so dry to talk about use cases. Yeah. Yeah.Maria [00:02:26]: It's like really like investor question. Like, what kind of use case?Ethan [00:02:28]: We're just like, we've been so broken and trained. But I mean, on the base case, it's just like, don't you want your AI to know everything you've said and like everywhere you've been, like, wouldn't you want that?Maria [00:02:40]: Yeah. And don't stay there and repeat every time, like, oh, this is what I like. You already know that. And you do things for me based on that. That's I think is really cool.swyx [00:02:50]: Great. Do you want to jump into a demo? Do you have any other questions?Alessio [00:02:54]: I want to maybe just cover the origin story. Just how did you two meet? What was the was this the first idea you started working on? Was there something else before?Maria [00:03:02]: I can start. So Ethan and I, we know each other from six years now. He had a company called Squad. And before that was called Olabot and was a personal AI. Yeah, I should. So maybe you should start this one. But yeah, that's how I know Ethan. Like he was pivoting from personal AI to Squad. And there was a co-watching with friends product. I had experience working with TikTok and video content. So I had the pivoting and we launched Squad and was really successful. And at the end. The founders decided to sell that to Twitter, now X. So both of us, we joined X. We launched Twitter Spaces. We launched many other products. And yeah, till then, we basically continue to work together to the start of B.Ethan [00:03:46]: The interesting thing is like this isn't the first attempt at personal AI. In 2016, when I started my first company, it started out as a personal AI company. This is before Transformers, no BERT even like just RNNs. You couldn't really do any convincing dialogue at all. I met Esther, who was my previous co-founder. We both really interested in the idea of like having a machine kind of model or understand a dynamic human. We wanted to make personal AI. This was like more geared towards because we had obviously much limited tools, more geared towards like younger people. So I don't know if you remember in 2016, there was like a brief chatbot boom. It was way premature, but it was when Zuckerberg went up on F8 and yeah, M and like. Yeah. The messenger platform, people like, oh, bots are going to replace apps. It was like for about six months. And then everybody realized, man, these things are terrible and like they're not replacing apps. But it was at that time that we got excited and we're like, we tried to make this like, oh, teach the AI about you. So it was just an app that you kind of chatted with and it would ask you questions and then like give you some feedback.Maria [00:04:53]: But Hugging Face first version was launched at the same time. Yeah, we started it.Ethan [00:04:56]: We started out the same office as Hugging Face because Betaworks was our investor. So they had to think. They had a thing called Bot Camp. Betaworks is like a really cool VC because they invest in out there things. They're like way ahead of everybody else. And like back then it was they had something called Bot Camp. They took six companies and it was us and Hugging Face. And then I think the other four, I'm pretty sure, are dead. But and Hugging Face was the one that really got, you know, I mean, 30% success rate is pretty good. Yeah. But yeah, when we it was, it was like it was just the two founders. Yeah, they were kind of like an AI company in the beginning. It was a chat app for teenagers. A lot of people don't know that Hugging Face was like, hey, friend, how was school? Let's trade selfies. But then, you know, they built the Transformers library, I believe, to help them make their chat app better. And then they open sourced and it was like it blew up. And like they're like, oh, maybe this is the opportunity. And now they're Hugging Face. But anyway, like we were obsessed with it at that time. But then it was clear that there's some people who really love chatting and like answering questions. But it's like a lot of work, like just to kind of manually.Maria [00:06:00]: Yeah.Ethan [00:06:01]: Teach like all these things about you to an AI.Maria [00:06:04]: Yeah, there were some people that were super passionate, for example, teenagers. They really like, for example, to speak about themselves a lot. So they will reply to a lot of questions and speak about them. But most of the people, they don't really want to spend time.Ethan [00:06:18]: And, you know, it's hard to like really bring the value with it. We had like sentence similarity and stuff and could try and do, but it was like it was premature with the technology at the time. And so we pivoted. We went to YC and the long story, but like we pivoted to consumer video and that kind of went really viral and got a lot of usage quickly. And then we ended up selling it to Twitter, worked there and left before Elon, not related to Elon, but left Twitter.swyx [00:06:46]: And then I should mention this is the famous time when well, when when Elon was just came in, this was like Esther was the famous product manager who slept there.Ethan [00:06:56]: My co-founder, my former co-founder, she sleeping bag. She was the sleep where you were. Yeah, yeah, she stayed. We had left by that point.swyx [00:07:03]: She very stayed, she's famous for staying.Ethan [00:07:06]: Yeah, but later, later left or got, I think, laid off, laid off. Yeah, I think the whole product team got laid off. She was a product manager, director. But yeah, like we left before that. And then we're like, oh, my God, things are different now. You know, I think this is we really started working on again right before ChatGPT came out. But we had an app version and we kind of were trying different things around it. And then, you know, ultimately, it was clear that, like, there were some limitations we can go on, like a good question to ask any wearable company is like, why isn't this an app? Yes. Yeah. Because like.Maria [00:07:40]: Because we tried the app at the beginning.Ethan [00:07:43]: Yeah. Like the idea that it could be more of a and B comes from ambient. So like if it was more kind of just around you all the time and less about you having to go open the app and do the effort to, like, enter in data that led us down the path of hardware. Yeah. Because the sensors on this are microphones. So it's capturing and understanding audio. We started actually our first hardware with a vision component, too. And we can talk about why we're not doing that right now. But if you wanted to, like, have a continuous understanding of audio with your phone, it would monopolize your microphone. It would get interrupted by calls and you'd have to remember to turn it on. And like that little bit of friction is actually like a substantial barrier to, like, get your phone. It's like the experience of it just being with you all the time and like living alongside you. And so I think that that's like the key reason it's not an app. And in fact, we do have Apple Watch support. So anybody who has a watch, Apple Watch can use it right away without buying any hardware. Because we worked really hard to make a version for the watch that can run in the background, not super drain your battery. But even with the watch, there's still friction because you have to remember to turn it on and it still gets interrupted if somebody calls you. And you have to remember to. We send a notification, but you still have to go back and turn it on because it's just the way watchOS works.Maria [00:09:04]: One of the things that we are seeing from our Apple Watch users, like I love the Apple Watch integration. One of the things that we are seeing is that people, they start using it from Apple Watch and after a couple of days they buy the B because they just like to wear it.Ethan [00:09:17]: Yeah, we're seeing.Maria [00:09:18]: That's something that like they're learning and it's really cool. Yeah.Ethan [00:09:21]: I mean, I think like fundamentally we like to think that like a personal AI is like the mission. And it's more about like the understanding. Connecting the dots, making use of the data to provide some value. And the hardware is like the ears of the AI. It's not like integrating like the incoming sensor data. And that's really what we focus on. And like the hardware is, you know, if we can do it well and have a great experience on the Apple Watch like that, that's just great. I mean, but there's just some platform restrictions that like existing hardware makes it hard to provide that experience. Yeah.Alessio [00:09:54]: What do people do in like two or three days that then convinces them to buy it? They buy the product. This feels like a product where like after you use it for a while, you have enough data to start to get a lot of insights. But it sounds like maybe there's also like a short term.Maria [00:10:07]: From the Apple Watch users, I believe that because every time that you receive a call after, they need to go back to B and open it again. Or for example, every day they need to charge Apple Watch and reminds them to open the app every day. They feel like, okay, maybe this is too much work. I just want to wear the B and just keep it open and that's it. And I don't need to think about it.Ethan [00:10:27]: I think they see the kind of potential of it just from the watch. Because even if you wear it a day, like we send a summary notification at the end of the day about like just key things that happened to you in your day. And like I didn't even think like I'm not like a journaling type person or like because like, oh, I just live the day. Why do I need to like think about it? But like it's actually pretty sometimes I'm surprised how interesting it is to me just to kind of be like, oh, yeah, that and how it kind of fits together. And I think that's like just something people get immediately with the watch. But they're like, oh, I'd like an easier watch. I'd like a better way to do this.swyx [00:10:58]: It's surprising because I only know about the hardware. But I use the watch as like a backup for when I don't have the hardware. I feel like because now you're beamforming and all that, this is significantly better. Yeah, that's the other thing.Ethan [00:11:11]: We have way more control over like the Apple Watch. You're limited in like you can't set the gain. You can't change the sample rate. There's just very limited framework support for doing anything with audio. Whereas if you control it. Then you can kind of optimize it for your use case. The Apple Watch isn't meant to be kind of recording this. And we can talk when we get to the part about audio, why it's so hard. This is like audio on the hardest level because you don't know it has to work in all environments or you try and make it work as best as it can. Like this environment is very great. We're in a studio. But, you know, afterwards at dinner in a restaurant, it's totally different audio environment. And there's a lot of challenges with that. And having really good source audio helps. But then there's a lot more. But with the machine learning that still is, you know, has to be done to try and account because like you can tune something for one environment or another. But it'll make one good and one bad. And like making something that's flexible enough is really challenging.Alessio [00:12:10]: Do we want to do a demo just to set the stage? And then we kind of talk about.Maria [00:12:14]: Yeah, I think we can go like a walkthrough and the prod.Alessio [00:12:17]: Yeah, sure.swyx [00:12:17]: So I think we said I should. So for listeners, we'll be switching to video. That was superimposed on. And to this video, if you want to see it, go to our YouTube, like and subscribe as always. Yeah.Maria [00:12:31]: And by the bee. Yes.swyx [00:12:33]: And by the bee. While you wait. While you wait. Exactly. It doesn't take long.Maria [00:12:39]: Maybe you should have a discount code just for the listeners. Sure.swyx [00:12:43]: If you want to offer it, I'll take it. All right. Yeah. Well, discount code Swyx. Oh s**t. Okay. Yeah. There you go.Ethan [00:12:49]: An important thing to mention also is that the hardware is meant to work with the phone. And like, I think, you know, if you, if you look at rabbit or, or humane, they're trying to create like a new hardware platform. We think that the phone's just so dominant and it will be until we have the next generation, which is not going to be for five, you know, maybe some Orion type glasses that are cheap enough and like light enough. Like that's going to take a long time before with the phone rather than trying to just like replace it. So in the app, we have a summary of your days, but at the top, it's kind of what's going on now. And that's updating your phone. It's updating continuously. So right now it's saying, I'm discussing, you know, the development of, you know, personal AI, and that's just kind of the ongoing conversation. And then we give you a readable form. That's like little kind of segments of what's the important parts of the conversations. We do speaker identification, which is really important because you don't want your personal AI thinking you said something and attributing it to you when it was just somebody else in the conversation. So you can also teach it other people's voices. So like if some, you know, somebody close to you, so it can start to understand your relationships a little better. And then we do conversation end pointing, which is kind of like a task that didn't even exist before, like, cause nobody needed to do this. But like if you had somebody's whole day, how do you like break it into logical pieces? And so we use like not just voice activity, but other signals to try and split up because conversations are a little fuzzy. They can like lead into one, can start to the next. So also like the semantic content of it. When a conversation ends, we run it through larger models to try and get a better, you know, sense of the actual, what was said and then summarize it, provide key points. What was the general atmosphere and tone of the conversation and potential action items that might've come of that. But then at the end of the day, we give you like a summary of all your day and where you were and just kind of like a step-by-step walkthrough of what happened and what were the key points. That's kind of just like the base capture layer. So like if you just want to get a kind of glimpse or recall or reflect that's there. But really the key is like all of this is now like being influenced on to generate personal context about you. So we generate key items known to be true about you and that you can, you know, there's a human in the loop aspect is like you can, you have visibility. Right. Into that. And you can, you know, I have a lot of facts about technology because that's basically what I talk about all the time. Right. But I do have some hobbies that show up and then like, how do you put use to this context? So I kind of like measure my day now and just like, what is my token output of the day? You know, like, like as a human, how much information do I produce? And it's kind of measured in tokens and it turns out it's like around 200,000 or so a day. But so in the recall case, we have, um. A chat interface, but the key here is on the recall of it. Like, you know, how do you, you know, I probably have 50 million tokens of personal context and like how to make sense of that, make it useful. So I can ask simple, like, uh, recall questions, like details about the trip I was on to Taiwan, where recently we're with our manufacturer and, um, in real time, like it will, you know, it has various capabilities such as searching through your, your memories, but then also being able to search the web or look at my calendar, we have integrations with Gmail and calendars. So like connecting the dots between the in real life and the digital life. And, you know, I just asked it about my Taiwan trip and it kind of gives me the, the breakdown of the details, what happened, the issues we had around, you know, certain manufacturing problems and it, and it goes back and references the conversation so I can, I can go back to the source. Yeah.Maria [00:16:46]: Not just the conversation as well, the integrations. So we have as well Gmail and Google calendar. So if there is something there that was useful to have more context, we can see that.Ethan [00:16:56]: So like, and it can, I never use the word agentic cause it's, it's cringe, but like it can search through, you know, if I, if I'm brainstorming about something that spans across, like search through my conversation, search the email, look at the calendar and then depending on what's needed. Then synthesize, you know, something with all that context.Maria [00:17:18]: I love that you did the Spotify wrapped. That was pretty cool. Yeah.Ethan [00:17:22]: Like one thing I did was just like make a Spotify wrap for my 2024, like of my life. You can do that. Yeah, you can.Maria [00:17:28]: Wait. Yeah. I like those crazy.Ethan [00:17:31]: Make a Spotify wrapped for my life in 2024. Yeah. So it's like surprisingly good. Um, it like kind of like game metrics. So it was like you visited three countries, you shipped, you know, XMini, beta. Devices.Maria [00:17:46]: And that's kind of more personal insights and reflection points. Yeah.swyx [00:17:51]: That's fascinating. So that's the demo.Ethan [00:17:54]: Well, we have, we can show something that's in beta. I don't know if we want to do it. I don't know.Maria [00:17:58]: We want to show something. Do it.Ethan [00:18:00]: And then we can kind of fit. Yeah.Maria [00:18:01]: Yeah.Ethan [00:18:02]: So like the, the, the, the vision is also like, not just about like AI being with you in like just passively understanding you through living your experience, but also then like it proactively suggesting things to you. Yeah. Like at the appropriate time. So like not just pool, but, but kind of, it can step in and suggest things to you. So, you know, one integration we have that, uh, is in beta is with WhatsApp. Maria is asking for a recommendation for an Italian restaurant. Would you like me to look up some highly rated Italian restaurants nearby and send her a suggestion?Maria [00:18:34]: So what I did, I just sent to Ethan a message through WhatsApp in his own personal phone. Yeah.Ethan [00:18:41]: So, so basically. B is like watching all my incoming notifications. And if it meets two criteria, like, is it important enough for me to raise a suggestion to the user? And then is there something I could potentially help with? So this is where the actions come into place. So because Maria is my co-founder and because it was like a restaurant recommendation, something that it could probably help with, it proposed that to me. And then I can, through either the chat and we have another kind of push to talk walkie talkie style button. It's actually a multi-purpose button to like toggle it on or off, but also if you push to hold, you can talk. So I can say, yes, uh, find one and send it to her on WhatsApp is, uh, an Android cloud phone. So it's, uh, going to be able to, you know, that has access to all my accounts. So we're going to abstract this away and the execution environment is not really important, but like we can go into technically why Android is actually a pretty good one right now. But, you know, it's searching for Italian restaurants, you know, and we don't have to watch this. I could be, you know, have my ear AirPods in and in my pocket, you know, it's going to go to WhatsApp, going to find Maria's thread, send her the response and then, and then let us know. Oh my God.Alessio [00:19:56]: But what's the, I mean, an Italian restaurant. Yeah. What did it choose? What did it choose? It's easy to say. Real Italian is hard to play. Exactly.Ethan [00:20:04]: It's easy to say. So I doubt it. I don't know.swyx [00:20:06]: For the record, since you have the Italians, uh, best Italian restaurant in SF.Maria [00:20:09]: Oh my God. I still don't have one. What? No.Ethan [00:20:14]: I don't know. Successfully found and shared.Alessio [00:20:16]: Let's see. Let's see what the AI says. Bottega. Bottega? I think it's Bottega.Maria [00:20:21]: Have you been to Bottega? How is it?Alessio [00:20:24]: It's fine.Maria [00:20:25]: I've been to one called like Norcina, I think it was good.Alessio [00:20:29]: Bottega is on Valencia Street. It's fine. The pizza is not good.Maria [00:20:32]: It's not good.Alessio [00:20:33]: Some of the pastas are good.Maria [00:20:34]: You know, the people I'm sorry to interrupt. Sorry. But there is like this Delfina. Yeah. That here everybody's like, oh, Pizzeria Delfina is amazing. I'm overrated. This is not. I don't know. That's great. That's great.swyx [00:20:46]: The North Beach Cafe. That place you took us with Michele last time. Vega. Oh.Alessio [00:20:52]: The guy at Vega, Giuseppe, he's Italian. Which one is that? It's in Bernal Heights. Ugh. He's nice. He's not nice. I don't know that one. What's the name of the place? Vega. Vega. Vega. Cool. We got the name. Vega. But it's not Vega.Maria [00:21:02]: It's Italian. Whatswyx [00:21:10]: Vega. Vega.swyx [00:21:16]: Vega. Vega. Vega. Vega. Vega. Vega. Vega. Vega. Vega.Ethan [00:21:29]: Vega. Vega. Vega. Vega. Vega.Ethan [00:21:40]: We're going to see a lot of innovation around hardware and stuff, but I think the real core is being able to do something useful with the personal context. You always had the ability to capture everything, right? We've always had recorders, camcorders, body cameras, stuff like that. But what's different now is we can actually make sense and find the important parts in all of that context.swyx [00:22:04]: Yeah. So, and then one last thing, I'm just doing this for you, is you also have an API, which I think I'm the first developer against. Because I had to build my own. We need to hire a developer advocate. Or just hire AI engineers. The point is that you should be able to program your own assistant. And I tried OMI, the former friend, the knockoff friend, and then real friend doesn't have an API. And then Limitless also doesn't have an API. So I think it's very important to own your data. To be able to reprocess your audio, maybe. Although, by default, you do not store audio. And then also just to do any corrections. There's no way that my needs can be fully met by you. So I think the API is very important.Ethan [00:22:47]: Yeah. And I mean, I've always been a consumer of APIs in all my products.swyx [00:22:53]: We are API enjoyers in this house.Ethan [00:22:55]: Yeah. It's very frustrating when you have to go build a scraper. But yeah, it's for sure. Yeah.swyx [00:23:03]: So this whole combination of you have my location, my calendar, my inbox. It really is, for me, the sort of personal API.Alessio [00:23:10]: And is the API just to write into it or to have it take action on external systems?Ethan [00:23:16]: Yeah, we're expanding it. It's right now read-only. In the future, very soon, when the actions are more generally available, it'll be fully supported in the API.Alessio [00:23:27]: Nice. I'll buy one after the episode.Ethan [00:23:30]: The API thing, to me, is the most interesting. Yeah. We do have real-time APIs, so you can even connect a socket and connect it to whatever you want it to take actions with. Yeah. It's too smart for me.Alessio [00:23:43]: Yeah. I think when I look at these apps, and I mean, there's so many of these products, we launch, it's great that I can go on this app and do things. But most of my work and personal life is managed somewhere else. Yeah. So being able to plug into it. Integrate that. It's nice. I have a bunch of more, maybe, human questions. Sure. I think maybe people might have. One, is it good to have instant replay for any argument that you have? I can imagine arguing with my wife about something. And, you know, there's these commercials now where it's basically like two people arguing, and they're like, they can throw a flag, like in football, and have an instant replay of the conversation. I feel like this is similar, where it's almost like people cannot really argue anymore or, like, lie to each other. Because in a world in which everybody adopts this, I don't know if you thought about it. And also, like, how the lies. You know, all of us tell lies, right? How do you distinguish between when I'm, there's going to be sometimes things that contradict each other, because I might say something publicly, and I might think something, really, that I tell someone else. How do you handle that when you think about building a product like this?Maria [00:24:48]: I would say that I like the fact that B is an objective point of view. So I don't care too much about the lies, but I care more about the fact that can help me to understand what happened. Mm-hmm. And the emotions in a really objective way, like, really, like, critical and objective way. And if you think about humans, they have so many emotions. And sometimes something that happened to me, like, I don't know, I would feel, like, really upset about it or really angry or really emotional. But the AI doesn't have those emotions. It can read the conversation, understand what happened, and be objective. And I think the level of support is the one that I really like more. Instead of, like, oh, did this guy tell me a lie? I feel like that's not exactly, like, what I feel. I find it curious for me in terms of opportunity.Alessio [00:25:35]: Is the B going to interject in real time? Say I'm arguing with somebody. The B is like, hey, look, no, you're wrong. What? That person actually said.Ethan [00:25:43]: The proactivity is something we're very interested in. Maybe not for, like, specifically for, like, selling arguments, but more for, like, and I think that a lot of the challenge here is, you know, you need really good reasoning to kind of pull that off. Because you don't want it just constantly interjecting, because that would be super annoying. And you don't want it to miss things that it should be interjecting. So, like, it would be kind of a hard task even for a human to be, like, just come in at the right times when it's appropriate. Like, it would take the, you know, with the personal context, it's going to be a lot better. Because, like, if somebody knows about you, but even still, it requires really good reasoning to, like, not be too much or too little and just right.Maria [00:26:20]: And the second part about, well, like, some things, you know, you say something to somebody else, but after I change my mind, I send something. Like, it's every time I have, like, different type of conversation. And I'm like, oh, I want to know more about you. And I'm like, oh, I want to know more about you. I think that's something that I found really fascinating. One of the things that we are learning is that, indeed, humans, they evolve over time. So, for us, one of the challenges is actually understand, like, is this a real fact? Right. And so far, what we do is we give, you know, to the, we have the human in the loop that can say, like, yes, this is true, this is not. Or they can edit their own fact. For sure, in the future, we want to have all of that automatized inside of the product.Ethan [00:26:57]: But, I mean, I think your question kind of hits on, and I know that we'll talk about privacy, but also just, like, if you have some memory and you want to confirm it with somebody else, that's one thing. But it's for sure going to be true that in the future, like, not even that far into the future, that it's just going to be kind of normalized. And we're kind of in a transitional period now. And I think it's, like, one of the key things that is for us to kind of navigate that and make sure we're, like, thinking of all the consequences. And how to, you know, make the right choices in the way that everything's designed. And so, like, it's more beneficial than it could be harmful. But it's just too valuable for your AI to understand you. And so if it's, like, MetaRay bands or the Google Astra, I think it's just people are going to be more used to it. So people's behaviors and expectations will change. Whether that's, like, you know, something that is going to happen now or in five years, it's probably in that range. And so, like, I think we... We kind of adapt to new technologies all the time. Like, when the Ring cameras came out, that was kind of quite controversial. It's like... But now it's kind of... People just understand that a lot of people have cameras on their doors. And so I think that...Maria [00:28:09]: Yeah, we're in a transitional period for sure.swyx [00:28:12]: I will press on the privacy thing because that is the number one thing that everyone talks about. Obviously, I think in Silicon Valley, people are a little bit more tech-forward, experimental, whatever. But you want to go mainstream. You want to sell to consumers. And we have to worry about this stuff. Baseline question. The hardest version of this is law. There are one-party consent states where this is perfectly legal. Then there are two-party consent states where they're not. What have you come around to this on?Ethan [00:28:38]: Yeah, so the EU is a totally different regulatory environment. But in the U.S., it's basically on a state-by-state level. Like, in Nevada, it's single-party. In California, it's two-party. But it's kind of untested. You know, it's different laws, whether it's a phone call, whether it's in person. In a state like California, it's two-party. Like, anytime you're in public, there's no consent comes into play because the expectation of privacy is that you're in public. But we process the audio and nothing is persisted. And then it's summarized with the speaker identification focusing on the user. Now, it's kind of untested on a legal, and I'm not a lawyer, but does that constitute the same as, like, a recording? So, you know, it's kind of a gray area and untested in law right now. I think that the bigger question is, you know, because, like, if you had your Ray-Ban on and were recording, then you have a video of something that happened. And that's different than kind of having, like, an AI give you a summary that's focused on you that's not really capturing anybody's voice. You know, I think the bigger question is, regardless of the legal status, like, what is the ethical kind of situation with that? Because even in Nevada that we're—or many other U.S. states where you can record. Everything. And you don't have to have consent. Is it still, like, the right thing to do? The way we think about it is, is that, you know, we take a lot of precautions to kind of not capture personal information of people around. Both through the speaker identification, through the pipeline, and then the prompts, and the way we store the information to be kind of really focused on the user. Now, we know that's not going to, like, satisfy a lot of people. But I think if you do try it and wear it again. It's very hard for me to see anything, like, if somebody was wearing a bee around me that I would ever object that it captured about me as, like, a third party to it. And like I said, like, we're in this transitional period where the expectation will just be more normalized. That it's, like, an AI. It's not capturing, you know, a full audio recording of what you said. And it's—everything is fully geared towards helping the person kind of understand their state and providing valuable information to them. Not about, like, logging details about people they encounter.Alessio [00:30:57]: You know, I've had the same question also with the Zoom meeting transcribers thing. I think there's kind of, like, the personal impact that there's a Firefly's AI recorder. Yeah. I just know that it's being recorded. It's not like a—I don't know if I'm going to say anything different. But, like, intrinsically, you kind of feel—because it's not pervasive. And I'm curious, especially, like, in your investor meetings. Do people feel differently? Like, have you had people ask you to, like, turn it off? Like, in a business meeting, to not record? I'm curious if you've run into any of these behaviors.Maria [00:31:29]: You know what's funny? On my end, I wear it all the time. I take my coffee, a blue bottle with it. Or I work with it. Like, obviously, I work on it. So, I wear it all the time. And so far, I don't think anybody asked me to turn it off. I'm not sure if because they were really friendly with me that they know that I'm working on it. But nobody really cared.swyx [00:31:48]: It's because you live in SF.Maria [00:31:49]: Actually, I've been in Italy as well. Uh-huh. And in Italy, it's a super privacy concern. Like, Europe is a super privacy concern. And again, they're nothing. Like, it's—I don't know. Yeah. That, for me, was interesting.Ethan [00:32:01]: I think—yeah, nobody's ever asked me to turn it off, even after giving them full demos and disclosing. I think that some people have said, well, my—you know, in a personal relationship, my partner initially was, like, kind of uncomfortable about it. We heard that from a few users. And that was, like, more in just, like— It's not like a personal relationship situation. And the other big one is people are like, I do like it, but I cannot wear this at work. I guess. Yeah. Yeah. Because, like, I think I will get in trouble based on policies or, like, you know, if you're wearing it inside a research lab or something where you're working on things that are kind of sensitive that, like—you know, so we're adding certain features like geofencing, just, like, at this location. It's just never active.swyx [00:32:50]: I mean, I've often actually explained to it the other way, where maybe you only want it at work, so you never take it from work. And it's just a work device, just like your Zoom meeting recorder is a work device.Ethan [00:33:09]: Yeah, professionals have been a big early adopter segment. And you say in San Francisco, but we have out there our daily shipment of over 100. If you go look at the addresses, Texas, I think, is our biggest state, and Florida, just the biggest states. A lot of professionals who talk for, and we didn't go out to build it for that use case, but I think there is a lot of demand for white-collar people who talk for a living. And I think we're just starting to talk with them. I think they just want to be able to improve their performance around, understand what they were doing.Alessio [00:33:47]: How do you think about Gong.io? Some of these, for example, sales training thing, where you put on a sales call and then it coaches you. They're more verticalized versus having more horizontal platform.Ethan [00:33:58]: I am not super familiar with those things, because like I said, it was kind of a surprise to us. But I think that those are interesting. I've seen there's a bunch of them now, right? Yeah. It kind of makes sense. I'm terrible at sales, so I could probably use one. But it's not my job, fundamentally. But yeah, I think maybe it's, you know, we heard also people with restaurants, if they're able to understand, if they're doing well.Maria [00:34:26]: Yeah, but in general, I think a lot of people, they like to have the double check of, did I do this well? Or can you suggest me how I can do better? We had a user that was saying to us that he used for interviews. Yeah, he used job interviews. So he used B and after asked to the B, oh, actually, how do you think my interview went? What I should do better? And I like that. And like, oh, that's actually like a personal coach in a way.Alessio [00:34:50]: Yeah. But I guess the question is like, do you want to build all of those use cases? Or do you see B as more like a platform where somebody is going to build like, you know, the sales coach that connects to B so that you're kind of the data feed into it?Ethan [00:35:02]: I don't think this is like a data feed, more like an understanding kind of engine and like definitely. In the future, having third parties to the API and building out for all the different use cases is something that we want to do. But the like initial case we're trying to do is like build that layer for all that to work. And, you know, we're not trying to build all those verticals because no startup could do that well. But I think that it's really been quite fascinating to see, like, you know, I've done consumer for a long time. Consumer is very hard to predict, like, what's going to be. It's going to be like the thing that's the killer feature. And so, I mean, we really believe that it's the future, but we don't know like what exactly like process it will take to really gain mass adoption.swyx [00:35:50]: The killer consumer feature is whatever Nikita Beer does. Yeah. Social app for teens.Ethan [00:35:56]: Yeah, well, I like Nikita, but, you know, he's good at building bootstrap companies and getting them very viral. And then selling them and then they shut down.swyx [00:36:05]: Okay, so you just came back from CES.Maria [00:36:07]: Yeah, crazy. Yeah, tell us. It was my first time in Vegas and first time CES, both of them were overwhelming.swyx [00:36:15]: First of all, did you feel like you had to do it because you're in consumer hardware?Maria [00:36:19]: Then we decided to be there and to have a lot of partners and media meetings, but we didn't have our own booth. So we decided to just keep that. But we decided to be there and have a presence there, even just us and speak with people. It's very hard to stand out. Yeah, I think, you know, it depends what type of booth you have. I think if you can prepare like a really cool booth.Ethan [00:36:41]: Have you been to CES?Maria [00:36:42]: I think it can be pretty cool.Ethan [00:36:43]: It's massive. It's huge. It's like 80,000, 90,000 people across the Venetian and the convention center. And it's, to me, I always wanted to go just like...Maria [00:36:53]: Yeah, you were the one who was like...swyx [00:36:55]: I thought it was your idea.Ethan [00:36:57]: I always wanted to go just as a, like, just as a fan of...Maria [00:37:01]: Yeah, you wanted to go anyways.Ethan [00:37:02]: Because like, growing up, I think CES like kind of peaked for a while and it was like, oh, I want to go. That's where all the cool, like... gadgets, everything. Yeah, now it's like SmartBitch and like, you know, vacuuming the picks up socks. Exactly.Maria [00:37:13]: There are a lot of cool vacuums. Oh, they love it.swyx [00:37:15]: They love the Roombas, the pick up socks.Maria [00:37:16]: And pet tech. Yeah, yeah. And dog stuff.swyx [00:37:20]: Yeah, there's a lot of like robot stuff. New TVs, new cars that never ship. Yeah. Yeah. I'm thinking like last year, this time last year was when Rabbit and Humane launched at CES and Rabbit kind of won CES. And now this year, no wearables except for you guys.Ethan [00:37:32]: It's funny because it's obviously it's AI everything. Yeah. Like every single product. Yeah.Maria [00:37:37]: Toothbrush with AI, vacuums with AI. Yeah. Yeah.Ethan [00:37:41]: We like hair blow, literally a hairdryer with AI. We saw.Maria [00:37:45]: Yeah, that was cool.Ethan [00:37:46]: But I think that like, yeah, we didn't, another kind of difference like around our, like we didn't want to do like a big overhypey promised kind of Rabbit launch. Because I mean, they did, hats off to them, like on the presentation and everything, obviously. But like, you know, we want to let the product kind of speak for itself and like get it out there. And I think we were really happy. We got some very good interest from media and some of the partners there. So like it was, I think it was definitely worth going. I would say like if you're in hardware, it's just kind of how you make use of it. Like I think to do it like a big Rabbit style or to have a huge show on there, like you need to plan that six months in advance. And it's very expensive. But like if you, you know, go there, there's everybody's there. All the media is there. There's a lot of some pre-show events that it's just great to talk to people. And the industry also, all the manufacturers, suppliers are there. So we learned about some really cool stuff that we might like. We met with somebody. They have like thermal energy capture. And it's like, oh, could you maybe not need to charge it? Because they have like a thermal that can capture your body heat. And what? Yeah, they're here. They're actually here. And in Palo Alto, they have like a Fitbit thing that you don't have to charge.swyx [00:39:01]: Like on paper, that's the power you can get from that. What's the power draw for this thing?Ethan [00:39:05]: It's more than you could get from the body heat, it turns out. But it's quite small. I don't want to disclose technically. But I think that solar is still, they also have one where it's like this thing could be like the face of it. It's just a solar cell. And like that is more realistic. Or kinetic. Kinetic, apparently, I'm not an expert in this, but they seem to think it wouldn't be enough. Kinetic is quite small, I guess, on the capture.swyx [00:39:33]: Well, I mean, watch. Watchmakers have been powering with kinetic for a long time. Yeah. We don't have to talk about that. I just want to get a sense of CES. Would you do it again? I definitely would not. Okay. You're just a fan of CES. Business point of view doesn't make sense. I happen to be in the conference business, right? So I'm kind of just curious. Yeah.Maria [00:39:49]: So I would say as we did, so without the booth and really like straightforward conversations that were already planned. Three days. That's okay. I think it was okay. Okay. But if you need to invest for a booth that is not. Okay. A good one. Which is how much? I think.Ethan [00:40:06]: 10 by 10 is 5,000. But on top of that, you need to. And then they go like 10 by 10 is like super small. Yeah. And like some companies have, I think would probably be more in like the six figure range to get. And I mean, I think that, yeah, it's very noisy. We heard this, that it's very, very noisy. Like obviously if you're, everything is being launched there and like everything from cars to cell phones are being launched. Yeah. So it's hard to stand out. But like, I think going in with a plan of who you want to talk to, I feel like.Maria [00:40:36]: That was worth it.Ethan [00:40:37]: Worth it. We had a lot of really positive media coverage from it and we got the word out and like, so I think we accomplished what we wanted to do.swyx [00:40:46]: I mean, there's some world in which my conference is kind of the CES of whatever AI becomes. Yeah. I think that.Maria [00:40:52]: Don't do it in Vegas. Don't do it in Vegas. Yeah. Don't do it in Vegas. That's the only thing. I didn't really like Vegas. That's great. Amazing. Those are my favorite ones.Alessio [00:41:02]: You can not fit 90,000 people in SF. That's really duh.Ethan [00:41:05]: You need to do like multiple locations so you can do Moscone and then have one in.swyx [00:41:09]: I mean, that's what Salesforce conferences. Well, GDC is how many? That might be 50,000, right? Okay. Form factor, right? Like my way to introduce this idea was that I was at the launch in Solaris. What was the old name of it? Newton. Newton. Of Tab when Avi first launched it. He was like, I thought through everything. Every form factor, pendant is the thing. And then we got the pendants for this original. The first one was just pendants and I took it off and I forgot to put it back on. So you went through pendants, pin, bracelet now, and maybe there's sort of earphones in the future, but what was your iterations?Maria [00:41:49]: So we had, I believe now three or four iterations. And one of the things that we learned is indeed that people don't like the pendant. In particular, woman, you don't want to have like anything here on the chest because it's maybe you have like other necklace or any other stuff.Ethan [00:42:03]: You just ship a premium one that's gold. Yeah. We're talking some fashion reached out to us.Maria [00:42:11]: Some big fashion. There is something there.swyx [00:42:13]: This is where it helps to have an Italian on the team.Maria [00:42:15]: There is like some big Italian luxury. I can't say anything. So yeah, bracelet actually came from the community because they were like, oh, I don't want to wear anything like as necklace or as a pendant. Like it's. And also like the one that we had, I don't know if you remember, like it was like circle, like it was like this and was like really bulky. Like people didn't like it. And also, I mean, I actually, I don't dislike, like we were running fast when we did that. Like our, our thing was like, we wanted to ship them as soon as possible. So we're not overthinking the form factor or the material. We were just want to be out. But after the community organically, basically all of them were like, well, why you don't just don't do the bracelet? Like he's way better. I will just wear it. And that's it. So that's how we ended up with the bracelet, but it's still modular. So I still want to play around the father is modular and you can, you know, take it off and wear it as a clip or in the future, maybe we will bring back the pendant. But I like the fact that there is some personalization and right now we have two colors, yellow and black. Soon we will have other ones. So yeah, we can play a lot around that.Ethan [00:43:25]: I think the form factor. Like the goal is for it to be not super invasive. Right. And something that's easy. So I think in the future, smaller, thinner, not like apple type obsession with thinness, but it does matter like the, the size and weight. And we would love to have more context because that will help, but to make it work, I think it really needs to have good power consumption, good battery life. And, you know, like with the humane swapping the batteries, I have one, I mean, I'm, I'm, I think we've made, and there's like pretty incredible, some of the engineering they did, but like, it wasn't kind of geared towards solving the problem. It was just, it's too heavy. The swappable batteries is too much to man, like the heat, the thermals is like too much to light interface thing. Yeah. Like that. That's cool. It's cool. It's cool. But it's like, if, if you have your handout here, you want to use your phone, like it's not really solving a problem. Cause you know how to use your phone. It's got a brilliant display. You have to kind of learn how to gesture this low range. Yeah. It's like a resolution laser, but the laser is cool that the fact they got it working in that thing, even though if it did overheat, but like too heavy, too cumbersome, too complicated with the multiple batteries. So something that's power efficient, kind of thin, both in the physical sense and also in the edge compute kind of way so that it can be as unobtrusive as possible. Yeah.Maria [00:44:47]: Users really like, like, I like when they say yes, I like to wear it and forget about it because I don't need to charge it every single day. On the other version, I believe we had like 35 hours or something, which was okay. But people, they just prefer the seven days battery life and-swyx [00:45:03]: Oh, this is seven days? Yeah. Oh, I've been charging every three days.Maria [00:45:07]: Oh, no, you can like keep it like, yeah, it's like almost seven days.swyx [00:45:11]: The other thing that occurs to me, maybe there's an Apple watch strap so that I don't have to double watch. Yeah.Maria [00:45:17]: That's the other one that, yeah, I thought about it. I saw as well the ones that like, you can like put it like back on the phone. Like, you know- Plog. There is a lot.swyx [00:45:27]: So yeah, there's a competitor called Plog. Yeah. It's not really a competitor. They only transcribe, right? Yeah, they only transcribe. But they're very good at it. Yeah.Ethan [00:45:33]: No, they're great. Their hardware is really good too.swyx [00:45:36]: And they just launched the pin too. Yeah.Ethan [00:45:38]: I think that the MagSafe kind of form factor has a lot of advantages, but some disadvantages. You can definitely put a very huge battery on that, you know? And so like the battery life's not, the power consumption's not so much of a concern, but you know, downside the phone's like in your pocket. And so I think that, you know, form factors will continue to evolve, but, and you know, more sensors, less obtrusive and-Maria [00:46:02]: Yeah. We have a new version.Ethan [00:46:04]: Easier to use.Maria [00:46:05]: Okay.swyx [00:46:05]: Looking forward to that. Yeah. I mean, we'll, whenever we launch this, we'll try to show whatever, but I'm sure you're going to keep iterating. Last thing on hardware, and then we'll go on to the software side, because I think that's where you guys are also really, really strong. Vision. You wanted to talk about why no vision? Yeah.Ethan [00:46:20]: I think it comes down to like when you're, when you're a startup, especially in hardware, you're just, you work within the constraints, right? And so like vision is super useful and super interesting. And what we actually started with, there's two issues with vision that make it like not the place we decided to start. One is power consumption. So you know, you kind of have to trade off your power budget, like capturing even at a low frame rate and transmitting the radio is actually the thing that takes up the majority of the power. So. Yeah. So you would really have to have quite a, like unacceptably, like large and heavy battery to do it continuously all day. We have, I think, novel kind of alternative ways that might allow us to do that. And we have some prototypes. The other issue is form factor. So like even with like a wide field of view, if you're wearing something on your chest, it's going, you know, obviously the wrist is not really that much of an option. And if you're wearing it on your chest, it's, it's often gone. You're going to probably be not capturing like the field of view of what's interesting to you. So that leaves you kind of with your head and face. And then anything that goes on, on the face has to look cool. Like I don't know if you remember the spectacles, it was kind of like the first, yeah, but they kind of, they didn't, they were not very successful. And I think one of the reasons is they were, they're so weird looking. Yeah. The camera was so big on the side. And if you look at them at array bands where they're way more successful, they, they look almost indistinguishable from array bands. And they invested a lot into that and they, they have a partnership with Qualcomm to develop custom Silicon. They have a stake in Luxottica now. So like they coming from all the angles, like to make glasses, I think like, you know, I don't know if you know, Brilliant Labs, they're cool company, they make frames, which is kind of like a cool hackable glasses and, and, and like, they're really good, like on hardware, they're really good. But even if you look at the frames, which I would say is like the most advanced kind of startup. Yeah. Yeah. Yeah. There was one that launched at CES, but it's not shipping yet. Like one that you can buy now, it's still not something you'd wear every day and the battery life is super short. So I think just the challenge of doing vision right, like off the bat, like would require quite a bit more resources. And so like audio is such a good entry point and it's also the privacy around audio. If you, if you had images, that's like another huge challenge to overcome. So I think that. Ideally the personal AI would have, you know, all the senses and you know, we'll, we'll get there. Yeah. Okay.swyx [00:48:57]: One last hardware thing. I have to ask this because then we'll move to the software. Were either of you electrical engineering?Ethan [00:49:04]: No, I'm CES. And so I have a, I've taken some EE courses, but I, I had done prior to working on, on the hardware here, like I had done a little bit of like embedded systems, like very little firmware, but we have luckily on the team, somebody with deep experience. Yeah.swyx [00:49:21]: I'm just like, you know, like you have to become hardware people. Yeah.Ethan [00:49:25]: Yeah. I mean, I learned to worry about supply chain power. I think this is like radio.Maria [00:49:30]: There's so many things to learn.Ethan [00:49:32]: I would tell this about hardware, like, and I know it's been said before, but building a prototype and like learning how the electronics work and learning about firmware and developing, this is like, I think fun for a lot of engineers and it's, it's all totally like achievable, especially now, like with, with the tools we have, like stuff you might've been intimidated about. Like, how do I like write this firmware now? With Sonnet, like you can, you can get going and actually see results quickly. But I think going from prototype to actually making something manufactured is a enormous jump. And it's not all about technology, the supply chain, the procurement, the regulations, the cost, the tooling. The thing about software that I'm used to is it's funny that you can make changes all along the way and ship it. But like when you have to buy tooling for an enclosure that's expensive.swyx [00:50:24]: Do you buy your own tooling? You have to.Ethan [00:50:25]: Don't you just subcontract out to someone in China? Oh, no. Do we make the tooling? No, no. You have to have CNC and like a bunch of machines.Maria [00:50:31]: Like nobody makes their own tooling, but like you have to design this design and you submitEthan [00:50:36]: it and then they go four to six weeks later. Yeah. And then if there's a problem with it, well, then you're not, you're not making any, any of your enclosures. And so you have to really plan ahead. And like.swyx [00:50:48]: I just want to leave tips for other hardware founders. Like what resources or websites are most helpful in your sort of manufacturing journey?Ethan [00:50:55]: You know, I think it's different depending on like it's hardware so specialized in different ways.Maria [00:51:00]: I will say that, for example, I should choose a manufacturer company. I speak with other founders and like we can give you like some, you know, some tips of who is good and who is not, or like who's specialized in something versus somebody else. Yeah.Ethan [00:51:15]: Like some people are good in plastics. Some people are good.Maria [00:51:18]: I think like for us, it really helped at the beginning to speak with others and understand. Okay. Like who is around. I work in Shenzhen. I lived almost two years in China. I have an idea about like different hardware manufacturer and all of that. Soon I will go back to Shenzhen to check out. So I think it's good also to go in place and check.Ethan [00:51:40]: Yeah, you have to like once you, if you, so we did some stuff domestically and like if you have that ability. The reason I say ability is very expensive, but like to build out some proof of concepts and do field testing before you take it to a manufacturer, despite what people say, there's really good domestic manufacturing for small quantities at extremely high prices. So we got our first PCB and the assembly done in LA. So there's a lot of good because of the defense industry that can do quick churn. So it's like, we need this board. We need to find out if it's working. We have this deadline we want to start, but you need to go through this. And like if you want to have it done and fabricated in a week, they can do it for a price. But I think, you know, everybody's kind of trending even for prototyping now moving that offshore because in China you can do prototyping and get it within almost the same timeline. But the thing is with manufacturing, like it really helps to go there and kind of establish the relationship. Yeah.Alessio [00:52:38]: My first company was a hardware company and we did our PCBs in China and took a long time. Now things are better. But this was, yeah, I don't know, 10 years ago, something like that. Yeah.Ethan [00:52:47]: I think that like the, and I've heard this too, we didn't run into this problem, but like, you know, if it's something where you don't have the relationship, they don't see you, they don't know you, you know, you might get subcontracted out or like they're not paying attention. But like if you're, you know, you have the relationship and a priority, like, yeah, it's really good. We ended up doing the fabrication assembly in Taiwan for various reasons.Maria [00:53:11]: And I think it really helped the fact that you went there at some point. Yeah.Ethan [00:53:15]: We're really happy with the process and, but I mean the whole process of just Choosing the right people. Choosing the right people, but also just sourcing the bill materials and all of that stuff. Like, I guess like if you have time, it's not that bad, but if you're trying to like really push the speed at that, it's incredibly stressful. Okay. We got to move to the software. Yeah.Alessio [00:53:38]: Yeah. So the hardware, maybe it's hard for people to understand, but what software people can understand is that running. Transcription and summarization, all of these things in real time every day for 24 hours a day. It's not easy. So you mentioned 200,000 tokens for a day. Yeah. How do you make it basically free to run all of this for the consumer?Ethan [00:53:59]: Well, I think that the pipeline and the inference, like people think about all of these tokens, but as you know, the price of tokens is like dramatically dropping. You guys probably have some charts somewhere that you've posted. We do. And like, if you see that trend in like 250,000 input tokens, it's not really that much, right? Like the output.swyx [00:54:21]: You do several layers. You do live. Yeah.Ethan [00:54:23]: Yeah. So the speech to text is like the most challenging part actually, because you know, it requires like real time processing and then like later processing with a larger model. And one thing that is fairly obvious is that like, you don't need to transcribe things that don't have any voice in it. Right? So good voice activity is key, right? Because like the majority of most people's day is not spent with voice activity. Right? So that is the first step to cutting down the amount of compute you have to do. And voice activity is a fairly cheap thing to do. Very, very cheap thing to do. The models that need to summarize, you don't need a Sonnet level kind of model to summarize. You do need a Sonnet level model to like execute things like the agent. And we will be having a subscription for like features like that because it's, you know, although now with the R1, like we'll see, we haven't evaluated it. A deep seek? Yeah. I mean, not that one in particular, but like, you know, they're already there that can kind of perform at that level. I was like, it's going to stay in six months, but like, yeah. So self-hosted models help in the things where you can. So you are self-hosting models. Yes. You are fine tuning your own ASR. Yes. I will say that I see in the future that everything's trending down. Although like, I think there might be an intermediary step with things to become expensive, which is like, we're really interested because like the pipeline is very tedious and like a lot of tuning. Right. Which is brutal because it's just a lot of trial and error. Whereas like, well, wouldn't it be nice if an end to end model could just do all of this and learn it? If we could do transcription with like an LLM, there's so many advantages to that, but it's going to be a larger model and hence like more compute, you know, we're optimistic. Maybe we could distill something down and like, we kind of more than focus on reducing the cost of the existing pipeline or trying to the next generation. Cause it's very clear that like all ASR, all speech to the text is going to be pretty obsolete pretty soon. So like investing into that is probably kind of a dead end. Cause it's just going to be. It's going to be obsolete.swyx [00:56:39]: It's interesting. Like I think when I initially invested in tab this is, this shows you how wrong I was. I was like, oh, this is a sort of razor blades, blade razors and blades model where you sell a cheap hardware and you make up a subscription, like a monthly subscription. And now I just checked friend is a one-time sale, $99 limitless one-time sale, $99. These guys one-time sale, $49 and inference is free. What? Wow. It's crazy.Ethan [00:57:09]: I think when you probably invested, like how much was a million input tokens at that time and what is it now?swyx [00:57:15]: It's a fascinating business and like, you know, there's a lot to dig into there, but just getting that perspective out there is, I think it's not something that people think about a lot.Alessio [00:57:24]: And you obviously have thought a lot about. What about memory? I think this is something we go back and forth on about memory as in you're just memorizing facts and then understanding implicit preference and adjusting facts that you think are important. Have you ever done something about a person? Any learnings from that? I know there's a lot of open source frameworks now that do it that you build all of your own infrastructure internally.Ethan [00:57:46]: Yeah, we did. I mean I evaluated used a lot in other projects. I think that there's a few different tasks or things that revolve around memory. Like one is like retrieval obviously. And like when you need to find like even if you have a large corpus of how do you find? And so like I think existing kind of rag pipelines also will probably be the most helpful. The frameworks, I have not found one, like, there's no general way to do RAG that works, like, it's really highly dependent on the data. So, like, if you're going to be customizing something that much, it's just, you get kind of more bang from the buck from designing it all yourself. You know, a lot of those frameworks are great for getting going quickly. But I think it's really interesting memory when you're trying to do, for a person, because memory is decay, right? Like, I'm going to London, you know, then I come back, I'm not going to London anymore. What we've learned is, like, doing the traditional, like, embedding and RAG is suboptimal. We kind of built our own using small models to do really massively parallel retrieval. Which I think is going to be maybe more common in the future. And then, like, how to represent a person. We still require some human loop. And I mean, this is an ongoing project. And, you know, we're learning every day. Like, how do you correct the model when it gets something wrong about you? Right now, we have, like, things that are, like, super confirmed that are, like, ground truth about you because the human accepted it. But ideally, like, that step wouldn't be necessary. And then we have things that are fuzzier. And, like, the more... Stuff that we know is true, the more accurate we are when we're trying to decide, is this fuzzy stuff? Because it's probably, like, if you have the context, it's probably not true. So I think it's one of the most core challenges is how to handle both retrieval and then modeling and, like, especially when you're dealing with noisy source data. Because, like, even if, in an ideal world, even if you just had perfect transcription and you're going off that, that's still not enough information, right? And even if you had visual, it's still not enough. Like, there's still going to be...Alessio [00:59:55]: Yeah, one way I think about it is I usually like to order the same thing from the same restaurant if I like it. But I'm not saying that out loud. And it's kind of like, are these type of behaviors? Like, when you ask about a favorite restaurant, I would just want it to give me restaurants that I've already been to that I like. Or, like, if I'm like, hey, just order something. from this place, I should just reorder the same thing. Because it knows that I like to redo the same thing. But I feel like today, most agent memory things that I see people publish, it's like, you know, just write down the data thing.Ethan [01:00:39]: Yeah, I mean, I think that's why the reasoning, like, in our case, like, giving it time to consider all of the sources it has. So, like, look at the email, see, like, the receipts, and then look at the conversations to see, like, what I've mentioned. And then be able to then take enough time to search through all the contexts and connect the dots is, I think, really important. And, like, I don't know, like, some of the agent memory stuff is, like, the key value with RAG on top. Like, and the results there are just not complete enough when you have, like, growing corpus and, like, managing decay and hallucinations that might be in the source material. So, this is where people usually bring in knowledge graphs. Yes. And do you do it? We don't extensively use knowledge graphs. It's something, you know, we didn't talk also about the kind of potential future social aspects.Maria [01:01:33]: Yeah, I wanted to speak about it.Ethan [01:01:35]: But the problem with knowledge graphs that we found is, like, and I don't know if you can tell me what your experience has been, but they're great for representing the data, but then, like, using it at inference time is kind of challenging.swyx [01:01:49]: For speed or what other issues?Ethan [01:01:51]: Just, like, the LLM understanding. Like, the graph. Yeah. The input. Yeah, it's not in the training data, for sure. I think that the graph is the right kind of way to store the data, but, like, then you need to have the right retrieval and then just kind of formatting in a way that, like, doesn't just overwhelm or confuse what you're trying to do. Should we ask about social? Yeah, I thought you were going to go into it. Yeah. Like, not directly related. We did some experimentation. Not directly related to, like, graph retrieval or graph knowledge races. Yeah. Yeah. Yeah. Yeah. The idea that having, like, your personal context, but then, like, other people can query it, you know, it can divulge some things that you would have full control over. Then Maria and I are trying to negotiate, like, where we're going to dinner, like, there can be an exchange. We exactly did this experiment. Yeah. There can be an exchange between the agents and, like, oh.Maria [01:02:45]: So how, like, my agent can speak with Ethan's agent. Both of them, they know our location, what we like, where we went in the past. Yeah. And even, you know, if we have our calendar integrated, they know when we're free. So they can interact with each other and have a conversation and decide a place to go for us. Wow. And we did that. And it was, for me, really cool because they suggested to us a nice French restaurant that we went at the end.swyx [01:03:11]: That you've never been to?Maria [01:03:12]: That we've never been to. Okay. But both of us, they said that we like French food. Both of us, we were in Pacific Heights. And, yeah, this was really trivial. Yeah.Ethan [01:03:23]: It's a trivial, like, toy use. But I guess, like, in terms of you've been using it for a while, like, if I wanted to buy you a gift.Maria [01:03:30]: Oh, my God. You bought me a bunch of candles now that I think about it.Ethan [01:03:35]: This is another use case. I was like, yeah. When we were testing the agent, like, a bunch of candles from Amazon showed up at her door.Maria [01:03:43]: Yeah, because I love candles, but I didn't expect 20. Yeah.Ethan [01:03:47]: It was a lot of experimenting. But, like, how to manage that where it's like, what's okay for your B to divulge to him? Who? Yeah. Like, shouldn't you get an authorization request every time? Yeah, yeah, yeah.swyx [01:03:58]: For personal context. Yeah, yeah, yeah.Ethan [01:04:00]: So, like, you know, you would have to, human would have to sign off on it. But I think then, like, then I wouldn't have to guess. I could just.swyx [01:04:10]: Yeah, yeah. You know, there's this culture that, like, is very alien to everyone else outside of SF and outside the Gen Z bubble in SF, which is sharing, location sharing. Yeah. I can tell my close friends where they are exactly right now in the city. Yeah. And it's opt-in. And, like, it's. Dude. Dude. You know, and, like, it's normal and, like, it freaks out everyone who's not here. Yeah. Yeah. And so maybe we can share preference, like, who we like. Absolutely.Maria [01:04:34]: I really believe in it, for sure. We will.Ethan [01:04:36]: Or even, like, small updates about your day. My parents would love that because I don't do that. Yeah. now there's no friction. It can just be more or less automatic. Yeah. Dating? I was trained always to avoid dating. Really? As a startup founder. Yeah, you can hate that. Yeah. Everyone hates it?Maria [01:04:55]: We thought about it. Like, sometimes some people, they ask to us because it's like, oh, you know so much about me. Like, can you measure compatibility with somebody else or something like that? Yeah. Probably there is a future. Maybe somebody should build that. I think on our end, we were like, no, this is. We don't want to.Ethan [01:05:11]: I will build on your API. My sister is actually a personality psychology professor and she studies personality. And we were at Thanksgiving because my parents wear one. And I was like, ask it. Like, give me my big five. Yeah. Which is like the personality type. And it's like. Does it know my big five? Just ask it to consider everything and give your big five. And my sister said it was pretty. I didn't agree with it because it said I was disagreeable. I agree with that. But she seemed to think it was agreeable. And so.swyx [01:05:41]: You disagree that you're disagreeable? Yeah. Yeah. What other proof do we need then?Ethan [01:05:47]: Yeah. I think I'm very agreeable.Ethan [01:05:51]: But I think that we do. I did get some users are like, oh, if like we're a couple. Yeah.Maria [01:05:56]: We had like couples. Actually. They bought the product together. Yeah. Like both. Like couple. They bought the hardware. So there is something there. Another test is like the Myers-Briggs. I know that you don't like that one. No. No.swyx [01:06:08]: Ocean is cooler than Myers-Briggs. Yeah. Everyone stop using my MBTI. Use my. Use Ocean. Yeah.Maria [01:06:12]: Yeah. For me, like it was on point. Like every time. Like it. Awesome.Alessio [01:06:16]: Anything else that we didn't cover? Any cool underrated things?Maria [01:06:21]: Go to b.computer. Forty nine. Ninety nine. And you buy the device. That's the. That's the call to action.swyx [01:06:28]: And you're hiring?Maria [01:06:29]: We are hiring. For sure.Ethan [01:06:32]: AI engineers.Maria [01:06:33]: AI engineers. Nice. What is an AI engineer?Ethan [01:06:35]: Yeah. But did you study? Somebody who's scrappy and willing to.Maria [01:06:42]: Work with us. Yeah.Ethan [01:06:43]: I think. I think you coined the term, right? So you can tell us.Maria [01:06:48]: Somebody that can adapt. That has resistance. Yeah. Yeah.swyx [01:06:51]: People have different perspectives and what is useful for you is different from what is useful for me. Yeah. So anyway, it's so useful.Ethan [01:06:57]: I mean, I think that always on AI is really going to explode and it's going to be a lot from both a lot of startups, but incumbents and there's going to be all kinds of new things that we're going to learn about how it's going to change all of our lives. I think that's the thing I'm most certain about. So. And being AI.swyx [01:07:15]: Well, thanks very much. Thank you guys. This is a pleasure. Thank you. Yeah. We'll see you launch whenever. Thank you. I'm sure that launch is happening. Yeah. Thanks. Thank you. Get full access to Latent.Space at www.latent.space/subscribe
-
 The AI Architect — Bret Taylor
The AI Architect — Bret TaylorFrom 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2025-02-11 01:32
If you’re in SF, join us tomorrow for a fun meetup at CodeGen Night!If you’re in NYC, join us for AI Engineer Summit! The Agent Engineering track is now sold out, but 25 tickets remain for AI Leadership and 5 tickets for the workshops. You can see the full schedule of speakers and workshops at https://ai.engineer!It’s exceedingly hard to introduce someone like Bret Taylor. We could recite his Wikipedia page, or his extensive work history through Silicon Valley’s greatest companies, but everyone else already does that.As a podcast by AI engineers for AI engineers, we had the opportunity to do something a little different. We wanted to dig into what Bret sees from his vantage point at the top of our industry for the last 2 decades, and how that explains the rise of the AI Architect at Sierra, the leading conversational AI/CX platform.“Across our customer base, we are seeing a new role emerge - the role of the AI architect. These leaders are responsible for helping define, manage and evolve their company's AI agent over time. They come from a variety of both technical and business backgrounds, and we think that every company will have one or many AI architects managing their AI agent and related experience.”In our conversation, Bret Taylor confirms the Paul Buchheit legend that he rewrote Google Maps in a weekend, armed with only the help of a then-nascent Google Closure Compiler and no other modern tooling. But what we find remarkable is that he was the PM of Maps, not an engineer, though of course he still identifies as one. We find this theme recurring throughout Bret’s career and worldview. We think it is plain as day that AI leadership will have to be hands-on and technical, especially when the ground is shifting as quickly as it is today:“There's a lot of power in combining product and engineering into as few people as possible… few great things have been created by committee.”“If engineering is an order taking organization for product you can sometimes make meaningful things, but rarely will you create extremely well crafted breakthrough products. Those tend to be small teams who deeply understand the customer need that they're solving, who have a maniacal focus on outcomes.”“And I think the reason why is if you look at like software as a service five years ago, maybe you can have a separation of product and engineering because most software as a service created five years ago. I wouldn't say there's like a lot of technological breakthroughs required for most business applications. And if you're making expense reporting software or whatever, it's useful… You kind of know how databases work, how to build auto scaling with your AWS cluster, whatever, you know, it's just, you're just applying best practices to yet another problem. "When you have areas like the early days of mobile development or the early days of interactive web applications, which I think Google Maps and Gmail represent, or now AI agents, you're in this constant conversation with what the requirements of your customers and stakeholders are and all the different people interacting with it and the capabilities of the technology. And it's almost impossible to specify the requirements of a product when you're not sure of the limitations of the technology itself.”This is the first time the difference between technical leadership for “normal” software and for “AI” software was articulated this clearly for us, and we’ll be thinking a lot about this going forward. We left a lot of nuggets in the conversation, so we hope you’ll just dive in with us (and thank Bret for joining the pod!)Full YouTubePlease Like and Subscribe :)Timestamps* 00:00:02 Introductions and Bret Taylor's background* 00:01:23 Bret's experience at Stanford and the dot-com era* 00:04:04 The story of rewriting Google Maps backend* 00:11:06 Early days of interactive web applications at Google* 00:15:26 Discussion on product management and engineering roles* 00:21:00 AI and the future of software development* 00:26:42 Bret's approach to identifying customer needs and building AI companies* 00:32:09 The evolution of business models in the AI era* 00:41:00 The future of programming languages and software development* 00:49:38 Challenges in precisely communicating human intent to machines* 00:56:44 Discussion on Artificial General Intelligence (AGI) and its impact* 01:08:51 The future of agent-to-agent communication* 01:14:03 Bret's involvement in the OpenAI leadership crisis* 01:22:11 OpenAI's relationship with Microsoft* 01:23:23 OpenAI's mission and priorities* 01:27:40 Bret's guiding principles for career choices* 01:29:12 Brief discussion on pasta-making* 01:30:47 How Bret keeps up with AI developments* 01:32:15 Exciting research directions in AI* 01:35:19 Closing remarks and hiring at Sierra Transcript[00:02:05] Introduction and Guest Welcome[00:02:05] Alessio: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO at Decibel Partners, and I'm joined by my co host swyx, founder of smol.ai.[00:02:17] swyx: Hey, and today we're super excited to have Bret Taylor join us. Welcome. Thanks for having me. It's a little unreal to have you in the studio.[00:02:25] swyx: I've read about you so much over the years, like even before. Open AI effectively. I mean, I use Google Maps to get here. So like, thank you for everything that you've done. Like, like your story history, like, you know, I think people can find out what your greatest hits have been.[00:02:40] Bret Taylor's Early Career and Education[00:02:40] swyx: How do you usually like to introduce yourself when, you know, you talk about, you summarize your career, like, how do you look at yourself?[00:02:47] Bret: Yeah, it's a great question. You know, we, before we went on the mics here, we're talking about the audience for this podcast being more engineering. And I do think depending on the audience, I'll introduce myself differently because I've had a lot of [00:03:00] corporate and board roles. I probably self identify as an engineer more than anything else though.[00:03:04] Bret: So even when I was. Salesforce, I was coding on the weekends. So I think of myself as an engineer and then all the roles that I do in my career sort of start with that just because I do feel like engineering is sort of a mindset and how I approach most of my life. So I'm an engineer first and that's how I describe myself.[00:03:24] Bret: You majored in computer[00:03:25] swyx: science, like 1998. And, and I was high[00:03:28] Bret: school, actually my, my college degree was Oh, two undergrad. Oh, three masters. Right. That old.[00:03:33] swyx: Yeah. I mean, no, I was going, I was going like 1998 to 2003, but like engineering wasn't as, wasn't a thing back then. Like we didn't have the title of senior engineer, you know, kind of like, it was just.[00:03:44] swyx: You were a programmer, you were a developer, maybe. What was it like in Stanford? Like, what was that feeling like? You know, was it, were you feeling like on the cusp of a great computer revolution? Or was it just like a niche, you know, interest at the time?[00:03:57] Stanford and the Dot-Com Bubble[00:03:57] Bret: Well, I was at Stanford, as you said, from 1998 to [00:04:00] 2002.[00:04:02] Bret: 1998 was near the peak of the dot com bubble. So. This is back in the day where most people that they're coding in the computer lab, just because there was these sun microsystems, Unix boxes there that most of us had to do our assignments on. And every single day there was a. com like buying pizza for everybody.[00:04:20] Bret: I didn't have to like, I got. Free food, like my first two years of university and then the dot com bubble burst in the middle of my college career. And so by the end there was like tumbleweed going to the job fair, you know, it was like, cause it was hard to describe unless you were there at the time, the like level of hype and being a computer science major at Stanford was like, A thousand opportunities.[00:04:45] Bret: And then, and then when I left, it was like Microsoft, IBM.[00:04:49] Joining Google and Early Projects[00:04:49] Bret: And then the two startups that I applied to were VMware and Google. And I ended up going to Google in large part because a woman named Marissa Meyer, who had been a teaching [00:05:00] assistant when I was, what was called a section leader, which was like a junior teaching assistant kind of for one of the big interest.[00:05:05] Bret: Yes. Classes. She had gone there. And she was recruiting me and I knew her and it was sort of felt safe, you know, like, I don't know. I thought about it much, but it turned out to be a real blessing. I realized like, you know, you always want to think you'd pick Google if given the option, but no one knew at the time.[00:05:20] Bret: And I wonder if I'd graduated in like 1999 where I've been like, mom, I just got a job at pets. com. It's good. But you know, at the end I just didn't have any options. So I was like, do I want to go like make kernel software at VMware? Do I want to go build search at Google? And I chose Google. 50, 50 ball.[00:05:36] Bret: I'm not really a 50, 50 ball. So I feel very fortunate in retrospect that the economy collapsed because in some ways it forced me into like one of the greatest companies of all time, but I kind of lucked into it, I think.[00:05:47] The Google Maps Rewrite Story[00:05:47] Alessio: So the famous story about Google is that you rewrote the Google maps back in, in one week after the map quest quest maps acquisition, what was the story there?[00:05:57] Alessio: Is it. Actually true. Is it [00:06:00] being glorified? Like how, how did that come to be? And is there any detail that maybe Paul hasn't shared before?[00:06:06] Bret: It's largely true, but I'll give the color commentary. So it was actually the front end, not the back end, but it turns out for Google maps, the front end was sort of the hard part just because Google maps was.[00:06:17] Bret: Largely the first ish kind of really interactive web application, say first ish. I think Gmail certainly was though Gmail, probably a lot of people then who weren't engineers probably didn't appreciate its level of interactivity. It was just fast, but. Google maps, because you could drag the map and it was sort of graphical.[00:06:38] Bret: My, it really in the mainstream, I think, was it a map[00:06:41] swyx: quest back then that was, you had the arrows up and down, it[00:06:44] Bret: was up and down arrows. Each map was a single image and you just click left and then wait for a few seconds to the new map to let it was really small too, because generating a big image was kind of expensive on computers that day.[00:06:57] Bret: So Google maps was truly innovative in that [00:07:00] regard. The story on it. There was a small company called where two technologies started by two Danish brothers, Lars and Jens Rasmussen, who are two of my closest friends now. They had made a windows app called expedition, which had beautiful maps. Even in 2000.[00:07:18] Bret: For whenever we acquired or sort of acquired their company, Windows software was not particularly fashionable, but they were really passionate about mapping and we had made a local search product that was kind of middling in terms of popularity, sort of like a yellow page of search product. So we wanted to really go into mapping.[00:07:36] Bret: We'd started working on it. Their small team seemed passionate about it. So we're like, come join us. We can build this together.[00:07:42] Technical Challenges and Innovations[00:07:42] Bret: It turned out to be a great blessing that they had built a windows app because you're less technically constrained when you're doing native code than you are building a web browser, particularly back then when there weren't really interactive web apps and it ended up.[00:07:56] Bret: Changing the level of quality that we [00:08:00] wanted to hit with the app because we were shooting for something that felt like a native windows application. So it was a really good fortune that we sort of, you know, their unusual technical choices turned out to be the greatest blessing. So we spent a lot of time basically saying, how can you make a interactive draggable map in a web browser?[00:08:18] Bret: How do you progressively load, you know, new map tiles, you know, as you're dragging even things like down in the weeds of the browser at the time, most browsers like Internet Explorer, which was dominant at the time would only load two images at a time from the same domain. So we ended up making our map tile servers have like.[00:08:37] Bret: Forty different subdomains so we could load maps and parallels like lots of hacks. I'm happy to go into as much as like[00:08:44] swyx: HTTP connections and stuff.[00:08:46] Bret: They just like, there was just maximum parallelism of two. And so if you had a map, set of map tiles, like eight of them, so So we just, we were down in the weeds of the browser anyway.[00:08:56] Bret: So it was lots of plumbing. I can, I know a lot more about browsers than [00:09:00] most people, but then by the end of it, it was fairly, it was a lot of duct tape on that code. If you've ever done an engineering project where you're not really sure the path from point A to point B, it's almost like. Building a house by building one room at a time.[00:09:14] Bret: The, there's not a lot of architectural cohesion at the end. And then we acquired a company called Keyhole, which became Google earth, which was like that three, it was a native windows app as well, separate app, great app, but with that, we got licenses to all this satellite imagery. And so in August of 2005, we added.[00:09:33] Bret: Satellite imagery to Google Maps, which added even more complexity in the code base. And then we decided we wanted to support Safari. There was no mobile phones yet. So Safari was this like nascent browser on, on the Mac. And it turns out there's like a lot of decisions behind the scenes, sort of inspired by this windows app, like heavy use of XML and XSLT and all these like.[00:09:54] Bret: Technologies that were like briefly fashionable in the early two thousands and everyone hates now for good [00:10:00] reason. And it turns out that all of the XML functionality and Internet Explorer wasn't supporting Safari. So people are like re implementing like XML parsers. And it was just like this like pile of s**t.[00:10:11] Bret: And I had to say a s**t on your part. Yeah, of[00:10:12] Alessio: course.[00:10:13] Bret: So. It went from this like beautifully elegant application that everyone was proud of to something that probably had hundreds of K of JavaScript, which sounds like nothing. Now we're talking like people have modems, you know, not all modems, but it was a big deal.[00:10:29] Bret: So it was like slow. It took a while to load and just, it wasn't like a great code base. Like everything was fragile. So I just got. Super frustrated by it. And then one weekend I did rewrite all of it. And at the time the word JSON hadn't been coined yet too, just to give you a sense. So it's all XML.[00:10:47] swyx: Yeah.[00:10:47] Bret: So we used what is now you would call JSON, but I just said like, let's use eval so that we can parse the data fast. And, and again, that's, it would literally as JSON, but at the time there was no name for it. So we [00:11:00] just said, let's. Pass on JavaScript from the server and eval it. And then somebody just refactored the whole thing.[00:11:05] Bret: And, and it wasn't like I was some genius. It was just like, you know, if you knew everything you wished you had known at the beginning and I knew all the functionality, cause I was the primary, one of the primary authors of the JavaScript. And I just like, I just drank a lot of coffee and just stayed up all weekend.[00:11:22] Bret: And then I, I guess I developed a bit of reputation and no one knew about this for a long time. And then Paul who created Gmail and I ended up starting a company with him too, after all of this told this on a podcast and now it's large, but it's largely true. I did rewrite it and it, my proudest thing.[00:11:38] Bret: And I think JavaScript people appreciate this. Like the un G zipped bundle size for all of Google maps. When I rewrote, it was 20 K G zipped. It was like much smaller for the entire application. It went down by like 10 X. So. What happened on Google? Google is a pretty mainstream company. And so like our usage is shot up because it turns out like it's faster.[00:11:57] Bret: Just being faster is worth a lot of [00:12:00] percentage points of growth at a scale of Google. So how[00:12:03] swyx: much modern tooling did you have? Like test suites no compilers.[00:12:07] Bret: Actually, that's not true. We did it one thing. So I actually think Google, I, you can. Download it. There's a, Google has a closure compiler, a closure compiler.[00:12:15] Bret: I don't know if anyone still uses it. It's gone. Yeah. Yeah. It's sort of gone out of favor. Yeah. Well, even until recently it was better than most JavaScript minifiers because it was more like it did a lot more renaming of variables and things. Most people use ES build now just cause it's fast and closure compilers built on Java and super slow and stuff like that.[00:12:37] Bret: But, so we did have that, that was it. Okay.[00:12:39] The Evolution of Web Applications[00:12:39] Bret: So and that was treated internally, you know, it was a really interesting time at Google at the time because there's a lot of teams working on fairly advanced JavaScript when no one was. So Google suggest, which Kevin Gibbs was the tech lead for, was the first kind of type ahead, autocomplete, I believe in a web browser, and now it's just pervasive in search boxes that you sort of [00:13:00] see a type ahead there.[00:13:01] Bret: I mean, chat, dbt[00:13:01] swyx: just added it. It's kind of like a round trip.[00:13:03] Bret: Totally. No, it's now pervasive as a UI affordance, but that was like Kevin's 20 percent project. And then Gmail, Paul you know, he tells the story better than anyone, but he's like, you know, basically was scratching his own itch, but what was really neat about it is email, because it's such a productivity tool, just needed to be faster.[00:13:21] Bret: So, you know, he was scratching his own itch of just making more stuff work on the client side. And then we, because of Lars and Yen sort of like setting the bar of this windows app or like we need our maps to be draggable. So we ended up. Not only innovate in terms of having a big sync, what would be called a single page application today, but also all the graphical stuff you know, we were crashing Firefox, like it was going out of style because, you know, when you make a document object model with the idea that it's a document and then you layer on some JavaScript and then we're essentially abusing all of this, it just was running into code paths that were not.[00:13:56] Bret: Well, it's rotten, you know, at this time. And so it was [00:14:00] super fun. And, and, you know, in the building you had, so you had compilers, people helping minify JavaScript just practically, but there is a great engineering team. So they were like, that's why Closure Compiler is so good. It was like a. Person who actually knew about programming languages doing it, not just, you know, writing regular expressions.[00:14:17] Bret: And then the team that is now the Chrome team believe, and I, I don't know this for a fact, but I'm pretty sure Google is the main contributor to Firefox for a long time in terms of code. And a lot of browser people were there. So every time we would crash Firefox, we'd like walk up two floors and say like, what the hell is going on here?[00:14:35] Bret: And they would load their browser, like in a debugger. And we could like figure out exactly what was breaking. And you can't change the code, right? Cause it's the browser. It's like slow, right? I mean, slow to update. So, but we could figure out exactly where the bug was and then work around it in our JavaScript.[00:14:52] Bret: So it was just like new territory. Like so super, super fun time, just like a lot of, a lot of great engineers figuring out [00:15:00] new things. And And now, you know, the word, this term is no longer in fashion, but the word Ajax, which was asynchronous JavaScript and XML cause I'm telling you XML, but see the word XML there, to be fair, the way you made HTTP requests from a client to server was this.[00:15:18] Bret: Object called XML HTTP request because Microsoft and making Outlook web access back in the day made this and it turns out to have nothing to do with XML. It's just a way of making HTTP requests because XML was like the fashionable thing. It was like that was the way you, you know, you did it. But the JSON came out of that, you know, and then a lot of the best practices around building JavaScript applications is pre React.[00:15:44] Bret: I think React was probably the big conceptual step forward that we needed. Even my first social network after Google, we used a lot of like HTML injection and. Making real time updates was still very hand coded and it's really neat when you [00:16:00] see conceptual breakthroughs like react because it's, I just love those things where it's like obvious once you see it, but it's so not obvious until you do.[00:16:07] Bret: And actually, well, I'm sure we'll get into AI, but I, I sort of feel like we'll go through that evolution with AI agents as well that I feel like we're missing a lot of the core abstractions that I think in 10 years we'll be like, gosh, how'd you make agents? Before that, you know, but it was kind of that early days of web applications.[00:16:22] swyx: There's a lot of contenders for the reactive jobs of of AI, but no clear winner yet. I would say one thing I was there for, I mean, there's so much we can go into there. You just covered so much.[00:16:32] Product Management and Engineering Synergy[00:16:32] swyx: One thing I just, I just observe is that I think the early Google days had this interesting mix of PM and engineer, which I think you are, you didn't, you didn't wait for PM to tell you these are my, this is my PRD.[00:16:42] swyx: This is my requirements.[00:16:44] mix: Oh,[00:16:44] Bret: okay.[00:16:45] swyx: I wasn't technically a software engineer. I mean,[00:16:48] Bret: by title, obviously. Right, right, right.[00:16:51] swyx: It's like a blend. And I feel like these days, product is its own discipline and its own lore and own industry and engineering is its own thing. And there's this process [00:17:00] that happens and they're kind of separated, but you don't produce as good of a product as if they were the same person.[00:17:06] swyx: And I'm curious, you know, if, if that, if that sort of resonates in, in, in terms of like comparing early Google versus modern startups that you see out there,[00:17:16] Bret: I certainly like wear a lot of hats. So, you know, sort of biased in this, but I really agree that there's a lot of power and combining product design engineering into as few people as possible because, you know few great things have been created by committee, you know, and so.[00:17:33] Bret: If engineering is an order taking organization for product you can sometimes make meaningful things, but rarely will you create extremely well crafted breakthrough products. Those tend to be small teams who deeply understand the customer need that they're solving, who have a. Maniacal focus on outcomes.[00:17:53] Bret: And I think the reason why it's, I think for some areas, if you look at like software as a service five years ago, maybe you can have a [00:18:00] separation of product and engineering because most software as a service created five years ago. I wouldn't say there's like a lot of like. Technological breakthroughs required for most, you know, business applications.[00:18:11] Bret: And if you're making expense reporting software or whatever, it's useful. I don't mean to be dismissive of expense reporting software, but you probably just want to understand like, what are the requirements of the finance department? What are the requirements of an individual file expense report? Okay.[00:18:25] Bret: Go implement that. And you kind of know how web applications are implemented. You kind of know how to. How databases work, how to build auto scaling with your AWS cluster, whatever, you know, it's just, you're just applying best practices to yet another problem when you have areas like the early days of mobile development or the early days of interactive web applications, which I think Google Maps and Gmail represent, or now AI agents, you're in this constant conversation with what the requirements of your customers and stakeholders are and all the different people interacting with it.[00:18:58] Bret: And the capabilities of the [00:19:00] technology. And it's almost impossible to specify the requirements of a product when you're not sure of the limitations of the technology itself. And that's why I use the word conversation. It's not literal. That's sort of funny to use that word in the age of conversational AI.[00:19:15] Bret: You're constantly sort of saying, like, ideally, you could sprinkle some magic AI pixie dust and solve all the world's problems, but it's not the way it works. And it turns out that actually, I'll just give an interesting example.[00:19:26] AI Agents and Modern Tooling[00:19:26] Bret: I think most people listening probably use co pilots to code like Cursor or Devon or Microsoft Copilot or whatever.[00:19:34] Bret: Most of those tools are, they're remarkable. I'm, I couldn't, you know, imagine development without them now, but they're not autonomous yet. Like I wouldn't let it just write most code without my interactively inspecting it. We just are somewhere between it's an amazing co pilot and it's an autonomous software engineer.[00:19:53] Bret: As a product manager, like your aspirations for what the product is are like kind of meaningful. But [00:20:00] if you're a product person, yeah, of course you'd say it should be autonomous. You should click a button and program should come out the other side. The requirements meaningless. Like what matters is like, what is based on the like very nuanced limitations of the technology.[00:20:14] Bret: What is it capable of? And then how do you maximize the leverage? It gives a software engineering team, given those very nuanced trade offs. Coupled with the fact that those nuanced trade offs are changing more rapidly than any technology in my memory, meaning every few months you'll have new models with new capabilities.[00:20:34] Bret: So how do you construct a product that can absorb those new capabilities as rapidly as possible as well? That requires such a combination of technical depth and understanding the customer that you really need more integration. Of product design and engineering. And so I think it's why with these big technology waves, I think startups have a bit of a leg up relative to incumbents because they [00:21:00] tend to be sort of more self actualized in terms of just like bringing those disciplines closer together.[00:21:06] Bret: And in particular, I think entrepreneurs, the proverbial full stack engineers, you know, have a leg up as well because. I think most breakthroughs happen when you have someone who can understand those extremely nuanced technical trade offs, have a vision for a product. And then in the process of building it, have that, as I said, like metaphorical conversation with the technology, right?[00:21:30] Bret: Gosh, I ran into a technical limit that I didn't expect. It's not just like changing that feature. You might need to refactor the whole product based on that. And I think that's, that it's particularly important right now. So I don't, you know, if you, if you're building a big ERP system, probably there's a great reason to have product and engineering.[00:21:51] Bret: I think in general, the disciplines are there for a reason. I think when you're dealing with something as nuanced as the like technologies, like large language models today, there's a ton of [00:22:00] advantage of having. Individuals or organizations that integrate the disciplines more formally.[00:22:05] Alessio: That makes a lot of sense.[00:22:06] Alessio: I've run a lot of engineering teams in the past, and I think the product versus engineering tension has always been more about effort than like whether or not the feature is buildable. But I think, yeah, today you see a lot more of like. Models actually cannot do that. And I think the most interesting thing is on the startup side, people don't yet know where a lot of the AI value is going to accrue.[00:22:26] Alessio: So you have this rush of people building frameworks, building infrastructure, layered things, but we don't really know the shape of the compute. I'm curious that Sierra, like how you thought about building an house, a lot of the tooling for evals or like just, you know, building the agents and all of that.[00:22:41] Alessio: Versus how you see some of the startup opportunities that is maybe still out there.[00:22:46] Bret: We build most of our tooling in house at Sierra, not all. It's, we don't, it's not like not invented here syndrome necessarily, though, maybe slightly guilty of that in some ways, but because we're trying to build a platform [00:23:00] that's in Dorian, you know, we really want to have control over our own destiny.[00:23:03] Bret: And you had made a comment earlier that like. We're still trying to figure out who like the reactive agents are and the jury is still out. I would argue it hasn't been created yet. I don't think the jury is still out to go use that metaphor. We're sort of in the jQuery era of agents, not the react era.[00:23:19] Bret: And, and that's like a throwback for people listening,[00:23:22] swyx: we shouldn't rush it. You know?[00:23:23] Bret: No, yeah, that's my point is. And so. Because we're trying to create an enduring company at Sierra that outlives us, you know, I'm not sure we want to like attach our cart to some like to a horse where it's not clear that like we've figured out and I actually want as a company, we're trying to enable just at a high level and I'll, I'll quickly go back to tech at Sierra, we help consumer brands build customer facing AI agents.[00:23:48] Bret: So. Everyone from Sonos to ADT home security to Sirius XM, you know, if you call them on the phone and AI will pick up with you, you know, chat with them on the Sirius XM homepage. It's an AI agent called Harmony [00:24:00] that they've built on our platform. We're what are the contours of what it means for someone to build an end to end complete customer experience with AI with conversational AI.[00:24:09] Bret: You know, we really want to dive into the deep end of, of all the trade offs to do it. You know, where do you use fine tuning? Where do you string models together? You know, where do you use reasoning? Where do you use generation? How do you use reasoning? How do you express the guardrails of an agentic process?[00:24:25] Bret: How do you impose determinism on a fundamentally non deterministic technology? There's just a lot of really like as an important design space. And I could sit here and tell you, we have the best approach. Every entrepreneur will, you know. But I hope that in two years, we look back at our platform and laugh at how naive we were, because that's the pace of change broadly.[00:24:45] Bret: If you talk about like the startup opportunities, I'm not wholly skeptical of tools companies, but I'm fairly skeptical. There's always an exception for every role, but I believe that certainly there's a big market for [00:25:00] frontier models, but largely for companies with huge CapEx budgets. So. Open AI and Microsoft's Anthropic and Amazon Web Services, Google Cloud XAI, which is very well capitalized now, but I think the, the idea that a company can make money sort of pre training a foundation model is probably not true.[00:25:20] Bret: It's hard to, you're competing with just, you know, unreasonably large CapEx budgets. And I just like the cloud infrastructure market, I think will be largely there. I also really believe in the applications of AI. And I define that not as like building agents or things like that. I define it much more as like, you're actually solving a problem for a business.[00:25:40] Bret: So it's what Harvey is doing in legal profession or what cursor is doing for software engineering or what we're doing for customer experience and customer service. The reason I believe in that is I do think that in the age of AI, what's really interesting about software is it can actually complete a task.[00:25:56] Bret: It can actually do a job, which is very different than the value proposition of [00:26:00] software was to ancient history two years ago. And as a consequence, I think the way you build a solution and For a domain is very different than you would have before, which means that it's not obvious, like the incumbent incumbents have like a leg up, you know, necessarily, they certainly have some advantages, but there's just such a different form factor, you know, for providing a solution and it's just really valuable.[00:26:23] Bret: You know, it's. Like just think of how much money cursor is saving software engineering teams or the alternative, how much revenue it can produce tool making is really challenging. If you look at the cloud market, just as a analog, there are a lot of like interesting tools, companies, you know, Confluent, Monetized Kafka, Snowflake, Hortonworks, you know, there's a, there's a bunch of them.[00:26:48] Bret: A lot of them, you know, have that mix of sort of like like confluence or have the open source or open core or whatever you call it. I, I, I'm not an expert in this area. You know, I do think [00:27:00] that developers are fickle. I think that in the tool space, I probably like. Default towards open source being like the area that will win.[00:27:09] Bret: It's hard to build a company around this and then you end up with companies sort of built around open source to that can work. Don't get me wrong, but I just think that it's nowadays the tools are changing so rapidly that I'm like, not totally skeptical of tool makers, but I just think that open source will broadly win, but I think that the CapEx required for building frontier models is such that it will go to a handful of big companies.[00:27:33] Bret: And then I really believe in agents for specific domains which I think will, it's sort of the analog to software as a service in this new era. You know, it's like, if you just think of the cloud. You can lease a server. It's just a low level primitive, or you can buy an app like you know, Shopify or whatever.[00:27:51] Bret: And most people building a storefront would prefer Shopify over hand rolling their e commerce storefront. I think the same thing will be true of AI. So [00:28:00] I've. I tend to like, if I have a, like an entrepreneur asked me for advice, I'm like, you know, move up the stack as far as you can towards a customer need.[00:28:09] Bret: Broadly, but I, but it doesn't reduce my excitement about what is the reactive building agents kind of thing, just because it is, it is the right question to ask, but I think we'll probably play out probably an open source space more than anything else.[00:28:21] swyx: Yeah, and it's not a priority for you. There's a lot in there.[00:28:24] swyx: I'm kind of curious about your idea maze towards, there are many customer needs. You happen to identify customer experience as yours, but it could equally have been coding assistance or whatever. I think for some, I'm just kind of curious at the top down, how do you look at the world in terms of the potential problem space?[00:28:44] swyx: Because there are many people out there who are very smart and pick the wrong problem.[00:28:47] Bret: Yeah, that's a great question.[00:28:48] Future of Software Development[00:28:48] Bret: By the way, I would love to talk about the future of software, too, because despite the fact it didn't pick coding, I have a lot of that, but I can talk to I can answer your question, though, you know I think when a technology is as [00:29:00] cool as large language models.[00:29:02] Bret: You just see a lot of people starting from the technology and searching for a problem to solve. And I think it's why you see a lot of tools companies, because as a software engineer, you start building an app or a demo and you, you encounter some pain points. You're like,[00:29:17] swyx: a lot of[00:29:17] Bret: people are experiencing the same pain point.[00:29:19] Bret: What if I make it? That it's just very incremental. And you know, I always like to use the metaphor, like you can sell coffee beans, roasted coffee beans. You can add some value. You took coffee beans and you roasted them and roasted coffee beans largely, you know, are priced relative to the cost of the beans.[00:29:39] Bret: Or you can sell a latte and a latte. Is rarely priced directly like as a percentage of coffee bean prices. In fact, if you buy a latte at the airport, it's a captive audience. So it's a really expensive latte. And there's just a lot that goes into like. How much does a latte cost? And I bring it up because there's a supply chain from growing [00:30:00] coffee beans to roasting coffee beans to like, you know, you could make one at home or you could be in the airport and buy one and the margins of the company selling lattes in the airport is a lot higher than the, you know, people roasting the coffee beans and it's because you've actually solved a much more acute human problem in the airport.[00:30:19] Bret: And, and it's just worth a lot more to that person in that moment. It's kind of the way I think about technology too. It sounds funny to liken it to coffee beans, but you're selling tools on top of a large language model yet in some ways your market is big, but you're probably going to like be price compressed just because you're sort of a piece of infrastructure and then you have open source and all these other things competing with you naturally.[00:30:43] Bret: If you go and solve a really big business problem for somebody, that's actually like a meaningful business problem that AI facilitates, they will value it according to the value of that business problem. And so I actually feel like people should just stop. You're like, no, that's, that's [00:31:00] unfair. If you're searching for an idea of people, I, I love people trying things, even if, I mean, most of the, a lot of the greatest ideas have been things no one believed in.[00:31:07] Bret: So I like, if you're passionate about something, go do it. Like who am I to say, yeah, a hundred percent. Or Gmail, like Paul as far, I mean I, some of it's Laura at this point, but like Gmail is Paul's own email for a long time. , and then I amusingly and Paul can't correct me, I'm pretty sure he sent her in a link and like the first comment was like, this is really neat.[00:31:26] Bret: It would be great. It was not your email, but my own . I don't know if it's a true story. I'm pretty sure it's, yeah, I've read that before. So scratch your own niche. Fine. Like it depends on what your goal is. If you wanna do like a venture backed company, if its a. Passion project, f*****g passion, do it like don't listen to anybody.[00:31:41] Bret: In fact, but if you're trying to start, you know an enduring company, solve an important business problem. And I, and I do think that in the world of agents, the software industries has shifted where you're not just helping people more. People be more productive, but you're actually accomplishing tasks autonomously.[00:31:58] Bret: And as a consequence, I think the [00:32:00] addressable market has just greatly expanded just because software can actually do things now and actually accomplish tasks and how much is coding autocomplete worth. A fair amount. How much is the eventual, I'm certain we'll have it, the software agent that actually writes the code and delivers it to you, that's worth a lot.[00:32:20] Bret: And so, you know, I would just maybe look up from the large language models and start thinking about the economy and, you know, think from first principles. I don't wanna get too far afield, but just think about which parts of the economy. We'll benefit most from this intelligence and which parts can absorb it most easily.[00:32:38] Bret: And what would an agent in this space look like? Who's the customer of it is the technology feasible. And I would just start with these business problems more. And I think, you know, the best companies tend to have great engineers who happen to have great insight into a market. And it's that last part that I think some people.[00:32:56] Bret: Whether or not they have, it's like people start so much in the technology, they [00:33:00] lose the forest for the trees a little bit.[00:33:02] Alessio: How do you think about the model of still selling some sort of software versus selling more package labor? I feel like when people are selling the package labor, it's almost more stateless, you know, like it's easier to swap out if you're just putting an input and getting an output.[00:33:16] Alessio: If you think about coding, if there's no ID, you're just putting a prompt and getting back an app. It doesn't really matter. Who generates the app, you know, you have less of a buy in versus the platform you're building, I'm sure on the backend customers have to like put on their documentation and they have, you know, different workflows that they can tie in what's kind of like the line to draw there versus like going full where you're managed customer support team as a service outsource versus.[00:33:40] Alessio: This is the Sierra platform that you can build on. What was that decision? I'll sort of[00:33:44] Bret: like decouple the question in some ways, which is when you have something that's an agent, who is the person using it and what do they want to do with it? So let's just take your coding agent for a second. I will talk about Sierra as well.[00:33:59] Bret: Who's the [00:34:00] customer of a, an agent that actually produces software? Is it a software engineering manager? Is it a software engineer? And it's there, you know, intern so to speak. I don't know. I mean, we'll figure this out over the next few years. Like what is that? And is it generating code that you then review?[00:34:16] Bret: Is it generating code with a set of unit tests that pass, what is the actual. For lack of a better word contract, like, how do you know that it did what you wanted it to do? And then I would say like the product and the pricing, the packaging model sort of emerged from that. And I don't think the world's figured out.[00:34:33] Bret: I think it'll be different for every agent. You know, in our customer base, we do what's called outcome based pricing. So essentially every time the AI agent. Solves the problem or saves a customer or whatever it might be. There's a pre negotiated rate for that. We do that. Cause it's, we think that that's sort of the correct way agents, you know, should be packaged.[00:34:53] Bret: I look back at the history of like cloud software and notably the introduction of the browser, which led to [00:35:00] software being delivered in a browser, like Salesforce to. Famously invented sort of software as a service, which is both a technical delivery model through the browser, but also a business model, which is you subscribe to it rather than pay for a perpetual license.[00:35:13] Bret: Those two things are somewhat orthogonal, but not really. If you think about the idea of software running in a browser, that's hosted. Data center that you don't own, you sort of needed to change the business model because you don't, you can't really buy a perpetual license or something otherwise like, how do you afford making changes to it?[00:35:31] Bret: So it only worked when you were buying like a new version every year or whatever. So to some degree, but then the business model shift actually changed business as we know it, because now like. Things like Adobe Photoshop. Now you subscribe to rather than purchase. So it ended up where you had a technical shift and a business model shift that were very logically intertwined that actually the business model shift was turned out to be as significant as the technical as the shift.[00:35:59] Bret: And I think with [00:36:00] agents, because they actually accomplish a job, I do think that it doesn't make sense to me that you'd pay for the privilege of like. Using the software like that coding agent, like if it writes really bad code, like fire it, you know, I don't know what the right metaphor is like you should pay for a job.[00:36:17] Bret: Well done in my opinion. I mean, that's how you pay your software engineers, right? And[00:36:20] swyx: and well, not really. We paid to put them on salary and give them options and they vest over time. That's fair.[00:36:26] Bret: But my point is that you don't pay them for how many characters they write, which is sort of the token based, you know, whatever, like, There's a, that famous Apple story where we're like asking for a report of how many lines of code you wrote.[00:36:40] Bret: And one of the engineers showed up with like a negative number cause he had just like done a big refactoring. There was like a big F you to management who didn't understand how software is written. You know, my sense is like the traditional usage based or seat based thing. It's just going to look really antiquated.[00:36:55] Bret: Cause it's like asking your software engineer, how many lines of code did you write today? Like who cares? Like, cause [00:37:00] absolutely no correlation. So my old view is I don't think it's be different in every category, but I do think that that is the, if an agent is doing a job, you should, I think it properly incentivizes the maker of that agent and the customer of, of your pain for the job well done.[00:37:16] Bret: It's not always perfect to measure. It's hard to measure engineering productivity, but you can, you should do something other than how many keys you typed, you know Talk about perverse incentives for AI, right? Like I can write really long functions to do the same thing, right? So broadly speaking, you know, I do think that we're going to see a change in business models of software towards outcomes.[00:37:36] Bret: And I think you'll see a change in delivery models too. And, and, you know, in our customer base you know, we empower our customers to really have their hands on the steering wheel of what the agent does they, they want and need that. But the role is different. You know, at a lot of our customers, the customer experience operations folks have renamed themselves the AI architects, which I think is really cool.[00:37:55] Bret: And, you know, it's like in the early days of the Internet, there's the role of the webmaster. [00:38:00] And I don't know whether your webmaster is not a fashionable, you know, Term, nor is it a job anymore? I just, I don't know. Will they, our tech stand the test of time? Maybe, maybe not. But I do think that again, I like, you know, because everyone listening right now is a software engineer.[00:38:14] Bret: Like what is the form factor of a coding agent? And actually I'll, I'll take a breath. Cause actually I have a bunch of pins on them. Like I wrote a blog post right before Christmas, just on the future of software development. And one of the things that's interesting is like, if you look at the way I use cursor today, as an example, it's inside of.[00:38:31] Bret: A repackaged visual studio code environment. I sometimes use the sort of agentic parts of it, but it's largely, you know, I've sort of gotten a good routine of making it auto complete code in the way I want through tuning it properly when it actually can write. I do wonder what like the future of development environments will look like.[00:38:55] Bret: And to your point on what is a software product, I think it's going to change a lot in [00:39:00] ways that will surprise us. But I always use, I use the metaphor in my blog post of, have you all driven around in a way, Mo around here? Yeah, everyone has. And there are these Jaguars, the really nice cars, but it's funny because it still has a steering wheel, even though there's no one sitting there and the steering wheels like turning and stuff clearly in the future.[00:39:16] Bret: If once we get to that, be more ubiquitous, like why have the steering wheel and also why have all the seats facing forward? Maybe just for car sickness. I don't know, but you could totally rearrange the car. I mean, so much of the car is oriented around the driver, so. It stands to reason to me that like, well, autonomous agents for software engineering run through visual studio code.[00:39:37] Bret: That seems a little bit silly because having a single source code file open one at a time is kind of a goofy form factor for when like the code isn't being written primarily by you, but it begs the question of what's your relationship with that agent. And I think the same is true in our industry of customer experience, which is like.[00:39:55] Bret: Who are the people managing this agent? What are the tools do they need? And they definitely need [00:40:00] tools, but it's probably pretty different than the tools we had before. It's certainly different than training a contact center team. And as software engineers, I think that I would like to see particularly like on the passion project side or research side.[00:40:14] Bret: More innovation in programming languages. I think that we're bringing the cost of writing code down to zero. So the fact that we're still writing Python with AI cracks me up just cause it's like literally was designed to be ergonomic to write, not safe to run or fast to run. I would love to see more innovation and how we verify program correctness.[00:40:37] Bret: I studied for formal verification in college a little bit and. It's not very fashionable because it's really like tedious and slow and doesn't work very well. If a lot of code is being written by a machine, you know, one of the primary values we can provide is verifying that it actually does what we intend that it does.[00:40:56] Bret: I think there should be lots of interesting things in the software development life cycle, like how [00:41:00] we think of testing and everything else, because. If you think about if we have to manually read every line of code that's coming out as machines, it will just rate limit how much the machines can do. The alternative is totally unsafe.[00:41:13] Bret: So I wouldn't want to put code in production that didn't go through proper code review and inspection. So my whole view is like, I actually think there's like an AI native I don't think the coding agents don't work well enough to do this yet, but once they do, what is sort of an AI native software development life cycle and how do you actually.[00:41:31] Bret: Enable the creators of software to produce the highest quality, most robust, fastest software and know that it's correct. And I think that's an incredible opportunity. I mean, how much C code can we rewrite and rust and make it safe so that there's fewer security vulnerabilities. Can we like have more efficient, safer code than ever before?[00:41:53] Bret: And can you have someone who's like that guy in the matrix, you know, like staring at the little green things, like where could you have an operator [00:42:00] of a code generating machine be like superhuman? I think that's a cool vision. And I think too many people are focused on like. Autocomplete, you know, right now, I'm not, I'm not even, I'm guilty as charged.[00:42:10] Bret: I guess in some ways, but I just like, I'd like to see some bolder ideas. And that's why when you were joking, you know, talking about what's the react of whatever, I think we're clearly in a local maximum, you know, metaphor, like sort of conceptual local maximum, obviously it's moving really fast. I think we're moving out of it.[00:42:26] Alessio: Yeah. At the end of 23, I've read this blog post from syntax to semantics. Like if you think about Python. It's taking C and making it more semantic and LLMs are like the ultimate semantic program, right? You can just talk to them and they can generate any type of syntax from your language. But again, the languages that they have to use were made for us, not for them.[00:42:46] Alessio: But the problem is like, as long as you will ever need a human to intervene, you cannot change the language under it. You know what I mean? So I'm curious at what point of automation we'll need to get, we're going to be okay making changes. To the underlying languages, [00:43:00] like the programming languages versus just saying, Hey, you just got to write Python because I understand Python and I'm more important at the end of the day than the model.[00:43:08] Alessio: But I think that will change, but I don't know if it's like two years or five years. I think it's more nuanced actually.[00:43:13] Bret: So I think there's a, some of the more interesting programming languages bring semantics into syntax. So let me, that's a little reductive, but like Rust as an example, Rust is memory safe.[00:43:25] Bret: Statically, and that was a really interesting conceptual, but it's why it's hard to write rust. It's why most people write python instead of rust. I think rust programs are safer and faster than python, probably slower to compile. But like broadly speaking, like given the option, if you didn't have to care about the labor that went into it.[00:43:45] Bret: You should prefer a program written in Rust over a program written in Python, just because it will run more efficiently. It's almost certainly safer, et cetera, et cetera, depending on how you define safe, but most people don't write Rust because it's kind of a pain in the ass. And [00:44:00] the audience of people who can is smaller, but it's sort of better in most, most ways.[00:44:05] Bret: And again, let's say you're making a web service and you didn't have to care about how hard it was to write. If you just got the output of the web service, the rest one would be cheaper to operate. It's certainly cheaper and probably more correct just because there's so much in the static analysis implied by the rest programming language that it probably will have fewer runtime errors and things like that as well.[00:44:25] Bret: So I just give that as an example, because so rust, at least my understanding that came out of the Mozilla team, because. There's lots of security vulnerabilities in the browser and it needs to be really fast. They said, okay, we want to put more of a burden at the authorship time to have fewer issues at runtime.[00:44:43] Bret: And we need the constraint that it has to be done statically because browsers need to be really fast. My sense is if you just think about like the, the needs of a programming language today, where the role of a software engineer is [00:45:00] to use an AI to generate functionality and audit that it does in fact work as intended, maybe functionally, maybe from like a correctness standpoint, some combination thereof, how would you create a programming system that facilitated that?[00:45:15] Bret: And, you know, I bring up Rust is because I think it's a good example of like, I think given a choice of writing in C or Rust, you should choose Rust today. I think most people would say that, even C aficionados, just because. C is largely less safe for very similar, you know, trade offs, you know, for the, the system and now with AI, it's like, okay, well, that just changes the game on writing these things.[00:45:36] Bret: And so like, I just wonder if a combination of programming languages that are more structurally oriented towards the values that we need from an AI generated program, verifiable correctness and all of that. If it's tedious to produce for a person, that maybe doesn't matter. But one thing, like if I asked you, is this rest program memory safe?[00:45:58] Bret: You wouldn't have to read it, you just have [00:46:00] to compile it. So that's interesting. I mean, that's like an, that's one example of a very modest form of formal verification. So I bring that up because I do think you have AI inspect AI, you can have AI reviewed. Do AI code reviews. It would disappoint me if the best we could get was AI reviewing Python and having scaled a few very large.[00:46:21] Bret: Websites that were written on Python. It's just like, you know, expensive and it's like every, trust me, every team who's written a big web service in Python has experimented with like Pi Pi and all these things just to make it slightly more efficient than it naturally is. You don't really have true multi threading anyway.[00:46:36] Bret: It's just like clearly that you do it just because it's convenient to write. And I just feel like we're, I don't want to say it's insane. I just mean. I do think we're at a local maximum. And I would hope that we create a programming system, a combination of programming languages, formal verification, testing, automated code reviews, where you can use AI to generate software in a high scale way and trust it.[00:46:59] Bret: And you're [00:47:00] not limited by your ability to read it necessarily. I don't know exactly what form that would take, but I feel like that would be a pretty cool world to live in.[00:47:08] Alessio: Yeah. We had Chris Lanner on the podcast. He's doing great work with modular. I mean, I love. LVM. Yeah. Basically merging rust in and Python.[00:47:15] Alessio: That's kind of the idea. Should be, but I'm curious is like, for them a big use case was like making it compatible with Python, same APIs so that Python developers could use it. Yeah. And so I, I wonder at what point, well, yeah.[00:47:26] Bret: At least my understanding is they're targeting the data science Yeah. Machine learning crowd, which is all written in Python, so still feels like a local maximum.[00:47:34] Bret: Yeah.[00:47:34] swyx: Yeah, exactly. I'll force you to make a prediction. You know, Python's roughly 30 years old. In 30 years from now, is Rust going to be bigger than Python?[00:47:42] Bret: I don't know this, but just, I don't even know this is a prediction. I just am sort of like saying stuff I hope is true. I would like to see an AI native programming language and programming system, and I use language because I'm not sure language is even the right thing, but I hope in 30 years, there's an AI native way we make [00:48:00] software that is wholly uncorrelated with the current set of programming languages.[00:48:04] Bret: or not uncorrelated, but I think most programming languages today were designed to be efficiently authored by people and some have different trade offs.[00:48:15] Evolution of Programming Languages[00:48:15] Bret: You know, you have Haskell and others that were designed for abstractions for parallelism and things like that. You have programming languages like Python, which are designed to be very easily written, sort of like Perl and Python lineage, which is why data scientists use it.[00:48:31] Bret: It's it can, it has a. Interactive mode, things like that. And I love, I'm a huge Python fan. So despite all my Python trash talk, a huge Python fan wrote at least two of my three companies were exclusively written in Python and then C came out of the birth of Unix and it wasn't the first, but certainly the most prominent first step after assembly language, right?[00:48:54] Bret: Where you had higher level abstractions rather than and going beyond go to, to like abstractions, [00:49:00] like the for loop and the while loop.[00:49:01] The Future of Software Engineering[00:49:01] Bret: So I just think that if the act of writing code is no longer a meaningful human exercise, maybe it will be, I don't know. I'm just saying it sort of feels like maybe it's one of those parts of history that just will sort of like go away, but there's still the role of this offer engineer, like the person actually building the system.[00:49:20] Bret: Right. And. What does a programming system for that form factor look like?[00:49:25] React and Front-End Development[00:49:25] Bret: And I, I just have a, I hope to be just like I mentioned, I remember I was at Facebook in the very early days when, when, what is now react was being created. And I remember when the, it was like released open source I had left by that time and I was just like, this is so f*****g cool.[00:49:42] Bret: Like, you know, to basically model your app independent of the data flowing through it, just made everything easier. And then now. You know, I can create, like there's a lot of the front end software gym play is like a little chaotic for me, to be honest with you. It is like, it's sort of like [00:50:00] abstraction soup right now for me, but like some of those core ideas felt really ergonomic.[00:50:04] Bret: I just wanna, I'm just looking forward to the day when someone comes up with a programming system that feels both really like an aha moment, but completely foreign to me at the same time. Because they created it with sort of like from first principles recognizing that like. Authoring code in an editor is maybe not like the primary like reason why a programming system exists anymore.[00:50:26] Bret: And I think that's like, that would be a very exciting day for me.[00:50:28] The Role of AI in Programming[00:50:28] swyx: Yeah, I would say like the various versions of this discussion have happened at the end of the day, you still need to precisely communicate what you want. As a manager of people, as someone who has done many, many legal contracts, you know how hard that is.[00:50:42] swyx: And then now we have to talk to machines doing that and AIs interpreting what we mean and reading our minds effectively. I don't know how to get across that barrier of translating human intent to instructions. And yes, it can be more declarative, but I don't know if it'll ever Crossover from being [00:51:00] a programming language to something more than that.[00:51:02] Bret: I agree with you. And I actually do think if you look at like a legal contract, you know, the imprecision of the English language, it's like a flaw in the system. How many[00:51:12] swyx: holes there are.[00:51:13] Bret: And I do think that when you're making a mission critical software system, I don't think it should be English language prompts.[00:51:19] Bret: I think that is silly because you want the precision of a a programming language. My point was less about that and more about if the actual act of authoring it, like if you.[00:51:32] Formal Verification in Software[00:51:32] Bret: I'll think of some embedded systems do use formal verification. I know it's very common in like security protocols now so that you can, because the importance of correctness is so great.[00:51:41] Bret: My intellectual exercise is like, why not do that for all software? I mean, probably that's silly just literally to do what we literally do for. These low level security protocols, but the only reason we don't is because it's hard and tedious and hard and tedious are no longer factors. So, like, if I could, I mean, [00:52:00] just think of, like, the silliest app on your phone right now, the idea that that app should be, like, formally verified for its correctness feels laughable right now because, like, God, why would you spend the time on it?[00:52:10] Bret: But if it's zero costs, like, yeah, I guess so. I mean, it never crashed. That's probably good. You know, why not? I just want to, like, set our bars really high. Like. We should make, software has been amazing. Like there's a Mark Andreessen blog post, software is eating the world. And you know, our whole life is, is mediated digitally.[00:52:26] Bret: And that's just increasing with AI. And now we'll have our personal agents talking to the agents on the CRO platform and it's agents all the way down, you know, our core infrastructure is running on these digital systems. We now have like, and we've had a shortage of software developers for my entire life.[00:52:45] Bret: And as a consequence, you know if you look, remember like health care, got healthcare. gov that fiasco security vulnerabilities leading to state actors getting access to critical infrastructure. I'm like. We now have like created this like amazing system that can [00:53:00] like, we can fix this, you know, and I, I just want to, I'm both excited about the productivity gains in the economy, but I just think as software engineers, we should be bolder.[00:53:08] Bret: Like we should have aspirations to fix these systems so that like in general, as you said, as precise as we want to be in the specification of the system. We can make it work correctly now, and I'm being a little bit hand wavy, and I think we need some systems. I think that's where we should set the bar, especially when so much of our life depends on this critical digital infrastructure.[00:53:28] Bret: So I'm I'm just like super optimistic about it. But actually, let's go to what you said for a second, which is correct.[00:53:33] The Importance of Specifications[00:53:33] Bret: Specifications. I think this is the most interesting part of A. I. Agents broadly, which is that most specifications are incomplete. So let's go back to our product engineering discussions.[00:53:45] Bret: You're like, okay, here's a P. R. D. Product requirements document and there's it's really detailed mockups and this like when you click this button, it does this and it's like 100 percent you can think of a missing requirement that [00:54:00] document. Let's say you click this button And the internet goes out, what do you do?[00:54:04] Bret: I don't know if that's in the PRD. It probably isn't, you know, there's, there's always going to be something because like humans are complicated. Right. So what ends up happening is like, I don't know if you can measure it, like what percentage of a product's actual functionality is determined by its code versus the specification, like for a traditional product, Oh, 95%.[00:54:24] Bret: I mean, a little bit, but a lot of it. So like. Code is the specification.[00:54:29] Open Source and Implicit Standards[00:54:29] Bret: It's actually why if you just look at the history of technology, why open source has won out over specifications, like, you know, for a long time, there was a W3C working group on the HTML specification and then, you know, once web kit became prevalent.[00:54:46] Bret: The internet evolved a lot faster and it's not the expense of the standards organizations. It just turns out having a committee of people argue is like a lot less efficient than someone checking in code and then all of a sudden you had vector graphics and you had like [00:55:00] all this really cool stuff that, you know, someone who, in the Google maps days, a guy like, God, that would have made my life easier.[00:55:05] Bret: You know, it's like. SVG support, life would have been a breeze. Try drawing a driving directions line without vector graphics. And so, you know, in general, I think we've gone from these protocols defined in a document to basically open source code that becomes an implicit standard, like systems calls and Linux, like.[00:55:26] Bret: There is a specification. There is post X as a standard, but like the Colonel is the like, that's what people write against and it's both the documented behavior and all of the undocumented behaviors as well for better for worse. And it's why, you know, Linus and others are so adamant about things like binary compatibility and all that, like this stuff matters.[00:55:48] Bret: So one of the things that I really think about is like working with agents broadly is how do you, it's. I don't want to say it's easy to specify the guardrails, you know, [00:56:00] but what about all those unspecified behaviors? So so much of like being a software engineer is like, you come to the point where you're like the internet's out and you get back the error code from the call and you got to do something with it.[00:56:12] Bret: And you know, what percent of the time do you just be like. Yeah, I'm going to do this because it seems reasonable. And what percentage of time do you like write a slack to your PM and be like, what do I do in this case? It's probably more the former than the latter. Otherwise it'd be really fricking inefficient to write software.[00:56:27] AI Agents and Decision Making[00:56:27] Bret: But what happens when your AI makes that decision for you? It's not a wrong decision. You didn't say anything about that case. The AI agent, the word agent comes from the word agency, right? So it's demonstrating its agency and it's making a decision. Does it document it? That would probably be tedious to like, because there's so many implicit decisions.[00:56:44] Bret: What happens when you click the button and the internet's out? It does something you don't like. How do you fix it? I actually think that we are like entering this new world where like the, how we express to an AI agent, what we want [00:57:00] is always going to be an incomplete specification, and that's why agents are useful because they can fill in the gaps with some decent amount of reasoning.[00:57:07] Bret: How you actually tune these over time. And imagine like building an app with an AI agent as your software engineering companion, there's like an infinitely long tail. Infinite is probably over exaggerating a bit, but there's a fairly long tail of functionality that I guarantee is not specified how you actually tune that.[00:57:25] Bret: And this is what I mean about creating a programming system. I don't think we know what that system is yet. And then similarly, I actually think for every single agentic domain, whether it's customer service or legal or software engineering, that's essentially what the company building those agents is building is like the system through which you express the behaviors you want, esoteric and small as it might be anyway, I think that's a really exciting area though, just because I think that's where the magic or that's where the product insights will be in the space is like, how do you encounter that those moments?[00:57:56] Bret: It's kind of built into the UX[00:57:58] swyx: and it can't just be, [00:58:00] the answer can't just be prompt better, you know? No, no, it's impossible.[00:58:04] Bret: The prompt would be too long. Like, imagine getting a PRD that literally specified the behavior of everything that was represented by code. The answer would just be code. Like at that point.[00:58:14] Bret: So here's my point, like prompts are great, but it's not actually a complete specification for anything. It never can be. And so, and I think that's. How you do interactivity, like the sort of human in a loop thing, when and how you do it. And that's why I really believe in, in domain specific agents, because I think answering that in the abstract is like a interesting intellectual exercise.[00:58:39] Bret: But I, that's why I like talking about agents in the abstract kind of, I'm actively disinterested in it because I don't think it actually means anything. All it means is software is making decisions. That's what, you know, at least in a reductive way. But in the context of software engineering, it does make sense.[00:58:53] Bret: Cause you know, like what is the process of first you specify what you want in a product, then you use it, then you give [00:59:00] feedback. You can imagine building a product that actually facilitated that closed loop system. And then how is that represented that complete specification of both what you knew you wanted, what you discovered through usage, the union of all of that is what you care about, and the rest is less to the AI.[00:59:16] Bret: In the legal context, I'm certain there's a way to know, like, when should the AI ask questions? When shouldn't it? How do you actually intervene when it's wrong? And certainly in the customer service case, it's very clear, you know, and how, like how we, our customers review every conversation, how we. Help them find the conversations they should review when they're having millions so they can find the few that are interesting how when something is wrong in one of those conversations, how they can give feedback.[00:59:42] Bret: So it's fixed the next time in a way where we know the context of why I made that decision. But it's not up to us what's right, right? It's up to our customers. So that's why I actually think for right, you know, right now when you think about building an agent and domain to some degree, how you actually interact with the [01:00:00] people specifies behavior is actually where a lot of the magic is.[01:00:03] swyx: Stop me if this is a little bit annoying to you, but I have a bit of a trouble squaring. domain specific agents with the belief that AGI is real, or AGI is coming, because the point is general intelligence. And some part, some way, one way to view the bitter lesson is we can always make progress on being more domain specific.[01:00:22] swyx: Take whatever SOTA is, and you make progress being more domain specific, and then you will be wiped out. The next advance happens. Clearly, you don't believe in that, but how do you personally square those things?[01:00:34] Bret: Yeah, it's a really heavy question.[01:00:36] The Impact of AGI on Industries[01:00:36] Bret: And you know, I think a lot about AGI given my role at open AI but it's even hard for me to really conceptualize.[01:00:41] Bret: And I love spending time with open AI researchers and actually just like people in the community broadly just talking about the implications because there's the first order of fact and I effects of something that is super intelligent in some domains. And then there's the second and third order effects are harder to predict.[01:00:57] Bret: So first as I think that. [01:01:00] It seems likely to me that, you know, at first and something that is AGI will be good in digital domains. You know, because it's software. So if you think about something like AI discovering a new say like pharmaceutical therapy, the barrier to that is probably less the discovery than the clinical trial.[01:01:23] Bret: And, and AI doesn't necessarily help with a clinical trial, right? That's a process that's. Independent of intelligence and it's, it's a physical process. Similarly, if you think about the problem of climate change or like carbon removal, there's probably a lot of that domain that requires great ideas, but like whatever great idea you came up with, if you wanted to sequester that much carbon, there's probably a big physical component to that.[01:01:47] Bret: So it's not really limited by intelligence. It might be, I'm sure it could be accelerated somewhat by intelligence. There's a really interesting conversation with an economist named Tyler Cohen, California. And recently he just, I just watched a video [01:02:00] of him and he was just talking about how there's parts of the economy where intelligence is sort of the limited resource that will take on AI slash AGI really rapidly and will drive incredible productivity gains.[01:02:13] Bret: But there are other parts of the economy that aren't and those will interact. It goes back to these complex second artifacts like prices will go up in the domains that can absorb absorb intelligence rapidly, which will actually then slow down, you know, so it's going to, I don't think it'll be evenly spread.[01:02:28] Bret: I don't think it would be perhaps as rapidly felt in all parts of the economy as people think I might be wrong, but I just think you can generalize in terms of its ability to. Reason about different domains, which I think is what AGI means to most people, but it may not actually. Generalized in the world and tell, because there's a lot of intelligence is not the limiting factor and like a lot of the economy.[01:02:54] Bret: So going back to your, your more practical question is like, why make software at all of, you know, AGI is coming and [01:03:00] say it that way. Should we learn to[01:03:01] swyx: code?[01:03:01] Bret: There's all variations of this. You know, my view is that I really do view AI as a tool and AGI as a tool for humanity. And so my view is when we were talking about like.[01:03:14] Bret: Is your job as a maker of software to author a code in an editor? I would argue no just like a generation ago. Your job wasn't to punch cards in a punch card That is not what your job is. Your job is to produce digital something, whatever it is, what is the purpose of the software that you're making?[01:03:34] Bret: Your job is to produce that. And so I think that like our jobs will change rapidly and meaningfully, but I think the idea that like our job is to type in a. And an editor is, is an artifact of the tools that we have, not actually what we're hired to do, which is to produce a digital experience, to, you know, make firmware for a toaster or whatever, whatever it is we're [01:04:00] doing.[01:04:00] Bret: Right. Like that's our job. Right. And. As a consequence, I think with things like AGI, I think the certainly software engineering will be one of the disciplines most impacted. And I think that it's very, so like, I think if you're in this industry and you define yourself by the tools that you use, like how many characters you can type into them every day, that's probably not like a long term stable place to be, because that's something that certainly AI can do better than you.[01:04:33] Bret: But your judgment about what to build and how to build it still apply. And that will always be true. And one way to think about it's like a little bit reductive is like, you know, look at startups versus larger companies. Like companies like Google and Amazon have so many more engineers than a startup, but then some startups still win.[01:04:51] Bret: Like, why was that? Well, they made better decisions, right? They didn't type faster or produce more code. They did the right thing in the right market, the right time. [01:05:00] And, and similarly. If you look at some of the great companies, it wasn't the lack of they had some unique idea. Sometimes that's a reason why a company succeeds, but it's often a lot of other things and a lot of other forms of execution.[01:05:12] Bret: So like broadly, like the existence of a lot of intelligence will change a lot and it'll change our jobs more than any other industry, or maybe not, maybe it's exaggerated, but certainly as much as any other industry. But I don't think it like changes, like why the economy around digital technology exists.[01:05:29] Bret: And as a consequence, I think I'm really bullish on like the future of, of the software industry. I just think that like some things that are really expensive today will become almost free. And but I think that, I mean, let's be honest, the half life of technology companies is not particularly long as it is.[01:05:46] Bret: Yeah, I, I brought this anecdote in a recent conversation, but When I started at Google, we were in one building in Mountain View and then eventually moved into a campus, which was previously the Silicon Graphics campus. That was the first campus Google, I'm pretty sure it [01:06:00] still has that campus. I think it's got a billion now.[01:06:02] Bret: SGI was a company that was like really, really big, big enough to have a campus and then went out of business. And it wasn't that old of a company, by the way, it's not like IBM, you know, it was like. Big enough to get a campus and go to business in my lifetime, you know, that type of thing. And then at Facebook, we had an office in pallets.[01:06:18] Bret: I moved, I didn't go into the original office when I joined. It was the second office, this old HP building near Stanford. And then we got big enough to want to campus and we bought some microsystems campus. Sun Microsystem famously came out of Stanford, went high flying, was one of the. com darlings, and then eventually sort of like bought for pennies on the dollar by Oracle.[01:06:39] Bret: And you know, like all those companies, like in my lifetime were big enough to like go public, have a campus and then go out of business. So I think a lot will change. I don't mean to say this is going to be easy or like no one's business model is under threat, but. Will digital technology remain important?[01:06:56] Bret: Will entrepreneurs having good judgment about where to [01:07:00] apply this technology to create something of economic value still apply like a hundred percent. And I've always used the metaphor, like if you went back to 1980 and describe many of the jobs that we have, it would be hard for people to conceptualize.[01:07:13] Bret: Like imagine. I'm a podcaster. You're like, what the hell does that mean? Imagine going back to like 1776 and describing to Ben Franklin, our economy today, like let alone the technology industry, just the services economy. It would be probably hard for him to conceptualize just like who grows the food, just because the idea that so few people in this country are necessary to produce the food for so many people would defy.[01:07:39] Bret: So much of his conception of just like how food is grown, that it would just be like, it would probably take a couple hours of explaining. It's kind of like the same thing. It's like we, we have a view of like how this world works right now. That's based on just the constraints that exist, but there's gonna be a lot of other opportunities and other things like that.[01:07:57] Bret: So I don't know. I mean, it's certainly [01:08:00] writing code is really valuable right now and it probably will change rapidly. I think people just need a lot of agility. I always use the metaphor where like a bunch of accountants and Microsoft Excel was just invented. Are you going to be the first person who sets down your HP calculator and says, I'm going to learn how to use this tool because it's just a better way of doing what I'm already doing.[01:08:19] Bret: Or are you going to be the one who's like, you know, begrudgingly pulling out their slide rule and HP calculator and saying these kids these days, you know, their Excel, they don't understand, you know, it's been a little bit reductive, but I just feel like the, the probably the best thing all of us can do, not just in software industry, but I do think it's really.[01:08:38] Bret: Kind of interesting just reflection that we're disrupting our own industry as much as anything else with this technology is to lean into the change, try the tools, like install the latest coding assistance, you know, when Oh three mini comes out, write some code with it that you don't want to be the last accountant to embrace Excel.[01:08:57] Bret: You might not have your job anymore, so.[01:08:59] swyx: [01:09:00] We have some personal questions on like how you keep up with AI and you know, all that, all the other stuff. But I also want to, and I'll let you get to your question. I just wanted to say that the analogy that you made on food was really interesting and resonated with me.[01:09:12] swyx: I feel like we are kind of in like an agrarian economy of like a barter economy for intelligence and now we're sort of industrializing intelligence. And I, that really just was an aha[01:09:21] Alessio: moment for me. I just wanted to reflect that. Yeah. How do you think about. The person being replaced by an agent and how agents talk to each other.[01:09:29] Alessio: So even at Sierra today, right, you're building agents that people talk to, but in the future, you're going to have agents that are going to complain about the order they placed to the customer support agents all the way down. Exactly. And you know, you were the CTO of Facebook, you built OpenGraph there.[01:09:44] Alessio: And I think there were a lot of pros, things that were being enabled, then maybe a lot of cons that came out of that. How do you think about how the agent protocols should be built, thinking about all the implications of it, you know, privacy, data, discoverability and all that?[01:09:57] Bret: Yeah, I think it's a little early for a [01:10:00] protocol to emerge.[01:10:00] Bret: I've read about a few of the attempts and maybe some of them will catch on. One of the things that's really interesting about large language models is because they're trained on language as they are very capable of using the interfaces built for us. And so. My intuition right now is that because we can make an interface that works for us and also works for the AI, maybe that's good enough.[01:10:23] Bret: You know, I mean, a little bit hand wavy here, but making a machine protocol for agents that's inaccessible to people, there's some upsides to it, but there's also quite a bit of downside to it as well. I think it was Andrej Karpathy, but I can't remember. But like one of the more well known AI researchers wrote, like I spent half my day writing English, you know, in my software engineering I have an intuition that agents will speak to agents using language for a while.[01:10:53] Bret: I don't know if that's true. But there's a lot of reasons why there, that may be true. And so, you know, [01:11:00] when. Your personal agent speaks to a Sierra agent to help figure out why your Sonos speaker has the flashing orange light. My intuition is it will be in English for a while. And I think there's a lot of, like, benefits to that.[01:11:13] Bret: I do think that we still are in the early days of Like long running agents I don't know if you tried the deep research agent that just came up,[01:11:22] swyx: we have one for you. Oh, that's great.[01:11:25] Bret: It was interesting cause it was probably the first time I really got like notified by open AI when something was done and I brought up before the interactive parts of it.[01:11:34] Bret: That's the area that I'm most interested in right now. It just is like most agentic workflows are relatively short running and. The workflows that are multi stakeholder, long running and multi system we deal with a lot of those and, and at Sierra, but broadly speaking, I think that those are interesting just because I, I always use the metaphor that prior to the mobile phone, every time you got like [01:12:00] a notification from some internet service, you get an email, not because email was like the best way to notify you, but it's the only way.[01:12:08] Bret: And so you know, you used to get tagged on a photo in Facebook and you get an email about it. Then once. This was in everyone's pocket. Every app had equal access to buzzing your pocket. And now, you know, for most of the apps I use, I don't get email notifications. I just get, get it directly from the app.[01:12:25] Bret: I sort of wonder what the form factors will be for agents. How do you address and reach out to other agents? And then how does it bring you the, the operator of the agent into the loop at the right time? You know, I certainly think there's companies like, you know, with chat GPT, that will be one of the major consumer surfaces.[01:12:42] Bret: So there's like, there's a lot of like gravity to those services. But then if I think about sort of domain specific workflows as well, I think there's just a lot to figure out there. So I'm less. The agent agent protocols. I actually think I could be wrong. I just haven't thought about a lot. Like it's sort of interesting, but actually just how it engages with all [01:13:00] the people in it is actually one of the things I'm most interested to sort of see how it plays out as well.[01:13:04] Alessio: Yeah. I think to me, the things that are at the core of it is kind of like our back, you know, it's like, can this agent access this thing? I think in the customer support use cases, maybe less prominent, but like in the enterprises is more interesting. And also like language, like you can compress the language.[01:13:20] Alessio: If the human didn't have to read it, you can kind of save tokens, make things faster. So yeah, you mentioned being notified about deep research. Is there a open AI deep research has been achieved internally notification that goes out to everybody and the board gets summoned and you get to see it. Can you give any backstory on that process?[01:13:40] Bret: OpenAI is a mission driven nonprofit that I think of primarily as a research lab. It's obviously more than that, you know, in some ways like chat GPT is a cultural defining product. But at the end of the day, the mission is to ensure that artificial general intelligence benefits all of humanity. So a lot [01:14:00] of our board discussions are about.[01:14:02] Bret: Research and its implications on humanity, which is primarily safety. Obviously, I think the one cannot achieve AGI and not think about safety as a primary responsibility for that mission, but it's also access and other things. So things like deep research, we definitely talk about because it's a big part of, if you think about what does it mean to build AGI, but we talk about a lot of different things, you know, so it's like Sometimes we hear about things super early.[01:14:26] Bret: Sometimes if it's not really related, if it's sort of far afield from the core of the mission, you know, it's like more casual. So it's pretty fun, fun to be a part of that just because it's my favorite part of every board discussion is just hearing from the researchers about. How they're thinking about the future and just like the next, next milestone and creating AGI.[01:14:44] swyx: Well, lots of milestones. Maybe we'll just start at the beginning. Like, you know, there are very few people that have been in the rooms that you've been in. How do these conversations start? How do you get brought into opening? I obviously there's, there's a bit of drama that you can go into if you want.[01:14:56] swyx: Just take us into the room. Like what happens? What is it [01:15:00] like?[01:15:00] Bret: Was it a. Thursday or Friday when Friday was fired. Yeah. So I heard about it like everyone else, you know, just like saw it on, on social media. And I remember[01:15:12] swyx: where I was walking here and I was[01:15:14] Bret: totally shocked and messaged my co founder clay.[01:15:17] Bret: And I was like, gosh, I wonder what happened. And then. On Saturday, trying to just protect sort of like people's privacy on this. But I ended up talking to both Adam D'Angelo and Sam Altman and basically getting a kind of synopsis of what was going on and my understanding that you could, you'd have to ask them for sort of their perspective on this was just basically like they, both the board and Sam both felt some trust in me.[01:15:44] Bret: And it was a very complicated situation because the, the company was reacted pretty negatively, understandably negatively to Sam's being fired. I don't think they really understood what was going on. And so the board was, you know, in a situation where they needed to sort of figure [01:16:00] out a path forward and they reached out to me and then I talked to Sam and basically ended up kind of the mediator for lack of a better word, not really formally that, but fundamentally that.[01:16:10] Bret: And as the board was trying to figure out a path forward, you know, we, we ended up with a lot of discussions with like how to reinstate Sam is a CEO of the company, but also do a review of what happens so that the board's concerns could be fully sort of adjudicated, you know because they obviously did have concerns going into it.[01:16:29] Bret: So it ended up there. So I think broadly speaking, I was just like a known, like a lot of the stakeholders in it knew of me and, and I'd like to think I have some integrity, so it was just sort of like, you know, they were trying to find a way out of a very complex situation. So I ended up kind of meeting in that and have formed a.[01:16:48] Bret: A really great relationship with Sam and Greg and pretty challenging time for the company didn't plan to be, you know, on the board. I got pulled in because of the crisis that happened. [01:17:00] And I don't think I'll be on the board forever either. I, I posted when I joined that I was going to do it temporarily.[01:17:05] Bret: That was like a year ago. You know, I really like to focus on Sierra, but I also really care about, it's just an amazing mission. So[01:17:15] Navigating High-Stakes Situations[01:17:15] swyx: I've been maybe been in like high stakes situations like that, like twice, but obviously not as high stakes, but like, what principles do you have? When you know, like, this is the highest egos, highest amount of stakes possible, highest amount of money, whatever.[01:17:31] swyx: What principles do you have to go into something like this? Like, obviously you have a great reputation, you have a great network. What are your must do's and what are your must not do's?[01:17:39] Bret: I'm not sure there's a If there were a playbook for these situations, there'd be a lot simpler. You know, I just probably go back to like the way I operate in general.[01:17:49] Bret: One is first principles thinking. So I, I do think that there's crisis playbooks, but there was nothing quite like this and you really need to [01:18:00] understand what's going on and why. I think a lot of. Moments of crisis are fundamentally human problems. You can strategize about people's incentives and this and that and the other thing, but I think it's really important to understand all the people involved and what motivates them and why, which is fundamentally an exercise in empathy.[01:18:18] Bret: Actually. Like, do you really understand. Why people are doing what they're doing and then getting good advice, you know, and I think people What's interesting about a high profile crisis is everyone wants to give you advice So there's no shortage of advice, but the good advice is the one I think that really involves judgment Which is who are people based on first principles analysis of the situation based on your assessment?[01:18:41] Bret: Of what, you know, all the people involved who would have true expertise and good judgment, you know, in these situations so that you can either validate your judgment if you have an intuition or if it's an area that's like a area of like, say, a legal expertise that you're not expert and [01:19:00] you want the best in the world to give you advice.[01:19:02] Bret: And I actually find people often seek out. The wrong people for advice and it's really important in those circumstances.[01:19:08] swyx: Well, I mean, it's super well navigated. I have, I've got one more and then we can sort of move on on this topic. The the, the Microsoft offer was real, right? For Sam and team to move over at some, at one point in that weekend.[01:19:19] Bret: I'm not sure. I was sort of in it from one vantage point, which was actually, it's interesting. It's like, I didn't really have. Particular skin in the game. So like I came up with this, I still don't own any equity in open AI. I was just I was just a meaningful bystander in the process. And the reason I got involved and and it will get to answer your question, but the reason I got involved was just because I cared about open AI.[01:19:44] Bret: So. You know, I had left my job at Salesforce and by coincidence, the next month chat GBT comes out and, you know, I got nerd sniped like everyone else. I'm like, I want to spend my life on this. This is so amazing. And I wouldn't, I don't know if I'd be, I wouldn't, I'm not [01:20:00] sure I would have started another company if not for open AI, kind of inspiring the world with chat GPT, maybe I would have, I don't know, but it was like, it had a very significant impact on you, all of us, I think.[01:20:11] Bret: So the idea that it would dissolve in a weekend just like bothered me a lot. And I'm very, like, I'm very grateful for, for open AI's existence. And, and I, my guess is that is probably shared by a lot of the competing research labs to different degrees too. It's just like it kind of that rising tide lifted all boats.[01:20:27] Bret: Like I think it created the proverbial iPhone moment for AI and, and changed, changed the world. So there were lots of. Microsoft is an investor in open AI. It has a vested interest in it. The Sam and Greg had their interests. The employees had their interests and there's lots of wheeling and dealing.[01:20:49] Bret: And I, you know, you can't AB test decision making. So I don't know if like things had fallen apart with that. I don't, I don't actually know. And you also don't know, like what's real, what's not. I [01:21:00] mean, so you'd have to talk to, to them to know it was really real. So.[01:21:03] swyx: Mentioning advisors. I heard it seems like Brian Armstrong was.[01:21:07] swyx: surprisingly strong advisor on during, during the whole journey, which is[01:21:10] Bret: the my understanding was both Brian Armstrong and Ron Conway were really close to Sam through it. And I ended up talking to him, but also tried to. Talk a lot to the board to, you know, trying to be the mediator. I was trying to, you obviously have a position on it.[01:21:25] Bret: Like, and I, I felt that, you know, from the outside looking in, I just really wanted to understand, like, why did this happen? And the process seemed, you know perhaps, you know, to say the least. But I was trying to remain sort of dispassionate because one of the principles was like, if you want to put Humpty Dumpty back together again, you can't be a single issue voter, right?[01:21:45] Bret: Like you have to go in and say like, so it was a pretty sensitive moment. But yeah, my, I think Brian's one of the great entrepreneurs and a true true, true friend and ally to, to Sam through that he's[01:21:55] swyx: been through a lot. As well. The reason I bring up Microsoft is because, [01:22:00] I mean, obviously Huge Backer.[01:22:01] swyx: We actually talked to David Juan who pitched, I think it was Satya at the time, on on the, the first billion dollar investment in OpenAI. The understanding I had was that the best situation was for Open OpenAI, for Microsoft was open. The As is second best was Microsoft Echo hires Sam and Greg and, and whoever else.[01:22:19] swyx: And that was the relationship at the time. Super close, exclusive relationship and all that. I think now things have evolved a little bit. And you know, with, with the evolution of Stargate and there's some, some uncertainty or FUD about the relationship between Microsoft and OpenAI. And I just wanted to, just kind of bring that up.[01:22:38] swyx: Because like, we're also working, like, one, Satya's, we're fortunate to have Satya as a subscriber to InSpace. And we're working on an interview with him. And we're trying to figure out. How this has evolved now, like what, what is, how would you characterize the relationship between Microsoft and OpenAI?[01:22:52] Bret: Microsoft's, you know, the most important partner of OpenAI, you know, so we have a really like deep relationship with them on many [01:23:00] fronts.[01:23:00] Bret: So I think it's always evolving just because the scale of this market is evolving and in particular the capital requirements for infrastructure. Are well beyond what anyone would have predicted two years ago, let alone whenever the Microsoft relationship started. Well, what was that six years ago? I actually don't, I should know off the top of my head, but it was a long time long in this, in the world of AI, a long, longer time ago.[01:23:24] Bret: I don't really think there's anything to share. I mean, it's I don't, I think the relationships evolved because the markets evolved, but the core tenants of the partnership have remained the same. And it's, you know, by far open eyes, most important partner.[01:23:36] swyx: Just double clicking a little bit more, just like a lot of, obviously a lot of our listeners are, you know, care a lot about the priorities of OpenAI.[01:23:43] swyx: I've had it phrased to me that OpenAI had sort of five Top level priorities, like always have frontier models always be on the frontier sort of efficiency as well. Be the first in sort of multi modality, whether it's video generation or real time voice, anything like that. How would you characterize the top priorities of [01:24:00] OpenAI?[01:24:00] swyx: Apart from just the highest level AGI thing.[01:24:02] Bret: I always come back to the highest level AGI as you put it, it is a mission driven organization. And I think a lot of companies talk about their mission, but OpenAI is literally like the mission defines everything that we do. And I think it is important to understand that if you're trying to like.[01:24:20] Bret: Predict where open AI is going to go, because if it doesn't serve the mission, it's very unlikely that it will be a priority for open AI. You know, it's a big organization, so occasionally you might have like side projects, you're like, you know what, I'm not sure that's going to really serve the mission as much as we thought, like, let's not do it anymore.[01:24:36] Bret: But at the end of the day, like people work at open AI because they believe in the benefits the AGI can have to humanity. Some people are there because they want to build it. And the actual act of building is incredibly intellectually rewarding. Some people are there because they want to ensure that AGI is safe.[01:24:55] Bret: I think we have the best AGI safety team in the world. And there's just [01:25:00] so many interesting research problems to, to tackle there as these models become increasingly capable, as they have access to the internet, it has access to tools. It's just like really interesting stuff, but everyone is there because they're interested in the mission.[01:25:13] Bret: And as a consequence, I think that. You know, if you look at something like deep research, that lens, it's pretty logical, right? It's like, of course, that's if you're going to think about what it means to create AGI, enabling AI to help further the cause of research is, is meaningful. You can see why a lot of the AGI labs are working on.[01:25:34] Bret: Software engineering and code generation, because that seems pretty useful if you're trying to make AGI, right? Just because a huge part of it is, is code, you know to do it. Similarly, as you look at sort of tool use and agents right down the middle of what you need to do AGI, that is the part of the company.[01:25:51] Bret: I don't think there is like a. Top, I mean, sure, there's like a, maybe an operational top 10 list, but it is fundamentally about building AGI and [01:26:00] ensuring AGI benefits all of humanity. And that's all we exist for. And the rest of it is like, not a distraction necessarily, but that's like the only reason the organization exists.[01:26:09] Bret: The thing that I think is remarkable is if I had. Describe that mission to the two of you four years ago, like, you know, one of the interesting things is like, how do you think society would use AI? We'd probably think almost maybe like industrial applications, robots, all these other things. I think chat GPT has been the most.[01:26:26] Bret: Delightful. And it doesn't feel counterintuitive now, but like counterintuitive way to serve that mission, because the idea that you can go to chat, gpt. com and access the most advanced intelligence in the world. And there's like a free tier is like pretty amazing. So actually one of the neat things I think is that chat GPT, you know, famously was a research preview that turned into this brand, you know, industry defining brand.[01:26:54] Bret: I think it is one of the more key parts of the mission in a lot of ways because it is the [01:27:00] way many people will use this intelligence for their everyday use. It's not limited to the few. It's not limited to, you know, a form factor that's inaccessible. So I actually think that. It's been really neat to see how much that has led to there's lots of different contours of the mission of, of AGI, but benefit humanity means everyone can use it.[01:27:21] Bret: And so I do think like to your point on is cost important. Oh yeah. Cost is really important. How can we have all of humanity access AI if it's incredibly expensive and you need the 200 subscription, which I pay for it. Cause I think, you know, one promote is mind blowing, you know, but it's, you want both cause you need the advanced research.[01:27:41] Bret: You also want everyone in the world to benefit. So that's the way, I mean, if you're trying to predict where we're going to go, just think, what would I do if I were running a company to, you know, go build AGI and ensures it benefits humanity. That's, that's how we prioritize everything.[01:27:57] Alessio: I know we're going to wrap up soon.[01:27:58] Alessio: I would love to ask some personal [01:28:00] questions. One, what are maybe. I've been guiding principles for you one and choosing what to do. So, you know, you were Salesforce. You were CTO of Facebook. I'm sure you got it done a lot more things, but those were the choices that you made. Do you have frameworks that you use for that?[01:28:15] Alessio: Yeah, let's start there.[01:28:16] Bret: I try to remain sort of like present and grounded in the moment. So. No, I wish I, I wish I did it more, but I don't I really try to focus on like impact, I guess, on what I work on, but also do I enjoy it? And sometimes I think, yeah, we talked a little bit about, you know, what should an entrepreneur work on if they want to start a business?[01:28:38] Bret: And I was sort of joking around about sometimes like best businesses are passion projects. I definitely take into account both. Like I, I want to have an impact on the world and I also like, want to enjoy building what I'm building. And I wouldn't work on something that was impactful if I didn't enjoy doing it every day.[01:28:55] Bret: And then I try to have some balance in my life. I've got a [01:29:00] family and one of the values of, of Sierra's competitive intensity, but we also have a value called family. And we always like to say. Intensity and balance are compatible. You can be in a really intense person and I don't have a lot of like hobbies.[01:29:18] Bret: I basically just like work and spend time with my family. But I have balanced there. And but I, but I do try to have that balance just because, you know, if you're proverbially, you know, on your deathbed, what do you, what do you want, and I want to be surrounded by people I love and to be proud of the impact that I had.[01:29:35] Alessio: I know you also love to make handmade pasta. I'm Italian, so I would love to hear favorite pasta shapes, maybe sauces. Oh,[01:29:43] Bret: that's good. I don't know where you found that. Was that deep research or whatever? It was deep research. That's a deep[01:29:48] swyx: cut. Sorry, where is this from?[01:29:50] Alessio: It was from,[01:29:51] swyx: from,[01:29:51] Alessio: I[01:29:51] Bret: forget,[01:29:52] Alessio: it was, it was,[01:29:52] Bret: the source was Ling.[01:29:55] Bret: I do love to cook. So I started making pasta when my [01:30:00] kids were little because I found getting them involved in the kitchen made them eat their meals better. So like participating in the act of making the food. Made them appreciate the food more. And so we do a lot of just like spaghetti linguine, just because it's pretty easy to do.[01:30:15] Bret: And the crank is turning and the part of the pasta making for me was like, they could operate the crank and I could put it through and it was very interactive. Sauces. I do a bunch probably, I mean. I, the like really simple marinara with really good tomatoes and it's like just a classic, especially if you're a really good pasta, but I like them all.[01:30:36] Bret: But I mean, I just, you know, that's probably the go to just cause it's easy. So[01:30:40] Alessio: I just said to us when I saw it come up in the research, I was like, I mean, you have to weigh in as the Italian here. Yeah, I would say so. There's one type of spaghetti you called. I like it. That's kind of like they're almost square.[01:30:51] Alessio: Those are really good. We're like you do a cherry tomato sauce with oil. You can put undo again there. Yeah, we can do a different pockets on [01:31:00] head[01:31:00] swyx: of the Italian Tech Mafia. Very, very good restaurants. I highly recommend going to Italian restaurants with him. Yeah. Okay. So my question would be, how do you keep up on the eye?[01:31:10] swyx: There's so much. going on. Do you have some special news resource that you use that no one else has?[01:31:17] Bret: No, but I most mornings I'll try to sort of like read, kind of check out what's going on on social media, just like any buzz around papers. But the thing that I don't The thing I really like, we have a small research team at Sierra and we'll do sessions on interesting papers then.[01:31:36] Bret: I think that's really nice. And, you know, usually it's someone who like really went deep on a paper and kind of does a, you know, you bring your lunch and just kind of do a readout. And I found that to be the most rewarding just because, you know, I love research, but sometimes, you know, some simple concepts are, you know, surrounded by a lot of ornate language and you're like, let's get a few more, you know, Greek letters in there to make it [01:32:00] seem like we did something smart, you know?[01:32:02] Bret: Sometimes just talking it through conceptually, I can grok the, so what, you know, more easily. And so that's also been interesting as well. And then just conversations, you know, I always try to, when someone says something I'm not familiar with, like I've gotten over the feeling dumb thing. I'm like, I don't know what that is.[01:32:20] Bret: Explain it to me. And, and yes, you can sometimes just find neat techniques, new papers, things like that. It's impossible to keep up that, to be honest with you.[01:32:29] swyx: For sure. I mean, if you're struggling, I mean, imagine the rest of us. But like, you know, you, you have really privileged and special conversations.[01:32:36] swyx: What research directions do you think people should pay attention to just based on the buzz you're hearing internally, or, you know,[01:32:42] Bret: This isn't surprising to you or anyone, but I, I think the I think in general, the reasoning models, but it's interesting because two years ago, you know, the chain of thought reasoning paper was pretty important, you know, and in general, chain of thought has always been a meaningful thing from the [01:33:00] time I think it was a Google paper, right?[01:33:01] Bret: If I'm remembering correctly and Google authors. Yeah. And I think that. It has always been a way to get more robust results, you know, from models. What's just really interesting is the combination of distillation and reasoning is making the relative performance. And I'll say actually performance is an ambiguous word, basically the latency of these reasoning models, more reasonable, because if you think about say GPT 4, which was, I think, a huge step change in intelligence, it was.[01:33:33] Bret: Quite slow and quite expensive for a long time. So it limited the applications. Once you got to 4. 0 and 4. 0 mini, you know, it opened the door to a lot of different applications, both for cost and latency. We know one came out really interesting quality wise, but it's quite slow, quite expensive. So just the limited applications.[01:33:52] Bret: Now I just saw like someone post one of they distilled one of the deep seek models and just made it really [01:34:00] small. And, you know, it's doing these chains of thoughts so fast, you know, it's achieving latency numbers. I think sort of similar to like GPT four back in the day. And now all of a sudden you're like, wow, this is really interesting.[01:34:11] Bret: And I just think. Especially if there's lots of people listening who are like applied AI people, it's basically like price performance quality. And for a long, like for a long time, the market's so young, if you, you really had to pick which quadrant you wanted for the use case and. The idea that we'll be able to get like relatively sophisticated reasoning at like oh, three minutes has been amazing.[01:34:34] Bret: If you haven't tried, it's like the speed of it makes me use it so much more than oh, one, just because oh, one, I'd actually often craft my prompts using for, oh, and then put it into a one just because it was so slow, you know, I just didn't want to like the turnaround time. So I'm just really excited about them.[01:34:50] Bret: I think we're in the early days in the same way with the rapid change from GPT three to three, five to four. And you just saw like. Every, and I think with these reasoning [01:35:00] models, just how we're using sort of inference time compute and the techniques around it, the use cases for it, it feels like we're in that kind of Cambrian explosion of ideas and possibilities.[01:35:11] Bret: So I just think it's really exciting. And and certainly if you look at some of the use cases we're talking about, like coding, these are the exact types of domains where these reasoning models. Do and should have better results. And certainly in our domain, there's just some problems that like thinking through more robustly, which we've always done, but it's just been like, these models are just coming out of the box with a lot more batteries included.[01:35:35] Bret: So I'm super excited about them.[01:35:37] Alessio: Any final call to action? Are you hiring, growing the team? More people should use Sierra, obviously.[01:35:42] Bret: We are growing the team and we're hiring software engineers, agent engineers so send me a note, Bret at Sierra dot AI, we're growing like weed. Our engineering team is exclusively in person in San Francisco, though we do have some kind of forward deployed engineers and, and other offices like [01:36:00] London, so[01:36:00] Alessio: awesome.[01:36:01] Alessio: Thank you so much for the time, Bret.[01:36:03] Bret: Thanks for having me. Get full access to Latent.Space at www.latent.space/subscribe
-
 Agent Engineering with Pydantic + Graphs — with Samuel Colvin
Agent Engineering with Pydantic + Graphs — with Samuel ColvinFrom 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2025-02-06 22:58
Did you know that adding a simple Code Interpreter took o3 from 9.2% to 32% on FrontierMath? The Latent Space crew is hosting a hack night Feb 11th in San Francisco focused on CodeGen use cases, co-hosted with E2B and Edge AGI; watch E2B’s new workshop and RSVP here!We’re happy to announce that today’s guest Samuel Colvin will be teaching his very first Pydantic AI workshop at the newly announced AI Engineer NYC Workshops day on Feb 22! 25 tickets left.If you’re a Python developer, it’s very likely that you’ve heard of Pydantic. Every month, it’s downloaded >300,000,000 times, making it one of the top 25 PyPi packages. OpenAI uses it in its SDK for structured outputs, it’s at the core of FastAPI, and if you’ve followed our AI Engineer Summit conference, Jason Liu of Instructor has given two great talks about it: “Pydantic is all you need” and “Pydantic is STILL all you need”. Now, Samuel Colvin has raised $17M from Sequoia to turn Pydantic from an open source project to a full stack AI engineer platform with Logfire, their observability platform, and PydanticAI, their new agent framework.Logfire: bringing OTEL to AIOpenTelemetry recently merged Semantic Conventions for LLM workloads which provides standard definitions to track performance like gen_ai.server.time_per_output_token. In Sam’s view at least 80% of new apps being built today have some sort of LLM usage in them, and just like web observability platform got replaced by cloud-first ones in the 2010s, Logfire wants to do the same for AI-first apps. If you’re interested in the technical details, Logfire migrated away from Clickhouse to Datafusion for their backend. We spent some time on the importance of picking open source tools you understand and that you can actually contribute to upstream, rather than the more popular ones; listen in ~43:19 for that part.Agents are the killer app for graphsPydantic AI is their attempt at taking a lot of the learnings that LangChain and the other early LLM frameworks had, and putting Python best practices into it. At an API level, it’s very similar to the other libraries: you can call LLMs, create agents, do function calling, do evals, etc.They define an “Agent” as a container with a system prompt, tools, structured result, and an LLM. Under the hood, each Agent is now a graph of function calls that can orchestrate multi-step LLM interactions. You can start simple, then move toward fully dynamic graph-based control flow if needed.“We were compelled enough by graphs once we got them right that our agent implementation [...] is now actually a graph under the hood.”Why Graphs?* More natural for complex or multi-step AI workflows.* Easy to visualize and debug with mermaid diagrams.* Potential for distributed runs, or “waiting days” between steps in certain flows.In parallel, you see folks like Emil Eifrem of Neo4j talk about GraphRAG as another place where graphs fit really well in the AI stack, so it might be time for more people to take them seriously.Full Video EpisodeLike and subscribe!Chapters* 00:00:00 Introductions* 00:00:24 Origins of Pydantic* 00:05:28 Pydantic's AI moment * 00:08:05 Why build a new agents framework?* 00:10:17 Overview of Pydantic AI* 00:12:33 Becoming a believer in graphs* 00:24:02 God Model vs Compound AI Systems* 00:28:13 Why not build an LLM gateway?* 00:31:39 Programmatic testing vs live evals* 00:35:51 Using OpenTelemetry for AI traces* 00:43:19 Why they don't use Clickhouse* 00:48:34 Competing in the observability space* 00:50:41 Licensing decisions for Pydantic and LogFire* 00:51:48 Building Pydantic.run* 00:55:24 Marimo and the future of Jupyter notebooks* 00:57:44 London's AI sceneShow Notes* Sam Colvin* Pydantic* Pydantic AI* Logfire* Pydantic.run* Zod* E2B* Arize* Langsmith* Marimo* Prefect* GLA (Google Generative Language API)* OpenTelemetry* Jason Liu* Sebastian Ramirez* Bogomil Balkansky* Hood Chatham* Jeremy Howard* Andrew LambTranscriptAlessio [00:00:03]: Hey, everyone. Welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol AI.Swyx [00:00:12]: Good morning. And today we're very excited to have Sam Colvin join us from Pydantic AI. Welcome. Sam, I heard that Pydantic is all we need. Is that true?Samuel [00:00:24]: I would say you might need Pydantic AI and Logfire as well, but it gets you a long way, that's for sure.Swyx [00:00:29]: Pydantic almost basically needs no introduction. It's almost 300 million downloads in December. And obviously, in the previous podcasts and discussions we've had with Jason Liu, he's been a big fan and promoter of Pydantic and AI.Samuel [00:00:45]: Yeah, it's weird because obviously I didn't create Pydantic originally for uses in AI, it predates LLMs. But it's like we've been lucky that it's been picked up by that community and used so widely.Swyx [00:00:58]: Actually, maybe we'll hear it. Right from you, what is Pydantic and maybe a little bit of the origin story?Samuel [00:01:04]: The best name for it, which is not quite right, is a validation library. And we get some tension around that name because it doesn't just do validation, it will do coercion by default. We now have strict mode, so you can disable that coercion. But by default, if you say you want an integer field and you get in a string of 1, 2, 3, it will convert it to 123 and a bunch of other sensible conversions. And as you can imagine, the semantics around it. Exactly when you convert and when you don't, it's complicated, but because of that, it's more than just validation. Back in 2017, when I first started it, the different thing it was doing was using type hints to define your schema. That was controversial at the time. It was genuinely disapproved of by some people. I think the success of Pydantic and libraries like FastAPI that build on top of it means that today that's no longer controversial in Python. And indeed, lots of other people have copied that route, but yeah, it's a data validation library. It uses type hints for the for the most part and obviously does all the other stuff you want, like serialization on top of that. But yeah, that's the core.Alessio [00:02:06]: Do you have any fun stories on how JSON schemas ended up being kind of like the structure output standard for LLMs? And were you involved in any of these discussions? Because I know OpenAI was, you know, one of the early adopters. So did they reach out to you? Was there kind of like a structure output console in open source that people were talking about or was it just a random?Samuel [00:02:26]: No, very much not. So I originally. Didn't implement JSON schema inside Pydantic and then Sebastian, Sebastian Ramirez, FastAPI came along and like the first I ever heard of him was over a weekend. I got like 50 emails from him or 50 like emails as he was committing to Pydantic, adding JSON schema long pre version one. So the reason it was added was for OpenAPI, which is obviously closely akin to JSON schema. And then, yeah, I don't know why it was JSON that got picked up and used by OpenAI. It was obviously very convenient for us. That's because it meant that not only can you do the validation, but because Pydantic will generate you the JSON schema, it will it kind of can be one source of source of truth for structured outputs and tools.Swyx [00:03:09]: Before we dive in further on the on the AI side of things, something I'm mildly curious about, obviously, there's Zod in JavaScript land. Every now and then there is a new sort of in vogue validation library that that takes over for quite a few years and then maybe like some something else comes along. Is Pydantic? Is it done like the core Pydantic?Samuel [00:03:30]: I've just come off a call where we were redesigning some of the internal bits. There will be a v3 at some point, which will not break people's code half as much as v2 as in v2 was the was the massive rewrite into Rust, but also fixing all the stuff that was broken back from like version zero point something that we didn't fix in v1 because it was a side project. We have plans to move some of the basically store the data in Rust types after validation. Not completely. So we're still working to design the Pythonic version of it, in order for it to be able to convert into Python types. So then if you were doing like validation and then serialization, you would never have to go via a Python type we reckon that can give us somewhere between three and five times another three to five times speed up. That's probably the biggest thing. Also, like changing how easy it is to basically extend Pydantic and define how particular types, like for example, NumPy arrays are validated and serialized. But there's also stuff going on. And for example, Jitter, the JSON library in Rust that does the JSON parsing, has SIMD implementation at the moment only for AMD64. So we can add that. We need to go and add SIMD for other instruction sets. So there's a bunch more we can do on performance. I don't think we're going to go and revolutionize Pydantic, but it's going to continue to get faster, continue, hopefully, to allow people to do more advanced things. We might add a binary format like CBOR for serialization for when you'll just want to put the data into a database and probably load it again from Pydantic. So there are some things that will come along, but for the most part, it should just get faster and cleaner.Alessio [00:05:04]: From a focus perspective, I guess, as a founder too, how did you think about the AI interest rising? And then how do you kind of prioritize, okay, this is worth going into more, and we'll talk about Pydantic AI and all of that. What was maybe your early experience with LLAMP, and when did you figure out, okay, this is something we should take seriously and focus more resources on it?Samuel [00:05:28]: I'll answer that, but I'll answer what I think is a kind of parallel question, which is Pydantic's weird, because Pydantic existed, obviously, before I was starting a company. I was working on it in my spare time, and then beginning of 22, I started working on the rewrite in Rust. And I worked on it full-time for a year and a half, and then once we started the company, people came and joined. And it was a weird project, because that would never go away. You can't get signed off inside a startup. Like, we're going to go off and three engineers are going to work full-on for a year in Python and Rust, writing like 30,000 lines of Rust just to release open-source-free Python library. The result of that has been excellent for us as a company, right? As in, it's made us remain entirely relevant. And it's like, Pydantic is not just used in the SDKs of all of the AI libraries, but I can't say which one, but one of the big foundational model companies, when they upgraded from Pydantic v1 to v2, their number one internal model... The metric of performance is time to first token. That went down by 20%. So you think about all of the actual AI going on inside, and yet at least 20% of the CPU, or at least the latency inside requests was actually Pydantic, which shows like how widely it's used. So we've benefited from doing that work, although it didn't, it would have never have made financial sense in most companies. In answer to your question about like, how do we prioritize AI, I mean, the honest truth is we've spent a lot of the last year and a half building. Good general purpose observability inside LogFire and making Pydantic good for general purpose use cases. And the AI has kind of come to us. Like we just, not that we want to get away from it, but like the appetite, uh, both in Pydantic and in LogFire to go and build with AI is enormous because it kind of makes sense, right? Like if you're starting a new greenfield project in Python today, what's the chance that you're using GenAI 80%, let's say, globally, obviously it's like a hundred percent in California, but even worldwide, it's probably 80%. Yeah. And so everyone needs that stuff. And there's so much yet to be figured out so much like space to do things better in the ecosystem in a way that like to go and implement a database that's better than Postgres is a like Sisyphean task. Whereas building, uh, tools that are better for GenAI than some of the stuff that's about now is not very difficult. Putting the actual models themselves to one side.Alessio [00:07:40]: And then at the same time, then you released Pydantic AI recently, which is, uh, um, you know, agent framework and early on, I would say everybody like, you know, Langchain and like, uh, Pydantic kind of like a first class support, a lot of these frameworks, we're trying to use you to be better. What was the decision behind we should do our own framework? Were there any design decisions that you disagree with any workloads that you think people didn't support? Well,Samuel [00:08:05]: it wasn't so much like design and workflow, although I think there were some, some things we've done differently. Yeah. I think looking in general at the ecosystem of agent frameworks, the engineering quality is far below that of the rest of the Python ecosystem. There's a bunch of stuff that we have learned how to do over the last 20 years of building Python libraries and writing Python code that seems to be abandoned by people when they build agent frameworks. Now I can kind of respect that, particularly in the very first agent frameworks, like Langchain, where they were literally figuring out how to go and do this stuff. It's completely understandable that you would like basically skip some stuff.Samuel [00:08:42]: I'm shocked by the like quality of some of the agent frameworks that have come out recently from like well-respected names, which it just seems to be opportunism and I have little time for that, but like the early ones, like I think they were just figuring out how to do stuff and just as lots of people have learned from Pydantic, we were able to learn a bit from them. I think from like the gap we saw and the thing we were frustrated by was the production readiness. And that means things like type checking, even if type checking makes it hard. Like Pydantic AI, I will put my hand up now and say it has a lot of generics and you need to, it's probably easier to use it if you've written a bit of Rust and you really understand generics, but like, and that is, we're not claiming that that makes it the easiest thing to use in all cases, we think it makes it good for production applications in big systems where type checking is a no-brainer in Python. But there are also a bunch of stuff we've learned from maintaining Pydantic over the years that we've gone and done. So every single example in Pydantic AI's documentation is run on Python. As part of tests and every single print output within an example is checked during tests. So it will always be up to date. And then a bunch of things that, like I say, are standard best practice within the rest of the Python ecosystem, but I'm not followed surprisingly by some AI libraries like coverage, linting, type checking, et cetera, et cetera, where I think these are no-brainers, but like weirdly they're not followed by some of the other libraries.Alessio [00:10:04]: And can you just give an overview of the framework itself? I think there's kind of like the. LLM calling frameworks, there are the multi-agent frameworks, there's the workflow frameworks, like what does Pydantic AI do?Samuel [00:10:17]: I glaze over a bit when I hear all of the different sorts of frameworks, but I like, and I will tell you when I built Pydantic, when I built Logfire and when I built Pydantic AI, my methodology is not to go and like research and review all of the other things. I kind of work out what I want and I go and build it and then feedback comes and we adjust. So the fundamental building block of Pydantic AI is agents. The exact definition of agents and how you want to define them. is obviously ambiguous and our things are probably sort of agent-lit, not that we would want to go and rename them to agent-lit, but like the point is you probably build them together to build something and most people will call an agent. So an agent in our case has, you know, things like a prompt, like system prompt and some tools and a structured return type if you want it, that covers the vast majority of cases. There are situations where you want to go further and the most complex workflows where you want graphs and I resisted graphs for quite a while. I was sort of of the opinion you didn't need them and you could use standard like Python flow control to do all of that stuff. I had a few arguments with people, but I basically came around to, yeah, I can totally see why graphs are useful. But then we have the problem that by default, they're not type safe because if you have a like add edge method where you give the names of two different edges, there's no type checking, right? Even if you go and do some, I'm not, not all the graph libraries are AI specific. So there's a, there's a graph library called, but it allows, it does like a basic runtime type checking. Ironically using Pydantic to try and make up for the fact that like fundamentally that graphs are not typed type safe. Well, I like Pydantic, but it did, that's not a real solution to have to go and run the code to see if it's safe. There's a reason that starting type checking is so powerful. And so we kind of, from a lot of iteration eventually came up with a system of using normally data classes to define nodes where you return the next node you want to call and where we're able to go and introspect the return type of a node to basically build the graph. And so the graph is. Yeah. Inherently type safe. And once we got that right, I, I wasn't, I'm incredibly excited about graphs. I think there's like masses of use cases for them, both in gen AI and other development, but also software's all going to have interact with gen AI, right? It's going to be like web. There's no longer be like a web department in a company is that there's just like all the developers are building for web building with databases. The same is going to be true for gen AI.Alessio [00:12:33]: Yeah. I see on your docs, you call an agent, a container that contains a system prompt function. Tools, structure, result, dependency type model, and then model settings. Are the graphs in your mind, different agents? Are they different prompts for the same agent? What are like the structures in your mind?Samuel [00:12:52]: So we were compelled enough by graphs once we got them right, that we actually merged the PR this morning. That means our agent implementation without changing its API at all is now actually a graph under the hood as it is built using our graph library. So graphs are basically a lower level tool that allow you to build these complex workflows. Our agents are technically one of the many graphs you could go and build. And we just happened to build that one for you because it's a very common, commonplace one. But obviously there are cases where you need more complex workflows where the current agent assumptions don't work. And that's where you can then go and use graphs to build more complex things.Swyx [00:13:29]: You said you were cynical about graphs. What changed your mind specifically?Samuel [00:13:33]: I guess people kept giving me examples of things that they wanted to use graphs for. And my like, yeah, but you could do that in standard flow control in Python became a like less and less compelling argument to me because I've maintained those systems that end up with like spaghetti code. And I could see the appeal of this like structured way of defining the workflow of my code. And it's really neat that like just from your code, just from your type hints, you can get out a mermaid diagram that defines exactly what can go and happen.Swyx [00:14:00]: Right. Yeah. You do have very neat implementation of sort of inferring the graph from type hints, I guess. Yeah. Is what I would call it. Yeah. I think the question always is I have gone back and forth. I used to work at Temporal where we would actually spend a lot of time complaining about graph based workflow solutions like AWS step functions. And we would actually say that we were better because you could use normal control flow that you already knew and worked with. Yours, I guess, is like a little bit of a nice compromise. Like it looks like normal Pythonic code. But you just have to keep in mind what the type hints actually mean. And that's what we do with the quote unquote magic that the graph construction does.Samuel [00:14:42]: Yeah, exactly. And if you look at the internal logic of actually running a graph, it's incredibly simple. It's basically call a node, get a node back, call that node, get a node back, call that node. If you get an end, you're done. We will add in soon support for, well, basically storage so that you can store the state between each node that's run. And then the idea is you can then distribute the graph and run it across computers. And also, I mean, the other weird, the other bit that's really valuable is across time. Because it's all very well if you look at like lots of the graph examples that like Claude will give you. If it gives you an example, it gives you this lovely enormous mermaid chart of like the workflow, for example, managing returns if you're an e-commerce company. But what you realize is some of those lines are literally one function calls another function. And some of those lines are wait six days for the customer to print their like piece of paper and put it in the post. And if you're writing like your demo. Project or your like proof of concept, that's fine because you can just say, and now we call this function. But when you're building when you're in real in real life, that doesn't work. And now how do we manage that concept to basically be able to start somewhere else in the in our code? Well, this graph implementation makes it incredibly easy because you just pass the node that is the start point for carrying on the graph and it continues to run. So it's things like that where I was like, yeah, I can just imagine how things I've done in the past would be fundamentally easier to understand if we had done them with graphs.Swyx [00:16:07]: You say imagine, but like right now, this pedantic AI actually resume, you know, six days later, like you said, or is this just like a theoretical thing we can go someday?Samuel [00:16:16]: I think it's basically Q&A. So there's an AI that's asking the user a question and effectively you then call the CLI again to continue the conversation. And it basically instantiates the node and calls the graph with that node again. Now, we don't have the logic yet for effectively storing state in the database between individual nodes that we're going to add soon. But like the rest of it is basically there.Swyx [00:16:37]: It does make me think that not only are you competing with Langchain now and obviously Instructor, and now you're going into sort of the more like orchestrated things like Airflow, Prefect, Daxter, those guys.Samuel [00:16:52]: Yeah, I mean, we're good friends with the Prefect guys and Temporal have the same investors as us. And I'm sure that my investor Bogomol would not be too happy if I was like, oh, yeah, by the way, as well as trying to take on Datadog. We're also going off and trying to take on Temporal and everyone else doing that. Obviously, we're not doing all of the infrastructure of deploying that right yet, at least. We're, you know, we're just building a Python library. And like what's crazy about our graph implementation is, sure, there's a bit of magic in like introspecting the return type, you know, extracting things from unions, stuff like that. But like the actual calls, as I say, is literally call a function and get back a thing and call that. It's like incredibly simple and therefore easy to maintain. The question is, how useful is it? Well, I don't know yet. I think we have to go and find out. We have a whole. We've had a slew of people joining our Slack over the last few days and saying, tell me how good Pydantic AI is. How good is Pydantic AI versus Langchain? And I refuse to answer. That's your job to go and find that out. Not mine. We built a thing. I'm compelled by it, but I'm obviously biased. The ecosystem will work out what the useful tools are.Swyx [00:17:52]: Bogomol was my board member when I was at Temporal. And I think I think just generally also having been a workflow engine investor and participant in this space, it's a big space. Like everyone needs different functions. I think the one thing that I would say like yours, you know, as a library, you don't have that much control of it over the infrastructure. I do like the idea that each new agents or whatever or unit of work, whatever you call that should spin up in this sort of isolated boundaries. Whereas yours, I think around everything runs in the same process. But you ideally want to sort of spin out its own little container of things.Samuel [00:18:30]: I agree with you a hundred percent. And we will. It would work now. Right. As in theory, you're just like as long as you can serialize the calls to the next node, you just have to all of the different containers basically have to have the same the same code. I mean, I'm super excited about Cloudflare workers running Python and being able to install dependencies. And if Cloudflare could only give me my invitation to the private beta of that, we would be exploring that right now because I'm super excited about that as a like compute level for some of this stuff where exactly what you're saying, basically. You can run everything as an individual. Like worker function and distribute it. And it's resilient to failure, et cetera, et cetera.Swyx [00:19:08]: And it spins up like a thousand instances simultaneously. You know, you want it to be sort of truly serverless at once. Actually, I know we have some Cloudflare friends who are listening, so hopefully they'll get in front of the line. Especially.Samuel [00:19:19]: I was in Cloudflare's office last week shouting at them about other things that frustrate me. I have a love-hate relationship with Cloudflare. Their tech is awesome. But because I use it the whole time, I then get frustrated. So, yeah, I'm sure I will. I will. I will get there soon.Swyx [00:19:32]: There's a side tangent on Cloudflare. Is Python supported at full? I actually wasn't fully aware of what the status of that thing is.Samuel [00:19:39]: Yeah. So Pyodide, which is Python running inside the browser in scripting, is supported now by Cloudflare. They basically, they're having some struggles working out how to manage, ironically, dependencies that have binaries, in particular, Pydantic. Because these workers where you can have thousands of them on a given metal machine, you don't want to have a difference. You basically want to be able to have a share. Shared memory for all the different Pydantic installations, effectively. That's the thing they work out. They're working out. But Hood, who's my friend, who is the primary maintainer of Pyodide, works for Cloudflare. And that's basically what he's doing, is working out how to get Python running on Cloudflare's network.Swyx [00:20:19]: I mean, the nice thing is that your binary is really written in Rust, right? Yeah. Which also compiles the WebAssembly. Yeah. So maybe there's a way that you'd build... You have just a different build of Pydantic and that ships with whatever your distro for Cloudflare workers is.Samuel [00:20:36]: Yes, that's exactly what... So Pyodide has builds for Pydantic Core and for things like NumPy and basically all of the popular binary libraries. Yeah. It's just basic. And you're doing exactly that, right? You're using Rust to compile the WebAssembly and then you're calling that shared library from Python. And it's unbelievably complicated, but it works. Okay.Swyx [00:20:57]: Staying on graphs a little bit more, and then I wanted to go to some of the other features that you have in Pydantic AI. I see in your docs, there are sort of four levels of agents. There's single agents, there's agent delegation, programmatic agent handoff. That seems to be what OpenAI swarms would be like. And then the last one, graph-based control flow. Would you say that those are sort of the mental hierarchy of how these things go?Samuel [00:21:21]: Yeah, roughly. Okay.Swyx [00:21:22]: You had some expression around OpenAI swarms. Well.Samuel [00:21:25]: And indeed, OpenAI have got in touch with me and basically, maybe I'm not supposed to say this, but basically said that Pydantic AI looks like what swarms would become if it was production ready. So, yeah. I mean, like, yeah, which makes sense. Awesome. Yeah. I mean, in fact, it was specifically saying, how can we give people the same feeling that they were getting from swarms that led us to go and implement graphs? Because my, like, just call the next agent with Python code was not a satisfactory answer to people. So it was like, okay, we've got to go and have a better answer for that. It's not like, let us to get to graphs. Yeah.Swyx [00:21:56]: I mean, it's a minimal viable graph in some sense. What are the shapes of graphs that people should know? So the way that I would phrase this is I think Anthropic did a very good public service and also kind of surprisingly influential blog post, I would say, when they wrote Building Effective Agents. We actually have the authors coming to speak at my conference in New York, which I think you're giving a workshop at. Yeah.Samuel [00:22:24]: I'm trying to work it out. But yes, I think so.Swyx [00:22:26]: Tell me if you're not. yeah, I mean, like, that was the first, I think, authoritative view of, like, what kinds of graphs exist in agents and let's give each of them a name so that everyone is on the same page. So I'm just kind of curious if you have community names or top five patterns of graphs.Samuel [00:22:44]: I don't have top five patterns of graphs. I would love to see what people are building with them. But like, it's been it's only been a couple of weeks. And of course, there's a point is that. Because they're relatively unopinionated about what you can go and do with them. They don't suit them. Like, you can go and do lots of lots of things with them, but they don't have the structure to go and have like specific names as much as perhaps like some other systems do. I think what our agents are, which have a name and I can't remember what it is, but this basically system of like, decide what tool to call, go back to the center, decide what tool to call, go back to the center and then exit. One form of graph, which, as I say, like our agents are effectively one implementation of a graph, which is why under the hood they are now using graphs. And it'll be interesting to see over the next few years whether we end up with these like predefined graph names or graph structures or whether it's just like, yep, I built a graph or whether graphs just turn out not to match people's mental image of what they want and die away. We'll see.Swyx [00:23:38]: I think there is always appeal. Every developer eventually gets graph religion and goes, oh, yeah, everything's a graph. And then they probably over rotate and go go too far into graphs. And then they have to learn a whole bunch of DSLs. And then they're like, actually, I didn't need that. I need this. And they scale back a little bit.Samuel [00:23:55]: I'm at the beginning of that process. I'm currently a graph maximalist, although I haven't actually put any into production yet. But yeah.Swyx [00:24:02]: This has a lot of philosophical connections with other work coming out of UC Berkeley on compounding AI systems. I don't know if you know of or care. This is the Gartner world of things where they need some kind of industry terminology to sell it to enterprises. I don't know if you know about any of that.Samuel [00:24:24]: I haven't. I probably should. I should probably do it because I should probably get better at selling to enterprises. But no, no, I don't. Not right now.Swyx [00:24:29]: This is really the argument is that instead of putting everything in one model, you have more control and more maybe observability to if you break everything out into composing little models and changing them together. And obviously, then you need an orchestration framework to do that. Yeah.Samuel [00:24:47]: And it makes complete sense. And one of the things we've seen with agents is they work well when they work well. But when they. Even if you have the observability through log five that you can see what was going on, if you don't have a nice hook point to say, hang on, this is all gone wrong. You have a relatively blunt instrument of basically erroring when you exceed some kind of limit. But like what you need to be able to do is effectively iterate through these runs so that you can have your own control flow where you're like, OK, we've gone too far. And that's where one of the neat things about our graph implementation is you can basically call next in a loop rather than just running the full graph. And therefore, you have this opportunity to to break out of it. But yeah, basically, it's the same point, which is like if you have two bigger unit of work to some extent, whether or not it involves gen AI. But obviously, it's particularly problematic in gen AI. You only find out afterwards when you've spent quite a lot of time and or money when it's gone off and done done the wrong thing.Swyx [00:25:39]: Oh, drop on this. We're not going to resolve this here, but I'll drop this and then we can move on to the next thing. This is the common way that we we developers talk about this. And then the machine learning researchers look at us. And laugh and say, that's cute. And then they just train a bigger model and they wipe us out in the next training run. So I think there's a certain amount of we are fighting the bitter lesson here. We're fighting AGI. And, you know, when AGI arrives, this will all go away. Obviously, on Latent Space, we don't really discuss that because I think AGI is kind of this hand wavy concept that isn't super relevant. But I think we have to respect that. For example, you could do a chain of thoughts with graphs and you could manually orchestrate a nice little graph that does like. Reflect, think about if you need more, more inference time, compute, you know, that's the hot term now. And then think again and, you know, scale that up. Or you could train Strawberry and DeepSeq R1. Right.Samuel [00:26:32]: I saw someone saying recently, oh, they were really optimistic about agents because models are getting faster exponentially. And I like took a certain amount of self-control not to describe that it wasn't exponential. But my main point was. If models are getting faster as quickly as you say they are, then we don't need agents and we don't really need any of these abstraction layers. We can just give our model and, you know, access to the Internet, cross our fingers and hope for the best. Agents, agent frameworks, graphs, all of this stuff is basically making up for the fact that right now the models are not that clever. In the same way that if you're running a customer service business and you have loads of people sitting answering telephones, the less well trained they are, the less that you trust them, the more that you need to give them a script to go through. Whereas, you know, so if you're running a bank and you have lots of customer service people who you don't trust that much, then you tell them exactly what to say. If you're doing high net worth banking, you just employ people who you think are going to be charming to other rich people and set them off to go and have coffee with people. Right. And the same is true of models. The more intelligent they are, the less we need to tell them, like structure what they go and do and constrain the routes in which they take.Swyx [00:27:42]: Yeah. Yeah. Agree with that. So I'm happy to move on. So the other parts of Pydantic AI that are worth commenting on, and this is like my last rant, I promise. So obviously, every framework needs to do its sort of model adapter layer, which is, oh, you can easily swap from OpenAI to Cloud to Grok. You also have, which I didn't know about, Google GLA, which I didn't really know about until I saw this in your docs, which is generative language API. I assume that's AI Studio? Yes.Samuel [00:28:13]: Google don't have good names for it. So Vertex is very clear. That seems to be the API that like some of the things use, although it returns 503 about 20% of the time. So... Vertex? No. Vertex, fine. But the... Oh, oh. GLA. Yeah. Yeah.Swyx [00:28:28]: I agree with that.Samuel [00:28:29]: So we have, again, another example of like, well, I think we go the extra mile in terms of engineering is we run on every commit, at least commit to main, we run tests against the live models. Not lots of tests, but like a handful of them. Oh, okay. And we had a point last week where, yeah, GLA is a little bit better. GLA1 was failing every single run. One of their tests would fail. And we, I think we might even have commented out that one at the moment. So like all of the models fail more often than you might expect, but like that one seems to be particularly likely to fail. But Vertex is the same API, but much more reliable.Swyx [00:29:01]: My rant here is that, you know, versions of this appear in Langchain and every single framework has to have its own little thing, a version of that. I would put to you, and then, you know, this is, this can be agree to disagree. This is not needed in Pydantic AI. I would much rather you adopt a layer like Lite LLM or what's the other one in JavaScript port key. And that's their job. They focus on that one thing and they, they normalize APIs for you. All new models are automatically added and you don't have to duplicate this inside of your framework. So for example, if I wanted to use deep seek, I'm out of luck because Pydantic AI doesn't have deep seek yet.Samuel [00:29:38]: Yeah, it does.Swyx [00:29:39]: Oh, it does. Okay. I'm sorry. But you know what I mean? Should this live in your code or should it live in a layer that's kind of your API gateway that's a defined piece of infrastructure that people have?Samuel [00:29:49]: And I think if a company who are well known, who are respected by everyone had come along and done this at the right time, maybe we should have done it a year and a half ago and said, we're going to be the universal AI layer. That would have been a credible thing to do. I've heard varying reports of Lite LLM is the truth. And it didn't seem to have exactly the type safety that we needed. Also, as I understand it, and again, I haven't looked into it in great detail. Part of their business model is proxying the request through their, through their own system to do the generalization. That would be an enormous put off to an awful lot of people. Honestly, the truth is I don't think it is that much work unifying the model. I get where you're coming from. I kind of see your point. I think the truth is that everyone is centralizing around open AIs. Open AI's API is the one to do. So DeepSeq support that. Grok with OK support that. Ollama also does it. I mean, if there is that library right now, it's more or less the open AI SDK. And it's very high quality. It's well type checked. It uses Pydantic. So I'm biased. But I mean, I think it's pretty well respected anyway.Swyx [00:30:57]: There's different ways to do this. Because also, it's not just about normalizing the APIs. You have to do secret management and all that stuff.Samuel [00:31:05]: Yeah. And there's also. There's Vertex and Bedrock, which to one extent or another, effectively, they host multiple models, but they don't unify the API. But they do unify the auth, as I understand it. Although we're halfway through doing Bedrock. So I don't know about it that well. But they're kind of weird hybrids because they support multiple models. But like I say, the auth is centralized.Swyx [00:31:28]: Yeah, I'm surprised they don't unify the API. That seems like something that I would do. You know, we can discuss all this all day. There's a lot of APIs. I agree.Samuel [00:31:36]: It would be nice if there was a universal one that we didn't have to go and build.Alessio [00:31:39]: And I guess the other side of, you know, routing model and picking models like evals. How do you actually figure out which one you should be using? I know you have one. First of all, you have very good support for mocking in unit tests, which is something that a lot of other frameworks don't do. So, you know, my favorite Ruby library is VCR because it just, you know, it just lets me store the HTTP requests and replay them. That part I'll kind of skip. I think you are busy like this test model. We're like just through Python. You try and figure out what the model might respond without actually calling the model. And then you have the function model where people can kind of customize outputs. Any other fun stories maybe from there? Or is it just what you see is what you get, so to speak?Samuel [00:32:18]: On those two, I think what you see is what you get. On the evals, I think watch this space. I think it's something that like, again, I was somewhat cynical about for some time. Still have my cynicism about some of the well, it's unfortunate that so many different things are called evals. It would be nice if we could agree. What they are and what they're not. But look, I think it's a really important space. I think it's something that we're going to be working on soon, both in Pydantic AI and in LogFire to try and support better because it's like it's an unsolved problem.Alessio [00:32:45]: Yeah, you do say in your doc that anyone who claims to know for sure exactly how your eval should be defined can safely be ignored.Samuel [00:32:52]: We'll delete that sentence when we tell people how to do their evals.Alessio [00:32:56]: Exactly. I was like, we need we need a snapshot of this today. And so let's talk about eval. So there's kind of like the vibe. Yeah. So you have evals, which is what you do when you're building. Right. Because you cannot really like test it that many times to get statistical significance. And then there's the production eval. So you also have LogFire, which is kind of like your observability product, which I tried before. It's very nice. What are some of the learnings you've had from building an observability tool for LEMPs? And yeah, as people think about evals, even like what are the right things to measure? What are like the right number of samples that you need to actually start making decisions?Samuel [00:33:33]: I'm not the best person to answer that is the truth. So I'm not going to come in here and tell you that I think I know the answer on the exact number. I mean, we can do some back of the envelope statistics calculations to work out that like having 30 probably gets you most of the statistical value of having 200 for, you know, by definition, 15% of the work. But the exact like how many examples do you need? For example, that's a much harder question to answer because it's, you know, it's deep within the how models operate in terms of LogFire. One of the reasons we built LogFire the way we have and we allow you to write SQL directly against your data and we're trying to build the like powerful fundamentals of observability is precisely because we know we don't know the answers. And so allowing people to go and innovate on how they're going to consume that stuff and how they're going to process it is we think that's valuable. Because even if we come along and offer you an evals framework on top of LogFire, it won't be right in all regards. And we want people to be able to go and innovate and being able to write their own SQL connected to the API. And effectively query the data like it's a database with SQL allows people to innovate on that stuff. And that's what allows us to do it as well. I mean, we do a bunch of like testing what's possible by basically writing SQL directly against LogFire as any user could. I think the other the other really interesting bit that's going on in observability is OpenTelemetry is centralizing around semantic attributes for GenAI. So it's a relatively new project. A lot of it's still being added at the moment. But basically the idea that like. They unify how both SDKs and or agent frameworks send observability data to to any OpenTelemetry endpoint. And so, again, we can go and having that unification allows us to go and like basically compare different libraries, compare different models much better. That stuff's in a very like early stage of development. One of the things we're going to be working on pretty soon is basically, I suspect, GenAI will be the first agent framework that implements those semantic attributes properly. Because, again, we control and we can say this is important for observability, whereas most of the other agent frameworks are not maintained by people who are trying to do observability. With the exception of Langchain, where they have the observability platform, but they chose not to go down the OpenTelemetry route. So they're like plowing their own furrow. And, you know, they're a lot they're even further away from standardization.Alessio [00:35:51]: Can you maybe just give a quick overview of how OTEL ties into the AI workflows? There's kind of like the question of is, you know, a trace. And a span like a LLM call. Is it the agent? It's kind of like the broader thing you're tracking. How should people think about it?Samuel [00:36:06]: Yeah, so they have a PR that I think may have now been merged from someone at IBM talking about remote agents and trying to support this concept of remote agents within GenAI. I'm not particularly compelled by that because I don't think that like that's actually by any means the common use case. But like, I suppose it's fine for it to be there. The majority of the stuff in OTEL is basically defining how you would instrument. A given call to an LLM. So basically the actual LLM call, what data you would send to your telemetry provider, how you would structure that. Apart from this slightly odd stuff on remote agents, most of the like agent level consideration is not yet implemented in is not yet decided effectively. And so there's a bit of ambiguity. Obviously, what's good about OTEL is you can in the end send whatever attributes you like. But yeah, there's quite a lot of churn in that space and exactly how we store the data. I think that one of the most interesting things, though, is that if you think about observability. Traditionally, it was sure everyone would say our observability data is very important. We must keep it safe. But actually, companies work very hard to basically not have anything that sensitive in their observability data. So if you're a doctor in a hospital and you search for a drug for an STI, the sequel might be sent to the observability provider. But none of the parameters would. It wouldn't have the patient number or their name or the drug. With GenAI, that distinction doesn't exist because it's all just messed up in the text. If you have that same patient asking an LLM how to. What drug they should take or how to stop smoking. You can't extract the PII and not send it to the observability platform. So the sensitivity of the data that's going to end up in observability platforms is going to be like basically different order of magnitude to what's in what you would normally send to Datadog. Of course, you can make a mistake and send someone's password or their card number to Datadog. But that would be seen as a as a like mistake. Whereas in GenAI, a lot of data is going to be sent. And I think that's why companies like Langsmith and are trying hard to offer observability. On prem, because there's a bunch of companies who are happy for Datadog to be cloud hosted, but want self-hosted self-hosting for this observability stuff with GenAI.Alessio [00:38:09]: And are you doing any of that today? Because I know in each of the spans you have like the number of tokens, you have the context, you're just storing everything. And then you're going to offer kind of like a self-hosting for the platform, basically. Yeah. Yeah.Samuel [00:38:23]: So we have scrubbing roughly equivalent to what the other observability platforms have. So if we, you know, if we see password as the key, we won't send the value. But like, like I said, that doesn't really work in GenAI. So we're accepting we're going to have to store a lot of data and then we'll offer self-hosting for those people who can afford it and who need it.Alessio [00:38:42]: And then this is, I think, the first time that most of the workloads performance is depending on a third party. You know, like if you're looking at Datadog data, usually it's your app that is driving the latency and like the memory usage and all of that. Here you're going to have spans that maybe take a long time to perform because the GLA API is not working or because OpenAI is kind of like overwhelmed. Do you do anything there since like the provider is almost like the same across customers? You know, like, are you trying to surface these things for people and say, hey, this was like a very slow span, but actually all customers using OpenAI right now are seeing the same thing. So maybe don't worry about it or.Samuel [00:39:20]: Not yet. We do a few things that people don't generally do in OTA. So we send. We send information at the beginning. At the beginning of a trace as well as sorry, at the beginning of a span, as well as when it finishes. By default, OTA only sends you data when the span finishes. So if you think about a request which might take like 20 seconds, even if some of the intermediate spans finished earlier, you can't basically place them on the page until you get the top level span. And so if you're using standard OTA, you can't show anything until those requests are finished. When those requests are taking a few hundred milliseconds, it doesn't really matter. But when you're doing Gen AI calls or when you're like running a batch job that might take 30 minutes. That like latency of not being able to see the span is like crippling to understanding your application. And so we've we do a bunch of slightly complex stuff to basically send data about a span as it starts, which is closely related. Yeah.Alessio [00:40:09]: Any thoughts on all the other people trying to build on top of OpenTelemetry in different languages, too? There's like the OpenLEmetry project, which doesn't really roll off the tongue. But how do you see the future of these kind of tools? Is everybody going to have to build? Why does everybody want to build? They want to build their own open source observability thing to then sell?Samuel [00:40:29]: I mean, we are not going off and trying to instrument the likes of the OpenAI SDK with the new semantic attributes, because at some point that's going to happen and it's going to live inside OTEL and we might help with it. But we're a tiny team. We don't have time to go and do all of that work. So OpenLEmetry, like interesting project. But I suspect eventually most of those semantic like that instrumentation of the big of the SDKs will live, like I say, inside the main OpenTelemetry report. I suppose. What happens to the agent frameworks? What data you basically need at the framework level to get the context is kind of unclear. I don't think we know the answer yet. But I mean, I was on the, I guess this is kind of semi-public, because I was on the call with the OpenTelemetry call last week talking about GenAI. And there was someone from Arize talking about the challenges they have trying to get OpenTelemetry data out of Langchain, where it's not like natively implemented. And obviously they're having quite a tough time. And I was realizing, hadn't really realized this before, but how lucky we are to primarily be talking about our own agent framework, where we have the control rather than trying to go and instrument other people's.Swyx [00:41:36]: Sorry, I actually didn't know about this semantic conventions thing. It looks like, yeah, it's merged into main OTel. What should people know about this? I had never heard of it before.Samuel [00:41:45]: Yeah, I think it looks like a great start. I think there's some unknowns around how you send the messages that go back and forth, which is kind of the most important part. It's the most important thing of all. And that is moved out of attributes and into OTel events. OTel events in turn are moving from being on a span to being their own top-level API where you send data. So there's a bunch of churn still going on. I'm impressed by how fast the OTel community is moving on this project. I guess they, like everyone else, get that this is important, and it's something that people are crying out to get instrumentation off. So I'm kind of pleasantly surprised at how fast they're moving, but it makes sense.Swyx [00:42:25]: I'm just kind of browsing through the specification. I can already see that this basically bakes in whatever the previous paradigm was. So now they have genai.usage.prompt tokens and genai.usage.completion tokens. And obviously now we have reasoning tokens as well. And then only one form of sampling, which is top-p. You're basically baking in or sort of reifying things that you think are important today, but it's not a super foolproof way of doing this for the future. Yeah.Samuel [00:42:54]: I mean, that's what's neat about OTel is you can always go and send another attribute and that's fine. It's just there are a bunch that are agreed on. But I would say, you know, to come back to your previous point about whether or not we should be relying on one centralized abstraction layer, this stuff is moving so fast that if you start relying on someone else's standard, you risk basically falling behind because you're relying on someone else to keep things up to date.Swyx [00:43:14]: Or you fall behind because you've got other things going on.Samuel [00:43:17]: Yeah, yeah. That's fair. That's fair.Swyx [00:43:19]: Any other observations just about building LogFire, actually? Let's just talk about this. So you announced LogFire. I was kind of only familiar with LogFire because of your Series A announcement. I actually thought you were making a separate company. I remember some amount of confusion with you when that came out. So to be clear, it's Pydantic LogFire and the company is one company that has kind of two products, an open source thing and an observability thing, correct? Yeah. I was just kind of curious, like any learnings building LogFire? So classic question is, do you use ClickHouse? Is this like the standard persistence layer? Any learnings doing that?Samuel [00:43:54]: We don't use ClickHouse. We started building our database with ClickHouse, moved off ClickHouse onto Timescale, which is a Postgres extension to do analytical databases. Wow. And then moved off Timescale onto DataFusion. And we're basically now building, it's DataFusion, but it's kind of our own database. Bogomil is not entirely happy that we went through three databases before we chose one. I'll say that. But like, we've got to the right one in the end. I think we could have realized that Timescale wasn't right. I think ClickHouse. They both taught us a lot and we're in a great place now. But like, yeah, it's been a real journey on the database in particular.Swyx [00:44:28]: Okay. So, you know, as a database nerd, I have to like double click on this, right? So ClickHouse is supposed to be the ideal backend for anything like this. And then moving from ClickHouse to Timescale is another counterintuitive move that I didn't expect because, you know, Timescale is like an extension on top of Postgres. Not super meant for like high volume logging. But like, yeah, tell us those decisions.Samuel [00:44:50]: So at the time, ClickHouse did not have good support for JSON. I was speaking to someone yesterday and said ClickHouse doesn't have good support for JSON and got roundly stepped on because apparently it does now. So they've obviously gone and built their proper JSON support. But like back when we were trying to use it, I guess a year ago or a bit more than a year ago, everything happened to be a map and maps are a pain to try and do like looking up JSON type data. And obviously all these attributes, everything you're talking about there in terms of the GenAI stuff. You can choose to make them top level columns if you want. But the simplest thing is just to put them all into a big JSON pile. And that was a problem with ClickHouse. Also, ClickHouse had some really ugly edge cases like by default, or at least until I complained about it a lot, ClickHouse thought that two nanoseconds was longer than one second because they compared intervals just by the number, not the unit. And I complained about that a lot. And then they caused it to raise an error and just say you have to have the same unit. Then I complained a bit more. And I think as I understand it now, they have some. They convert between units. But like stuff like that, when all you're looking at is when a lot of what you're doing is comparing the duration of spans was really painful. Also things like you can't subtract two date times to get an interval. You have to use the date sub function. But like the fundamental thing is because we want our end users to write SQL, the like quality of the SQL, how easy it is to write, matters way more to us than if you're building like a platform on top where your developers are going to write the SQL. And once it's written and it's working, you don't mind too much. So I think that's like one of the fundamental differences. The other problem that I have with the ClickHouse and Impact Timescale is that like the ultimate architecture, the like snowflake architecture of binary data in object store queried with some kind of cache from nearby. They both have it, but it's closed sourced and you only get it if you go and use their hosted versions. And so even if we had got through all the problems with Timescale or ClickHouse, we would end up like, you know, they would want to be taking their 80% margin. And then we would be wanting to take that would basically leave us less space for margin. Whereas data fusion. Properly open source, all of that same tooling is open source. And for us as a team of people with a lot of Rust expertise, data fusion, which is implemented in Rust, we can literally dive into it and go and change it. So, for example, I found that there were some slowdowns in data fusion's string comparison kernel for doing like string contains. And it's just Rust code. And I could go and rewrite the string comparison kernel to be faster. Or, for example, data fusion, when we started using it, didn't have JSON support. Obviously, as I've said, it's something we can do. It's something we needed. I was able to go and implement that in a weekend using our JSON parser that we built for Pydantic Core. So it's the fact that like data fusion is like for us the perfect mixture of a toolbox to build a database with, not a database. And we can go and implement stuff on top of it in a way that like if you were trying to do that in Postgres or in ClickHouse. I mean, ClickHouse would be easier because it's C++, relatively modern C++. But like as a team of people who are not C++ experts, that's much scarier than data fusion for us.Swyx [00:47:47]: Yeah, that's a beautiful rant.Alessio [00:47:49]: That's funny. Most people don't think they have agency on these projects. They're kind of like, oh, I should use this or I should use that. They're not really like, what should I pick so that I contribute the most back to it? You know, so but I think you obviously have an open source first mindset. So that makes a lot of sense.Samuel [00:48:05]: I think if we were probably better as a startup, a better startup and faster moving and just like headlong determined to get in front of customers as fast as possible, we should have just started with ClickHouse. I hope that long term we're in a better place for having worked with data fusion. We like we're quite engaged now with the data fusion community. Andrew Lam, who maintains data fusion, is an advisor to us. We're in a really good place now. But yeah, it's definitely slowed us down relative to just like building on ClickHouse and moving as fast as we can.Swyx [00:48:34]: OK, we're about to zoom out and do Pydantic run and all the other stuff. But, you know, my last question on LogFire is really, you know, at some point you run out sort of community goodwill just because like, oh, I use Pydantic. I love Pydantic. I'm going to use LogFire. OK, then you start entering the territory of the Datadogs, the Sentrys and the honeycombs. Yeah. So where are you going to really spike here? What differentiator here?Samuel [00:48:59]: I wasn't writing code in 2001, but I'm assuming that there were people talking about like web observability and then web observability stopped being a thing, not because the web stopped being a thing, but because all observability had to do web. If you were talking to people in 2010 or 2012, they would have talked about cloud observability. Now that's not a term because all observability is cloud first. The same is going to happen to gen AI. And so whether or not you're trying to compete with Datadog or with Arise and Langsmith, you've got to do first class. You've got to do general purpose observability with first class support for AI. And as far as I know, we're the only people really trying to do that. I mean, I think Datadog is starting in that direction. And to be honest, I think Datadog is a much like scarier company to compete with than the AI specific observability platforms. Because in my opinion, and I've also heard this from lots of customers, AI specific observability where you don't see everything else going on in your app is not actually that useful. Our hope is that we can build the first general purpose observability platform with first class support for AI. And that we have this open source heritage of putting developer experience first that other companies haven't done. For all I'm a fan of Datadog and what they've done. If you search Datadog logging Python. And you just try as a like a non-observability expert to get something up and running with Datadog and Python. It's not trivial, right? That's something Sentry have done amazingly well. But like there's enormous space in most of observability to do DX better.Alessio [00:50:27]: Since you mentioned Sentry, I'm curious how you thought about licensing and all of that. Obviously, your MIT license, you don't have any rolling license like Sentry has where you can only use an open source, like the one year old version of it. Was that a hard decision?Samuel [00:50:41]: So to be clear, LogFire is co-sourced. So Pydantic and Pydantic AI are MIT licensed and like properly open source. And then LogFire for now is completely closed source. And in fact, the struggles that Sentry have had with licensing and the like weird pushback the community gives when they take something that's closed source and make it source available just meant that we just avoided that whole subject matter. I think the other way to look at it is like in terms of either headcount or revenue or dollars in the bank. The amount of open source we do as a company is we've got to be open source. We're up there with the most prolific open source companies, like I say, per head. And so we didn't feel like we were morally obligated to make LogFire open source. We have Pydantic. Pydantic is a foundational library in Python. That and now Pydantic AI are our contribution to open source. And then LogFire is like openly for profit, right? As in we're not claiming otherwise. We're not sort of trying to walk a line if it's open source. But really, we want to make it hard to deploy. So you probably want to pay us. We're trying to be straight. That it's to pay for. We could change that at some point in the future, but it's not an immediate plan.Alessio [00:51:48]: All right. So the first one I saw this new I don't know if it's like a product you're building the Pydantic that run, which is a Python browser sandbox. What was the inspiration behind that? We talk a lot about code interpreter for lamps. I'm an investor in a company called E2B, which is a code sandbox as a service for remote execution. Yeah. What's the Pydantic that run story?Samuel [00:52:09]: So Pydantic that run is again completely open source. I have no interest in making it into a product. We just needed a sandbox to be able to demo LogFire in particular, but also Pydantic AI. So it doesn't have it yet, but I'm going to add basically a proxy to OpenAI and the other models so that you can run Pydantic AI in the browser. See how it works. Tweak the prompt, et cetera, et cetera. And we'll have some kind of limit per day of what you can spend on it or like what the spend is. The other thing we wanted to be able to do was to be able to when you log into LogFire. We have quite a lot of drop off of like a lot of people sign up, find it interesting and then don't go and create a project. And my intuition is that they're like, oh, OK, cool. But now I have to go and open up my development environment, create a new project, do something with the right token. I can't be bothered. And then they drop off and they forget to come back. And so we wanted a really nice way of being able to click here and you can run it in the browser and see what it does. As I think happens to all of us, I sort of started seeing if I could do it a week and a half ago. Got something to run. And then ended up, you know, improving it. And suddenly I spent a week on it. But I think it's useful. Yeah.Alessio [00:53:15]: I remember maybe a couple, two, three years ago, there were a couple of companies trying to build in the browser terminals exactly for this. It's like, you know, you go on GitHub, you see a project that is interesting, but now you got to like clone it and run it on your machine. Sometimes it can be sketchy. This is cool, especially since you already make all the docs runnable in your docs. Like you said, you kind of test them. It sounds like you might just have.Samuel [00:53:39]: So, yeah. The thing is that on every example in Pydantic AI, there's a button that basically says run, which takes you into Pydantic.run, has that code there. And depending on how hard we want to push, we can also have it like hooked up to LogFire automatically. So there's a like, hey, just come and join the project. And you can see what that looks like in LogFire.Swyx [00:53:58]: That's super cool.Alessio [00:53:59]: So I think that's one of the biggest personally for me, one of the biggest drop offs from open source projects. It's kind of like do this. And then as long as something as soon as something doesn't work, I just drop off.Swyx [00:54:09]: So it takes some discipline. You know, like there's been very many versions of this that I've been through in my career where you had to extract this code and run it. And it always falls out of date. Often we would have these this concept of transclusion where we have a separate code examples repo that we want to be that and that we pulled into our docs. And it never never really works. It takes a lot of discipline. So kudos to you on this.Samuel [00:54:31]: And it was it was years of maintaining Pydantic and people complaining, hey, that example is out of date now. But eventually we went and built a PyTest example. Which is another the hardest to search for open source project we ever built. Because obviously, as you can imagine, if you search PyTest examples, you get examples of how to use PyTest. But the PyTest examples will basically go through both your code inside your doc strings to look for Python code and through markdown in your docs and extract that code and then run it for you and run linting over it and soon run type checking over it. So and that's how we keep our examples up to date. But now now we have these like hundreds of examples. All of which are runnable and self-contained. Or if they if they refer to the previous example, it's already structured that they have to be able to import the code from the previous example. So why don't we give someone a nice place to just be able to actually run that using OpenAI and see what the output is. Lovely.Alessio [00:55:24]: All right. So that's kind of Pydantic. And the notes here, I just like going through people's X account, not Twitter. So for four years, you've been saying we need a plain text accessor to Jupyter notebooks. Yeah. I think people maybe have gone the other way, which may get even more opinionated, like with X and like all these kind of like notebook companies.Samuel [00:55:46]: Well, yes. So in reply to that, someone replied and said Marimo is that. And sure enough, Marimo is really impressive. And I've subsequently spoken to spoken to the Marimo guys and got to angel invest in their account. I think it's SeedGround. So like Marimo is very cool. It's doing that. And Marimo also notebooks also run in the browser again using Pyodide. In fact, I nearly got there. We didn't build Pydantic.run because we were just going to use Marimo. But my concern was that people would think LogFire was only to be used in notebooks. And I wanted something that like ironically felt more basic, felt more like a terminal so that no one thought it was like just for notebooks. Yeah.Swyx [00:56:22]: There's a lot of notebook haters out there.Samuel [00:56:24]: And indeed, I have very strong opinions about, you know, proper like Jupyter notebooks. This idea that like you have to run the cells in the right order. I mean, a whole bunch of things. It's basically like worse than Excel or similar. Similarly bad to Excel. Oh, so you are a notebook hater that invested in a notebook. I have this rant called notebook, which was like my attempt to build an alternative that is mostly just a rant about the 10 reasons why notebooks are just as bad as Excel. But Marimo et al, the new ones that are text-based, at least solve a whole bunch of those problems.Swyx [00:56:58]: Agree with that. Yes. I was kind of wishing for something like a better notebook. And then I saw Marimo. I was like, oh, yeah, these guys have are ahead of me on this. Yeah. I don't know if I would do the sort of annotation-based thing. Like, you know, a lot of people love the, oh, annotate this function. And it just adds magic. I think similarly to what Jeremy Howard does with his stuff. It seems a little bit too magical still. But hey, it's a big improvement from notebooks. Yeah.Samuel [00:57:23]: Yeah. Great.Alessio [00:57:24]: Just as on the LLM usage, like the IPyMB file, it's just not good to put in LLMs. So just that alone, I think should be okay.Swyx [00:57:36]: It's just not good to put in LLMs.Alessio [00:57:38]: It's really not. They freak out.Samuel [00:57:41]: It's not good to put in Git either. I mean, I freak out.Swyx [00:57:44]: Okay. Well, we will kill IPyMB at some point. Yeah. Any other takes? I was going to ask you just like, broaden out just about the London scene. You know, what's it like building out there, you know, over the pond?Samuel [00:57:56]: I'm an evening person. And the good thing is that I can get up late and then work late because I'm speaking to people in the U.S. a lot of the time. So I got invited just earlier today to some drinks reception.Samuel [00:58:09]: So I'm feeling positive about the U.K. right now on AI. But I think, look, like everywhere that isn't the U.S. and China knows that we're like way behind on AI. I think it's good that the U.K. is like beginning to say, this is an opportunity, not just a risk. I keep being told you should be at more events. You should be like, you know, hanging out with AI people more. My instinct is like, I'd rather sit at my computer and write code. I think that like, is probably a more effective way of getting people's attention. I'm like, I don't know. I mean, like a bit of me thinks I should be sitting on Twitter, not in San Francisco chatting to people. I think it's probably a bit of a mixture and I could probably do with being in the States a bit more. I think I'm going to be over there a bit more this year. But like, there's definitely the risk if you're in somewhere where everyone wants to chat to you about code where you don't write any code. And that's a failure mode.Swyx [00:58:58]: I would say, yeah, definitely for sure. There's a scene and, you know, one way to really fail at this is to just be involved in that scene. And have that eat up your time, but be at the right events and the ones that I'm running are good events, hopefully.Swyx [00:59:16]: What I say is like, use those things to produce high quality content that travels in a different medium than you normally would be able to. Because there's some selectivity, because there's a broad, there's a focused community on that thing. They will discover your work more. It will be highly produced, you know, that's the pitch over there on why at least I do conferences. And then in terms of talking to people, I always think about this, a three strikes rule. So after a while it gets repetitive, but maybe like the first 10, 20 conversations you have about people, if the same stuff is coming up, that is an indication to you that people like want a thing and it helps you prioritize in a more long form way than you can get in shallow interactions online, right? So that in person, eye to eye, like this is my pain at work and you see the pain and you're like, oh, okay. Like if I do this for you. You will love our tool and like, you can't really replace that. It's customer interviews. Really. Yeah.Samuel [01:00:11]: I agree entirely with that. I think that I think there's a, you're, you're right on a lot of that. And I think that like, it's very easy to get distracted by what people are saying on Twitter and LinkedIn.Swyx [01:00:19]: That's another thing.Samuel [01:00:20]: It's pretty hard to correct for which of those people are actually building this stuff in production in like serious companies and which of them are on day four of learning to code. Cause they have equally strident opinions and in like few characters, they, they seem equally valid. But which one's real and which one's not, or which one is from someone who really knows their stuff is, is hard to know.Alessio [01:00:40]: Anything else, Sam? What do you want to get off your chest?Samuel [01:00:43]: Nothing in particular. I think we, I've really enjoyed our conversation. I would say, I think if anyone who is like looked at, at Pydance AI, we know it's not complete yet. We know there's a bunch of things that are missing embeddings, like storage, MCP and tool sets and stuff like that. We're trying to be deliberate and do stuff well. And that involves not being feature complete yet. Like keep coming back and looking in a few months because we're, we're pretty determined to get that. We know that this stuff is like, whether or not you think that AI is going to be the next Excel, the next internet or the next industrial revolution is going to affect all of us enormously. And so as a company, we get that like making Pydantic AI the best agent framework is existential for us.Alessio [01:01:22]: You're also the first series A company I see that has no open roles for now. Every founder that comes in our podcast, the call to action is like, please come work with us.Samuel [01:01:31]: We are not hiring right now. I want to, I would love, uh, bluntly for Logfire to have a bit more commercial traction and a bit more revenue before I, before I hire some more people. It's quite nice having a few years of runway, not a few months of runway. So I'm not in any, any great appetite to go and like destroy that runway overnight by hiring another, another 10 people. Even if like we, the whole team is like rushed off their feet, kind of doing, as you said, like three to four startups at the same time.Alessio [01:01:58]: Awesome, man. Thank you for joining us.Samuel [01:01:59]: Thank you very much. Get full access to Latent.Space at www.latent.space/subscribe
-
 The Agent Reasoning Interface: o1/o3, Claude 3, ChatGPT Canvas, Tasks, and Operator — with Karina Nguyen of OpenAI
The Agent Reasoning Interface: o1/o3, Claude 3, ChatGPT Canvas, Tasks, and Operator — with Karina Nguyen of OpenAIFrom 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2025-02-01 01:43
Sponsorships and tickets for the AI Engineer Summit are selling fast! See the new website with speakers and schedules live! If you are building AI agents or leading teams of AI Engineers, this will be the single highest-signal conference of the year for you, this Feb 20-22nd in NYC.We’re pleased to share that Karina will be presenting OpenAI’s closing keynote at the AI Engineer Summit. We were fortunate to get some time with her today to introduce some of her work, and hope this serves as nice background for her talk!There are very few early AI careers that have been as impactful as Karina Nguyen’s. After stints at Notion, Square, Dropbox, Primer, the New York Times, and UC Berkeley, She joined Anthropic as employee ~60 and worked on a wide range of research/product roles for Claude 1, 2, and 3. We’ll just let her LinkedIn speak for itself:Now, as Research manager and Post-training lead in Model Behavior at OpenAI, she creates new interaction paradigms for reasoning interfaces and capabilities, like ChatGPT Canvas, Tasks, SimpleQA, streaming chain-of-thought for o1 models, and more via novel synthetic model training. Ideal AI Research+Product ProcessIn the podcast we got a sense of what Karina has found works for her and her team to be as productive as they have been:* Write PRD (Define what you want)* Funding (Get resources)* Prototype Prompted Baseline (See what’s possible)* Write and Run Evals (Get failures to hillclimb)* Model training (Exceed baseline without overfitting)* Bugbash (Find bugs and solve them)* Ship (Get users!)We could turn this into a snazzy viral graphic but really this is all it is. Simple to say, difficult to do well. Hopefully it helps you define your process if you do similar product-research work. Show Notes* Our Reasoning Price War post * Karina LinkedIn, Website, Twitter* OSINT visualization work* Ukraine 3D storytelling* Karina on Claude Artifacts* Karina on Claude 3 Benchmarks* Inspiration for Artifacts / Canvas from early UX work she did on GPT-3* “i really believe that things like canvas and tasks should and could have happened like 2 yrs ago, idk why we are lagging in the form factors” (tweet)* Our article on prompting o1 vs Karina’s Claude prompting principles* Canvas: https://openai.com/index/introducing-canvas/ * We trained GPT-4o to collaborate as a creative partner. The model knows when to open a canvas, make targeted edits, and fully rewrite. It also understands broader context to provide precise feedback and suggestions.To support this, our research team developed the following core behaviors:* Triggering the canvas for writing and coding* Generating diverse content types* Making targeted edits* Rewriting documents* Providing inline critiqueWe measured progress with over 20 automated internal evaluations. We used novel synthetic data generation techniques, such as distilling outputs from OpenAI o1-preview, to post-train the model for its core behaviors. This approach allowed us to rapidly address writing quality and new user interactions, all without relying on human-generated data.* Tasks: https://www.theverge.com/2025/1/14/24343528/openai-chatgpt-repeating-tasks-agent-ai* * Agents and Operator* What are agents? “Agents are a gradual progression of tasks: starting with one-off actions, moving to collaboration, and ultimately fully trustworthy long-horizon delegation in complex envs like multi-player/multiagents.” (tweet)* tasks and canvas fall within the first two, and we are def. marching towards the third—though the form factor for 3 will take time to develop * Operator/Computer Use Agents* https://openai.com/index/introducing-operator/* Misc:* Andrew Ng* Prediction: Personal AI Consumer playbook* ChatGPT as generative OSTimestamps* 00:00 Welcome to the Latent Space Podcast* 00:11 Introducing Karina Nguyen* 02:21 Karina's Journey to OpenAI* 04:45 Early Prototypes and Projects* 05:25 Joining Anthropic and Early Work* 07:16 Challenges and Innovations at Anthropic* 11:30 Launching Claude 3* 21:57 Behavioral Design and Model Personality* 27:37 The Making of ChatGPT Canvas* 34:34 Canvas Update and Initial Impressions* 34:46 Differences Between Canvas and API Outputs* 35:50 Core Use Cases of Canvas* 36:35 Canvas as a Writing Partner* 36:55 Canvas vs. Google Docs and Future Improvements* 37:35 Canvas for Coding and Executing Code* 38:50 Challenges in Developing Canvas* 41:45 Introduction to Tasks* 41:53 Developing and Iterating on Tasks* 46:27 Future Vision for Tasks and Proactive Models* 52:23 Computer Use Agents and Their Potential* 01:00:21 Cultural Differences Between OpenAI and Anthropic* 01:03:46 Call to Action and Final ThoughtsTranscriptAlessio [00:00:04]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel, and I'm joined by my usual co-host, Swyx.swyx [00:00:11]: Hey, and today we're very, very blessed to have Karina Nguyen in the studio. Welcome.Karina [00:00:15]: Nice to meet you.swyx [00:00:16]: We finally made it happen. We finally made it happen. First time we tried this, you were working at a different company, and now we're here. Fortunately, you had some time, so thank you so much for joining us. Yeah, thank you for inviting me. Karina, your website says you lead a research team in OpenAI, creating new interaction paradigms for reasoning interfaces and capabilities like ChatGPT Canvas, and most recently, ChatGPT TAS. I don't know, is that what we're calling it? Streaming chain of thought for O1 models and more via novel synthetic model training. What is this research team?Karina [00:00:45]: Yeah, I need to clarify this a little bit more. I think it changed a lot since the last time we launched. So we launched Canvas, and it was the first project. I was a tech lead, basically, and then I think over time I was trying to refine what my team is, and I feel like it's at the intersection of human-computer interaction, defining what the next interaction paradigms might look like with some of the most recent reasoning models, as well as actually trying to come up with novel methods, how to improve those models for certain tasks if you want to. So for Canvas, for example, one of the most common use cases is basically writing and coding. And we're continually working on, okay, how do we make Canvas coding to go beyond what is possible right now? And that requires us to actually do our own training and coming up with new methods of synthetic data generation. The way I'm thinking about it is that my team is going from very full stack, from training models all the way up to deployment and making sure that we create novel product features that is coherent to what you're doing. So we're really working on that.swyx [00:02:08]: So it's, it's a lot of work to do right now. And I think that's why I think it's such a great opportunity. You know, how could something this big work in like an industrial space and in the things that we're doing, you know, it's a really exciting time for us. And it's just, you know, it's a lot of work, but what I really like about working in digital space is the, you know, the visual space is always the best place to stay. It's not just the skill sets that need to be done.Alessio [00:02:17]: Like we have, like, a lot of things to be done, but like, we've got a lot of different, you know, things to come up with. I know you have some early UX prototypes with GPT-3 as well, and kind of like maybe how that is informed, the way you build products.Karina [00:02:32]: I think my background was mostly like working on computer vision applications for like investigative journalism. Back when I was like at school at Berkeley, and I was working a lot with like Human Rights Center and like investigative journalists from various media. And that's how I learned more about like AI, like with vision transformers. And at that time, I was working with some of the professors at Berkeley AI Research.swyx [00:03:00]: There are some Pulitzer Prize winning professors, right, that teach there?Karina [00:03:04]: No, so it's mostly like was reporting for like teams like the New York Times, like the AP Associated Press. So it was like all in the context of like Human Rights Center. Got it. Yeah. So that was like in computer vision. And then I saw... I saw Crisolo's work around, you know, like interpretability from Google. And that's how I found out about like Anthropic. And at that time, I was just like, I think it was like the year when like Ukraine's war happened. And I was like trying to find a full-time job. And it was kind of like all got distracted. It was like kind of like spring. And I was like very focused on like figuring out like what to do. And then my best option at that time was just like continue my internship. At the New York Times and convert to like full-time. At the New York Times, it was just like working on like mostly like product engineering work around like R&D prototypes, kind of like storytelling features on the mobile experience. So it kind of like storytelling experiences. And like at that time, we were like thinking about like how do we employ like NLP techniques to like scrape some of the archives from the New York Times or something. But then I always wanted to like get into like AI. And like I knew OpenAI for a while, like since I was like, and I was like, I don't know, I don't know. So I kind of like applied to Anthropic just on the website. And I was rejected the first time. But then at that time, they were not hiring for like anything like product engineering or front-end engineering, which was something I was like, at that time, I was like interested in. And then there was like a new opening at Anthropic was like kind of like you are front-end engineer. And so I applied. And that's how my journey began. But like the earlier prototypes was mostly like I used like Clip.swyx [00:05:13]: We'll briefly mention that the Ukrainian crisis actually hit home more for you than most people because you're from the Ukraine and you moved here like for school, I guess. Yeah.Karina [00:05:23]: Yeah.swyx [00:05:23]: We'll come back to that if it comes up. But then you joined Anthropic, not just as a front-end engineer. You were the first. Is that true? Designer? Yeah.Karina [00:05:32]: Yes. I think like I did both product design and front-end engineering together. And like at that time it was like pre-CHPT. It was like, I think August 2022. And that was a time when Anthropic really decided to like do more product-y related things. And the vision was like, we need to like fund research and like building product is like the best way to like fund safety research, which I find it quite admirable. So the really first product that Anthropic built was like Cloud and Slack. And it was sunsetted not long after, but like it was like one of the first, I think I still come back to that idea of like Cloud operating inside some of the organizational workplace like Slack and something magical in there. And I remember we built like ideas like summarize the thread, but you can like imagine having automated like ways of like, maybe Cloud should like summarize multiple channels every week, custom for what you like or for what you want. And then we built some like really cool features. Like this. So we could like tag Cloud and then ask to summarize what's what happened in the thread. So just like new ideas, but we didn't quite double down because you could like imagine like Cloud having access to like the files or like Google drive that you can upload and just connectors, like connections in the Slack. Also the UX was kind of constraining at that time. I was thinking like, oh, we wanted to do this feature, but like Slack interface kind of constrained us to like do that. And we didn't want to like be dependent on the platform, like Slack. And then after like ChaiGPT came out, I remember the first two weeks, my manager made me this challenge, like, can I like reproduce kind of like a similar interface in like two weeks? And one of the early mistakes being in the engineering is like, I said, yes, instead I should have said like, you know, it's double, two X at the time. Sure. Um, and this is how like Cloud.ai was kind of like born.swyx [00:07:39]: Oh, so you actually wrote Cloud.ai? Yeah. As your first job. Yeah.Karina [00:07:43]: Like, I think like the first like 50,000 code of lines without any reviews at that time, because there's no one, um, yeah, it was like very small team. It was all like six, seven team who we were called like deployment team. Yeah.swyx [00:07:59]: Oh, mine, I actually interviewed for, uh, at Anthropic around that time. I got, I was given Cloud in Sheets and that was my other form factor. I was like, oh yeah, this needs to be in a table so we can, we can just copy paste and just span it out. Uh, which is kind of cool. The other rumor that, um, we might as well just mention this, um, Raza Habib from HumanLoop, uh, often says that, uh, you know, there was some, there's some version of ChatGPT in Anthropic, like you had the chat interface already, like you had Slack, why not launch a web UI? Like basically like how did, how did OpenAI beat Anthropic to ChatGPT basically? Um, well, it seems kind of obvious to have it.Karina [00:08:35]: I think ChatGPT model itself came out way before then we decided to like launch Cloud2 necessarily. And I think like at that time, Cloud 1.3 had a lot of hallucinations actually. So I think there was like, one of the concerns is like, I don't think like the leadership was convinced, had the conviction that this is the model that you need to like, you want to like deploy or something. So it was a lot of discussions around, around that time. But Cloud 1.3 was like, I don't know if you played with that, but it's like extremely creative and it was like really cool.swyx [00:09:07]: Nice.Alessio [00:09:08]: It's still creative. And you had a tweet. Recently that you said things like Canvas and Tasks could have happened two years ago, but they were not. Do you know why they were not? Was it too many researchers at the labs not focused on UX? Was it just not a priority for the labs?Karina [00:09:24]: Yeah. I come back to that question a lot. I guess like I was working on something similar to like Canvas-y, but for Cloud at that time in like 2023, it was the same similar idea of like Cloud workspace where a human and a Cloud could have like a shared workspace. Yeah. And that's Artifacts. Which is like a document. Right.swyx [00:09:44]: No, no, no. This is Cloud projects.Karina [00:09:46]: I don't know. I think it kind of evolved. I think like at that time I was like in product engineering team and then I switched to like research team and the product engineering team grew so much. They had their own ideas of like artifacts and like projects. So not necessarily, maybe they had, they looked at my like previous explorations, but like, you know, when I was exploring like Cloud documents or like Cloud workspace was like. Yeah. I don't think anybody was thinking about UX as much or like not many like researchers understood that. And I think the inspiration actually for, I still have like all the sketches, but the inspiration was like from the Harry Potter, like Tom Riddler diary. That was an inspiration of like having Cloud writing into the document or something and communicate back.swyx [00:10:34]: So like in the movie you write a little bit and then it answers you. Yeah.Karina [00:10:37]: Okay.swyx [00:10:38]: Interesting.Karina [00:10:39]: But that was like in the. Only in the context of like writing. I think Canvas is like more also serves like coding, one of the most common use cases. But yeah, I think like those, those ideas could have happened like two years ago. Just like maybe, I don't think it was like a priority at that time. It was like very unclear. I think like AI landscape at that time was very nascent. If that makes sense. Like nobody, like, even when I would talk to like some of the designers at that time, like product designers, they were not even thinking about that at all. They did not have like AI in mind. And like, it's kind of interesting, except for one of my designer friends. His name is Jason Yuan. Yeah. Who was thinking about that.swyx [00:11:19]: And Jason now is a new computer. Yes. We'll have them on at some point. I had them speak at my first summit and you're speaking the second one, which will be really fun. Nice. We'll stay on Anthropic for a bit and then we'll move on to more recent things. I think the other big project that you were, you were involved with was just Cloud 3. Just tell us the story. Like, what was it like to launch one of the biggest launches of the year? Yeah.Karina [00:11:39]: I think like I was, so Cloud 3.swyx [00:11:43]: This is Haiku, Sonnet, Opus all at once, right? Yes. Yeah.Karina [00:11:46]: It was a Cloud 3 family. I was a part of the post-training fine tuning team. We only had like, what, like 10, 12 people involved. And it was really, really fun to like work together as friends. So yeah, I was mostly involved in like Cloud 3 Haiku post-training side and then evaluations, like developing new evaluations. And like literally writing the entire like model card. And I had a lot of fun. I think like the way you train the model is like very different, obviously. But I think what I've learned is that like you will end up with like, I don't know, like 70 models and every model will have its own like brain damage. And like, so it's just like, like kind of just bugs.swyx [00:12:28]: Like personality wise or performance benchmarks?Karina [00:12:31]: I think every model is very different. And I think like, it's like one of the interesting like research questions is like, how do you understand like the data interface? How do you understand the interactions as you like train the model? It's like, if you train the model on like contradictory data sets, how can you make sure that there won't be like any like weird like side effects? And sometimes you get like side effects. And like the learning is that you have to like iterate very rapidly and like have to like debug and detect it and make like address it with like interventions. And actually some of the techniques from like software engineering is very like useful here. It's like, how do you- Yeah, exactly.swyx [00:13:09]: So I really empathize with this because data sets, if you put in the wrong one, you can basically kind of screw up like the past month of training. The problem with this for me is the existence of YOLO runs. I cannot square this with YOLO runs. If you're telling me like you're taking such care about data sets, then every day I'm going to check in, run evals and do that stuff. But then we also know that YOLO runs exist. Yes. So how do you square that?Karina [00:13:32]: Well, I think it's like dependent on how much compute you have. Right? So it's like, it's actually a lot of questions and like researchers are like, how do you most effectively use the compute that you have? And maybe you can have like two to three runs that is only like YOLO runs. But if you don't have a luxury of that, like you kind of need to like prioritize ruthlessly. Like what are the experiments that are most important to like run? Yeah. I think this is what like research management is basically. It's like, how do you-swyx [00:14:04]: Funding efforts. Yeah. Yeah. Prioritizing.Karina [00:14:07]: Take like research bets and make sure that you build the conviction and those bets rapidly such that if they work out, you like double down on them. Yeah.swyx [00:14:15]: You almost have to like kind of ablate data sets too and like do it on the side channel and then merge it in. Yeah. It's kind of super interesting. Tell us more, like what's your favorite? So you, I have this in front of me, the model card. You say constructing this painful, this table was slightly painful. Just pick a benchmark and what's an interesting story behind one of them?Karina [00:14:33]: I would say GPQA was kind of interesting. I think it was like the first, I think we were the first lab, like Antarctica was the first lab to like run.swyx [00:14:42]: Oh, because it was like relatively new after NeurIPS? Yeah.Karina [00:14:45]: Yeah. Okay. Published GPQA like numbers. And I think one of the things that we've learned was that I personally learned about that, like any evals is like, some evals are like very like high variance. And like GPQA is like, happened to be like a huge like high variance. Like evaluation. So like one thing that we did is like having like run the average of like five and like take the average. But like the hardest thing about like the model card is like none of the numbers are like apples to apples. Yes. Will knows this. So you actually need to like go back to like, I don't know, like GPT-4 model card and like read the appendix just to like make sure that like the settings are the same as you're running the settings too. So it's like never an apples to apples. Yeah. But it's interesting how like, you know, when you market models as products, like customers don't necessarily know. Yeah. Like.swyx [00:15:44]: They're just like, my MMLU is 99. What do you mean? Yeah, exactly. Why isn't there an industry standard harness, right? There's this eLuther's thing, which it seems like none of the model labs use. And then OpenAI put out simple eval and nobody uses that. Why isn't there just one standard way everyone runs this? Because the alternative approach is you rerun your evals on their models. And obviously the numbers, your numbers will be lower. Yeah. And they'll be unhappy. So that's why you don't do that.Karina [00:16:12]: I think it operates on an assumption that like the models, the next generation of the model or the model that you produce next is going to behave the same. So for example, like I think the way you prompt a one or like a cloud three is going to be very different from each other. I feel like there's a lot of like prompting that you need to do to get the evals to run correctly. So sometimes the model will just like output like new lines and the way it parsed will be like incorrect or something. This has happened with like Stanford. I remember like when Stanford had this also like they were like running benchmarks. Helm? Yeah, Helm. And somehow like cloud was like always like not performing well. And that's because like the way they prompted it was kind of wrong. So it's like a lot of like techniques. Yeah. It's just like very hard because like nobody even knows.swyx [00:17:00]: Has that gone away with chat models instead of, you know, just raw completion models?Karina [00:17:05]: Yeah, I guess like each eval also can be run in a very different way. Sometimes you can like ask the model to output in like XML tags, but some models are not really good at XML tags. So it's like, do you change the formatting per model or like do you run the same format across all models? And then like the metrics themselves, right? Like maybe, you know, accuracy is like one thing, but maybe you care about like some other metrics like F score or like some other like things. Yeah. It's like hard. I don't know.Alessio [00:17:36]: And talking about O1 prompting, we just had a O1 prompting post on the newsletter, which I think was...swyx [00:17:42]: Apparently it went viral within OpenAI. Yeah. I don't know. I got pinged by other OpenAI people. They were like, is this helpful to us? I'm like, okay. Oh, nice. Yeah.Alessio [00:17:50]: I think it's like maybe one of the top three most read posts now. Yeah. Cool. And I didn't write it. Okay. Exactly.swyx [00:17:57]: Anyway, go ahead.Alessio [00:17:57]: What are your tips on O1 versus like cloud prompting or like what are things that you took away from that experience? And especially now, I know that with 4.0 for Canvas, you've done RL after on the model. So yeah, just general learning. So now to think about prompting these models differently.Karina [00:18:12]: I actually think like O1, I did not even harness the magic of like O1 prompting. But like one thing that I found is that like, if you give O1 like hard, like constraints of like what you're doing. What you're looking for, basically the model will be, will have a much easier time to like kind of like select the candidates and match like the candidate that is most like fulfilled the criteria that you gave. And I think there's a class of problems like this that O1 excels at. For example, if you have a question, like a bio question on like some, or like in chemistry, right? Like if you have like very specific criteria with the protein or like some of the. Chemical bindings or something like, then the model will be really, will be really good at like determining the exact candidate that will match the certain criteria.swyx [00:19:04]: I have often thought that we need a new IF eval for this. Because this is basically kind of instruction following, isn't it? Yes. But I don't think IF eval has like multi-step IF eval. Yeah. So that's what basically I use AI News for. I have a lot of prompts and a lot of steps and a lot of criteria and O1 just kind of checks through each kind of systematically. And we don't have any evals like that.Karina [00:19:24]: Yeah.Alessio [00:19:25]: Does OpenAI know how to prompt O1? I think that's kind of like the, that's the, you know, Sam is always talking about incremental deployments and kind of like getting, having people getting used to it. When you release a model, you obviously do all the safety testing, but do you feel like people internally know how to get a hundred percent out of the model? Or like, are you also spending a lot of time learning from like the outside on how to better prompt O1 and like all these things? Yeah.Karina [00:19:50]: I certainly think that you learn so much from like external feedback too. Yeah. I feel like I don't fully know on how people use like O1. I think like a lot of people use O1 for like really hardcore like coding questions. I feel like I don't fully know how to best use O1. You release the model. Except for like, I use O1 to just like do some like synthetic data explorations. But that's it.Alessio [00:20:16]: Do people inside of OpenAI, once the model is coming out, do you get like a company-wide memo of like, hey, this is how you should try and prompt this? Yes. Especially for people that might not be close to it during development, you know, or I don't know if you can share anything, but I'm curious how internally these things kind of get shared.Karina [00:20:34]: I feel like I'm like in my own little corner in like research. I don't really like to look at some of the Slack channels.swyx [00:20:40]: It's very, very big.Karina [00:20:41]: So I actually don't know if something like this exists. Probably. It might be exist because we need to share to like customers or like, you know, like some of the guides. I'm like, how do you use this model? So probably there is.swyx [00:20:56]: I often say this. The reason that AI engineering can exist outside of the model labs is because the model labs release models with capabilities that they don't even fully know because you never trained specifically for it. It's emergent. And you can rely on basically crowdsourcing the search of that space or the behavior space to the rest of us. Yeah. So like, you don't have to know. That's what I'm saying. Yeah.Karina [00:21:20]: I think like an interesting thing about like O1 is like. That like it's really for like average human. Sometimes I don't even know whether the model like produced the correct output or not. Like it's really hard for me to like verify even like hard like stem questions. I don't know if I'm not an expert. Like I usually don't know. So it's like the question of like alignment is actually more important like for this like complex reasoning models to like how do we help humans to like verify the outputs of these models is quite important. And I feel like. Yeah. Like learning from external feedback is kind of cool.swyx [00:21:56]: For sure. One last thing on cloud three. You had a section on behavioral design. Yes. Anthropics very famous for the HHH goals. What was your insights there? Or, you know, maybe just talk a little bit about what you explored. Yeah.Karina [00:22:09]: I think like behavioral design is like a really cool. I'm glad that I made it like a section around this. And it's like really cool. I think like.swyx [00:22:17]: Like you weren't going to publish one and then you insisted on it or what?Karina [00:22:20]: I think like I just like put the section. Yeah. I think like I put the section inside it and like, yeah, Jared, my like one of my most favorite researchers like, yeah, that's cool. Let's, let's do that. I guess. Yeah. Like nobody had this like term like behavioral design necessarily for the models. It's kind of like a new little field of like extending like product design into like the model design. Right. Like, so how do you create a behavior for the model in certain contexts? So as for example, like in Canvas, right. Like one of the things that we had to like think about is like, okay, like now the model enters like more collaborative environment, more collaborative context. So like what's the most appropriate behavior for the model to act like as a collaborator? Should it ask like more follow up questions? Should it like change? What's the tone should be? Like what is the collaborator's tone? It's different from like a chat, like conversationalist versus like collaborator. So how do you shape the perspective? Like, you know, like the persona and the personality around that is it has like some philosophical questions too. Like, yeah. Behavioral. I mean, like, I guess like I can talk more about like the methods of like creating the personality. Please. It's the same thing as like you would create like a character in a video game or something. It's kind of like...swyx [00:23:39]: Charisma, intelligence. Yeah, exactly. Wisdom.Karina [00:23:42]: What are the core principles? Helpful, harmless, honest. Yeah. And obviously for Cloud, this was my, is much easier than I would say like for ChargeAPD. For Cloud, it's like baked in the mission, right? It's like honest, harmless, helpful. But the most complicated thing about the model behavior or the behavioral design is that sometimes two values would contradict each other. I think this happened in Cloud 3. One of the main things that we were thinking about was like, how do we balance this like honesty versus like homelessness or like helpfulness? And it's like, we don't want the model to always like refuse even to like innocuous queries, like some like creative writing prompts, but also if you don't want the model to be act like a, be harmful or something. So it's like, there's always a balance between those two. And it's more like art than the science necessarily. And this is what data sets craft is, is like more of an art than a literal science. You can definitely do like empirical research on this, but it's actually like, like this is the idea of like synthetic data. Like if you look back to like institutional AI paper is around like, how do you create completions such that you would agree to certain like principles that you want your model to agree on? So it's like, if you create the core values of the models, how do you decompose those core values? Into like specific scenarios or like, so how does the model need to express its honesty in a variety of kind of like scenarios? And this is where like generalization happens when you craft the persona of the model. Yeah.swyx [00:25:22]: It seems like what you described behavior modification or shaping as a side job that was done. I mean, I think Anthropic has always focused on it the first and the most. But now it's like every lab has sort of. It's like a vibes officer for you guys is Amanda, for OpenAI it's Rune, and then for Google, it's Steven Johnson and Raiza who we had on the podcast. Do you think this is like a job? Like, it's like a, like every, every company needs a tastemaker.Karina [00:25:50]: I think the model's personality is actually the reflection of the company or the reflection of the people who create that model. So like for Claude's, I think Amanda was doing a lot of like Claude character work and I was working with her at the time.swyx [00:26:04]: But there's no team, right? Claude character work. Now there's a little bit of a team. Isn't that cool?Karina [00:26:09]: But before that there was none. I think like actually it was Claude 3, he was like, we kind of doubled down on the feedback from Claude 2. Like people, we didn't even like think, but like people said like Claude 2 is like so much better at like writing and like has certain personality, even though it was like unintentional at all. And we did not pay that much attention and didn't know even how to like productionize this property of model being better. Like personality. And to like, with Claude 3, we kind of like had to like double down because we knew that if you would launch like in chat, we wanted to like Claude honesty is like really good for like enterprise customers. So we kind of wanted to like make sure the hallucinations went, like factuality would like go up or something. We didn't have a team until or after like Claude 3, I guess. Yeah.swyx [00:26:58]: I mean, it's, it's growing now. And I think anyway, everyone's taking it seriously.Karina [00:27:00]: I think on OpenAI there was a team called Model Design. It's John, the PM. She's leading that team and I work very closely with those teams that we were working on, like actually writing improvements that we did with ChaiGPT last year. And then I was working on like this collaboration, like how do you make ChaiGPT act like a collaborator for like Canvas? And then, yeah, we worked together on some of the projects.swyx [00:27:25]: I don't think it's publicly known his, his actual name other than Rune, but he's, he's, he's mostly, he's mostly doxxed.Alessio [00:27:32]: We'll beep it and then people can guess. Yeah. Do we want to move on to OpenAI and some of the recent work, especially you mentioned Canvas. So the first thing about Canvas is like, it's not just a UX thing. You have a different model in the backend, which you post-trained on or one preview distilled data, which was pretty interesting. Can you maybe just run people through, you come up with a feature idea, maybe then how do you decide what goes in the model, what goes in the product and just that, that process? Yeah.Karina [00:28:03]: I think the most unique thing about ChaiGPT Canvas. What I really liked about that was that it was also the team formed out of the air. So it was like July 4th or something... Wow. during the break. Like on Independence Day.swyx [00:28:17]: They just like, okay.Karina [00:28:18]: I think it was, there was some like company break or something. I remember I was just like taking a break and then I was like pitching this idea to like Barrett Zarf. Barrett Zarf, yeah. Who was my manager at that time. Just like, I just want to like create this like Canvas or something. And I really didn't know how to like apply this. Navigate, OpenAI, it was like my first, like, I don't know, like first month at OpenAI and I really didn't know how to like navigate, how do I get product to work with me or like some of the ideas, like some of the things like this was like, so I'm really grateful for like actually Barrett and Mira who helped me to like staff this project basically. And I think that was really cool. And it was like this 4th of July and like Barrett was like, yeah, actually, who's like an engineering manager is like, yeah, we should like staff this project with like five, six engineers or something. And then Karina can be a researcher on this project. And I think like, this is how the team was formed. This was kind of like out of the air. And so like, I didn't know anyone there at that time, except for Thomas Dimson. He did like the first like initial like engineering prototype of the canvas and it kind of like reshaped. But I think the first, we learned a lot on the way how to work together as product and research. And I think this is one of the first projects at OpenAI where research and product work together from the very beginning. And we just made it like a successful project in my opinion is because like designers, engineers, PM and research team were all together. And we would like push back on each other. Like if like it doesn't make sense. Yeah. we'd like to do it on the model side, like we are hard to like collaborate with like applied engineers to like make sure this is being handled on the applied side. But the idea is you can go that far with like prompted baseline, prompt, the charge of PT was kind of like the first thing that we tried was like a canvas as a tool or something. So how do we define the behavior of the canvas? But then like we've found like different like edge cases that we wanted to like fix and the only way to like fix the some of these edge cases actually through post training. So we actually, what we did was actually retrain the entire 4.0 plus our Canvas stuff. And this is like, there are like two reasons why we did this is because like the first one is that we wanted to ship this as a better model in the dropdown menu. We could like rapidly iterate on users' feedback as we ship it and not going through the entire like integration process into like this like new one model or something, which took some time. Right. So I'm like from beta to like GA, it took, I think, three months. So we kind of wanted to like ship our own model with that feature to like learn from the user feedback very quickly. So that was like one of the decisions we made. And then with Canvas itself, we just like had a lot of like different like behavioral, it's again, like it's a behavioral engineering. It's kind of like various behavioral craft around like when does Canvas need to write comments? When does it need to like update or like edit the document? When does it need to like update or like edit the document? When does it need to edit the entire, like rewrite the entire document versus like edit very specific section of the user asks? And when does it need to like trigger the Canvas itself? It was one of those, those like behavioral engineering questions that we had. At that time, I was also working with like writing quality. So that was like the perfect way for us to like literally both teach the model how to use Canvas, but also like improve writing quality if writing was like one of the main use cases for Chachi PD. So I think that was like the reasoning around that.swyx [00:31:55]: There's so many questions. Oh my God. Quick one. What does improved writing quality mean? What are the evals?Karina [00:32:01]: What are the evals? Yeah. So the way I'm thinking about it is like have two various directions. The first direction is like, how do you improve the quality of the writing of the current use cases of Chachi PD? And those, most of the use cases are mostly like nonfiction writings. It's like email writing or like some of the, maybe you've blog posts, cover letters is like one. I don't mean use cases, but then the second one is like, how do we teach the model to literally think more creatively or like write in a more creative manner such that it will like just create novel forms writing. And I think the second one is like much of a longer term, like research question. While the first one is more like, okay, we just need to improve data quality for the writing use cases that between the models are. It is more straightforward question. Okay. But the way we evaluated the writing quality, so actually I worked with Jan's team on the model design. So they had a team of like model writers and we would work together and it's just like a human eval. It's like internal human eval where we would just like that. Yeah. On the prompt distribution that we cared about, like we want to make sure that the models that we like use, that we trained were always like better or something. Yeah.swyx [00:33:20]: So like some test set of like a hundred prompts that you want to make sure you're good on. I don't know. I don't know how big the prompt distribution needs to be because you are literally catering to everyone. Right.Karina [00:33:32]: Yeah. I think it was much more opinionated way of like improving writing quality because we worked together with like model designers to like come up with like core principles of what makes this particular writing good. Like what does make email writing good? And we had to like craft like some of the literally like rubric on like what makes it good and then make sure during the eval, we check the marks on this like rubric. Yeah.swyx [00:33:58]: That's what I do. Yeah. That's what school teachers do. Yeah.Karina [00:34:02]: Yeah. It's really funny.swyx [00:34:03]: Like, yeah, that's exactly how we grade essays. Yes.Karina [00:34:06]: Yeah.Alessio [00:34:06]: I guess my question is when do you work the improvements back in the model? So the canvas model is better writing. Why not just make the core model better too? So for example, I built this small podcasting thing for a podcast and I have the 4.0 API and I asked it to write a write up about the episode based on the transcript. And then I've done the same in canvas. The canvas one is a lot better. Like the one from the raw 4.0, it starts, the podcast delves and I was like, no, I'm not delved in the third word. Why not put them back in 4.0 core or is there just like.Karina [00:34:38]: I think you put it back in the core now.Alessio [00:34:40]: Yeah. So like, so the 4.0 canvas now is the same as 4.0. Yeah. You, you must've missed that update. Yeah. What's the, what's the, what's the process to, I think it's just like an AB test almost. Right. To me, it feels, I mean, I've only tried it like three times. But it feels the canvas, the canvas output feels very different than the API output.Karina [00:35:01]: Yeah, yeah. I think like, there's always like a difference in the model quality. I would say like the original better model that we released this canvas was actually much more creative than even right now when I use like 4.0 with canvas. I think it's just like the complexity of like the data and the complexity of the, it's kind of like versioning issues right here. It's like, okay, like your version. 11 will be very different from like version eight, right? It's like, even though like the stuff that you put in is like the same or something.swyx [00:35:32]: It's a good time to, to say that I have used it a lot more than three times. I'm a huge fan of canvas. I think it is, um, yeah, like it's weird when I talk to my other friends, they, they don't really get it yet or they don't really use it yet. I think because it's maybe sold as like sort of writing help when really like it's kind of, it's the scratch pad. Yeah. What are the core use cases or like, yeah.Karina [00:35:53]: Oh yeah. I'm curious. Literally draft.swyx [00:35:54]: Drafting anything like I want to draft like copy for my conference that I'm running, like I'll put it there first and then I like, it'll just have the canvas up and I'll just say what I don't like about it and it changes. I will maybe edit stuff here and paste in. So, so for example, like I wanted to draft a brainstorm list of reasons of signs that you may be an NPC just for fun, just like a blog post for fun. Nice. And I was like, okay, I'll do 10 of these and then I want you to generate the next 10. So I wrote 10. I placed it in it to, to chat GPT. Okay. And they generated the next 10 and they all sucked, all horrible, but it also spun up the canvas with, with the blog posts and I was like, okay, self-critique why your output sucks and then try again. And it, and it just kind of just iterates on the blog posts with me as a writing partner and it is so much better than, I don't know, like intermediate steps. I was like, that would be my primary use case literally drafting anything. I think the other way that I'll put it, I'm not putting words in your mouth. This is how I view what canvas is and why. It's so important. It's basically an inversion of what Google docs is, wants to do with Gemini. It's like Google docs on the main screen and then Gemini on the side and right now what chat GPT has done is do the chat thing first and then the docs on the side, but it's kind of like a reversal of, of what is the main thing. Like Google docs starts with the canvas first that you can edit and whatever, and then you maybe sometimes you call in the AI assistants, but chat GPT, what you are now is you're kind of AI first with these, the site output being Google docs.Karina [00:37:22]: I think we definitely want to improve. Like writing use case in terms of like, how do we make it easier for people to format or like do some of the editing? I think there is still a lot of room for improvement, to be honest. I think the another thing is like coding, right? I feel like one of the things that'd be like doubling down is actually like executing code inside the canvas. And there's a lot of questions like, how do you evolve this? It's kind of like IDE for both. And I feel like this is where I'm coming from is like the chat GPT evolves into this blank image. It's kind of like the interface, which can morph itself in whatever you trying, like the model should try to like derive your true intent and then modify the interface based on your intent. And then if you like writing, it should become like the most powerful, like writing IDE possible. If it's like coding, it should become like a coding IDE or something.swyx [00:38:14]: I think it's a little bit of a odd decision for me to call those two things, the same product name, because they're basically two different UIs. Like one is code interpreter plus plus. The other one is canvas. Yes. I don't know if you have other thoughts on canvas.Alessio [00:38:27]: No, I'm just curious, maybe some of the harder things. So when I was reading, for example, forcing the model to do targeted edits versus like for rewrite, it sounds like it was like really hard in the AI engineer mind. Maybe sometimes it's like just pass one sentence in the prompt. It's just going to rewrite that sentence. Right. But obviously it's harder than that. What are maybe some of the like hard things that people don't understand from the outside and building products like this?Karina [00:38:50]: I think it's always hard with any new like product feature. Like. Canvas or tasks or like any other new features that you don't know how people would use this feature. And so how do you even like build evaluations that would simulate how people would use this feature? And it's always like really hard for us. Therefore, like we try to like lean on to like iterative deployment this in order to like learn from user feedback as much as possible. Again, it's like we didn't know that like code diffs was very difficult. For a model, for example, again, it's like, do we go back to like fundamentally improve like code diffs as a model capability, or do you like do a workaround where the model will just like rewrite the entire document, which is yield to like higher accuracy? And so those are like some of the decisions that we had to like make as yeah. How do you like improve the bar to the product quality, but also make sure the model. Quality is also a part of it. And like, what kind of like cheat offs you're okay to do? Again, I think, I think this is like new way of product development is more like product research, model training and like product development goes like together hand in hand. This is like one of the hardest things, like defining the entire like model behaviors. I think just like, is there's so many edge cases that might happen, especially when you like do canvas was like other tools, right? Like canvas plus Dalek. Canvas plus search. If you like select certain section and then like ask for search, like how do you build such evals? Like what kind of like features or like behaviors that you care the most about? And this is how you build evals.swyx [00:40:35]: You tested against every feature of ChatGPT? No. Oh, okay. I mean, I don't think there's that many that you can. Right. It will take forever.Karina [00:40:44]: But it's the same. It's indecision boundary between like Python, ADA advanced data analysis versus canvas. Is one of the most trickiest like decision boundary behaviors that we had to like figure out, like how do you derive the intent from the human user query? Yeah. And how do I say this? Deriving the intent, meaning does the user expect canvas or some other tool and then like make sure that it's like maximally like the intent was is like actually still one of the hardest problems. Yeah. Especially with like agents, right? Like you don't want like agents to go for like five minutes and do something on the background and then come back with like some mid answer that you could have gotten from like a normal model or like the answers that you didn't even want because it didn't have enough context. It didn't like follow up correctly.swyx [00:41:40]: You said the magic word. We have to take a shot every time you say it. You said agents.swyx [00:41:46]: So let's move to tasks. You just launched tasks. What was that like? What was the story? I mean, it's, it's your, it's your baby. SoKarina [00:41:52]: Now that I have a team, I actually like tasks was purely like my residence projects. I was mostly a supervisor. So I kind of like delegated a lot of things to my resident. His name is like Vivek. And I think this is like one of the projects where I learned management, I would say. Yeah. But it was really cool. I think it's very similar model. I'm trying to replicate canvas operational model. How do we operate with product people or like product applied orgs was research and the same happened. I was trying to replicate like the methods and replicate the operational process with tasks. And actually tasks was developed less than like two months. So if canvas took like, I don't know, four months, then tasks took like two months. And I think again, like it's kind of very similar process of like, how do we build eval? You know, some people like ask for like reminders in actual charge GPT, but then like, obviously, even though they know it doesn't work. Yeah. So like there is some like demand or like desire from users to like do this. And actually I feel like task is like simple feature in my opinion is something that you would want from any model. Right. But then the magic is like when I actually, because the model is so general, it knows how to use search or like canvas or like create cypher. You know, you can modify stories and create Python puzzles when coupled with status actually becomes like really, really powerful. It was like the same ideas of like, how do we shape the behavior of the model? Again, we shipped it as like as a better model in the model dropdown. And then we are working towards like making that feature integrated in like the core model. So I feel like the principles that like everything should be like in one model, but because of some of the operational difficulties, it's, it's much easier to like deploy. It's a separate model first to like learn from the user feedback and then iterate very quickly and then improve into the core model basically. Again, this is a project was also like together at the beginning from the very beginning, designers, engineers, researchers were working all together and together with model designers, we were like trying to like come up with like evals evaluations and like testing and like bug bashing. And it's like a lot of cool like synergy.swyx [00:44:12]: Evals, bug bashing. I'm trying to distill. Okay. I would love a canvas for this, for distill what the ideal product management or research management process is. Right. Start from like, do you have a PRD? Do you have a doc that like these, these things? Yes. And then from PRD, you get funding maybe or like, you know, staffing resources, whatever. Yes. And then prototype maybe. Yeah. Prototype.Karina [00:44:37]: I would say like prototype was prompted baseline. It's all, all, everything starts with like prompted baseline. Yeah. And then like we craft like certain like evaluations that you want to like capture. Okay. They want to like measure progress at least for the model and then make sure that evals are good and make sure that the prompted baseline actually fails on those like evals because then you have like, if you're allowed to like hill climb on. And then once you start iterating on the model training, it's actually very iterative. So like every time you train the model or you like look at the benchmark or like look at your evals and it like goes up, it's like good. But then also you don't want to like, you want to make sure it's not like super overfitting. Like that's where you run on other evals, right? Like intelligence evals or something. And then like. Yeah.swyx [00:45:20]: You don't want regressions on the other stuff. Right. Yes. Okay. Is that your job or is that like the rest of the company's job to do?Karina [00:45:26]: I think it's mainly my like. Really? The job of the people who like.swyx [00:45:30]: Because regressions are going to happen and you don't necessarily own the data for the other stuff.Karina [00:45:34]: What's happening right now is that like you, basically you only like update your, your data sets, right? So it's like you compare on the baseline, you compare like the regressions on the baseline model.swyx [00:45:47]: Model training and then book bash. And that's, that's about it. And then ship.Karina [00:45:50]: Actually, I did the course with Andrew Yang, who. Yes. There was like one little lesson around this. Okay.swyx [00:45:57]: I haven't seen. Product research. You tweeted a picture with him and it wasn't clear if you were working on a course. I mean, it looked like the standard course picture with Andrew Yang. Yes. Okay. There was a course with him. What was that like working with him?Karina [00:46:08]: No, I'm not working with him. I just like, I just like did the course with him. Yeah. Yeah.Alessio [00:46:11]: How do you think about the tasks? So I started creating a bunch of them. Like, do you see this as being, going back to like the composability, like composable together later? Like you're going to be scheduled one task that does multiple tasks chained together. What's the vision?Karina [00:46:27]: I would say task is like a foundational module, obviously to generalize to all sorts of like behaviors that you want. Like sometimes like I see like people have like three tasks.Karina [00:46:41]: And right now I don't think like the model handles this very well. I think that ideally we learn from like the user behavior and ideally the model will just be more proactive in suggesting of like, oh, I can either do this for you every day because I've observed that you do that every day or something. So it's like more becomes like a proactive behavior. I think right now you have to be more explicit, like, oh yeah, like every day, like remind me of this. But I think like the, the ideally the model will always think about you on the background and like kind of suggests, okay, like I noticed you've been reading some of this particular like how I can use articles. Maybe I can try to suggest you like every day or something. So it's like, it's just like much more like of a natural like friend, I think.swyx [00:47:35]: Well, there is an actual startup called Friend that is trying to do that. Oh, Yes. We'll have, we'll interview Avi at some point. But like it sounds like the guiding principle is just what is useful to you. It's a little bit B2C, you know, is there any B2B push at all or you don't think about that?Karina [00:47:51]: I personally don't think about that as much, but I definitely feel like B2B is cool. Again, I come back to like Cloud and Slack. It's like one of the, like the first like interfaces where like the model was operating inside your organization, right? It would be very cool for the model to like handle that. To like become like a productive member of your organization. And then either like even like even process, like I right now, like I'm thinking like processing like user feedback. I think it'd be very cool if the model would just like start doing this for us and like we don't have to hire a new person on this just for this or something. And like you have like very simple like data analysis or like data analytics or like how this features like.swyx [00:48:36]: Do you do this analysis yourself? Or do you have a data science team that tells you insights?Karina [00:48:40]: I think there are some data scientists. Okay.swyx [00:48:43]: I've often wondered, I think there should be some startup or something that does automated data insights. Like I just throw you my data. You tell me. Yeah. Yeah, exactly. Cause that's what the data team at any company does. Right. Which is just give us your data. We'll like make PowerPoints. Yeah. Yeah.Karina [00:48:59]: That'd be very cool.swyx [00:49:00]: That's, I think that's a, that's a really good vision. You had thoughts on agents in general. There's some more proactive stuff. You actually had tweeted a definition. Which is kind of interesting.Karina [00:49:09]: I did.swyx [00:49:10]: Well, I'll read it out to you. You tell me. Okay. If you still agree with yourself. This is five days ago. Agents are a gradual progression of tasks, starting off with one-off actions, moving to collaboration. Ultimately fully trustworthy long horizon. I know it's, I know it's uncomfortable to have your tweets read to you. I have had this done to me. Ultimately fully trustworthy long horizon delegation in complex environments like multiplayer, multi-agents, tasks, and canvases fall within the first two. What is the third one?Karina [00:49:34]: One of my weaknesses is like, I like writing long sentences. I feel like that's a good thing. Like I need to like learn how to.swyx [00:49:39]: That's fine. That's fine. Is that your definition of agents? Like what are you looking for?Karina [00:49:43]: I'm not sure if this is my definition of agents, but I feel like it's more like how I think it makes sense, right? Like I feel like for me to like trust an agent with my passwords or my credit card, I actually need to build trust with that agent that it will handle my tasks correctly and reliably. And the way I would go about this is how I would naturally like collaborate with other people. Is it like we first, even if it's any project, right, like we first came, when we first come, like we don't even know each other. Like we don't know how each other's like working style, like what I prefer, what do they prefer, how do they prefer to communicate, et cetera, et cetera. So like you spend like the first, like, I don't know, like two weeks to just like learn their style of working. And then like over time you adapt to their working style and then this is how you create the collaboration. And then like at the beginning you don't have much trust. So like how do you build more trust, especially like, it's the same thing as like with a manager, right? Like it's like, how do you build trust with your manager? What does they need to know about you? What do you need to know about them? Over time as you build trust and trust builds either through collaboration, which is why I feel like building Canvas was kind of like the first steps towards like more collaborative agents. I think with humans, so like you can, you should need to show a consistency. Yeah. Consistent effort to each other, like consistent effort that you care about each other is that you like work together very well or something. So consistency and like collaboration is like what creates trust. And then I will naturally will try to delegate tasks to a model because I know the model will not fail me or something. So it's kind of like building out like the intuition for the form factor of like new agents. Because sometimes I feel like a lot of researchers or like people in AI community are like so, into like, yeah, agents, delegate everything like blah, blah, blah, but like on the way towards that, I think like collaboration is actually one of the main roadblocks or like milestones to get over. Because then you will learn some of the implicit preferences that would help you, that would help towards like this full delegation model. Yeah.swyx [00:51:55]: Trust is very important. I have an AGI working for me and I, we're, we're still working on the trust issues. Okay. Um, we are recording this just before the launch of the podcast. We have a collaborative operator. The other side of agents that is very topical recently is computer use and topic launch computer use recently. Um, you know, you're not saying this, but opening is rumored to be working on things and like, there's a lot of labs are like exploring this, like sort of drive a computer generally. Um, how important is that for agents?Karina [00:52:23]: I think it would be one of the core capabilities of agents. Yeah. Computer using, oh, agents using desktop or like your computer is like the delegation part. So like when you might want to like delegate an agent to like order a book for me or like order a flight or like search for a flight and then order things. And I feel like this idea was flying around like for a long time since at least like 2022 or something. And finally we are here. It's just like there's a lot of like lag between idea and like full execution in the orders like two to three years.swyx [00:53:01]: The vision models had to get better. Yeah. A lot better.Karina [00:53:04]: The perception and something. But I think like it's really cool. I feel like it has like implications for like consumers definitely like delegation. But I guess again like I think like latency is like one of the most important factors here. It's like you don't want to make sure that the model correctly understands what you want. And then if it doesn't understand or if it doesn't know like full context, it should like ask for a follow up question and then like use that to perform the task. Like the agent should know if it has enough information to complete the task at the maximal, if it's a maximal success or not. And I think this is like still an open kind of like research question I feel like. Yeah. And the second idea is that like I think it also enables new class of like research questions of like computer use agents. Like can we use it in RL? Right. Like this is kind of like very cool like nascent area of like research.swyx [00:53:59]: What's one thing? What's one thing that you think by the end of this year people will be using computer use agents a lot for?Karina [00:54:05]: I don't know. It's really hard to predict. I'm trying to look for.swyx [00:54:09]: Maybe for coding.Karina [00:54:11]: I don't know.swyx [00:54:11]: For coding?Karina [00:54:12]: I think like right now like with Canvas we are thinking about like this paradigm of like real time collaboration to like asynchronous collaboration. So it's like it would be cool if I can just delegate to a model like, okay, can you figure out like how to do this feature or something? And then the model can just like. Test out that feature in its own like virtual environment or something. I don't know. Like maybe this is a weird idea. Obviously, there will be a lot of use cases around the consumers, the consumer use cases like, hey, like shop for me or something.swyx [00:54:43]: I was going to say, everyone goes to booking plane tickets. That's like the worst example because you only booked plane tickets, what, two or three times a year? Or like concert tickets.Karina [00:54:50]: I don't know. Yeah.swyx [00:54:51]: Concert tickets. Yeah.Karina [00:54:51]: Like Taylor Swift.swyx [00:54:52]: I want a Facebook marketplace bought that just scrolls Facebook marketplace for free stuff. Yeah. And then just go and get it. Yeah.Karina [00:55:00]: I have a question. I don't know. What do you think?swyx [00:55:01]: I have been very bearish in computer use because they're slow, they're expensive, they're imprecise, like the accuracy is horrible. Still, even with Anthopics new stuff, I'm really waiting to see what opening I might do to change my opinions. And really what I'm trying to do is like Jan last year versus December last year, I changed a lot of opinions. What am I wrong about today? And computer use is probably one of them where I'm like, I don't think, I don't know if by end of the year we'll still be using them. Will my ChatGPT have? Like every GPT instance, will they, will they have a virtual computer? Maybe? I don't know. Coding? Yes. Because he, he invested in a company that does, does that for the, the code sandboxes there. There are a bunch of code sandbox companies. E2B is the name. But then like in browsers, yes. Computer use is like coding plus browsers, plus everything else. There's a whole operating system and it's very like, you have to be pixel precise. You have to OCR. Well, I think OCR is basically solved, but like pixel precise and like understand the UI of what you're operating. And like, I don't know if the models are, I don't know. There you go.Karina [00:56:01]: Yeah. Yeah. Two questions. Like, do you think the progress of like mini models, like O3 mini or like O1 mini, I guess like it's came back to like the cloud, cloud 3 high cool, cloud 1.2 instant, like this like gradual progression of like small models becoming really powerful, which are very also like fast. Like I'm sure like the computer use agents like would be able to like couple with like those like small models that will solve some of the latency issues, in my opinion. I think in terms of like other operating system, I think a lot about it these days, it's just like, if you're entering this like task oriented, like operating system or something, where also a generative OS, like in my opinion, like people in like few years will click on like websites way less. I want to see the plot of like website clicks over time. But then my prediction is like, it will click. It will go down and like people's access to the internet will be through the model's lens. Either you see what the model is doing or you don't see what the model is doing on the internet. Yeah.Alessio [00:57:10]: I think my personal benchmark for computer use this year is expense reports. So I have to do my expense report every month. But what you need to do. So for example, I expense a lunch, I have to go back on the calendar and see who I was having lunch with. Then I need to upload the receipt of the lunch and I need to tag the person. The expense report, blah, blah, blah. Yeah. It's very simple on a task by task basis. Yeah. But like you have to go to every app. Right. That I use. You have to go to like the, you know, Uber app. You have to go to the camera roll to get the photo of the receipt, all these things. It's not, you cannot actually do it today, but it feels like a tractable problem. You know that probably by the end of the year we should be able to do it.Karina [00:57:49]: Yeah. This reminds me of like the idea of you kind of want to show to computer use agents how you would want. How you want or how you like booking your flights. It's kind of like a few shot. Yeah.swyx [00:58:03]: Demonstration.Karina [00:58:04]: Demonstrations of like maybe there is more efficient way that you do things that the model should learn to do it in that way. And so it's kind of like, again, comes back to like personalized tasks too is like right now task is just like where you're like rudimentary, but in the future tasks should become like much more personalized for your preferences.swyx [00:58:27]: Okay. Well, we mentioned that. Oh, I'll also say that I think one takeaway I got from your, this conversation is that ChatGPT will have to integrate a lot more with my life. Like you, you, you will need my calendar. You will need my email. Yes. Like for sure. And maybe you use MCP. I don't know. Have you, have you looked at MCP?Karina [00:58:43]: No, I haven't.swyx [00:58:44]: It's good. It's got a lot of adoption. Okay.Alessio [00:58:47]: Anything else that we're forgetting about or like maybe something that people should use more? Yeah. I don't know. Before we wrap on like the open AI side of things.Karina [00:58:56]: I think. I think like search product is kind of cool, like ChatGPT search. I think this idea of like, you know, like right now I'm thinking a lot of us, like, you know, the magic of ChatGPT when it first came out, it was like, you know, you ask something, any like instruction, and then like, it would like follow the instruction that you gave to a model, right? Like write a poem and we'll give you a poem. But I think like the magic of the next generation of ChatGPT is like actually, and we're like, we're marching towards that. It's like, when you ask a question, it's not just a question. It's not just going to be in the text output. The ideal output might be like in some form of like a react app on the fly or something. So like, this is happening with like search, right? Like give me like Apple stock and then it gives you the chart and gives you like this like generative UI. And I feel like this is what I mean by like the evolution of ChatGPT becomes like more of a generative OS with a task orientation or something. So it's like, and then UI will adapt to what you like. So like, if you really like 3D, what do you like? If you really like 3D visualizations, I think the model should give you as much visualization as possible. Like, you know, if you really like certain way of like the UIs, like maybe you like round corners. I don't know. It's just like some color schemes that you're like, it's just like the UI becomes like more dynamic and like becomes like a custom, custom model, like personal model, right? Like from personal computer to like a personal model, I think. Yeah.swyx [01:00:20]: Takes overall, you are one of the rare few people, actually, maybe not that rare. To work at both OpenAI and Anthropic.Karina [01:00:28]: Not anymore. Yeah.swyx [01:00:31]: Cultural difference. What are general takes that people like only like you see?Karina [01:00:35]: I love both places. I think I've learned so much at Anthropic and I'm really, really grateful to the people and I'm still like friends with a lot of people there. And I was really sad when John left OpenAI because I came to OpenAI because I wanted to work with the most or something. What's he doing now? But I think it changed a lot. So I think like... When I first joined Anthropic, they were like, I don't know, 60, 70 people. When they left, they were like 700 like people. So it's like a massive like growth. OpenAI and Anthropic is different in terms of like more like maybe like product mindset. Maybe OpenAI is much more willing to take some of the product risks and explore different bets. And I think Anthropic is much more focused and they have... I think it's fine. Like they have to like prioritize, but they definitely double down on like enterprise might be more than like consumers or something. I don't know. It's just like some of the product mindsets might be different. I would say like research, I've enjoyed like both like research cultures, both at Anthropic and like OpenAI. I feel like they are more... On the daily basis, I feel like it's more similar than different.swyx [01:01:50]: I mean, no surprise.Karina [01:01:52]: Like how you run experiments is kind of like very similar. I'm sure the Anthropic...swyx [01:01:55]: I mean, you know, Dario used to be VP research, right? So he set the culture at OpenAI. So yeah, it makes sense. Maybe quick takes on people that you mentioned. Barrett, you mentioned Mira. Like what's one thing you learned from Barrett, Mira, Sam, maybe? Something like that. Like one lesson that you would share to others.Karina [01:02:13]: I wish I like worked with them way longer. I think what I've learned from Mira is actually her like interdisciplinary mindset. She's really good at like connecting dots. Between like product and like kind of balancing like product research and like create this like comprehensive, like coherent story. Because sometimes like there are like researchers who like really hate doing product and there are researchers who really love doing product. And it's like kind of dichotomy between two and also like safety is like a part of this process. So kind of, you kind of want to like create this coherent, like think from like systems perspective. Or like think about like bigger picture. And I think I learned a lot from her on that. I definitely feel like I have much more creative freedom at OpenAI. And that's because the environment that the leaders set like enables me to do that. So it's like if I have an idea, if I want.swyx [01:03:10]: Propose it. Yeah, exactly. On your first month.Karina [01:03:11]: There's like more like creative freedom and like resource reallocation. Especially in research is like being adaptable to like new technologies and like change your views based on that. Yeah. Like you know, I've seen a lot of like researches that are like based on like empirical results or kind of like change the research directions. I've seen a lot of like, sometimes I've seen researchers who would just like get stuck on the same directions for like two to three years and they would never like work out or something, but they would still be like stubborn. So it's like adaptability to like new directions and like new paradigms. It's kind of like one of those things that-Alessio [01:03:42]: This is a Barrett thing or this is a general culture thing?Karina [01:03:45]: A general kind of culture, I think. Cool.Alessio [01:03:46]: Yeah. And just to wrap up, we just usually have a call to action.Alessio [01:03:52]: Do you want people to give you feedback? Do you want people to join your team?Karina [01:03:56]: Oh yeah, of course. I'm definitely hiring for like research engineers who are like more product minded people. So it's like people who know how to train the models, but also like interested in like deploying into like the products and developing like new product features. I'm definitely looking for those archetypes of like research engineers or like research scientists. So yeah. If you're like looking for a job, if you're like interested in joining my team, I'm like really looking forward to that. I'm definitely happy to just reach out, I guess.swyx [01:04:24]: And then just like generally, what do you want people to do more of in the world, whether or not they work with you, like, you know, call to action as in like everyone should be doing this.Karina [01:04:32]: I think this is something that I tell to a lot of like designers is that like, I think people should like spend more time just like play around with the models. And the more you play with a model, the more creative ideas you'll get around like what kind of like new potential features of the products or like new kinds of things. Kind of like interaction paradigms that you might want to create with those models. I feel like we are bottlenecked by like human creativity on like completely changing the way we think about the internet or like some of the, the way you think about software, like AI right now is pushes us to like rethink everything that we've done before in my view. And I feel like not enough people are either double down on like those ideas or I'm just like not seeing a lot of like human creativity in this like. Interface design or like product design mindsets. So I feel like it'd be really great for people to just like do that. And especially right now it's like research, some research becomes like much more product oriented. So it's like you actually can train the models for the things that you want to do in a product or something. Yeah.swyx [01:05:41]: And you define the process now. Now this is my go-to for how to manage a process. I think it's pretty common sense, but it's nice to hear from you that cause you actually did it. That's nice. Thank you for driving innovation, interface design and the new models at OpenAI and Anthropic. And we're looking forward to what you're going to talk about in New York. Yeah.Karina [01:06:01]: Thank you so much for inviting me here. I hope my job will not be automated by the time.swyx [01:06:06]: Well, I hope you automate yourself and we'll do whatever else you want to do. That's it. Thank you. Awesome. Thanks. Get full access to Latent.Space at www.latent.space/subscribe
-
 Outlasting Noam Shazeer, crowdsourcing Chat + AI with >1.4m DAU, and becoming the "Western DeepSeek" — with William Beauchamp, Chai Research
Outlasting Noam Shazeer, crowdsourcing Chat + AI with >1.4m DAU, and becoming the "Western DeepSeek" — with William Beauchamp, Chai ResearchFrom 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2025-01-26 03:17
One last Gold sponsor slot is available for the AI Engineer Summit in NYC. Our last round of invites is going out soon - apply here - If you are building AI agents or AI eng teams, this will be the single highest-signal conference of the year for you!While the world melts down over DeepSeek, few are talking about the OTHER notable group of former hedge fund traders who pivoted into AI and built a remarkably profitable consumer AI business with a tiny team with incredibly cracked engineering team — Chai Research. In short order they have:* Started a Chat AI company well before Noam Shazeer started Character AI, and outlasted his departure.* Crossed 1m DAU in 2.5 years - William updates us on the pod that they’ve hit 1.4m DAU now, another +40% from a few months ago. Revenue crossed >$22m. * Launched the Chaiverse model crowdsourcing platform - taking 3-4 week A/B testing cycles down to 3-4 hours, and deploying >100 models a week.While they’re not paying million dollar salaries, you can tell they’re doing pretty well for an 11 person startup:The Chai Recipe: Building infra for rapid evalsRemember how the central thesis of LMarena (formerly LMsys) is that the only comprehensive way to evaluate LLMs is to let users try them out and pick winners?At the core of Chai is a mobile app that looks like Character AI, but is actually the largest LLM A/B testing arena in the world, specialized on retaining chat users for Chai’s usecases (therapy, assistant, roleplay, etc). It’s basically what LMArena would be if taken very, very seriously at one company (with $1m in prizes to boot):Chai publishes occasional research on how they think about this, including talks at their Palo Alto office:William expands upon this in today’s podcast (34 mins in):Fundamentally, the way I would describe it is when you're building anything in life, you need to be able to evaluate it. And through evaluation, you can iterate, we can look at benchmarks, and we can say the issues with benchmarks and why they may not generalize as well as one would hope in the challenges of working with them. But something that works incredibly well is getting feedback from humans. And so we built this thing where anyone can submit a model to our developer backend, and it gets put in front of 5000 users, and the users can rate it. And we can then have a really accurate ranking of like which model, or users finding more engaging or more entertaining. And it gets, you know, it's at this point now, where every day we're able to, I mean, we evaluate between 20 and 50 models, LLMs, every single day, right. So even though we've got only got a team of, say, five AI researchers, they're able to iterate a huge quantity of LLMs, right. So our team ships, let's just say minimum 100 LLMs a week is what we're able to iterate through. Now, before that moment in time, we might iterate through three a week, we might, you know, there was a time when even doing like five a month was a challenge, right? By being able to change the feedback loops to the point where it's not, let's launch these three models, let's do an A-B test, let's assign, let's do different cohorts, let's wait 30 days to see what the day 30 retention is, which is the kind of the, if you're doing an app, that's like A-B testing 101 would be, do a 30-day retention test, assign different treatments to different cohorts and come back in 30 days. So that's insanely slow. That's just, it's too slow. And so we were able to get that 30-day feedback loop all the way down to something like three hours.In Crowdsourcing the leap to Ten Trillion-Parameter AGI, William describes Chai’s routing as a recommender system, which makes a lot more sense to us than previous pitches for model routing startups:William is notably counter-consensus in a lot of his AI product principles:* No streaming: Chats appear all at once to allow rejection sampling* No voice: Chai actually beat Character AI to introducing voice - but removed it after finding that it was far from a killer feature.* Blending: “Something that we love to do at Chai is blending, which is, you know, it's the simplest way to think about it is you're going to end up, and you're going to pretty quickly see you've got one model that's really smart, one model that's really funny. How do you get the user an experience that is both smart and funny? Well, just 50% of the requests, you can serve them the smart model, 50% of the requests, you serve them the funny model.” (that’s it!)But chief above all is the recommender system.We also referenced Exa CEO Will Bryk’s concept of SuperKnowlege:Full Video versionOn YouTube. please like and subscribe!Timestamps* 00:00:04 Introductions and background of William Beauchamp* 00:01:19 Origin story of Chai AI* 00:04:40 Transition from finance to AI* 00:11:36 Initial product development and idea maze for Chai* 00:16:29 User psychology and engagement with AI companions* 00:20:00 Origin of the Chai name* 00:22:01 Comparison with Character AI and funding challenges* 00:25:59 Chai's growth and user numbers* 00:34:53 Key inflection points in Chai's growth* 00:42:10 Multi-modality in AI companions and focus on user-generated content* 00:46:49 Chaiverse developer platform and model evaluation* 00:51:58 Views on AGI and the nature of AI intelligence* 00:57:14 Evaluation methods and human feedback in AI development* 01:02:01 Content creation and user experience in Chai* 01:04:49 Chai Grant program and company culture* 01:07:20 Inference optimization and compute costs* 01:09:37 Rejection sampling and reward models in AI generation* 01:11:48 Closing thoughts and recruitmentTranscriptAlessio [00:00:04]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel, and today we're in the Chai AI office with my usual co-host, Swyx.swyx [00:00:14]: Hey, thanks for having us. It's rare that we get to get out of the office, so thanks for inviting us to your home. We're in the office of Chai with William Beauchamp. Yeah, that's right. You're founder of Chai AI, but previously, I think you're concurrently also running your fund?William [00:00:29]: Yep, so I was simultaneously running an algorithmic trading company, but I fortunately was able to kind of exit from that, I think just in Q3 last year. Yeah, congrats. Yeah, thanks.swyx [00:00:43]: So Chai has always been on my radar because, well, first of all, you do a lot of advertising, I guess, in the Bay Area, so it's working. Yep. And second of all, the reason I reached out to a mutual friend, Joyce, was because I'm just generally interested in the... ...consumer AI space, chat platforms in general. I think there's a lot of inference insights that we can get from that, as well as human psychology insights, kind of a weird blend of the two. And we also share a bit of a history as former finance people crossing over. I guess we can just kind of start it off with the origin story of Chai.William [00:01:19]: Why decide working on a consumer AI platform rather than B2B SaaS? So just quickly touching on the background in finance. Sure. Originally, I'm from... I'm from the UK, born in London. And I was fortunate enough to go study economics at Cambridge. And I graduated in 2012. And at that time, everyone in the UK and everyone on my course, HFT, quant trading was really the big thing. It was like the big wave that was happening. So there was a lot of opportunity in that space. And throughout college, I'd sort of played poker. So I'd, you know, I dabbled as a professional poker player. And I was able to accumulate this sort of, you know, say $100,000 through playing poker. And at the time, as my friends would go work at companies like ChangeStreet or Citadel, I kind of did the maths. And I just thought, well, maybe if I traded my own capital, I'd probably come out ahead. I'd make more money than just going to work at ChangeStreet.swyx [00:02:20]: With 100k base as capital?William [00:02:22]: Yes, yes. That's not a lot. Well, it depends what strategies you're doing. And, you know, there is an advantage. There's an advantage to being small, right? Because there are, if you have a 10... Strategies that don't work in size. Exactly, exactly. So if you have a fund of $10 million, if you find a little anomaly in the market that you might be able to make 100k a year from, that's a 1% return on your 10 million fund. If your fund is 100k, that's 100% return, right? So being small, in some sense, was an advantage. So started off, and the, taught myself Python, and machine learning was like the big thing as well. Machine learning had really, it was the first, you know, big time machine learning was being used for image recognition, neural networks come out, you get dropout. And, you know, so this, this was the big thing that's going on at the time. So I probably spent my first three years out of Cambridge, just building neural networks, building random forests to try and predict asset prices, right, and then trade that using my own money. And that went well. And, you know, if you if you start something, and it goes well, you You try and hire more people. And the first people that came to mind was the talented people I went to college with. And so I hired some friends. And that went well and hired some more. And eventually, I kind of ran out of friends to hire. And so that was when I formed the company. And from that point on, we had our ups and we had our downs. And that was a whole long story and journey in itself. But after doing that for about eight or nine years, on my 30th birthday, which was four years ago now, I kind of took a step back to just evaluate my life, right? This is what one does when one turns 30. You know, I just heard it. I hear you. And, you know, I looked at my 20s and I loved it. It was a really special time. I was really lucky and fortunate to have worked with this amazing team, been successful, had a lot of hard times. And through the hard times, learned wisdom and then a lot of success and, you know, was able to enjoy it. And so the company was making about five million pounds a year. And it was just me and a team of, say, 15, like, Oxford and Cambridge educated mathematicians and physicists. It was like the real dream that you'd have if you wanted to start a quant trading firm. It was like...swyx [00:04:40]: Your own, all your own money?William [00:04:41]: Yeah, exactly. It was all the team's own money. We had no customers complaining to us about issues. There's no investors, you know, saying, you know, they don't like the risk that we're taking. We could. We could really run the thing exactly as we wanted it. It's like Susquehanna or like Rintec. Yeah, exactly. Yeah. And they're the companies that we would kind of look towards as we were building that thing out. But on my 30th birthday, I look and I say, OK, great. This thing is making as much money as kind of anyone would really need. And I thought, well, what's going to happen if we keep going in this direction? And it was clear that we would never have a kind of a big, big impact on the world. We can enrich ourselves. We can make really good money. Everyone on the team would be paid very, very well. Presumably, I can make enough money to buy a yacht or something. But this stuff wasn't that important to me. And so I felt a sort of obligation that if you have this much talent and if you have a talented team, especially as a founder, you want to be putting all that talent towards a good use. I looked at the time of like getting into crypto and I had a really strong view on crypto, which was that as far as a gambling device. This is like the most fun form of gambling invented in like ever super fun, I thought as a way to evade monetary regulations and banking restrictions. I think it's also absolutely amazing. So it has two like killer use cases, not so much banking the unbanked, but everything else, but everything else to do with like the blockchain and, and you know, web, was it web 3.0 or web, you know, that I, that didn't, it didn't really make much sense. And so instead of going into crypto, which I thought, even if I was successful, I'd end up in a lot of trouble. I thought maybe it'd be better to build something that governments wouldn't have a problem with. I knew that LLMs were like a thing. I think opening. I had said they hadn't released GPT-3 yet, but they'd said GPT-3 is so powerful. We can't release it to the world or something. Was it GPT-2? And then I started interacting with, I think Google had open source, some language models. They weren't necessarily LLMs, but they, but they were. But yeah, exactly. So I was able to play around with, but nowadays so many people have interacted with the chat GPT, they get it, but it's like the first time you, you can just talk to a computer and it talks back. It's kind of a special moment and you know, everyone who's done that goes like, wow, this is how it should be. Right. It should be like, rather than having to type on Google and search, you should just be able to ask Google a question. When I saw that I read the literature, I kind of came across the scaling laws and I think even four years ago. All the pieces of the puzzle were there, right? Google had done this amazing research and published, you know, a lot of it. Open AI was still open. And so they'd published a lot of their research. And so you really could be fully informed on, on the state of AI and where it was going. And so at that point I was confident enough, it was worth a shot. I think LLMs are going to be the next big thing. And so that's the thing I want to be building in, in that space. And I thought what's the most impactful product I can possibly build. And I thought it should be a platform. So I myself love platforms. I think they're fantastic because they open up an ecosystem where anyone can contribute to it. Right. So if you think of a platform like a YouTube, instead of it being like a Hollywood situation where you have to, if you want to make a TV show, you have to convince Disney to give you the money to produce it instead, anyone in the world can post any content they want to YouTube. And if people want to view it, the algorithm is going to promote it. Nowadays. You can look at creators like Mr. Beast or Joe Rogan. They would have never have had that opportunity unless it was for this platform. Other ones like Twitter's a great one, right? But I would consider Wikipedia to be a platform where instead of the Britannica encyclopedia, which is this, it's like a monolithic, you get all the, the researchers together, you get all the data together and you combine it in this, in this one monolithic source. Instead. You have this distributed thing. You can say anyone can host their content on Wikipedia. Anyone can contribute to it. And anyone can maybe their contribution is they delete stuff. When I was hearing like the kind of the Sam Altman and kind of the, the Muskian perspective of AI, it was a very kind of monolithic thing. It was all about AI is basically a single thing, which is intelligence. Yeah. Yeah. The more intelligent, the more compute, the more intelligent, and the more and better AI researchers, the more intelligent, right? They would speak about it as a kind of erased, like who can get the most data, the most compute and the most researchers. And that would end up with the most intelligent AI. But I didn't believe in any of that. I thought that's like the total, like I thought that perspective is the perspective of someone who's never actually done machine learning. Because with machine learning, first of all, you see that the performance of the models follows an S curve. So it's not like it just goes off to infinity, right? And the, the S curve, it kind of plateaus around human level performance. And you can look at all the, all the machine learning that was going on in the 2010s, everything kind of plateaued around the human level performance. And we can think about the self-driving car promises, you know, how Elon Musk kept saying the self-driving car is going to happen next year, it's going to happen next, next year. Or you can look at the image recognition, the speech recognition. You can look at. All of these things, there was almost nothing that went superhuman, except for something like AlphaGo. And we can speak about why AlphaGo was able to go like super superhuman. So I thought the most likely thing was going to be this, I thought it's not going to be a monolithic thing. That's like an encyclopedia Britannica. I thought it must be a distributed thing. And I actually liked to look at the world of finance for what I think a mature machine learning ecosystem would look like. So, yeah. So finance is a machine learning ecosystem because all of these quant trading firms are running machine learning algorithms, but they're running it on a centralized platform like a marketplace. And it's not the case that there's one giant quant trading company of all the data and all the quant researchers and all the algorithms and compute, but instead they all specialize. So one will specialize on high frequency training. Another will specialize on mid frequency. Another one will specialize on equity. Another one will specialize. And I thought that's the way the world works. That's how it is. And so there must exist a platform where a small team can produce an AI for a unique purpose. And they can iterate and build the best thing for that, right? And so that was the vision for Chai. So we wanted to build a platform for LLMs.Alessio [00:11:36]: That's kind of the maybe inside versus contrarian view that led you to start the company. Yeah. And then what was maybe the initial idea maze? Because if somebody told you that was the Hugging Face founding story, people might believe it. It's kind of like a similar ethos behind it. How did you land on the product feature today? And maybe what were some of the ideas that you discarded that initially you thought about?William [00:11:58]: So the first thing we built, it was fundamentally an API. So nowadays people would describe it as like agents, right? But anyone could write a Python script. They could submit it to an API. They could send it to the Chai backend and we would then host this code and execute it. So that's like the developer side of the platform. On their Python script, the interface was essentially text in and text out. An example would be the very first bot that I created. I think it was a Reddit news bot. And so it would first, it would pull the popular news. Then it would prompt whatever, like I just use some external API for like Burr or GPT-2 or whatever. Like it was a very, very small thing. And then the user could talk to it. So you could say to the bot, hi bot, what's the news today? And it would say, this is the top stories. And you could chat with it. Now four years later, that's like perplexity or something. That's like the, right? But back then the models were first of all, like really, really dumb. You know, they had an IQ of like a four year old. And users, there really wasn't any demand or any PMF for interacting with the news. So then I was like, okay. Um. So let's make another one. And I made a bot, which was like, you could talk to it about a recipe. So you could say, I'm making eggs. Like I've got eggs in my fridge. What should I cook? And it'll say, you should make an omelet. Right. There was no PMF for that. No one used it. And so I just kept creating bots. And so every single night after work, I'd be like, okay, I like, we have AI, we have this platform. I can create any text in textile sort of agent and put it on the platform. And so we just create stuff night after night. And then all the coders I knew, I would say, yeah, this is what we're going to do. And then I would say to them, look, there's this platform. You can create any like chat AI. You should put it on. And you know, everyone's like, well, chatbots are super lame. We want absolutely nothing to do with your chatbot app. No one who knew Python wanted to build on it. I'm like trying to build all these bots and no consumers want to talk to any of them. And then my sister who at the time was like just finishing college or something, I said to her, I was like, if you want to learn Python, you should just submit a bot for my platform. And she, she built a therapy for me. And I was like, okay, cool. I'm going to build a therapist bot. And then the next day I checked the performance of the app and I'm like, oh my God, we've got 20 active users. And they spent, they spent like an average of 20 minutes on the app. I was like, oh my God, what, what bot were they speaking to for an average of 20 minutes? And I looked and it was the therapist bot. And I went, oh, this is where the PMF is. There was no demand for, for recipe help. There was no demand for news. There was no demand for dad jokes or pub quiz or fun facts or what they wanted was they wanted the therapist bot. the time I kind of reflected on that and I thought, well, if I want to consume news, the most fun thing, most fun way to consume news is like Twitter. It's not like the value of there being a back and forth, wasn't that high. Right. And I thought if I need help with a recipe, I actually just go like the New York times has a good recipe section, right? It's not actually that hard. And so I just thought the thing that AI is 10 X better at is a sort of a conversation right. That's not intrinsically informative, but it's more about an opportunity. You can say whatever you want. You're not going to get judged. If it's 3am, you don't have to wait for your friend to text back. It's like, it's immediate. They're going to reply immediately. You can say whatever you want. It's judgment-free and it's much more like a playground. It's much more like a fun experience. And you could see that if the AI gave a person a compliment, they would love it. It's much easier to get the AI to give you a compliment than a human. From that day on, I said, okay, I get it. Humans want to speak to like humans or human like entities and they want to have fun. And that was when I started to look less at platforms like Google. And I started to look more at platforms like Instagram. And I was trying to think about why do people use Instagram? And I could see that I think Chai was, was filling the same desire or the same drive. If you go on Instagram, typically you want to look at the faces of other humans, or you want to hear about other people's lives. So if it's like the rock is making himself pancakes on a cheese plate. You kind of feel a little bit like you're the rock's friend, or you're like having pancakes with him or something, right? But if you do it too much, you feel like you're sad and like a lonely person, but with AI, you can talk to it and tell it stories and tell you stories, and you can play with it for as long as you want. And you don't feel like you're like a sad, lonely person. You feel like you actually have a friend.Alessio [00:16:29]: And what, why is that? Do you have any insight on that from using it?William [00:16:33]: I think it's just the human psychology. I think it's just the idea that, with old school social media. You're just consuming passively, right? So you'll just swipe. If I'm watching TikTok, just like swipe and swipe and swipe. And even though I'm getting the dopamine of like watching an engaging video, there's this other thing that's building my head, which is like, I'm feeling lazier and lazier and lazier. And after a certain period of time, I'm like, man, I just wasted 40 minutes. I achieved nothing. But with AI, because you're interacting, you feel like you're, it's not like work, but you feel like you're participating and contributing to the thing. You don't feel like you're just. Consuming. So you don't have a sense of remorse basically. And you know, I think on the whole people, the way people talk about, try and interact with the AI, they speak about it in an incredibly positive sense. Like we get people who say they have eating disorders saying that the AI helps them with their eating disorders. People who say they're depressed, it helps them through like the rough patches. So I think there's something intrinsically healthy about interacting that TikTok and Instagram and YouTube doesn't quite tick. From that point on, it was about building more and more kind of like human centric AI for people to interact with. And I was like, okay, let's make a Kanye West bot, right? And then no one wanted to talk to the Kanye West bot. And I was like, ah, who's like a cool persona for teenagers to want to interact with. And I was like, I was trying to find the influencers and stuff like that, but no one cared. Like they didn't want to interact with the, yeah. And instead it was really just the special moment was when we said the realization that developers and software engineers aren't interested in building this sort of AI, but the consumers are right. And rather than me trying to guess every day, like what's the right bot to submit to the platform, why don't we just create the tools for the users to build it themselves? And so nowadays this is like the most obvious thing in the world, but when Chai first did it, it was not an obvious thing at all. Right. Right. So we took the API for let's just say it was, I think it was GPTJ, which was this 6 billion parameter open source transformer style LLM. We took GPTJ. We let users create the prompt. We let users select the image and we let users choose the name. And then that was the bot. And through that, they could shape the experience, right? So if they said this bot's going to be really mean, and it's going to be called like bully in the playground, right? That was like a whole category that I never would have guessed. Right. People love to fight. They love to have a disagreement, right? And then they would create, there'd be all these romantic archetypes that I didn't know existed. And so as the users could create the content that they wanted, that was when Chai was able to, to get this huge variety of content and rather than appealing to, you know, 1% of the population that I'd figured out what they wanted, you could appeal to a much, much broader thing. And so from that moment on, it was very, very crystal clear. It's like Chai, just as Instagram is this social media platform that lets people create images and upload images, videos and upload that, Chai was really about how can we let the users create this experience in AI and then share it and interact and search. So it's really, you know, I say it's like a platform for social AI.Alessio [00:20:00]: Where did the Chai name come from? Because you started the same path. I was like, is it character AI shortened? You started at the same time, so I was curious. The UK origin was like the second, the Chai.William [00:20:15]: We started way before character AI. And there's an interesting story that Chai's numbers were very, very strong, right? So I think in even 20, I think late 2022, was it late 2022 or maybe early 2023? Chai was like the number one AI app in the app store. So we would have something like 100,000 daily active users. And then one day we kind of saw there was this website. And we were like, oh, this website looks just like Chai. And it was the character AI website. And I think that nowadays it's, I think it's much more common knowledge that when they left Google with the funding, I think they knew what was the most trending, the number one app. And I think they sort of built that. Oh, you found the people.swyx [00:21:03]: You found the PMF for them.William [00:21:04]: We found the PMF for them. Exactly. Yeah. So I worked a year very, very hard. And then they, and then that was when I learned a lesson, which is that if you're VC backed and if, you know, so Chai, we'd kind of ran, we'd got to this point, I was the only person who'd invested. I'd invested maybe 2 million pounds in the business. And you know, from that, we were able to build this thing, get to say a hundred thousand daily active users. And then when character AI came along, the first version, we sort of laughed. We were like, oh man, this thing sucks. Like they don't know what they're building. They're building the wrong thing anyway, but then I saw, oh, they've raised a hundred million dollars. Oh, they've raised another hundred million dollars. And then our users started saying, oh guys, your AI sucks. Cause we were serving a 6 billion parameter model, right? How big was the model that character AI could afford to serve, right? So we would be spending, let's say we would spend a dollar per per user, right? Over the, the, you know, the entire lifetime.swyx [00:22:01]: A dollar per session, per chat, per month? No, no, no, no.William [00:22:04]: Let's say we'd get over the course of the year, we'd have a million users and we'd spend a million dollars on the AI throughout the year. Right. Like aggregated. Exactly. Exactly. Right. They could spend a hundred times that. So people would say, why is your AI much dumber than character AIs? And then I was like, oh, okay, I get it. This is like the Silicon Valley style, um, hyper scale business. And so, yeah, we moved to Silicon Valley and, uh, got some funding and iterated and built the flywheels. And, um, yeah, I, I'm very proud that we were able to compete with that. Right. So, and I think the reason we were able to do it was just customer obsession. And it's similar, I guess, to how deep seek have been able to produce such a compelling model when compared to someone like an open AI, right? So deep seek, you know, their latest, um, V2, yeah, they claim to have spent 5 million training it.swyx [00:22:57]: It may be a bit more, but, um, like, why are you making it? Why are you making such a big deal out of this? Yeah. There's an agenda there. Yeah. You brought up deep seek. So we have to ask you had a call with them.William [00:23:07]: We did. We did. We did. Um, let me think what to say about that. I think for one, they have an amazing story, right? So their background is again in finance.swyx [00:23:16]: They're the Chinese version of you. Exactly.William [00:23:18]: Well, there's a lot of similarities. Yes. Yes. I have a great affinity for companies which are like, um, founder led, customer obsessed and just try and build something great. And I think what deep seek have achieved. There's quite special is they've got this amazing inference engine. They've been able to reduce the size of the KV cash significantly. And then by being able to do that, they're able to significantly reduce their inference costs. And I think with kind of with AI, people get really focused on like the kind of the foundation model or like the model itself. And they sort of don't pay much attention to the inference. To give you an example with Chai, let's say a typical user session is 90 minutes, which is like, you know, is very, very long for comparison. Let's say the average session length on TikTok is 70 minutes. So people are spending a lot of time. And in that time they're able to send say 150 messages. That's a lot of completions, right? It's quite different from an open AI scenario where people might come in, they'll have a particular question in mind. And they'll ask like one question. And a few follow up questions, right? So because they're consuming, say 30 times as many requests for a chat, or a conversational experience, you've got to figure out how to how to get the right balance between the cost of that and the quality. And so, you know, I think with AI, it's always been the case that if you want a better experience, you can throw compute at the problem, right? So if you want a better model, you can just make it bigger. If you want it to remember better, give it a longer context. And now, what open AI is doing to great fanfare is with projection sampling, you can generate many candidates, right? And then with some sort of reward model or some sort of scoring system, you can serve the most promising of these many candidates. And so that's kind of scaling up on the inference time compute side of things. And so for us, it doesn't make sense to think of AI is just the absolute performance. So. But what we're seeing, it's like the MML you score or the, you know, any of these benchmarks that people like to look at, if you just get that score, it doesn't really tell tell you anything. Because it's really like progress is made by improving the performance per dollar. And so I think that's an area where deep seek have been able to form very, very well, surprisingly so. And so I'm very interested in what Lama four is going to look like. And if they're able to sort of match what deep seek have been able to achieve with this performance per dollar gain.Alessio [00:25:59]: Before we go into the inference, some of the deeper stuff, can you give people an overview of like some of the numbers? So I think last I checked, you have like 1.4 million daily active now. It's like over 22 million of revenue. So it's quite a business.William [00:26:12]: Yeah, I think we grew by a factor of, you know, users grew by a factor of three last year. Revenue over doubled. You know, it's very exciting. We're competing with some really big, really well funded companies. Character AI got this, I think it was almost a $3 billion valuation. And they have 5 million DAU is a number that I last heard. Torquay, which is a Chinese built app owned by a company called Minimax. They're incredibly well funded. And these companies didn't grow by a factor of three last year. Right. And so when you've got this company and this team that's able to keep building something that gets users excited, and they want to tell their friend about it, and then they want to come and they want to stick on the platform. I think that's very special. And so last year was a great year for the team. And yeah, I think the numbers reflect the hard work that we put in. And then fundamentally, the quality of the app, the quality of the content, the quality of the content, the quality of the content, the quality of the content, the quality of the content. AI is the quality of the experience that you have. You actually published your DAU growth chart, which is unusual. And I see some inflections. Like, it's not just a straight line. There's some things that actually inflect. Yes. What were the big ones? Cool. That's a great, great, great question. Let me think of a good answer. I'm basically looking to annotate this chart, which doesn't have annotations on it. Cool. The first thing I would say is this is, I think the most important thing to know about success is that success is born out of failures. Right? Through failures that we learn. You know, if you think something's a good idea, and you do and it works, great, but you didn't actually learn anything, because everything went exactly as you imagined. But if you have an idea, you think it's going to be good, you try it, and it fails. There's a gap between the reality and expectation. And that's an opportunity to learn. The flat periods, that's us learning. And then the up periods is that's us reaping the rewards of that. So I think the big, of the growth shot of just 2024, I think the first thing that really kind of put a dent in our growth was our backend. So we just reached this scale. So we'd, from day one, we'd built on top of Google's GCP, which is Google's cloud platform. And they were fantastic. We used them when we had one daily active user, and they worked pretty good all the way up till we had about 500,000. It was never the cheapest, but from an engineering perspective, man, that thing scaled insanely good. Like, not Vertex? Not Vertex. Like GKE, that kind of stuff? We use Firebase. So we use Firebase. I'm pretty sure we're the biggest user ever on Firebase. That's expensive. Yeah, we had calls with engineers, and they're like, we wouldn't recommend using this product beyond this point, and you're 3x over that. So we pushed Google to their absolute limits. You know, it was fantastic for us, because we could focus on the AI. We could focus on just adding as much value as possible. But then what happened was, after 500,000, just the thing, the way we were using it, and it would just, it wouldn't scale any further. And so we had a really, really painful, at least three-month period, as we kind of migrated between different services, figuring out, like, what requests do we want to keep on Firebase, and what ones do we want to move on to something else? And then, you know, making mistakes. And learning things the hard way. And then after about three months, we got that right. So that, we would then be able to scale to the 1.5 million DAE without any further issues from the GCP. But what happens is, if you have an outage, new users who go on your app experience a dysfunctional app, and then they're going to exit. And so your next day, the key metrics that the app stores track are going to be something like retention rates. And so your next day, the key metrics that the app stores track are going to be something like retention rates. Money spent, and the star, like, the rating that they give you. In the app store. In the app store, yeah. Tyranny. So if you're ranked top 50 in entertainment, you're going to acquire a certain rate of users organically. If you go in and have a bad experience, it's going to tank where you're positioned in the algorithm. And then it can take a long time to kind of earn your way back up, at least if you wanted to do it organically. If you throw money at it, you can jump to the top. And I could talk about that. But broadly speaking, if we look at 2024, the first kink in the graph was outages due to hitting 500k DAU. The backend didn't want to scale past that. So then we just had to do the engineering and build through it. Okay, so we built through that, and then we get a little bit of growth. And so, okay, that's feeling a little bit good. I think the next thing, I think it's, I'm not going to lie, I have a feeling that when Character AI got... I was thinking. I think so. I think... So the Character AI team fundamentally got acquired by Google. And I don't know what they changed in their business. I don't know if they dialed down that ad spend. Products don't change, right? Products just what it is. I don't think so. Yeah, I think the product is what it is. It's like maintenance mode. Yes. I think the issue that people, you know, some people may think this is an obvious fact, but running a business can be very competitive, right? Because other businesses can see what you're doing, and they can imitate you. And then there's this... There's this question of, if you've got one company that's spending $100,000 a day on advertising, and you've got another company that's spending zero, if you consider market share, and if you're considering new users which are entering the market, the guy that's spending $100,000 a day is going to be getting 90% of those new users. And so I have a suspicion that when the founders of Character AI left, they dialed down their spending on user acquisition. And I think that kind of gave oxygen to like the other apps. And so Chai was able to then start growing again in a really healthy fashion. I think that's kind of like the second thing. I think a third thing is we've really built a great data flywheel. Like the AI team sort of perfected their flywheel, I would say, in end of Q2. And I could speak about that at length. But fundamentally, the way I would describe it is when you're building anything in life, you need to be able to evaluate it. And through evaluation, you can iterate, we can look at benchmarks, and we can say the issues with benchmarks and why they may not generalize as well as one would hope in the challenges of working with them. But something that works incredibly well is getting feedback from humans. And so we built this thing where anyone can submit a model to our developer backend, and it gets put in front of 5000 users, and the users can rate it. And we can then have a really accurate ranking of like which model, or users finding more engaging or more entertaining. And it gets, you know, it's at this point now, where every day we're able to, I mean, we evaluate between 20 and 50 models, LLMs, every single day, right. So even though we've got only got a team of, say, five AI researchers, they're able to iterate a huge quantity of LLMs, right. So our team ships, let's just say minimum 100 LLMs a week is what we're able to iterate through. Now, before that moment in time, we might iterate through three a week, we might, you know, there was a time when even doing like five a month was a challenge, right? By being able to change the feedback loops to the point where it's not, let's launch these three models, let's do an A-B test, let's assign, let's do different cohorts, let's wait 30 days to see what the day 30 retention is, which is the kind of the, if you're doing an app, that's like A-B testing 101 would be, do a 30-day retention test, assign different treatments to different cohorts and come back in 30 days. So that's insanely slow. That's just, it's too slow. And so we were able to get that 30-day feedback loop all the way down to something like three hours. And when we did that, we could really, really, really perfect techniques like DPO, fine tuning, prompt engineering, blending, rejection sampling, training a reward model, right, really successfully, like boom, boom, boom, boom, boom. And so I think in Q3 and Q4, we got, the amount of AI improvements we got was like astounding. It was getting to the point, I thought like how much more, how much more edge is there to be had here? But the team just could keep going and going and going. That was like number three for the inflection point.swyx [00:34:53]: There's a fourth?William [00:34:54]: The important thing about the third one is if you go on our Reddit or you talk to users of AI, there's like a clear date. It's like somewhere in October or something. The users, they flipped. Before October, the users... The users would say character AI is better than you, for the most part. Then from October onwards, they would say, wow, you guys are better than character AI. And that was like a really clear positive signal that we'd sort of done it. And I think people, you can't cheat consumers. You can't trick them. You can't b******t them. They know, right? If you're going to spend 90 minutes on a platform, and with apps, there's the barriers to switching is pretty low. Like you can try character AI, you can't cheat consumers. You can't cheat them. You can't cheat them. You can't cheat AI for a day. If you get bored, you can try Chai. If you get bored of Chai, you can go back to character. So the users, the loyalty is not strong, right? What keeps them on the app is the experience. If you deliver a better experience, they're going to stay and they can tell. So that was the fourth one was we were fortunate enough to get this hire. He was hired one really talented engineer. And then they said, oh, at my last company, we had a head of growth. He was really, really good. And he was the head of growth for ByteDance for two years. Would you like to speak to him? And I was like, yes. Yes, I think I would. And so I spoke to him. And he just blew me away with what he knew about user acquisition. You know, it was like a 3D chessswyx [00:36:21]: sort of thing. You know, as much as, as I know about AI. Like ByteDance as in TikTok US. Yes.William [00:36:26]: Not ByteDance as other stuff. Yep. He was interviewing us as we were interviewing him. Right. And so pick up options. Yeah, exactly. And so he was kind of looking at our metrics. And he was like, I saw him get really excited when he said, guys, you've got a million daily active users and you've done no advertising. I said, correct. And he was like, that's unheard of. He's like, I've never heard of anyone doing that. And then he started looking at our metrics. And he was like, if you've got all of this organically, if you start spending money, this is going to be very exciting. I was like, let's give it a go. So then he came in, we've just started ramping up the user acquisition. So that looks like spending, you know, let's say we're spending, we started spending $20,000 a day, it looked very promising than 20,000. Right now we're spending $40,000 a day on user acquisition. That's still only half of what like character AI or talkie may be spending. But from that, it's sort of, we were growing at a rate of maybe say, 2x a year. And that got us growing at a rate of 3x a year. So I'm growing, I'm evolving more and more to like a Silicon Valley style hyper growth, like, you know, you build something decent, and then you canswyx [00:37:33]: slap on a huge... You did the important thing, you did the product first.William [00:37:36]: Of course, but then you can slap on like, like the rocket or the jet engine or something, which is just this cash in, you pour in as much cash, you buy a lot of ads, and your growth is faster.swyx [00:37:48]: Not to, you know, I'm just kind of curious what's working right now versus what surprisinglyWilliam [00:37:52]: doesn't work. Oh, there's a long, long list of surprising stuff that doesn't work. Yeah. The surprising thing, like the most surprising thing, what doesn't work is almost everything doesn't work. That's what's surprising. And I'll give you an example. So like a year and a half ago, I was working at a company, we were super excited by audio. I was like, audio is going to be the next killer feature, we have to get in the app. And I want to be the first. So everything Chai does, I want us to be the first. We may not be the company that's strongest at execution, but we can always be theswyx [00:38:22]: most innovative. Interesting. Right? So we can... You're pretty strong at execution.William [00:38:26]: We're much stronger, we're much stronger. A lot of the reason we're here is because we were first. If we launched today, it'd be so hard to get the traction. Because it's like to get the flywheel, to get the users, to build a product people are excited about. If you're first, people are naturally excited about it. But if you're fifth or 10th, man, you've got to beswyx [00:38:46]: insanely good at execution. So you were first with voice? We were first. We were first. I only knowWilliam [00:38:51]: when character launched voice. They launched it, I think they launched it at least nine months after us. Okay. Okay. But the team worked so hard for it. At the time we did it, latency is a huge problem. Cost is a huge problem. Getting the right quality of the voice is a huge problem. Right? Then there's this user interface and getting the right user experience. Because you don't just want it to start blurting out. Right? You want to kind of activate it. But then you don't have to keep pressing a button every single time. There's a lot that goes into getting a really smooth audio experience. So we went ahead, we invested the three months, we built it all. And then when we did the A-B test, there was like, no change in any of the numbers. And I was like, this can't be right, there must be a bug. And we spent like a week just checking everything, checking again, checking again. And it was like, the users just did not care. And it was something like only 10 or 15% of users even click the button to like, they wanted to engage the audio. And they would only use it for 10 or 15% of the time. So if you do the math, if it's just like something that one in seven people use it for one seventh of their time. You've changed like 2% of the experience. So even if that that 2% of the time is like insanely good, it doesn't translate much when you look at the retention, when you look at the engagement, and when you look at the monetization rates. So audio did not have a big impact. I'm pretty big on audio. But yeah, I like it too. But it's, you know, so a lot of the stuff which I do, I'm a big, you can have a theory. And you resist. Yeah. Exactly, exactly. So I think if you want to make audio work, it has to be a unique, compelling, exciting experience that they can't have anywhere else.swyx [00:40:37]: It could be your models, which just weren't good enough.William [00:40:39]: No, no, no, they were great. Oh, yeah, they were very good. it was like, it was kind of like just the, you know, if you listen to like an audible or Kindle, or something like, you just hear this voice. And it's like, you don't go like, wow, this is this is special, right? It's like a convenience thing. But the idea is that if you can, if Chai is the only platform, like, let's say you have a Mr. Beast, and YouTube is the only platform you can use to make audio work, then you can watch a Mr. Beast video. And it's the most engaging, fun video that you want to watch, you'll go to a YouTube. And so it's like for audio, you can't just put the audio on there. And people go, oh, yeah, it's like 2% better. Or like, 5% of users think it's 20% better, right? It has to be something that the majority of people, for the majority of the experience, go like, wow, this is a big deal. That's the features you need to be shipping. If it's not going to appeal to the majority of people, for the majority of the experience, and it's not a big deal, it's not going to move you. Cool. So you killed it. I don't see it anymore. Yep. So I love this. The longer, it's kind of cheesy, I guess, but the longer I've been working at Chai, and I think the team agrees with this, all the platitudes, at least I thought they were platitudes, that you would get from like the Steve Jobs, which is like, build something insanely great, right? Or be maniacally focused, or, you know, the most important thing is saying no to, not to work on. All of these sort of lessons, they just are like painfully true. They're painfully true. So now I'm just like, everything I say, I'm either quoting Steve Jobs or Zuckerberg. I'm like, guys, move fast and break free.swyx [00:42:10]: You've jumped the Apollo to cool it now.William [00:42:12]: Yeah, it's just so, everything they said is so, so true. The turtle neck. Yeah, yeah, yeah. Everything is so true.swyx [00:42:18]: This last question on my side, and I want to pass this to Alessio, is on just, just multi-modality in general. This actually comes from Justine Moore from A16Z, who's a friend of ours. And a lot of people are trying to do voice image video for AI companions. Yes. You just said voice didn't work. Yep. What would make you revisit?William [00:42:36]: So Steve Jobs, he was very, listen, he was very, very clear on this. There's a habit of engineers who, once they've got some cool technology, they want to find a way to package up the cool technology and sell it to consumers, right? That does not work. So you're free to try and build a startup where you've got your cool tech and you want to find someone to sell it to. That's not what we do at Chai. At Chai, we start with the consumer. What does the consumer want? What is their problem? And how do we solve it? So right now, the number one problems for the users, it's not the audio. That's not the number one problem. It's not the image generation either. That's not their problem either. The number one problem for users in AI is this. All the AI is being generated by middle-aged men in Silicon Valley, right? That's all the content. You're interacting with this AI. You're speaking to it for 90 minutes on average. It's being trained by middle-aged men. The guys out there, they're out there. They're talking to you. They're talking to you. They're like, oh, what should the AI say in this situation, right? What's funny, right? What's cool? What's boring? What's entertaining? That's not the way it should be. The way it should be is that the users should be creating the AI, right? And so the way I speak about it is this. Chai, we have this AI engine in which sits atop a thin layer of UGC. So the thin layer of UGC is absolutely essential, right? It's just prompts. But it's just prompts. It's just an image. It's just a name. It's like we've done 1% of what we could do. So we need to keep thickening up that layer of UGC. It must be the case that the users can train the AI. And if reinforcement learning is powerful and important, they have to be able to do that. And so it's got to be the case that there exists, you know, I say to the team, just as Mr. Beast is able to spend 100 million a year or whatever it is on his production company, and he's got a team building the content, the Mr. Beast company is able to spend 100 million a year on his production company. And he's got a team building the content, which then he shares on the YouTube platform. Until there's a team that's earning 100 million a year or spending 100 million on the content that they're producing for the Chai platform, we're not finished, right? So that's the problem. That's what we're excited to build. And getting too caught up in the tech, I think is a fool's errand. It does not work.Alessio [00:44:52]: As an aside, I saw the Beast Games thing on Amazon Prime. It's not doing well. And I'mswyx [00:44:56]: curious. It's kind of like, I mean, the audience reading is high. The run-to-meet-all sucks, but the audience reading is high.Alessio [00:45:02]: But it's not like in the top 10. I saw it dropped off of like the... Oh, okay. Yeah, that one I don't know. I'm curious, like, you know, it's kind of like similar content, but different platform. And then going back to like, some of what you were saying is like, you know, people come to ChaiWilliam [00:45:13]: expecting some type of content. Yeah, I think it's something that's interesting to discuss is like, is moats. And what is the moat? And so, you know, if you look at a platform like YouTube, the moat, I think is in first is really is in the ecosystem. And the ecosystem, is comprised of you have the content creators, you have the users, the consumers, and then you have the algorithms. And so this, this creates a sort of a flywheel where the algorithms are able to be trained on the users, and the users data, the recommend systems can then feed information to the content creators. So Mr. Beast, he knows which thumbnail does the best. He knows the first 10 seconds of the video has to be this particular way. And so his content is super optimized for the YouTube platform. So that's why it doesn't do well on Amazon. If he wants to do well on Amazon, how many videos has he created on the YouTube platform? By thousands, 10s of 1000s, I guess, he needs to get those iterations in on the Amazon. So at Chai, I think it's all about how can we get the most compelling, rich user generated content, stick that on top of the AI engine, the recommender systems, in such that we get this beautiful data flywheel, more users, better recommendations, more creative, more content, more users.Alessio [00:46:34]: You mentioned the algorithm, you have this idea of the Chaiverse on Chai, and you have your own kind of like LMSYS-like ELO system. Yeah, what are things that your models optimize for, like your users optimize for, and maybe talk about how you build it, how people submit models?William [00:46:49]: So Chaiverse is what I would describe as a developer platform. More often when we're speaking about Chai, we're thinking about the Chai app. And the Chai app is really this product for consumers. And so consumers can come on the Chai app, they can come on the Chai app, they can come on the Chai app, they can interact with our AI, and they can interact with other UGC. And it's really just these kind of bots. And it's a thin layer of UGC. Okay. Our mission is not to just have a very thin layer of UGC. Our mission is to have as much UGC as possible. So we must have, I don't want people at Chai training the AI. I want people, not middle aged men, building AI. I want everyone building the AI, as many people building the AI as possible. Okay, so what we built was we built Chaiverse. And Chaiverse is kind of, it's kind of like a prototype, is the way to think about it. And it started with this, this observation that, well, how many models get submitted into Hugging Face a day? It's hundreds, it's hundreds, right? So there's hundreds of LLMs submitted each day. Now consider that, what does it take to build an LLM? It takes a lot of work, actually. It's like someone devoted several hours of compute, several hours of their time, prepared a data set, launched it, ran it, evaluated it, submitted it, right? So there's a lot of, there's a lot of, there's a lot of work that's going into that. So what we did was we said, well, why can't we host their models for them and serve them to users? And then what would that look like? The first issue is, well, how do you know if a model is good or not? Like, we don't want to serve users the crappy models, right? So what we would do is we would, I love the LMSYS style. I think it's really cool. It's really simple. It's a very intuitive thing, which is you simply present the users with two completions. You can say, look, this is from model one. This is from model two. This is from model three. This is from model A. This is from model B, which is better. And so if someone submits a model to Chaiverse, what we do is we spin up a GPU. We download the model. We're going to now host that model on this GPU. And we're going to start routing traffic to it. And we're going to send, we think it takes about 5,000 completions to get an accurate signal. That's roughly what LMSYS does. And from that, we're able to get an accurate ranking. And we're able to get an accurate ranking. And we're able to get an accurate ranking of which models are people finding entertaining and which models are not entertaining. If you look at the bottom 80%, they'll suck. You can just disregard them. They totally suck. Then when you get the top 20%, you know you've got a decent model, but you can break it down into more nuance. There might be one that's really descriptive. There might be one that's got a lot of personality to it. There might be one that's really illogical. Then the question is, well, what do you do with these top models? From that, you can do more sophisticated things. You can try and do like a routing thing where you say for a given user request, we're going to try and predict which of these end models that users enjoy the most. That turns out to be pretty expensive and not a huge source of like edge or improvement. Something that we love to do at Chai is blending, which is, you know, it's the simplest way to think about it is you're going to end up, and you're going to pretty quickly see you've got one model that's really smart, one model that's really funny. How do you get the user an experience that is both smart and funny? Well, just 50% of the requests, you can serve them the smart model, 50% of the requests, you serve them the funny model. Just a random 50%? Just a random, yeah. And then... That's blending? That's blending. You can do more sophisticated things on top of that, as in all things in life, but the 80-20 solution, if you just do that, you get a pretty powerful effect out of the gate. Random number generator. I think it's like the robustness of randomness. Random is a very powerful optimization technique, and it's a very robust thing. So you can explore a lot of the space very efficiently. There's one thing that's really, really important to share, and this is the most exciting thing for me, is after you do the ranking, you get an ELO score, and you can track a user's first join date, the first date they submit a model to Chaiverse, they almost always get a terrible ELO, right? So let's say the first submission they get an ELO of 1,100 or 1,000 or something, and you can see that they iterate and they iterate and iterate, and it will be like, no improvement, no improvement, no improvement, and then boom. Do you give them any data, or do you have to come up with this themselves? We do, we do, we do, we do. We try and strike a balance between giving them data that's very useful, you've got to be compliant with GDPR, which is like, you have to work very hard to preserve the privacy of users of your app. So we try to give them as much signal as possible, to be helpful. The minimum is we're just going to give you a score, right? That's the minimum. But that alone is people can optimize a score pretty well, because they're able to come up with theories, submit it, does it work? No. A new theory, does it work? No. And then boom, as soon as they figure something out, they keep it, and then they iterate, and then boom,Alessio [00:51:46]: they figure something out, and they keep it. Last year, you had this post on your blog, cross-sourcing the lead to the 10 trillion parameter, AGI, and you call it a mixture of experts, recommenders. Yep. Any insights?William [00:51:58]: Updated thoughts, 12 months later? I think the odds, the timeline for AGI has certainly been pushed out, right? Now, this is in, I'm a controversial person, I don't know, like, I just think... You don't believe in scaling laws, you think AGI is further away. I think it's an S-curve. I think everything's an S-curve. And I think that the models have proven to just be far worse at reasoning than people sort of thought. And I think whenever I hear people talk about LLMs as reasoning engines, I sort of cringe a bit. I don't think that's what they are. I think of them more as like a simulator. I think of them as like a, right? So they get trained to predict the next most likely token. It's like a physics simulation engine. So you get these like games where you can like construct a bridge, and you drop a car down, and then it predicts what should happen. And that's really what LLMs are doing. It's not so much that they're reasoning, it's more that they're just doing the most likely thing. So fundamentally, the ability for people to add in intelligence, I think is very limited. What most people would consider intelligence, I think the AI is not a crowdsourcing problem, right? Now with Wikipedia, Wikipedia crowdsources knowledge. It doesn't crowdsource intelligence. So it's a subtle distinction. AI is fantastic at knowledge. I think it's weak at intelligence. And a lot, it's easy to conflate the two because if you ask it a question and it gives you, you know, if you said, who was the seventh president of the United States, and it gives you the correct answer, I'd say, well, I don't know the answer to that. And you can conflate that with intelligence. But really, that's a question of knowledge. And knowledge is really this thing about saying, how can I store all of this information? And then how can I retrieve something that's relevant? Okay, they're fantastic at that. They're fantastic at storing knowledge and retrieving the relevant knowledge. They're superior to humans in that regard. And so I think we need to come up for a new word. How does one describe AI should contain more knowledge than any individual human? It should be more accessible than any individual human. That's a very powerful thing. That's superswyx [00:54:07]: powerful. But what words do we use to describe that? We had a previous guest on Exa AI that does search. And he tried to coin super knowledge as the opposite of super intelligence.William [00:54:20]: Exactly. I think super knowledge is a more accurate word for it.swyx [00:54:24]: You can store more things than any human can.William [00:54:26]: And you can retrieve it better than any human can as well. And I think it's those two things combined that's special. I think that thing will exist. That thing can be built. And I think you can start with something that's entertaining and fun. And I think, I often think it's like, look, it's going to be a 20 year journey. And we're in like, year four, or it's like the web. And this is like 1998 or something. You know, you've got a long, long way to go before the Amazon.coms are like these huge, multi trillion dollar businesses that every single person uses every day. And so AI today is very simplistic. And it's fundamentally the way we're using it, the flywheels, and this ability for how can everyone contribute to it to really magnify the value that it brings. Right now, like, I think it's a bit sad. It's like, right now you have big labs, I'm going to pick on open AI. And they kind of go to like these human labelers. And they say, we're going to pay you to just label this like subset of questions that we want to get a really high quality data set, then we're going to get like our own computers that are really powerful. And that's kind of like the thing. For me, it's so much like Encyclopedia Britannica. It's like insane. All the people that were interested in blockchain, it's like, well, this is this is what needs to be decentralized, you need to decentralize that thing. Because if you distribute it, people can generate way more data in a distributed fashion, way more, right? You need the incentive. Yeah, of course. Yeah. But I mean, the, the, that's kind of the exciting thing about Wikipedia was it's this understanding, like the incentives, you don't need money to incentivize people. You don't need dog coins. No. Sometimes, sometimes people get the satisfaction from just seeing the correct thing. Number go up. Yeah, yeah. I mean, you do pay money for Chai vs. Weed. We've, we've paid out over $100,000 to model creators. But do you know what we saw? It's not motivating. We saw that it didn't really make a difference. Like if they were submitting models at a certain rate, if you pay them a bunch of money, they didn't change the rate. What the money let them do was if they wanted to fine tune Alarma 70B on eight H100s overnight, if you give them money, then they can do it. Or you could give them compute. Yeah. So, so I think the most exciting person we ever saw from interacting with Chai, Chai vs. was we gave some kid who was like, like 17 years old, I think we gave him $1,000 and he spent all the money on buying a physical computer. And he took a picture of it and said, this is what I bought. And I'm going to be training more models with it. So that's why, that's why I love platforms.swyx [00:57:00]: Should you hire him or?William [00:57:02]: That's the temptation. Yeah. That's the temptation. But you want to keep the team small? No, no. As a platform, we can't just hire every good content creator. We've got to build the systems and the best content creator today isn't going to be the best content creator next year.Alessio [00:57:14]: What about Eva? So you've talked about reasoning and knowledge. Most of the benchmarks that people use want to mimic reasoning. Yep. I want to register, I disagree on the reasoning, but we have to keep going. Yeah, I'm curious, like how, how do you think about the evals that matter to you?swyx [00:57:29]: So yeah, like Elo cannot be the only eval. You must have internal evals. You mentioned evals.William [00:57:34]: I think Elo is a fantastic north star and the reason for it, or like it's the main one we want to see go up because it's this human feedback. The humans know what they want. It's beautiful because when you come up with an eval, you're further removing yourself away from the true problem. Right? So whatever it is you're trying to optimize or figure out, you kind of have to, have to slice it. And then you've got this, it's like a snapshot. Like as soon as you saturate one eval, you need to figure out a new eval. But with, by saying to humans, just which is better, A or B, it's super robust. It's super generalizable. It just keeps, keeps scaling. So we've in the past used evals to get through a, to get through a blocker. I mean, a great example is, you know, is like having like a safety filter or something. Yeah. Where you want to make sure your models, because listen, users find, you'll be shocked the correlation between not family friendly content, whether that's just like swearing, like people find it funny when the AI swears. So if you have two completions, A or B, like if you give me any LLM, I can make it 20% funnier just by training it to throw in swear words. So the issue with that is it's like, how are we measuring like quality improvements? Are we measuring superficial improvements? Right. And this actually links back to the LLM sys. They did a style control.swyx [00:58:54]: We actually had them on the podcast.William [00:58:56]: Yeah. Yeah. And so that's the way I, I would rather just lean on human feedback and just continue to make that more and more robust and more and more useful. And, you know, you can say some people are like GPU poor and GPU rich. We're like, we're feedback rich. Like when you've got one and a half million people a day, we get as much feedback from humans as we want. So we're not in a position where we needed to have the evals very much. Yeah. And when we do, we saturate them pretty quick. So a safety one, you know, within a month, we don't need to use it anymore because it's sort of, it's, you know, the issue has been addressed.swyx [00:59:29]: I think one problem I have, and this is a broader products question maybe, is that the ELOs apply to the whole user population. That's right. Clearly the user behavior, there's segments that have like, I'm a role play person, I'm a therapy person, I'm a not safe for work person. You don't split them?William [00:59:44]: This is why I say like, I think we're in year four of like a 20 year thing where it's like, at the end of the day, I'm a role play person. And I think if we all go on like Spotify or like, imagine if Spotify only had the top five musicians, I think it would retain over 85% of its existing users. Yeah. Right. And I think if YouTube, if YouTube only kept the top five content creators, it would be enough for the vast majority of people. The thing I'm just trying to share here is there's one surprising thing about humans is their preferences are pretty correlated. What you find funny and entertaining, I find funny and entertaining, and he finds funny and entertaining. There might be degrees of variation in it, I might find it super funny, you might find it only slightly funny, but optimizing to a global works very, very well. And for segmentation to be really powerful, segmentation will work amazing if you found a comment super boring, and I found it super fun. If we could segment that, then that would unlock really powerful stuff. But unfortunately, that's not the shape of human behavior, right? It's like, I might rank it 10 out of 10 funny, you might rank it 7 out of 10 funny. And it's like, it doesn't give you... It doesn't give you as much space to play as you would hope. It's an element of the diversity of content that AI can produce right now, which is it's not as diverse as if you consider a platform like YouTube, you can watch a Mr. Beast video, that's totally different to a makeup tutorial. So there's enough diversity there where if you go on my YouTube feed, it is totally different to my sister's one. My sister's one, it's all like women, and if you go on mine, it's all like bald, middle-aged men, either talking about MMA or, right? I think with AI, it's still a bit too early for that degree of segmentation. So I think it all comes, the recommender systems, the personalization. But this is why I like the, don't start with the technology, start with the problem. The problem is UGC. We must give users the tools to build more variety and more engaging content.swyx [01:01:42]: Yeah. I feel like there's... I was surprised at how thin it was when I tried out Chai. Yeah. It's very thin. Haven't you been tempted? Like there's this ecosystem of Cobalt, Silly Tavern, those guys. They have model cards. It seems like an industry standard almost. Yeah, agreed. Can I just import those? I don't think I want to say.William [01:02:01]: Oh, you're already working on it. No, it's like, I remember when Chai meant, Chai, Silly Tavern, and like Cobalt, Cobalt AI is basically as old as Chai. So when Chai was, when we just existed, they just existed. And both of us were using GPT. Chai, yeah, yeah, yeah. And I remember very early on, I was like, these guys shouldn't even exist. Because if we build a good enough platform, they should just be posting their content on our platform.swyx [01:02:28]: Yeah, but they're open source. No, exactly.William [01:02:30]: That was what I learned. Eventually, I learned like they're, what they're excited about is slightly different from a typical consumer. My answer is, it's kind of like a complex thing where it's really down to the content creator wants, typically they're building it for themselves. And typically they want to create an experience for themselves. So one content creator might have to write a thousand words describing, let's take a science fiction scenario. Let's say, okay, you're on a spaceship and you're going off into space and your crew, these are your crew members. You've got one that's really friendly, one that's really mean, and you're the new cadet and you want to rise to the top. And they can really go into great detail, right? And then you can give that to like a Lama 70B. And Lama 70B will do a pretty good job of adhering to the prompt and the user will have a good experience. Okay. Very few users will ever go to that level of content creation. If instead the user, we can really make the AI understand the user more so that rather than having to use a thousand characters or a thousand tokens to describe the scenario, we can just say, look, you're on a spaceship. You've got three crewmate. It's going to be dramatic and there should be some fighting. And then the AI gives you an even better experience. Then the content creator is happier. And so fundamentally, the way I'd kind of think about it. Is there's the sterability of the AI. And so a lot of the work we do at Chai is really about saying we want the AI to react to the user and react to the content creator in the way that they most want. One kind of like analog would be TikTok. I think the thing that TikTok did insanely good was they made it really easy for like anyone. If you make a video on TikTok, almost anyone can make a kind of fun video really easy. You just put some music on the top of it. You throw some of the. Animations on top and it's not hard to have a pretty fun thing. And I think that's much more like the Chai style where it's like users don't want to have to work. You know, if your content is only good, if you have like Shakespeare, it's better if, if just anyone at home can make the, can make the thing. So that's, that's kind of like my answer to the silly talent style. And I think the right answer is how do you get the silly time people fine tuning models that create a really special effect.Alessio [01:04:46]: As we wrap this is kind of the call for action.William [01:04:49]: Uh, part one, you have Chai Grant, which I think a lot of people don't know about, which is grants for open source projects, any ideas, any projects that you want to see people work on the should apply or let me think, I think, um, so we do try Chai Grant and fundamentally, you know, we give cash, no strings attached. It's kind of our way of doing two things. One, giving back and support in the community. We've benefited from a lot of open source packages. A lot of our developers and engineers are like. Really? Really pro open source. And then also it's a great way to just meet talented people and, and like expand connections. So with respect to Chai Grant, if anyone's got any sort of, um, GitHub project, any sort of thing they built that they're proud of, just apply, just apply. It's like no strings attached cash and people have a pretty high success rate. So that's the first thing. Other call to actions would be, I think Chai is this, you know, it's a startup. We're a small team. It's like 15 people. We work very intense. It's a very hardcore. Sort of environment, which we found that a lot of people don't like. They don't like the, you know, they'll ask us this concept of what life balance one time. A person said, they said something like, I can't get this done because I'm taking PTO on Friday. And I said, what is PTO? Okay. Um, it stands for paid time off and this, I know what it is and this person was gone. They didn't like, they were no longer in the company four weeks on legally. I think you have to, oh, it's true. There's no problem. Look, if you've got. You've got to take a day off, right? We all have personal lives, right? But it's about this idea of responsibility. If you're not in the office on Friday, you still have your responsibilities. So I don't care if you work hard Thursday to get it wrapped up. I don't care if you're working hard Saturday to get it wrapped up. It's not an excuse to, it's not an excuse. The way this individual spoke about it, it was like an excuse. I think it's an environment, very talented engineers working very hard in an intense space. It's the thing that gets me excited. It's, it's why I think, you know, I really love working at Chai is because it's a place of talent. It's a place of people working super hard. So yeah, I think people who have got, who've worked at startups and they, they love that. That's what they, they want the taste of, I think they should reach out, they should apply. And I think 90% of people can say that sounds terrible. Don't apply.swyx [01:07:03]: It's not for them.Alessio [01:07:03]: Yeah, it's exactly, exactly. Yeah. I just realized we skipped one important part. So you spent $10 million on compute last year. You say you're going to probably triple that. Yeah. I'm sure you're doing a lot of work on custom kernels, kind of like inference optimization, any cool stuff. Yeah. That you want to share there. Yeah.William [01:07:20]: Lots of cool stuff. So really quickly, I think inference is very, very important. It's super important. It's massively underlooked and we can look at all the different foundation models and the techniques, the differences in the foundation models on how well they perform from a cost perspective with inference. Mixture of experts, for example, tend to do really, really good from like a cost perspective. We've worked with a very talented team called.swyx [01:07:49]: MK1 and we, so I saw, I saw them in the Chaiverse logs. What are they?William [01:07:54]: We were using, we were running VLLM for a while and VLLM is really fantastic. Absolutely amazing. The work that they've done and achieved. And at some point I got introduced to the founder's name is Paul Marola. And he was a co-founder at Neuralink, really, really expert in like hardware. He kind of explained to me, he was like, look, if you know, hardware really well, you can write the CUDA kernels really well. He said, you should check out our inference engine. And they kind of blew VLLM out the water when we evaluated it much, much, much faster. And I think the special thing that he was able to do with us is we love rejection sampling. So we do much more rejection sampling than maybe typical and, you know, generate it. So we, we never, ever, ever just generate a single completion, right? This is why we don't do streaming. A lot of people like ChatGPT used to do a lot of streaming. Like the completion would come out one thing at a time. I did. I didn't notice that in your UX. Normally chat, you have to stream. Exactly. But Chai has never done streaming because if you stream, you're unable to do rejection sampling. The benefit of that is you can serve a larger model. The reason why you can serve a larger model is because they're saying instead of generating a completion in four seconds, because the user gets the first token faster, you can generate in 10 seconds. Well, if you've got 10 seconds to generate completion, you can serve a much larger model. So typically the people that are streaming, the benefit that they're getting is they're, you know, serving a larger model with Chai, we give you, you know, the second answer comes, boom, you get the full completion. And the reason for that is because we want to generate 16 completions, see the entire response, and then we want to evaluate which one we think is the best.swyx [01:09:34]: Do you have a separate LLM evaluator? Yes, we do. Yeah.William [01:09:37]: So, um, typically they're referred to as a reward model and that's a, you know, that's like a term from reinforcement learning. And for that, you can start off with something very simple, which is, do you think the user is going to respond to it? That's a simple one. So you can, you can train, you can take 50 million messages and, and look at all the sorts of messages users reply to, which ones they don't. And then you can train this, this reward model to evaluate completions. And so it knows like, okay, if you say this, the user is not going to respond. So don't bother sending it to the user. If you say this, the user is definitely going to engage with it. So send them, send them that.swyx [01:10:11]: There's an interesting parallel between MLAs and MLAs. I think we use at the top, spreading out to different experts and then at the bottom with rejection sampling, choosing from different paths.William [01:10:21]: I totally agree. That's the stuff that is the future of AI. I think that's the exciting stuff. And there's a parallel between that. Why was AlphaGo able to be superhuman? Right. It's this ability to generate many different paths. Tree search. And tree search. Exactly. So I think if you want to talk about what would intelligence look like, it looks much more like tree search. Combining the generative nature of these LLMs with a really good tree search. And that's what opening I've done with O1 and O3.swyx [01:10:51]: I don't know that they do tree search. They never said they do. It's implied. Yes. Okay. Yes. Yes. Are you comfortable with O1 being a reasoning engine? No, no, no, no.William [01:11:01]: I'm saying it's better at reasoning because they leverage the tree search well. And the, the issue of the reasoning is they're saying, is this like they train, they have the models to say, is this logically correct? And what's the likelihood of it being logically correct? So you can build up the sophisticated mechanisms to get it less bad at reasoning, but you'll see like eventually what, what AI is really, really good at. People won't say it's, it's always going to be better at retrieving. It's always going to be better at storing knowledge, which is so highly correlated with intelligence that we often assume it's the same. What, what AI is truly special at and gets consumers really excited is it's generative. It can just make stuff. We've never had a technology. Before that can just make stuff simulate.Alessio [01:11:45]: Yeah.William [01:11:45]: Yeah. So that's the special, that's the exciting thing.Alessio [01:11:48]: Awesome. Well, any parting parting thoughts?William [01:11:51]: No, it's been, it's been a pleasure. I guess the only thing I'd add is like our office is in Palo Alto. So, um, yeah, you know, people with startup experience looking to join a fast growing high impact startup. Yeah.swyx [01:12:03]: Uh, we'll find your culture deck, which is great. Fantastic. And then also, yeah. Yeah.Alessio [01:12:07]: What's the story where if you made a hundred K trading, we'll fast track your application. Like, I mean, I kind of qualify.William [01:12:15]: just looked at the team and it got to the point where almost every single person on the team you could point to, and they had done something special before joining the team. Like they, they had strong markers of like, there was something special about them. That's not to say it's like, like an exclusive thing. You have to have achieved something special, but it's just, uh, we got this one engineer and she, she started going to college. She went to CMU when she was like 15 years old or something. And it's like, that's a bit special. There's another engineer. He created a Git repo and I think he got like 1500 stars and it was like a repo for like, there was some drivers that he wrote. It was like a super low, low level thing. I was like, that's a bit special. We had this other guy, he joined the team and he'd, he had made a hundred K buying and selling sneakers, right? Trading. Yeah. So, so it's like, it's just this thing, like if you've been to Harvard, cool, that's great. It shows that you're really smart and you work really hard. Cool. That's good. But if you've actually built something and done something. I think there's a bit more tangible that gets us even more excited.Alessio [01:13:16]: Cool. Well, thanks for having us at ChaiHQ. Yeah.William [01:13:19]: Thanks guys. Get full access to Latent.Space at www.latent.space/subscribe
-
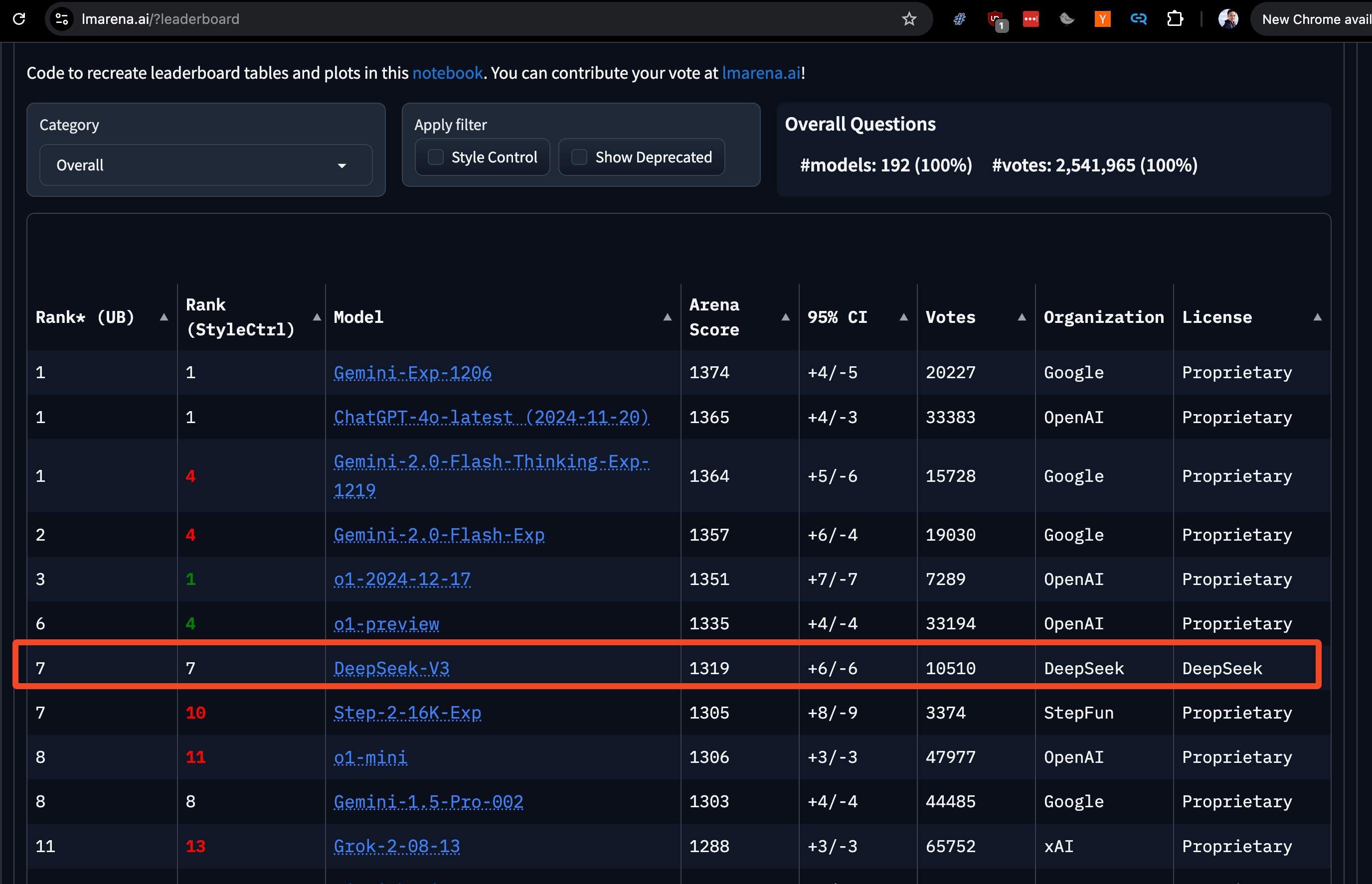 Everything you need to run Mission Critical Inference (ft. DeepSeek v3 + SGLang)
Everything you need to run Mission Critical Inference (ft. DeepSeek v3 + SGLang)From 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2025-01-19 04:00
Sponsorships and applications for the AI Engineer Summit in NYC are live! (Speaker CFPs have closed) If you are building AI agents or leading teams of AI Engineers, this will be the single highest-signal conference of the year for you.Right after Christmas, the Chinese Whale Bros ended 2024 by dropping the last big model launch of the year: DeepSeek v3. Right now on LM Arena, DeepSeek v3 has a score of 1319, right under the full o1 model, Gemini 2, and 4o latest. This makes it the best open weights model in the world in January 2025.There has been a big recent trend in Chinese labs releasing very large open weights models, with TenCent releasing Hunyuan-Large in November and Hailuo releasing MiniMax-Text this week, both over 400B in size. However these extra-large language models are very difficult to serve.Baseten was the first of the Inference neocloud startups to get DeepSeek V3 online, because of their H200 clusters, their close collaboration with the DeepSeek team and early support of SGLang, a relatively new VLLM alternative that is also used at frontier labs like X.ai. Each H200 has 141 GB of VRAM with 4.8 TB per second of bandwidth, meaning that you can use 8 H200's in a node to inference DeepSeek v3 in FP8, taking into account KV Cache needs. We have been close to Baseten since Sarah Guo introduced Amir Haghighat to swyx, and they supported the very first Latent Space Demo Day in San Francisco, which was effectively the trial run for swyx and Alessio to work together! Since then, Philip Kiely also led a well attended workshop on TensorRT LLM at the 2024 World's Fair. We worked with him to get two of their best representatives, Amir and Lead Model Performance Engineer Yineng Zhang, to discuss DeepSeek, SGLang, and everything they have learned running Mission Critical Inference workloads at scale for some of the largest AI products in the world.The Three Pillars of Mission Critical InferenceWe initially planned to focus the conversation on SGLang, but Amir and Yineng were quick to correct us that the choice of inference framework is only the simplest, first choice of 3 things you need for production inference at scale:“I think it takes three things, and each of them individually is necessary but not sufficient: * Performance at the model level: how fast are you running this one model running on a single GPU, let's say. The framework that you use there can, can matter. The techniques that you use there can matter. The MLA technique, for example, that Yineng mentioned, or the CUDA kernels that are being used. But there's also techniques being used at a higher level, things like speculative decoding with draft models or with Medusa heads. And these are implemented in the different frameworks, or you can even implement it yourself, but they're not necessarily tied to a single framework. But using speculative decoding gets you massive upside when it comes to being able to handle high throughput. But that's not enough. Invariably, that one model running on a single GPU, let's say, is going to get too much traffic that it cannot handle.* Horizontal scaling at the cluster/region level: And at that point, you need to horizontally scale it. That's not an ML problem. That's not a PyTorch problem. That's an infrastructure problem. How quickly do you go from, a single replica of that model to 5, to 10, to 100. And so that's the second, that's the second pillar that is necessary for running these machine critical inference workloads.And what does it take to do that? It takes, some people are like, Oh, You just need Kubernetes and Kubernetes has an autoscaler and that just works. That doesn't work for, for these kinds of mission critical inference workloads. And you end up catching yourself wanting to bit by bit to rebuild those infrastructure pieces from scratch. This has been our experience. * And then going even a layer beyond that, Kubernetes runs in a single. cluster. It's a single cluster. It's a single region tied to a single region. And when it comes to inference workloads and needing GPUs more and more, you know, we're seeing this that you cannot meet the demand inside of a single region. A single cloud's a single region. In other words, a single model might want to horizontally scale up to 200 replicas, each of which is, let's say, 2H100s or 4H100s or even a full node, you run into limits of the capacity inside of that one region. And what we had to build to get around that was the ability to have a single model have replicas across different regions. So, you know, there are models on Baseten today that have 50 replicas in GCP East and, 80 replicas in AWS West and Oracle in London, etc.* Developer experience for Compound AI Systems: The final one is wrapping the power of the first two pillars in a very good developer experience to be able to afford certain workflows like the ones that I mentioned, around multi step, multi model inference workloads, because more and more we're seeing that the market is moving towards those that the needs are generally in these sort of more complex workflows. We think they said it very well.Show Notes* Amir Haghighat, Co-Founder, Baseten* Yineng Zhang, Lead Software Engineer, Model Performance, BasetenFull YouTube EpisodePlease like and subscribe!Timestamps* 00:00 Introduction and Latest AI Model Launch* 00:11 DeepSeek v3: Specifications and Achievements* 03:10 Latent Space Podcast: Special Guests Introduction* 04:12 DeepSeek v3: Technical Insights* 11:14 Quantization and Model Performance* 16:19 MOE Models: Trends and Challenges* 18:53 Baseten's Inference Service and Pricing* 31:13 Optimization for DeepSeek* 31:45 Three Pillars of Mission Critical Inference Workloads* 32:39 Scaling Beyond Single GPU* 33:09 Challenges with Kubernetes and Infrastructure* 33:40 Multi-Region Scaling Solutions* 35:34 SG Lang: A New Framework* 38:52 Key Techniques Behind SG Lang* 48:27 Speculative Decoding and Performance* 49:54 Future of Fine-Tuning and RLHF* 01:00:28 Baseten's V3 and Industry TrendsBaseten’s previous TensorRT LLM workshop: Get full access to Latent.Space at www.latent.space/subscribe
-
 [Ride Home] Simon Willison: Things we learned about LLMs in 2024
[Ride Home] Simon Willison: Things we learned about LLMs in 2024From 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2025-01-12 07:31
Due to overwhelming demand (>15x applications:slots), we are closing CFPs for AI Engineer Summit NYC today. Last call! Thanks, we’ll be reaching out to all shortly!The world’s top AI blogger and friend of every pod, Simon Willison, dropped a monster 2024 recap: Things we learned about LLMs in 2024. Brian of the excellent TechMeme Ride Home pinged us for a connection and a special crossover episode, our first in 2025. The target audience for this podcast is a tech-literate, but non-technical one. You can see Simon’s notes for AI Engineers in his World’s Fair Keynote.Timestamp* 00:00 Introduction and Guest Welcome* 01:06 State of AI in 2025* 01:43 Advancements in AI Models* 03:59 Cost Efficiency in AI* 06:16 Challenges and Competition in AI* 17:15 AI Agents and Their Limitations* 26:12 Multimodal AI and Future Prospects* 35:29 Exploring Video Avatar Companies* 36:24 AI Influencers and Their Future* 37:12 Simplifying Content Creation with AI* 38:30 The Importance of Credibility in AI* 41:36 The Future of LLM User Interfaces* 48:58 Local LLMs: A Growing Interest* 01:07:22 AI Wearables: The Next Big Thing* 01:10:16 Wrapping Up and Final ThoughtsTranscript[00:00:00] Introduction and Guest Welcome[00:00:00] Brian: Welcome to the first bonus episode of the Tech Meme Write Home for the year 2025. I'm your host as always, Brian McCullough. Listeners to the pod over the last year know that I have made a habit of quoting from Simon Willison when new stuff happens in AI from his blog. Simon has been, become a go to for many folks in terms of, you know, Analyzing things, criticizing things in the AI space.[00:00:33] Brian: I've wanted to talk to you for a long time, Simon. So thank you for coming on the show. No, it's a privilege to be here. And the person that made this connection happen is our friend Swyx, who has been on the show back, even going back to the, the Twitter Spaces days but also an AI guru in, in their own right Swyx, thanks for coming on the show also.[00:00:54] swyx (2): Thanks. I'm happy to be on and have been a regular listener, so just happy to [00:01:00] contribute as well.[00:01:00] Brian: And a good friend of the pod, as they say. Alright, let's go right into it.[00:01:06] State of AI in 2025[00:01:06] Brian: Simon, I'm going to do the most unfair, broad question first, so let's get it out of the way. The year 2025. Broadly, what is the state of AI as we begin this year?[00:01:20] Brian: Whatever you want to say, I don't want to lead the witness.[00:01:22] Simon: Wow. So many things, right? I mean, the big thing is everything's got really good and fast and cheap. Like, that was the trend throughout all of 2024. The good models got so much cheaper, they got so much faster, they got multimodal, right? The image stuff isn't even a surprise anymore.[00:01:39] Simon: They're growing video, all of that kind of stuff. So that's all really exciting.[00:01:43] Advancements in AI Models[00:01:43] Simon: At the same time, they didn't get massively better than GPT 4, which was a bit of a surprise. So that's sort of one of the open questions is, are we going to see huge, but I kind of feel like that's a bit of a distraction because GPT 4, but way cheaper, much larger context lengths, and it [00:02:00] can do multimodal.[00:02:01] Simon: is better, right? That's a better model, even if it's not.[00:02:05] Brian: What people were expecting or hoping, maybe not expecting is not the right word, but hoping that we would see another step change, right? Right. From like GPT 2 to 3 to 4, we were expecting or hoping that maybe we were going to see the next evolution in that sort of, yeah.[00:02:21] Brian: We[00:02:21] Simon: did see that, but not in the way we expected. We thought the model was just going to get smarter, and instead we got. Massive drops in, drops in price. We got all of these new capabilities. You can talk to the things now, right? They can do simulated audio input, all of that kind of stuff. And so it's kind of, it's interesting to me that the models improved in all of these ways we weren't necessarily expecting.[00:02:43] Simon: I didn't know it would be able to do an impersonation of Santa Claus, like a, you know, Talked to it through my phone and show it what I was seeing by the end of 2024. But yeah, we didn't get that GPT 5 step. And that's one of the big open questions is, is that actually just around the corner and we'll have a bunch of GPT 5 class models drop in the [00:03:00] next few months?[00:03:00] Simon: Or is there a limit?[00:03:03] Brian: If you were a betting man and wanted to put money on it, do you expect to see a phase change, step change in 2025?[00:03:11] Simon: I don't particularly for that, like, the models, but smarter. I think all of the trends we're seeing right now are going to keep on going, especially the inference time compute, right?[00:03:21] Simon: The trick that O1 and O3 are doing, which means that you can solve harder problems, but they cost more and it churns away for longer. I think that's going to happen because that's already proven to work. I don't know. I don't know. Maybe there will be a step change to a GPT 5 level, but honestly, I'd be completely happy if we got what we've got right now.[00:03:41] Simon: But cheaper and faster and more capabilities and longer contexts and so forth. That would be thrilling to me.[00:03:46] Brian: Digging into what you've just said one of the things that, by the way, I hope to link in the show notes to Simon's year end post about what, what things we learned about LLMs in 2024. Look for that in the show notes.[00:03:59] Cost Efficiency in AI[00:03:59] Brian: One of the things that you [00:04:00] did say that you alluded to even right there was that in the last year, you felt like the GPT 4 barrier was broken, like IE. Other models, even open source ones are now regularly matching sort of the state of the art.[00:04:13] Simon: Well, it's interesting, right? So the GPT 4 barrier was a year ago, the best available model was OpenAI's GPT 4 and nobody else had even come close to it.[00:04:22] Simon: And they'd been at the, in the lead for like nine months, right? That thing came out in what, February, March of, of 2023. And for the rest of 2023, nobody else came close. And so at the start of last year, like a year ago, the big question was, Why has nobody beaten them yet? Like, what do they know that the rest of the industry doesn't know?[00:04:40] Simon: And today, that I've counted 18 organizations other than GPT 4 who've put out a model which clearly beats that GPT 4 from a year ago thing. Like, maybe they're not better than GPT 4. 0, but that's, that, that, that barrier got completely smashed. And yeah, a few of those I've run on my laptop, which is wild to me.[00:04:59] Simon: Like, [00:05:00] it was very, very wild. It felt very clear to me a year ago that if you want GPT 4, you need a rack of 40, 000 GPUs just to run the thing. And that turned out not to be true. Like the, the, this is that big trend from last year of the models getting more efficient, cheaper to run, just as capable with smaller weights and so forth.[00:05:20] Simon: And I ran another GPT 4 model on my laptop this morning, right? Microsoft 5. 4 just came out. And that, if you look at the benchmarks, it's definitely, it's up there with GPT 4. 0. It's probably not as good when you actually get into the vibes of the thing, but it, it runs on my, it's a 14 gigabyte download and I can run it on a MacBook Pro.[00:05:38] Simon: Like who saw that coming? The most exciting, like the close of the year on Christmas day, just a few weeks ago, was when DeepSeek dropped their DeepSeek v3 model on Hugging Face without even a readme file. It was just like a giant binary blob that I can't run on my laptop. It's too big. But in all of the benchmarks, it's now by far the best available [00:06:00] open, open weights model.[00:06:01] Simon: Like it's, it's, it's beating the, the metalamas and so forth. And that was trained for five and a half million dollars, which is a tenth of the price that people thought it costs to train these things. So everything's trending smaller and faster and more efficient.[00:06:15] Brian: Well, okay.[00:06:16] Challenges and Competition in AI[00:06:16] Brian: I, I kind of was going to get to that later, but let's, let's combine this with what I was going to ask you next, which is, you know, you're talking, you know, Also in the piece about the LLM prices crashing, which I've even seen in projects that I'm working on, but explain Explain that to a general audience, because we hear all the time that LLMs are eye wateringly expensive to run, but what we're suggesting, and we'll come back to the cheap Chinese LLM, but first of all, for the end user, what you're suggesting is that we're starting to see the cost come down sort of in the traditional technology way of Of costs coming down over time,[00:06:49] Simon: yes, but very aggressively.[00:06:51] Simon: I mean, my favorite thing, the example here is if you look at GPT-3, so open AI's g, PT three, which was the best, a developed model in [00:07:00] 2022 and through most of 20 2023. That, the models that we have today, the OpenAI models are a hundred times cheaper. So there was a 100x drop in price for OpenAI from their best available model, like two and a half years ago to today.[00:07:13] Simon: And[00:07:14] Brian: just to be clear, not to train the model, but for the use of tokens and things. Exactly,[00:07:20] Simon: for running prompts through them. And then When you look at the, the really, the top tier model providers right now, I think, are OpenAI, Anthropic, Google, and Meta. And there are a bunch of others that I could list there as well.[00:07:32] Simon: Mistral are very good. The, the DeepSeq and Quen models have got great. There's a whole bunch of providers serving really good models. But even if you just look at the sort of big brand name providers, they all offer models now that are A fraction of the price of the, the, of the models we were using last year.[00:07:49] Simon: I think I've got some numbers that I threw into my blog entry here. Yeah. Like Gemini 1. 5 flash, that's Google's fast high quality model is [00:08:00] how much is that? It's 0. 075 dollars per million tokens. Like these numbers are getting, So we just do cents per million now,[00:08:09] swyx (2): cents per million,[00:08:10] Simon: cents per million makes, makes a lot more sense.[00:08:12] Simon: Yeah they have one model 1. 5 flash 8B, the absolute cheapest of the Google models, is 27 times cheaper than GPT 3. 5 turbo was a year ago. That's it. And GPT 3. 5 turbo, that was the cheap model, right? Now we've got something 27 times cheaper, and the Google, this Google one can do image recognition, it can do million token context, all of those tricks.[00:08:36] Simon: But it's, it's, it's very, it's, it really is startling how inexpensive some of this stuff has got.[00:08:41] Brian: Now, are we assuming that this, that happening is directly the result of competition? Because again, you know, OpenAI, and probably they're doing this for their own almost political reasons, strategic reasons, keeps saying, we're losing money on everything, even the 200.[00:08:56] Brian: So they probably wouldn't, the prices wouldn't be [00:09:00] coming down if there wasn't intense competition in this space.[00:09:04] Simon: The competition is absolutely part of it, but I have it on good authority from sources I trust that Google Gemini is not operating at a loss. Like, the amount of electricity to run a prompt is less than they charge you.[00:09:16] Simon: And the same thing for Amazon Nova. Like, somebody found an Amazon executive and got them to say, Yeah, we're not losing money on this. I don't know about Anthropic and OpenAI, but clearly that demonstrates it is possible to run these things at these ludicrously low prices and still not be running at a loss if you discount the Army of PhDs and the, the training costs and all of that kind of stuff.[00:09:36] Brian: One, one more for me before I let Swyx jump in here. To, to come back to DeepSeek and this idea that you could train, you know, a cutting edge model for 6 million. I, I was saying on the show, like six months ago, that if we are getting to the point where each new model It would cost a billion, ten billion, a hundred billion to train that.[00:09:54] Brian: At some point it would almost, only nation states would be able to train the new models. Do you [00:10:00] expect what DeepSeek and maybe others are proving to sort of blow that up? Or is there like some sort of a parallel track here that maybe I'm not technically, I don't have the mouse to understand the difference.[00:10:11] Brian: Is the model, are the models going to go, you know, Up to a hundred billion dollars or can we get them down? Sort of like DeepSeek has proven[00:10:18] Simon: so I'm the wrong person to answer that because I don't work in the lab training these models. So I can give you my completely uninformed opinion, which is, I felt like the DeepSeek thing.[00:10:27] Simon: That was a bomb shell. That was an absolute bombshell when they came out and said, Hey, look, we've trained. One of the best available models and it cost us six, five and a half million dollars to do it. I feel, and they, the reason, one of the reasons it's so efficient is that we put all of these export controls in to stop Chinese companies from giant buying GPUs.[00:10:44] Simon: So they've, were forced to be, go as efficient as possible. And yet the fact that they've demonstrated that that's possible to do. I think it does completely tear apart this, this, this mental model we had before that yeah, the training runs just keep on getting more and more expensive and the number of [00:11:00] organizations that can afford to run these training runs keeps on shrinking.[00:11:03] Simon: That, that's been blown out of the water. So yeah, that's, again, this was our Christmas gift. This was the thing they dropped on Christmas day. Yeah, it makes me really optimistic that we can, there are, It feels like there was so much low hanging fruit in terms of the efficiency of both inference and training and we spent a whole bunch of last year exploring that and getting results from it.[00:11:22] Simon: I think there's probably a lot left. I think there's probably, well, I would not be surprised to see even better models trained spending even less money over the next six months.[00:11:31] swyx (2): Yeah. So I, I think there's a unspoken angle here on what exactly the Chinese labs are trying to do because DeepSea made a lot of noise.[00:11:41] swyx (2): so much for joining us for around the fact that they train their model for six million dollars and nobody quite quite believes them. Like it's very, very rare for a lab to trumpet the fact that they're doing it for so cheap. They're not trying to get anyone to buy them. So why [00:12:00] are they doing this? They make it very, very obvious.[00:12:05] swyx (2): Deepseek is about 150 employees. It's an order of magnitude smaller than at least Anthropic and maybe, maybe more so for OpenAI. And so what's, what's the end game here? Are they, are they just trying to show that the Chinese are better than us?[00:12:21] Simon: So Deepseek, it's the arm of a hedge, it's a, it's a quant fund, right?[00:12:25] Simon: It's an algorithmic quant trading thing. So I, I, I would love to get more insight into how that organization works. My assumption from what I've seen is it looks like they're basically just flexing. They're like, hey, look at how utterly brilliant we are with this amazing thing that we've done. And it's, it's working, right?[00:12:43] Simon: They but, and so is that it? Are they, is this just their kind of like, this is, this is why our company is so amazing. Look at this thing that we've done, or? I don't know. I'd, I'd love to get Some insight from, from within that industry as to, as to how that's all playing out.[00:12:57] swyx (2): The, the prevailing theory among the Local Llama [00:13:00] crew and the Twitter crew that I indexed for my newsletter is that there is some amount of copying going on.[00:13:06] swyx (2): It's like Sam Altman you know, tweet, tweeting about how they're being copied. And then also there's this, there, there are other sort of opening eye employees that have said, Stuff that is similar that DeepSeek's rate of progress is how U. S. intelligence estimates the number of foreign spies embedded in top labs.[00:13:22] swyx (2): Because a lot of these ideas do spread around, but they surprisingly have a very high density of them in the DeepSeek v3 technical report. So it's, it's interesting. We don't know how much, how many, how much tokens. I think that, you know, people have run analysis on how often DeepSeek thinks it is cloud or thinks it is opening GPC 4.[00:13:40] swyx (2): Thanks for watching! And we don't, we don't know. We don't know. I think for me, like, yeah, we'll, we'll, we basically will never know as, as external commentators. I think what's interesting is how, where does this go? Is there a logical floor or bottom by my estimations for the same amount of ELO started last year to the end of last year cost went down by a thousand X for the [00:14:00] GPT, for, for GPT 4 intelligence.[00:14:02] swyx (2): Would, do they go down a thousand X this year?[00:14:04] Simon: That's a fascinating question. Yeah.[00:14:06] swyx (2): Is there a Moore's law going on, or did we just get a one off benefit last year for some weird reason?[00:14:14] Simon: My uninformed hunch is low hanging fruit. I feel like up until a year ago, people haven't been focusing on efficiency at all. You know, it was all about, what can we get these weird shaped things to do?[00:14:24] Simon: And now once we've sort of hit that, okay, we know that we can get them to do what GPT 4 can do, When thousands of researchers around the world all focus on, okay, how do we make this more efficient? What are the most important, like, how do we strip out all of the weights that have stuff in that doesn't really matter?[00:14:39] Simon: All of that kind of thing. So yeah, maybe that was it. Maybe 2024 was a freak year of all of the low hanging fruit coming out at once. And we'll actually see a reduction in the, in that rate of improvement in terms of efficiency. I wonder, I mean, I think we'll know for sure in about three months time if that trend's going to continue or not.[00:14:58] swyx (2): I agree. You know, I [00:15:00] think the other thing that you mentioned that DeepSeq v3 was the gift that was given from DeepSeq over Christmas, but I feel like the other thing that might be underrated was DeepSeq R1,[00:15:11] Speaker 4: which is[00:15:13] swyx (2): a reasoning model you can run on your laptop. And I think that's something that a lot of people are looking ahead to this year.[00:15:18] swyx (2): Oh, did they[00:15:18] Simon: release the weights for that one?[00:15:20] swyx (2): Yeah.[00:15:21] Simon: Oh my goodness, I missed that. I've been playing with the quen. So the other great, the other big Chinese AI app is Alibaba's quen. Actually, yeah, I, sorry, R1 is an API available. Yeah. Exactly. When that's really cool. So Alibaba's Quen have released two reasoning models that I've run on my laptop.[00:15:38] Simon: Now there was, the first one was Q, Q, WQ. And then the second one was QVQ because the second one's a vision model. So you can like give it vision puzzles and a prompt that these things, they are so much fun to run. Because they think out loud. It's like the OpenAR 01 sort of hides its thinking process. The Query ones don't.[00:15:59] Simon: They just, they [00:16:00] just churn away. And so you'll give it a problem and it will output literally dozens of paragraphs of text about how it's thinking. My favorite thing that happened with QWQ is I asked it to draw me a pelican on a bicycle in SVG. That's like my standard stupid prompt. And for some reason it thought in Chinese.[00:16:18] Simon: It spat out a whole bunch of like Chinese text onto my terminal on my laptop, and then at the end it gave me quite a good sort of artistic pelican on a bicycle. And I ran it all through Google Translate, and yeah, it was like, it was contemplating the nature of SVG files as a starting point. And the fact that my laptop can think in Chinese now is so delightful.[00:16:40] Simon: It's so much fun watching you do that.[00:16:43] swyx (2): Yeah, I think Andrej Karpathy was saying, you know, we, we know that we have achieved proper reasoning inside of these models when they stop thinking in English, and perhaps the best form of thought is in Chinese. But yeah, for listeners who don't know Simon's blog he always, whenever a new model comes out, you, I don't know how you do it, but [00:17:00] you're always the first to run Pelican Bench on these models.[00:17:02] swyx (2): I just did it for 5.[00:17:05] Simon: Yeah.[00:17:07] swyx (2): So I really appreciate that. You should check it out. These are not theoretical. Simon's blog actually shows them.[00:17:12] Brian: Let me put on the investor hat for a second.[00:17:15] AI Agents and Their Limitations[00:17:15] Brian: Because from the investor side of things, a lot of the, the VCs that I know are really hot on agents, and this is the year of agents, but last year was supposed to be the year of agents as well. Lots of money flowing towards, And Gentic startups.[00:17:32] Brian: But in in your piece that again, we're hopefully going to have linked in the show notes, you sort of suggest there's a fundamental flaw in AI agents as they exist right now. Let me let me quote you. And then I'd love to dive into this. You said, I remain skeptical as to their ability based once again, on the Challenge of gullibility.[00:17:49] Brian: LLMs believe anything you tell them, any systems that attempt to make meaningful decisions on your behalf, will run into the same roadblock. How good is a travel agent, or a digital assistant, or even a research tool, if it [00:18:00] can't distinguish truth from fiction? So, essentially, what you're suggesting is that the state of the art now that allows agents is still, it's still that sort of 90 percent problem, the edge problem, getting to the Or, or, or is there a deeper flaw?[00:18:14] Brian: What are you, what are you saying there?[00:18:16] Simon: So this is the fundamental challenge here and honestly my frustration with agents is mainly around definitions Like any if you ask anyone who says they're working on agents to define agents You will get a subtly different definition from each person But everyone always assumes that their definition is the one true one that everyone else understands So I feel like a lot of these agent conversations, people talking past each other because one person's talking about the, the sort of travel agent idea of something that books things on your behalf.[00:18:41] Simon: Somebody else is talking about LLMs with tools running in a loop with a cron job somewhere and all of these different things. You, you ask academics and they'll laugh at you because they've been debating what agents mean for over 30 years at this point. It's like this, this long running, almost sort of an in joke in that community.[00:18:57] Simon: But if we assume that for this purpose of this conversation, an [00:19:00] agent is something that, Which you can give a job and it goes off and it does that thing for you like, like booking travel or things like that. The fundamental challenge is, it's the reliability thing, which comes from this gullibility problem.[00:19:12] Simon: And a lot of my, my interest in this originally came from when I was thinking about prompt injections as a source of this form of attack against LLM systems where you deliberately lay traps out there for this LLM to stumble across,[00:19:24] Brian: and which I should say you have been banging this drum that no one's gotten any far, at least on solving this, that I'm aware of, right.[00:19:31] Brian: Like that's still an open problem. The two years.[00:19:33] Simon: Yeah. Right. We've been talking about this problem and like, a great illustration of this was Claude so Anthropic released Claude computer use a few months ago. Fantastic demo. You could fire up a Docker container and you could literally tell it to do something and watch it open a web browser and navigate to a webpage and click around and so forth.[00:19:51] Simon: Really, really, really interesting and fun to play with. And then, um. One of the first demos somebody tried was, what if you give it a web page that says download and run this [00:20:00] executable, and it did, and the executable was malware that added it to a botnet. So the, the very first most obvious dumb trick that you could play on this thing just worked, right?[00:20:10] Simon: So that's obviously a really big problem. If I'm going to send something out to book travel on my behalf, I mean, it's hard enough for me to figure out which airlines are trying to scam me and which ones aren't. Do I really trust a language model that believes the literal truth of anything that's presented to it to go out and do those things?[00:20:29] swyx (2): Yeah I definitely think there's, it's interesting to see Anthropic doing this because they used to be the safety arm of OpenAI that split out and said, you know, we're worried about letting this thing out in the wild and here they are enabling computer use for agents. Thanks. The, it feels like things have merged.[00:20:49] swyx (2): You know, I'm, I'm also fairly skeptical about, you know, this always being the, the year of Linux on the desktop. And this is the equivalent of this being the year of agents that people [00:21:00] are not predicting so much as wishfully thinking and hoping and praying for their companies and agents to work.[00:21:05] swyx (2): But I, I feel like things are. Coming along a little bit. It's to me, it's kind of like self driving. I remember in 2014 saying that self driving was just around the corner. And I mean, it kind of is, you know, like in, in, in the Bay area. You[00:21:17] Simon: get in a Waymo and you're like, Oh, this works. Yeah, but it's a slow[00:21:21] swyx (2): cook.[00:21:21] swyx (2): It's a slow cook over the next 10 years. We're going to hammer out these things and the cynical people can just point to all the flaws, but like, there are measurable or concrete progress steps that are being made by these builders.[00:21:33] Simon: There is one form of agent that I believe in. I believe, mostly believe in the research assistant form of agents.[00:21:39] Simon: The thing where you've got a difficult problem and, and I've got like, I'm, I'm on the beta for the, the Google Gemini 1. 5 pro with deep research. I think it's called like these names, these names. Right. But. I've been using that. It's good, right? You can give it a difficult problem and it tells you, okay, I'm going to look at 56 different websites [00:22:00] and it goes away and it dumps everything to its context and it comes up with a report for you.[00:22:04] Simon: And it's not, it won't work against adversarial websites, right? If there are websites with deliberate lies in them, it might well get caught out. Most things don't have that as a problem. And so I've had some answers from that which were genuinely really valuable to me. And that feels to me like, I can see how given existing LLM tech, especially with Google Gemini with its like million token contacts and Google with their crawl of the entire web and their, they've got like search, they've got search and cache, they've got a cache of every page and so forth.[00:22:35] Simon: That makes sense to me. And that what they've got right now, I don't think it's, it's not as good as it can be, obviously, but it's, it's, it's, it's a real useful thing, which they're going to start rolling out. So, you know, Perplexity have been building the same thing for a couple of years. That, that I believe in.[00:22:50] Simon: You know, if you tell me that you're going to have an agent that's a research assistant agent, great. The coding agents I mean, chat gpt code interpreter, Nearly two years [00:23:00] ago, that thing started writing Python code, executing the code, getting errors, rewriting it to fix the errors. That pattern obviously works.[00:23:07] Simon: That works really, really well. So, yeah, coding agents that do that sort of error message loop thing, those are proven to work. And they're going to keep on getting better, and that's going to be great. The research assistant agents are just beginning to get there. The things I'm critical of are the ones where you trust, you trust this thing to go out and act autonomously on your behalf, and make decisions on your behalf, especially involving spending money, like that.[00:23:31] Simon: I don't see that working for a very long time. That feels to me like an AGI level problem.[00:23:37] swyx (2): It's it's funny because I think Stripe actually released an agent toolkit which is one of the, the things I featured that is trying to enable these agents each to have a wallet that they can go and spend and have, basically, it's a virtual card.[00:23:49] swyx (2): It's not that, not that difficult with modern infrastructure. can[00:23:51] Simon: stick a 50 cap on it, then at least it's an honor. Can't lose more than 50.[00:23:56] Brian: You know I don't, I don't know if either of you know Rafat Ali [00:24:00] he runs Skift, which is a, a travel news vertical. And he, he, he constantly laughs at the fact that every agent thing is, we're gonna get rid of booking a, a plane flight for you, you know?[00:24:11] Brian: And, and I would point out that, like, historically, when the web started, the first thing everyone talked about is, You can go online and book a trip, right? So it's funny for each generation of like technological advance. The thing they always want to kill is the travel agent. And now they want to kill the webpage travel agent.[00:24:29] Simon: Like it's like I use Google flight search. It's great, right? If you gave me an agent to do that for me, it would save me, I mean, maybe 15 seconds of typing in my things, but I still want to see what my options are and go, yeah, I'm not flying on that airline, no matter how cheap they are.[00:24:44] swyx (2): Yeah. For listeners, go ahead.[00:24:47] swyx (2): For listeners, I think, you know, I think both of you are pretty positive on NotebookLM. And you know, we, we actually interviewed the NotebookLM creators, and there are actually two internal agents going on internally. The reason it takes so long is because they're running an agent loop [00:25:00] inside that is fairly autonomous, which is kind of interesting.[00:25:01] swyx (2): For one,[00:25:02] Simon: for a definition of agent loop, if you picked that particularly well. For one definition. And you're talking about the podcast side of this, right?[00:25:07] swyx (2): Yeah, the podcast side of things. They have a there's, there's going to be a new version coming out that, that we'll be featuring at our, at our conference.[00:25:14] Simon: That one's fascinating to me. Like NotebookLM, I think it's two products, right? On the one hand, it's actually a very good rag product, right? You dump a bunch of things in, you can run searches, that, that, it does a good job of. And then, and then they added the, the podcast thing. It's a bit of a, it's a total gimmick, right?[00:25:30] Simon: But that gimmick got them attention, because they had a great product that nobody paid any attention to at all. And then you add the unfeasibly good voice synthesis of the podcast. Like, it's just, it's, it's, it's the lesson.[00:25:43] Brian: It's the lesson of mid journey and stuff like that. If you can create something that people can post on socials, you don't have to lift a finger again to do any marketing for what you're doing.[00:25:53] Brian: Let me dig into Notebook LLM just for a second as a podcaster. As a [00:26:00] gimmick, it makes sense, and then obviously, you know, you dig into it, it sort of has problems around the edges. It's like, it does the thing that all sort of LLMs kind of do, where it's like, oh, we want to Wrap up with a conclusion.[00:26:12] Multimodal AI and Future Prospects[00:26:12] Brian: I always call that like the the eighth grade book report paper problem where it has to have an intro and then, you know But that's sort of a thing where because I think you spoke about this again in your piece at the year end About how things are going multimodal and how things are that you didn't expect like, you know vision and especially audio I think So that's another thing where, at least over the last year, there's been progress made that maybe you, you didn't think was coming as quick as it came.[00:26:43] Simon: I don't know. I mean, a year ago, we had one really good vision model. We had GPT 4 vision, was, was, was very impressive. And Google Gemini had just dropped Gemini 1. 0, which had vision, but nobody had really played with it yet. Like Google hadn't. People weren't taking Gemini [00:27:00] seriously at that point. I feel like it was 1.[00:27:02] Simon: 5 Pro when it became apparent that actually they were, they, they got over their hump and they were building really good models. And yeah, and they, to be honest, the video models are mostly still using the same trick. The thing where you divide the video up into one image per second and you dump that all into the context.[00:27:16] Simon: So maybe it shouldn't have been so surprising to us that long context models plus vision meant that the video was, was starting to be solved. Of course, it didn't. Not being, you, what you really want with videos, you want to be able to do the audio and the images at the same time. And I think the models are beginning to do that now.[00:27:33] Simon: Like, originally, Gemini 1. 5 Pro originally ignored the audio. It just did the, the, like, one frame per second video trick. As far as I can tell, the most recent ones are actually doing pure multimodal. But the things that opens up are just extraordinary. Like, the the ChatGPT iPhone app feature that they shipped as one of their 12 days of, of OpenAI, I really can be having a conversation and just turn on my video camera and go, Hey, what kind of tree is [00:28:00] this?[00:28:00] Simon: And so forth. And it works. And for all I know, that's just snapping a like picture once a second and feeding it into the model. The, the, the things that you can do with that as an end user are extraordinary. Like that, that to me, I don't think most people have cottoned onto the fact that you can now stream video directly into a model because it, it's only a few weeks old.[00:28:22] Simon: Wow. That's a, that's a, that's a, that's Big boost in terms of what kinds of things you can do with this stuff. Yeah. For[00:28:30] swyx (2): people who are not that close I think Gemini Flashes free tier allows you to do something like capture a photo, one photo every second or a minute and leave it on 24, seven, and you can prompt it to do whatever.[00:28:45] swyx (2): And so you can effectively have your own camera app or monitoring app that that you just prompt and it detects where it changes. It detects for, you know, alerts or anything like that, or describes your day. You know, and, and, and the fact that this is free I think [00:29:00] it's also leads into the previous point of it being the prices haven't come down a lot.[00:29:05] Simon: And even if you're paying for this stuff, like a thing that I put in my blog entry is I ran a calculation on what it would cost to process 68, 000 photographs in my photo collection, and for each one just generate a caption, and using Gemini 1. 5 Flash 8B, it would cost me 1. 68 to process 68, 000 images, which is, I mean, that, that doesn't make sense.[00:29:28] Simon: None of that makes sense. Like it's, it's a, for one four hundredth of a cent per image to generate captions now. So you can see why feeding in a day's worth of video just isn't even very expensive to process.[00:29:40] swyx (2): Yeah, I'll tell you what is expensive. It's the other direction. So we're here, we're talking about consuming video.[00:29:46] swyx (2): And this year, we also had a lot of progress, like probably one of the most excited, excited, anticipated launches of the year was Sora. We actually got Sora. And less exciting.[00:29:55] Simon: We did, and then VO2, Google's Sora, came out like three [00:30:00] days later and upstaged it. Like, Sora was exciting until VO2 landed, which was just better.[00:30:05] swyx (2): In general, I feel the media, or the social media, has been very unfair to Sora. Because what was released to the world, generally available, was Sora Lite. It's the distilled version of Sora, right? So you're, I did not[00:30:16] Simon: realize that you're absolutely comparing[00:30:18] swyx (2): the, the most cherry picked version of VO two, the one that they published on the marketing page to the, the most embarrassing version of the soa.[00:30:25] swyx (2): So of course it's gonna look bad, so, well, I got[00:30:27] Simon: access to the VO two I'm in the VO two beta and I've been poking around with it and. Getting it to generate pelicans on bicycles and stuff. I would absolutely[00:30:34] swyx (2): believe that[00:30:35] Simon: VL2 is actually better. Is Sora, so is full fat Sora coming soon? Do you know, when, when do we get to play with that one?[00:30:42] Simon: No one's[00:30:43] swyx (2): mentioned anything. I think basically the strategy is let people play around with Sora Lite and get info there. But the, the, keep developing Sora with the Hollywood studios. That's what they actually care about. Gotcha. Like the rest of us. Don't really know what to do with the video anyway. Right.[00:30:59] Simon: I mean, [00:31:00] that's my thing is I realized that for generative images and images and video like images We've had for a few years and I don't feel like they've broken out into the talented artist community yet Like lots of people are having fun with them and doing and producing stuff. That's kind of cool to look at but what I want you know that that movie everything everywhere all at once, right?[00:31:20] Simon: One, one ton of Oscars, utterly amazing film. The VFX team for that were five people, some of whom were watching YouTube videos to figure out what to do. My big question for, for Sora and and and Midjourney and stuff, what happens when a creative team like that starts using these tools? I want the creative geniuses behind everything, everywhere all at once.[00:31:40] Simon: What are they going to be able to do with this stuff in like a few years time? Because that's really exciting to me. That's where you take artists who are at the very peak of their game. Give them these new capabilities and see, see what they can do with them.[00:31:52] swyx (2): I should, I know a little bit here. So it should mention that, that team actually used RunwayML.[00:31:57] swyx (2): So there was, there was,[00:31:57] Simon: yeah.[00:31:59] swyx (2): I don't know how [00:32:00] much I don't. So, you know, it's possible to overstate this, but there are people integrating it. Generated video within their workflow, even pre SORA. Right, because[00:32:09] Brian: it's not, it's not the thing where it's like, okay, tomorrow we'll be able to do a full two hour movie that you prompt with three sentences.[00:32:15] Brian: It is like, for the very first part of, of, you know video effects in film, it's like, if you can get that three second clip, if you can get that 20 second thing that they did in the matrix that blew everyone's minds and took a million dollars or whatever to do, like, it's the, it's the little bits and pieces that they can fill in now that it's probably already there.[00:32:34] swyx (2): Yeah, it's like, I think actually having a layered view of what assets people need and letting AI fill in the low value assets. Right, like the background video, the background music and, you know, sometimes the sound effects. That, that maybe, maybe more palatable maybe also changes the, the way that you evaluate the stuff that's coming out.[00:32:57] swyx (2): Because people tend to, in social media, try to [00:33:00] emphasize foreground stuff, main character stuff. So you really care about consistency, and you, you really are bothered when, like, for example, Sorad. Botch's image generation of a gymnast doing flips, which is horrible. It's horrible. But for background crowds, like, who cares?[00:33:18] Brian: And by the way, again, I was, I was a film major way, way back in the day, like, that's how it started. Like things like Braveheart, where they filmed 10 people on a field, and then the computer could turn it into 1000 people on a field. Like, that's always been the way it's around the margins and in the background that first comes in.[00:33:36] Brian: The[00:33:36] Simon: Lord of the Rings movies were over 20 years ago. Although they have those giant battle sequences, which were very early, like, I mean, you could almost call it a generative AI approach, right? They were using very sophisticated, like, algorithms to model out those different battles and all of that kind of stuff.[00:33:52] Simon: Yeah, I know very little. I know basically nothing about film production, so I try not to commentate on it. But I am fascinated to [00:34:00] see what happens when, when these tools start being used by the real, the people at the top of their game.[00:34:05] swyx (2): I would say like there's a cultural war that is more that being fought here than a technology war.[00:34:11] swyx (2): Most of the Hollywood people are against any form of AI anyway, so they're busy Fighting that battle instead of thinking about how to adopt it and it's, it's very fringe. I participated here in San Francisco, one generative AI video creative hackathon where the AI positive artists actually met with technologists like myself and then we collaborated together to build short films and that was really nice and I think, you know, I'll be hosting some of those in my events going forward.[00:34:38] swyx (2): One thing that I think like I want to leave it. Give people a sense of it's like this is a recap of last year But then sometimes it's useful to walk away as well with like what can we expect in the future? I don't know if you got anything. I would also call out that the Chinese models here have made a lot of progress Hyde Law and Kling and God knows who like who else in the video arena [00:35:00] Also making a lot of progress like surprising him like I think maybe actually Chinese China is surprisingly ahead with regards to Open8 at least, but also just like specific forms of video generation.[00:35:12] Simon: Wouldn't it be interesting if a film industry sprung up in a country that we don't normally think of having a really strong film industry that was using these tools? Like, that would be a fascinating sort of angle on this. Mm hmm. Mm hmm.[00:35:25] swyx (2): Agreed. I, I, I Oh, sorry. Go ahead.[00:35:29] Exploring Video Avatar Companies[00:35:29] swyx (2): Just for people's Just to put it on people's radar as well, Hey Jen, there's like there's a category of video avatar companies that don't specifically, don't specialize in general video.[00:35:41] swyx (2): They only do talking heads, let's just say. And HeyGen sings very well.[00:35:45] Brian: Swyx, you know that that's what I've been using, right? Like, have, have I, yeah, right. So, if you see some of my recent YouTube videos and things like that, where, because the beauty part of the HeyGen thing is, I, I, I don't want to use the robot voice, so [00:36:00] I record the mp3 file for my computer, And then I put that into HeyGen with the avatar that I've trained it on, and all it does is the lip sync.[00:36:09] Brian: So it looks, it's not 100 percent uncanny valley beatable, but it's good enough that if you weren't looking for it, it's just me sitting there doing one of my clips from the show. And, yeah, so, by the way, HeyGen. Shout out to them.[00:36:24] AI Influencers and Their Future[00:36:24] swyx (2): So I would, you know, in terms of like the look ahead going, like, looking, reviewing 2024, looking at trends for 2025, I would, they basically call this out.[00:36:33] swyx (2): Meta tried to introduce AI influencers and failed horribly because they were just bad at it. But at some point that there will be more and more basically AI influencers Not in a way that Simon is but in a way that they are not human.[00:36:50] Simon: Like the few of those that have done well, I always feel like they're doing well because it's a gimmick, right?[00:36:54] Simon: It's a it's it's novel and fun to like Like that, the AI Seinfeld thing [00:37:00] from last year, the Twitch stream, you know, like those, if you're the only one or one of just a few doing that, you'll get, you'll attract an audience because it's an interesting new thing. But I just, I don't know if that's going to be sustainable longer term or not.[00:37:11] Simon: Like,[00:37:12] Simplifying Content Creation with AI[00:37:12] Brian: I'm going to tell you, Because I've had discussions, I can't name the companies or whatever, but, so think about the workflow for this, like, now we all know that on TikTok and Instagram, like, holding up a phone to your face, and doing like, in my car video, or walking, a walk and talk, you know, that's, that's very common, but also, if you want to do a professional sort of talking head video, you still have to sit in front of a camera, you still have to do the lighting, you still have to do the video editing, versus, if you can just record, what I'm saying right now, the last 30 seconds, If you clip that out as an mp3 and you have a good enough avatar, then you can put that avatar in front of Times Square, on a beach, or whatever.[00:37:50] Brian: So, like, again for creators, the reason I think Simon, we're on the verge of something, it, it just, it's not going to, I think it's not, oh, we're going to have [00:38:00] AI avatars take over, it'll be one of those things where it takes another piece of the workflow out and simplifies it. I'm all[00:38:07] Simon: for that. I, I always love this stuff.[00:38:08] Simon: I like tools. Tools that help human beings do more. Do more ambitious things. I'm always in favor of, like, that, that, that's what excites me about this entire field.[00:38:17] swyx (2): Yeah. We're, we're looking into basically creating one for my podcast. We have this guy Charlie, he's Australian. He's, he's not real, but he pre, he opens every show and we are gonna have him present all the shorts.[00:38:29] Simon: Yeah, go ahead.[00:38:30] The Importance of Credibility in AI[00:38:30] Simon: The thing that I keep coming back to is this idea of credibility like in a world that is full of like AI generated everything and so forth It becomes even more important that people find the sources of information that they trust and find people and find Sources that are credible and I feel like that's the one thing that LLMs and AI can never have is credibility, right?[00:38:49] Simon: ChatGPT can never stake its reputation on telling you something useful and interesting because That means nothing, right? It's a matrix multiplication. It depends on who prompted it and so forth. So [00:39:00] I'm always, and this is when I'm blogging as well, I'm always looking for, okay, who are the reliable people who will tell me useful, interesting information who aren't just going to tell me whatever somebody's paying them to tell, tell them, who aren't going to, like, type a one sentence prompt into an LLM and spit out an essay and stick it online.[00:39:16] Simon: And that, that to me, Like, earning that credibility is really important. That's why a lot of my ethics around the way that I publish are based on the idea that I want people to trust me. I want to do things that, that gain credibility in people's eyes so they will come to me for information as a trustworthy source.[00:39:32] Simon: And it's the same for the sources that I'm, I'm consulting as well. So that's something I've, I've been thinking a lot about that sort of credibility focus on this thing for a while now.[00:39:40] swyx (2): Yeah, you can layer or structure credibility or decompose it like so one thing I would put in front of you I'm not saying that you should Agree with this or accept this at all is that you can use AI to generate different Variations and then and you pick you as the final sort of last mile person that you pick The last output and [00:40:00] you put your stamp of credibility behind that like that everything's human reviewed instead of human origin[00:40:04] Simon: Yeah, if you publish something you need to be able to put it on the ground Publishing it.[00:40:08] Simon: You need to say, I will put my name to this. I will attach my credibility to this thing. And if you're willing to do that, then, then that's great.[00:40:16] swyx (2): For creators, this is huge because there's a fundamental asymmetry between starting with a blank slate versus choosing from five different variations.[00:40:23] Brian: Right.[00:40:24] Brian: And also the key thing that you just said is like, if everything that I do, if all of the words were generated by an LLM, if the voice is generated by an LLM. If the video is also generated by the LLM, then I haven't done anything, right? But if, if one or two of those, you take a shortcut, but it's still, I'm willing to sign off on it.[00:40:47] Brian: Like, I feel like that's where I feel like people are coming around to like, this is maybe acceptable, sort of.[00:40:53] Simon: This is where I've been pushing the definition. I love the term slop. Where I've been pushing the definition of slop as AI generated [00:41:00] content that is both unrequested and unreviewed and the unreviewed thing is really important like that's the thing that elevates something from slop to not slop is if A human being has reviewed it and said, you know what, this is actually worth other people's time.[00:41:12] Simon: And again, I'm willing to attach my credibility to it and say, hey, this is worthwhile.[00:41:16] Brian: It's, it's, it's the cura curational, curatorial and editorial part of it that no matter what the tools are to do shortcuts, to do, as, as Swyx is saying choose between different edits or different cuts, but in the end, if there's a curatorial mind, Or editorial mind behind it.[00:41:32] Brian: Let me I want to wedge this in before we start to close.[00:41:36] The Future of LLM User Interfaces[00:41:36] Brian: One of the things coming back to your year end piece that has been a something that I've been banging the drum about is when you're talking about LLMs. Getting harder to use. You said most users are thrown in at the deep end.[00:41:48] Brian: The default LLM chat UI is like taking brand new computer users, dropping them into a Linux terminal and expecting them to figure it all out. I mean, it's, it's literally going back to the command line. The command line was defeated [00:42:00] by the GUI interface. And this is what I've been banging the drum about is like, this cannot be.[00:42:05] Brian: The user interface, what we have now cannot be the end result. Do you see any hints or seeds of a GUI moment for LLM interfaces?[00:42:17] Simon: I mean, it has to happen. It absolutely has to happen. The the, the, the, the usability of these things is turning into a bit of a crisis. And we are at least seeing some really interesting innovation in little directions.[00:42:28] Simon: Just like OpenAI's chat GPT canvas thing that they just launched. That is at least. Going a little bit more interesting than just chat, chats and responses. You know, you can, they're exploring that space where you're collaborating with an LLM. You're both working in the, on the same document. That makes a lot of sense to me.[00:42:44] Simon: Like that, that feels really smart. The one of the best things is still who was it who did the, the UI where you could, they had a drawing UI where you draw an interface and click a button. TL draw would then make it real thing. That was spectacular, [00:43:00] absolutely spectacular, like, alternative vision of how you'd interact with these models.[00:43:05] Simon: Because yeah, the and that's, you know, so I feel like there is so much scope for innovation there and it is beginning to happen. Like, like, I, I feel like most people do understand that we need to do better in terms of interfaces that both help explain what's going on and give people better tools for working with models.[00:43:23] Simon: I was going to say, I want to[00:43:25] Brian: dig a little deeper into this because think of the conceptual idea behind the GUI, which is instead of typing into a command line open word. exe, it's, you, you click an icon, right? So that's abstracting away sort of the, again, the programming stuff that like, you know, it's, it's a, a, a child can tap on an iPad and, and make a program open, right?[00:43:47] Brian: The problem it seems to me right now with how we're interacting with LLMs is it's sort of like you know a dumb robot where it's like you poke it and it goes over here, but no, I want it, I want to go over here so you poke it this way and you can't get it exactly [00:44:00] right, like, what can we abstract away from the From the current, what's going on that, that makes it more fine tuned and easier to get more precise.[00:44:12] Brian: You see what I'm saying?[00:44:13] Simon: Yes. And the this is the other trend that I've been following from the last year, which I think is super interesting. It's the, the prompt driven UI development thing. Basically, this is the pattern where Claude Artifacts was the first thing to do this really well. You type in a prompt and it goes, Oh, I should answer that by writing a custom HTML and JavaScript application for you that does a certain thing.[00:44:35] Simon: And when you think about that take and since then it turns out This is easy, right? Every decent LLM can produce HTML and JavaScript that does something useful. So we've actually got this alternative way of interacting where they can respond to your prompt with an interactive custom interface that you can work with.[00:44:54] Simon: People haven't quite wired those back up again. Like, ideally, I'd want the LLM ask me a [00:45:00] question where it builds me a custom little UI, For that question, and then it gets to see how I interacted with that. I don't know why, but that's like just such a small step from where we are right now. But that feels like such an obvious next step.[00:45:12] Simon: Like an LLM, why should it, why should you just be communicating with, with text when it can build interfaces on the fly that let you select a point on a map or or move like sliders up and down. It's gonna create knobs and dials. I keep saying knobs and dials. right. We can do that. And the LLMs can build, and Claude artifacts will build you a knobs and dials interface.[00:45:34] Simon: But at the moment they haven't closed the loop. When you twiddle those knobs, Claude doesn't see what you were doing. They're going to close that loop. I'm, I'm shocked that they haven't done it yet. So yeah, I think there's so much scope for innovation and there's so much scope for doing interesting stuff with that model where the LLM, anything you can represent in SVG, which is almost everything, can now be part of that ongoing conversation.[00:45:59] swyx (2): Yeah, [00:46:00] I would say the best executed version of this I've seen so far is Bolt where you can literally type in, make a Spotify clone, make an Airbnb clone, and it actually just does that for you zero shot with a nice design.[00:46:14] Simon: There's a benchmark for that now. The LMRena people now have a benchmark that is zero shot app, app generation, because all of the models can do it.[00:46:22] Simon: Like it's, it's, I've started figuring out. I'm building my own version of this for my own project, because I think within six months. I think it'll just be an expected feature. Like if you have a web application, why don't you have a thing where, oh, look, the, you can add a custom, like, so for my dataset data exploration project, I want you to be able to do things like conjure up a dashboard, just via a prompt.[00:46:43] Simon: You say, oh, I need a pie chart and a bar chart and put them next to each other, and then have a form where submitting the form inserts a row into my database table. And this is all suddenly feasible. It's, it's, it's not even particularly difficult to do, which is great. Utterly bizarre that these things are now easy.[00:47:00][00:47:00] swyx (2): I think for a general audience, that is what I would highlight, that software creation is becoming easier and easier. Gemini is now available in Gmail and Google Sheets. I don't write my own Google Sheets formulas anymore, I just tell Gemini to do it. And so I think those are, I almost wanted to basically somewhat disagree with, with your assertion that LMS got harder to use.[00:47:22] swyx (2): Like, yes, we, we expose more capabilities, but they're, they're in minor forms, like using canvas, like web search in, in in chat GPT and like Gemini being in, in Excel sheets or in Google sheets, like, yeah, we're getting, no,[00:47:37] Simon: no, no, no. Those are the things that make it harder, because the problem is that for each of those features, they're amazing.[00:47:43] Simon: If you understand the edges of the feature, if you're like, okay, so in Google, Gemini, Excel formulas, I can get it to do a certain amount of things, but I can't get it to go and read a web. You probably can't get it to read a webpage, right? But you know, there are, there are things that it can do and things that it can't do, which are completely undocumented.[00:47:58] Simon: If you ask it what it [00:48:00] can and can't do, they're terrible at answering questions about that. So like my favorite example is Claude artifacts. You can't build a Claude artifact that can hit an API somewhere else. Because the cause headers on that iframe prevents accessing anything outside of CDNJS. So, good luck learning cause headers as an end user in order to understand why Like, I've seen people saying, oh, this is rubbish.[00:48:26] Simon: I tried building an artifact that would run a prompt and it couldn't because Claude didn't expose an API with cause headers that all of this stuff is so weird and complicated. And yeah, like that, that, the more that with the more tools we add, the more expertise you need to really, To understand the full scope of what you can do.[00:48:44] Simon: And so it's, it's, I wouldn't say it's, it's, it's, it's like, the question really comes down to what does it take to understand the full extent of what's possible? And honestly, that, that's just getting more and more involved over time.[00:48:58] Local LLMs: A Growing Interest[00:48:58] swyx (2): I have one more topic that I, I [00:49:00] think you, you're kind of a champion of and we've touched on it a little bit, which is local LLMs.[00:49:05] swyx (2): And running AI applications on your desktop, I feel like you are an early adopter of many, many things.[00:49:12] Simon: I had an interesting experience with that over the past year. Six months ago, I almost completely lost interest. And the reason is that six months ago, the best local models you could run, There was no point in using them at all, because the best hosted models were so much better.[00:49:26] Simon: Like, there was no point at which I'd choose to run a model on my laptop if I had API access to Cloud 3. 5 SONNET. They just, they weren't even comparable. And that changed, basically, in the past three months, as the local models had this step changing capability, where now I can run some of these local models, and they're not as good as Cloud 3.[00:49:45] Simon: 5 SONNET, but they're not so far away that It's not worth me even using them. The other, the, the, the, the continuing problem is I've only got 64 gigabytes of RAM, and if you run, like, LLAMA370B, it's not going to work. Most of my RAM is gone. So now I have to shut down my Firefox tabs [00:50:00] and, and my Chrome and my VS Code windows in order to run it.[00:50:03] Simon: But it's got me interested again. Like, like the, the efficiency improvements are such that now, if you were to like stick me on a desert island with my laptop, I'd be very productive using those local models. And that's, that's pretty exciting. And if those trends continue, and also, like, I think my next laptop, if when I buy one is going to have twice the amount of RAM, At which point, maybe I can run the, almost the top tier, like open weights models and still be able to use it as a computer as well.[00:50:32] Simon: NVIDIA just announced their 3, 000 128 gigabyte monstrosity. That's pretty good price. You know, that's that's, if you're going to buy it,[00:50:42] swyx (2): custom OS and all.[00:50:46] Simon: If I get a job, if I, if, if, if I have enough of an income that I can justify blowing $3,000 on it, then yes.[00:50:52] swyx (2): Okay, let's do a GoFundMe to get Simon one it.[00:50:54] swyx (2): Come on. You know, you can get a job anytime you want. Is this, this is just purely discretionary .[00:50:59] Simon: I want, [00:51:00] I want a job that pays me to do exactly what I'm doing already and doesn't tell me what else to do. That's, thats the challenge.[00:51:06] swyx (2): I think Ethan Molik does pretty well. Whatever, whatever it is he's doing.[00:51:11] swyx (2): But yeah, basically I was trying to bring in also, you know, not just local models, but Apple intelligence is on every Mac machine. You're, you're, you seem skeptical. It's rubbish.[00:51:21] Simon: Apple intelligence is so bad. It's like, it does one thing well.[00:51:25] swyx (2): Oh yeah, what's that? It summarizes notifications. And sometimes it's humorous.[00:51:29] Brian: Are you sure it does that well? And also, by the way, the other, again, from a sort of a normie point of view. There's no indication from Apple of when to use it. Like, everybody upgrades their thing and it's like, okay, now you have Apple Intelligence, and you never know when to use it ever again.[00:51:47] swyx (2): Oh, yeah, you consult the Apple docs, which is MKBHD.[00:51:49] swyx (2): The[00:51:51] Simon: one thing, the one thing I'll say about Apple Intelligence is, One of the reasons it's so disappointing is that the models are just weak, but now, like, Llama 3b [00:52:00] is Such a good model in a 2 gigabyte file I think give Apple six months and hopefully they'll catch up to the state of the art on the small models And then maybe it'll start being a lot more interesting.[00:52:10] swyx (2): Yeah. Anyway, I like This was year one And and you know just like our first year of iPhone maybe maybe not that much of a hit and then year three They had the App Store so Hey I would say give it some time, and you know, I think Chrome also shipping Gemini Nano I think this year in Chrome, which means that every app, every web app will have for free access to a local model that just ships in the browser, which is kind of interesting.[00:52:38] swyx (2): And then I, I think I also wanted to just open the floor for any, like, you know, any of us what are the apps that, you know, AI applications that we've adopted that have, that we really recommend because these are all, you know, apps that are running on our browser that like, or apps that are running locally that we should be, that, that other people should be trying.[00:52:55] swyx (2): Right? Like, I, I feel like that's, that's one always one thing that is helpful at the start of the [00:53:00] year.[00:53:00] Simon: Okay. So for running local models. My top picks, firstly, on the iPhone, there's this thing called MLC Chat, which works, and it's easy to install, and it runs Llama 3B, and it's so much fun. Like, it's not necessarily a capable enough novel that I use it for real things, but my party trick right now is I get my phone to write a Netflix Christmas movie plot outline where, like, a bunch of Jeweller falls in love with the King of Sweden or whatever.[00:53:25] Simon: And it does a good job and it comes up with pun names for the movies. And that's, that's deeply entertaining. On my laptop, most recently, I've been getting heavy into, into Olama because the Olama team are very, very good at finding the good models and patching them up and making them work well. It gives you an API.[00:53:42] Simon: My little LLM command line tool that has a plugin that talks to Olama, which works really well. So that's my, my Olama is. I think the easiest on ramp to to running models locally, if you want a nice user interface, LMStudio is, I think, the best user interface [00:54:00] thing at that. It's not open source. It's good.[00:54:02] Simon: It's worth playing with. The other one that I've been trying with recently, there's a thing called, what's it called? Open web UI or something. Yeah. The UI is fantastic. It, if you've got Olama running and you fire this thing up, it spots Olama and it gives you an interface onto your Olama models. And that's really nicely done.[00:54:19] Simon: That's that, that, that, that's, that's my current favorite, like open source UI for these things. But yeah, so there's lots of good options. You do need a lot of disk space. Like the, the, the models are, the, the best, the, the models start at two gigabytes for like the 3B models that are actually worth playing with.[00:54:35] Simon: The, the really impressive ones tend to be in the sort of 20 to 30 gigabyte range in my experience.[00:54:40] swyx (2): Yeah, I think my, my struggle here is I'm not that much of a absolutist in terms of running things locally. Like I'm happy to call an API. Same here. I do it to play.[00:54:53] Simon: It's my research interest, yeah. When people[00:54:55] swyx (2): get so excited[00:54:56] Brian: Answer your own question.[00:54:59] swyx (2): Like, give us [00:55:00] more apps that you wanna Yeah, sometimes it's like, it's just nice to recommend apps. So, I use SuperWhisperer now. I tried WhisperFlow, didn't really work for me. SuperWhisperer is one of them, which basically replaces typing. Like, you should just type. Talk, most of the time, especially if you're doing anything long form.[00:55:19] swyx (2): You hold, I hold down caps lock and I, and I talk. And then when I'm done, I lift it up and it uses, it doesn't, it's not just about writing down your transcripts because I make ums and ahs all the time. I restate myself, myself all the time, but it uses GPT 4 to rewrite. And that's what these guys are doing.[00:55:33] swyx (2): They're all doing some form of state of the art ASR, automatic speech recognition, and then, and then and LLM to rewrite. And then I think I would also recommend. For people to check out Rosebud for journaling. I think AI for mental health is quite unexplored and it's not because we are trying to build AI therapists.[00:55:51] swyx (2): I think the therapists really hate that. You'll, you'll never be on the level of therapist that, that gets back to the human[00:55:57] Brian: thing that we were discussing, you know, on, on, [00:56:00] on some level. There are certain things and disciplines that require the human touch and that might be sure.[00:56:05] swyx (2): But the human touch cost me 300 an hour, right?[00:56:09] swyx (2): And then this thing's, this thing's 3 a month, you know. So there's a, there's a spectrum of people for, for whom that will work. And I think it's, it's cheap now to try all these things.[00:56:21] Simon: I'm going to throw in a quick recommendation for an app. Mac Whisper is my favorite desktop app. I love that thing.[00:56:29] Simon: It runs Whisper, and you can do things like you can paste in the URL to a YouTube video and it'll pull the audio and give you a transcript. So, that's how I watch YouTube now, is I slap it into Mac Whisper, and then I hit copy and paste into Claude, and then I use the Claude web app to do things. But Mac Whisper, it works with mp3 files.[00:56:46] Simon: Every time I'm on a podcast, I dump the mp3 into Mac Whisper, then I dump the transcript into Claude and say, And What should I put in the show notes? And it spits out a bullet point list where it says, Oh, you mentioned, like, data set that you should link to that, that kind of thing. [00:57:00] Stuff like that, that's Mac Whisperer, I use it several times a day, to be honest.[00:57:03] Simon: Like, it's, it's, it's great. Yeah.[00:57:05] Brian: I'm actually, I'm going to say one that is incredibly super basic, and again, coming back to just my workflow, but we are currently recording this on Riverside. Riverside is a great tool for recording video, audio things like we're doing right now, but I always use this as an example to folks when they're like, well, how, what will AI do for me when I first started using Riverside, like we're recording three different channels right now.[00:57:29] Brian: Right. You guys are recording locally, so there's three audio files, three video files. And then, when I first started using Riverside, you had to pump three tracks into Adobe and then edit. Okay, now we focus on Simon, now we focus on Swyx, now we focus on Brian, now we do all three. And then one day, a tool popped up that says hit this button, and it's smart edit.[00:57:52] Brian: And then, the AI determines, okay, Simon has been talking for 30 minutes, so go to the full shot of him. [00:58:00] And Brian is now talking, or there's overtalk, so let's have all three talking heads. With one button, for anything I posted, it saved me Three or four hours worth of work. That, to me, is like, again, if normies are listening[00:58:14] Simon: Riverside has that feature now.[00:58:15] Brian: Yeah.[00:58:15] swyx (2): Yeah. Yeah.[00:58:17] Simon: Damn. I don't use it. Oh, that[00:58:18] swyx (2): sounds fantastic. I still use a human editor.[00:58:21] Brian: The day it came out, I was running around the house, telling my wife, telling anyone that would listen, you don't know, I just saved three hours because they had a new feature. Like, that's That's exciting. Brian's[00:58:32] swyx (2): basically crying with joy right now.[00:58:35] Brian: Alright let's, let's try to bring this to a landing a little bit. Simon, I have about maybe two or three more. We can do these rapid fire. Cool. One of my shows, one of the things of my show is, it's sort of like Silicon Valley writ large, so it's sort of like the horse race of who's up and who's down or whatever.[00:58:52] Brian: To the degree that you're interested in pontificating on this, OpenAI is a company in 2025. Do you [00:59:00] see challenges coming? Are you bearish, bullish? I almost, I'm doing a CNBC sort of thing, but like, how do you feel about OpenAI this year?[00:59:06] Simon: I think, I think they're in a bit of trouble. They seem to have lost a lot of talent.[00:59:10] Simon: Like, they're losing, and they don't have that, if it wasn't for O3, they'd be in massive trouble, because they'd have lost that, like, top of the pile thing. I think O3 clawed them back up again, but one of the big stories of 2024 is OpenAI started as the clear leader. And now, Google Gemini is really good, like, Google Gemini had an amazing year.[00:59:28] Simon: Anthropic Claude, Claude 3. 5 Sonnet is still my personal favorite model. And that feels notable, like, like, OpenAI went from, like, nobody would argue they were not the, the leader in all of this stuff a year ago, and today, They're still doing great, but they're not, like, as far ahead as they were.[00:59:47] Brian: Next question, and maybe this couldn't be as rapid fire, but I loved, finally, from your piece, the idea that LLMs need better criticism, which I'd love you to expand on, because as I sort of straddle this world of tech journalism and [01:00:00] creator and investor and all that stuff I thought that you had a really interesting thing to say about how, and we even alluded to this about, like, Hollywood being against it, like, Better criticism in the sense that, as I took it, everybody is sort of, they've got their hackles up, they're trying to defend their livelihoods and things like that.[01:00:19] Brian: But it's either, this is gonna destroy my job and destroy the world, or, like, I'm, sorry, I'm again leading the witness. What did you mean by LLMs need better criticism?[01:00:30] Simon: So this is a frustration I have, that I, like, if I read a discussion thread somewhere about, on this topic, I can predict exactly what everyone's going to say.[01:00:38] Simon: People talk about the environmental impact, they talk about the plagiarism of the training data, the unlicensed training data. They'll, there's often this sort of, oh, and these things are completely useless thing. That's the one that I will push back against. The other things are true, right? The, the idea that LLMs are just completely useless, that the, the argument I always make there is, they are Very useful, if you understand how to use them, which is distinctly [01:01:00] unintuitive.[01:01:00] Simon: Like, you have to learn how to deal with something that will just wildly hallucinate and make things up, and all of those kinds of things. If you can learn how to, what they're good at and what they're bad at, I use them dozens of times a day, and I get enormous value out of them. So I'll push back on people who say, no, they're just useless.[01:01:16] Simon: But the other things, you know, the environmental impact of the, the way the training data works, I feel like the training data one's interesting, because It's probably legal under fair use, but it's clearly unfair if somebody takes your work without your permission and trains a model which then competes with you in the marketplace.[01:01:33] Simon: Like, like, legal or not, that, that, that's, that's, I, I understand why people are upset about that, that, that's a reasonable thing to be upset by. So What I want, and I also feel like the impact that this stuff can have on society, especially as it starts undermining all sorts of jobs that we never thought were going to be undermined by technology.[01:01:50] Simon: Like, who thought it would come for artists and lawyers first, right? That's bizarre. We need to have really high quality conversations where we help people figure out what works, what doesn't [01:02:00] work. We need people to be able to make good decisions about what to do with their careers to embrace this stuff and all of that sort of stuff.[01:02:06] Simon: And if we just get distracted by saying, yeah, but it's, it's, it's useless plagiarism driven, like environmental vent, vently contrast catastrophic. Even though those things represent quite a lot of truth, I don't think that that's a useful message to, to lead with. Like, I want to be having the much more interesting high level conversations.[01:02:24] Simon: Oh, okay. Well, if there are negatives, how do we, what do we do to counter those negatives? If there are positives, how do we encourage those? How do we help people make good decisions about how to use this technology?[01:02:36] swyx (2): I, I think, I, where I see this the most is for people who are kind of very in internal, like sort of you and I are immersed in this every single day, so we're frankly tired of the same debates being recycled again and again.[01:02:50] swyx (2): I think what might be more useful or, you know, More impactful is the level at which it starts to hit regulation. Last year, we had a couple [01:03:00] of very notable attempts at the White House level and in the California level to regulate AI, and those did not come to pass. But at some point, these criticisms bubble up to law, to matters of national security or national Science in progress.[01:03:17] swyx (2): And I, like, I feel like there needs to be more information or enlightenment there, maybe? If only because it tends to be that they're very trailing. Like the, you know, my favorite example to pick on, which is very unfair of me, but whatever you know, the, the California SB 1047 Act tried to cap compute at 10 to the power 25.[01:03:38] swyx (2): So that's a deep sink. Exactly. Well, it also is exactly at the point at which we pivoted from training GPT 5 to O1, where there is no longer scaling pre trained compute. What I'm saying is like, we're always trying to regulate the last war, and I don't think that works in a field that is basically 8 years old.[01:04:00][01:04:00] Simon: I think I've got, there are two, there are two areas of regulation I'm super interested in that, that, that one of them is I do think that regulating the way these things are used can work. The big example is I don't want somebody's insurance claim denied by a black box LLM where nobody can explain what it did.[01:04:16] Simon: Like that just feels Oh, we have laws for[01:04:17] Speaker 4: that. Exactly.[01:04:18] Simon: This is like gridlining. Well Yeah, take those laws, reinforce them, update them for modern capabilities. And then the other one there's some really interesting stuff around privacy. Like we've got this huge problem right now where People will refuse to use any of these tools because they don't trust that the things they say to it won't be trained on and then exposed to other people.[01:04:37] Simon: And there are lots of terms and conditions that you can read through and try and navigate around. I would love there to be just really straightforward laws that people understand where They know that it's not going to train on their input because there's a law that says under these circumstances that that can't happen.[01:04:52] Simon: Like that sort of stuff, like, like, it's basically taking our existing privacy laws and giving them a few more teeth and just reinforcing them without [01:05:00] introducing cookie banners a la the European Union, right? There's, these things are always very, it's very risky to try and get this stuff right because you can have all sorts of bad results if you don't design them correctly, but that, that's, there's space for that, I think.[01:05:15] Brian: Yeah, I, when I read that piece, and then when you just said you know Swyx said we, we're in the weeds on this every single day, so we're tired of hearing these arguments. It reminds me of folks that are always into politics, and then they're like, They're mad at the people that don't care about politics until it's an election year.[01:05:34] Brian: And then they're like, well, you're a low information voter because all you know is that the factory in your town got shut down or there's inflation or whatever. And so you vote one way or the other, but you haven't been paying attention. But that's kind of the point. So, what I'm trying to say is that you shouldn't expect normal people to pay attention, except for the fact that, oh, this might lose me my job.[01:05:52] Brian: So you can't, you can't blame them for being, I don't know, reactionary is the word, or emotional. But, [01:06:00] right if you're in the weeds, it's harder to, to keep up. Everybody informed, and this is gonna touch everybody. So I dunno. Okay, so this is the very last one. And then, and then we can wrap and, and do plugs and everything.[01:06:12] Brian: But Simon, this is for you. It was kind of alluded to a little bit, and you might not have one, but if there's something this year that an a generalist like me is not aware that is coming down the pike that you think is gonna be big in the AI space. And maybe Shawn, if you've got one too what do you think it would be?[01:06:31] Simon: I think for most people who haven't been paying attention, we know these things already. We know that the models are now almost free to run things against. The the fact that you can now do video, like stream video to a model, the one that I've not played with nearly as much, but the thing where you can share your entire screen with a model and get feedback there, that's going to be really useful.[01:06:49] Simon: Like that's, Again, the privacy side of things really matters though. I do not want some model just training on everything that it sees on my screen, but no, there's that, that I feel like, like, the [01:07:00] stuff that is now possible as of a few months ago is, is, that's enough. I don't need anything new. That's going to keep me busy all year.[01:07:07] swyx (2): Swyx are you going? Simon's always too content, and then he sees the next thing and he's like, Oh yeah, that's great too. Okay, I love trying to be contrarian by saying, What does everyone hate right now?[01:07:22] AI Wearables: The Next Big Thing[01:07:22] swyx (2): Remember this time last year, we just had CES, Rabbit R1, we had the humane, Wearables, wearables, yep.[01:07:29] swyx (2): Those are completely in the gutter, no one will touch them, they're toxic nuclear waste. Okay, this year is the year of wearables.[01:07:36] Brian: Yep, yep. I agree with you. By the way, that cycle, that cycle always works out where, like, you go to a CES and it's everything, hype, hype, hype, hype, and then three years later it becomes the thing, unless it's 3D TVs, in which case that was a mistake anyway.[01:07:52] Brian: But yeah.[01:07:53] Simon: Transparent TVs are the big thing for the last couple of years. What the hell?[01:07:56] swyx (2): Yeah you know, so I think Simon may have got one of these, [01:08:00] but there are a lot of people working on AI wearables here in SF. They are surprisingly cheap, surprisingly capable and with decent battery life, and they do useful things.[01:08:09] swyx (2): We have to work out the privacy aspect, of course. But people like Limitless which used to be called re privacy. I think they're shipping one of these wearables that based on your voice only records your voice. So you opted. Interesting. Right. Right. And so you can have perfect memory if you want.[01:08:26] swyx (2): You can have perfect memory at work. Your employer can buy these for you that only, it only applies at work and it's fine. It's, it's just a meeting aid. Lots of people use granola or some kind of fireflies or like some of these meeting recorders only for, for meetings. Online meetings. But what about in person meetings?[01:08:41] swyx (2): What about conversations and locations? That you've been? And some of that should be a choice. Right now you have zero choice you, and I think these wearables will enable some of that. And it's, it's up to us as a society to determine what's Acceptable and what's not. I really like these gray areas where we still don't know [01:09:00] yet.[01:09:00] swyx (2): People, whenever I tell people about this, they're like, I don't know, like, I'm sure I guess it's like, as though you have perfect memory. But some people have better memory than others. Like, Where's the light?[01:09:12] Brian: And there will be a lot more of these. I would add to that because Swyx, as you know, because you listen to my show the idea that AI has taken the smart glasses and completely changed everyone's mind about that as a product category and form factor.[01:09:28] Brian: And I should say this. From things that I've been looking at investing in wait till you see what they can add on to earbuds. Like, like the earbuds in your ear can do a lot more things than they're doing now and then you combine that with smart glasses, And you combine that with an LLM that you can access, maybe with a a phone as like the, the mothership.[01:09:48] Brian: There's some interesting things. The CES next year is gonna be crazy if you think wearables are crazy. AI wearables are a thing. Anyway, this year they were not a thing.[01:09:57] swyx (2): There[01:09:57] Brian: were[01:09:57] swyx (2): very much no wearables this[01:09:59] Simon: [01:10:00] year. This one's interesting as well, because the thing that makes these interesting is multimodal, like audio input, video input, image input, which a year ago was hardly a thing, and now it's dirt cheap.[01:10:11] Simon: So yeah, we're 12 months ago to build the software behind this stuff.[01:10:16] Brian: Yeah, all right.[01:10:16] Wrapping Up and Final Thoughts[01:10:16] Brian: Let's let's let's bring this to a landing. Swyx, go first. Tell everybody about obviously your podcast, which hopefully we're simulcasting, but also your conferences, events, everything.[01:10:30] swyx (2): Sure, yeah, you can find my work on latent.[01:10:33] swyx (2): space, it's the AI engineer podcast much more sort of focused on serving engineers and developers than the general audience, but you know, feel free to dive in to the deep end with us, and we are also hosting a conference in New York in February. The AI engineers summit where we gather people and this one is entirely focused on agents.[01:10:54] swyx (2): As much as you know, people like to make fun of the idea that every year is the year of agents at work I think people at [01:11:00] least want to gather to figure out what are the open problems to solve. And so these are the These are the community of builders that get together, they show their latest work like, like I have Instacart coming to show how they use agents for their recommendation system and their, their sort of background jobs and internal jobs and we have a whole bunch of like sort of financial tech company FinTech or finance companies also showing off their work that I cannot name yet, but it'll be lots of fun.[01:11:23] swyx (2): We, we, we do high quality events that sometimes people like Simon speak at.[01:11:28] Brian: And that right as I said, or I think I said online or on air that I saw Simon speak at one of your events last year. Wait Swyx, just say again, it's in February. It's in New York City. I'm going to be there if that matters to anybody, if that's an attraction, but what's the dates on that and how to apply.[01:11:43] swyx (2): I'm horrible at this. February 20th is the leadership day for management, like VPs of AI CTOs. And 21st is the engineer day, the individual contributors, hands on keyboard people. And that's when I'll have the big labs. So DeepMind, Anthropic, Meta, [01:12:00] OpenAI, all coming to share their agents work. And then we'll have some new launches as well that you haven't heard of.[01:12:06] Brian: And to sign up to attend what website can I go to? Yeah, it's apply. ai. engineer. All right, Simon, I'm gonna, I'm gonna hold hand you, or handhold you even more. Your weblog is simonwillison. net, but what else would you like us to know or, or go find out about what you're doing?[01:12:22] Simon: Yeah, I was gonna say my blog my other, my, my day, my day job, I call it a job is I work on open source tools for data journalism.[01:12:29] Simon: That's my project. Dataset, spelt like the word cassette, but data dataset. io. And that's beginning to grow some interesting AI tools. Like originally it was all about data publishing and exploration and analysis. And now I'm like, okay, well, what plugins for that can I build that you use, let you use LLMs to craft queries and build dashboards and all sorts of bits and pieces like that.[01:12:50] Simon: So I'm expecting to have some really interesting product features along those lines in the, in the next few months.[01:12:56] Brian: And I'll end by saying, if anyone's listening to this on SWYX's [01:13:00] show I do the TechMeme Ride Home every single weekday, 15 minute long tech news podcast. Look up Ride Home on your podcast app of choice.[01:13:08] Brian: TechMeme Ride Home. Gentlemen, thank you for your time. Thank you. This was fantastic. What a great way to start the year for, for this show.[01:13:16] Simon: Cool. Thanks a lot for having me. This has been really fun. Yeah, thanks for having us. Honored to be on. Get full access to Latent.Space at www.latent.space/subscribe
-
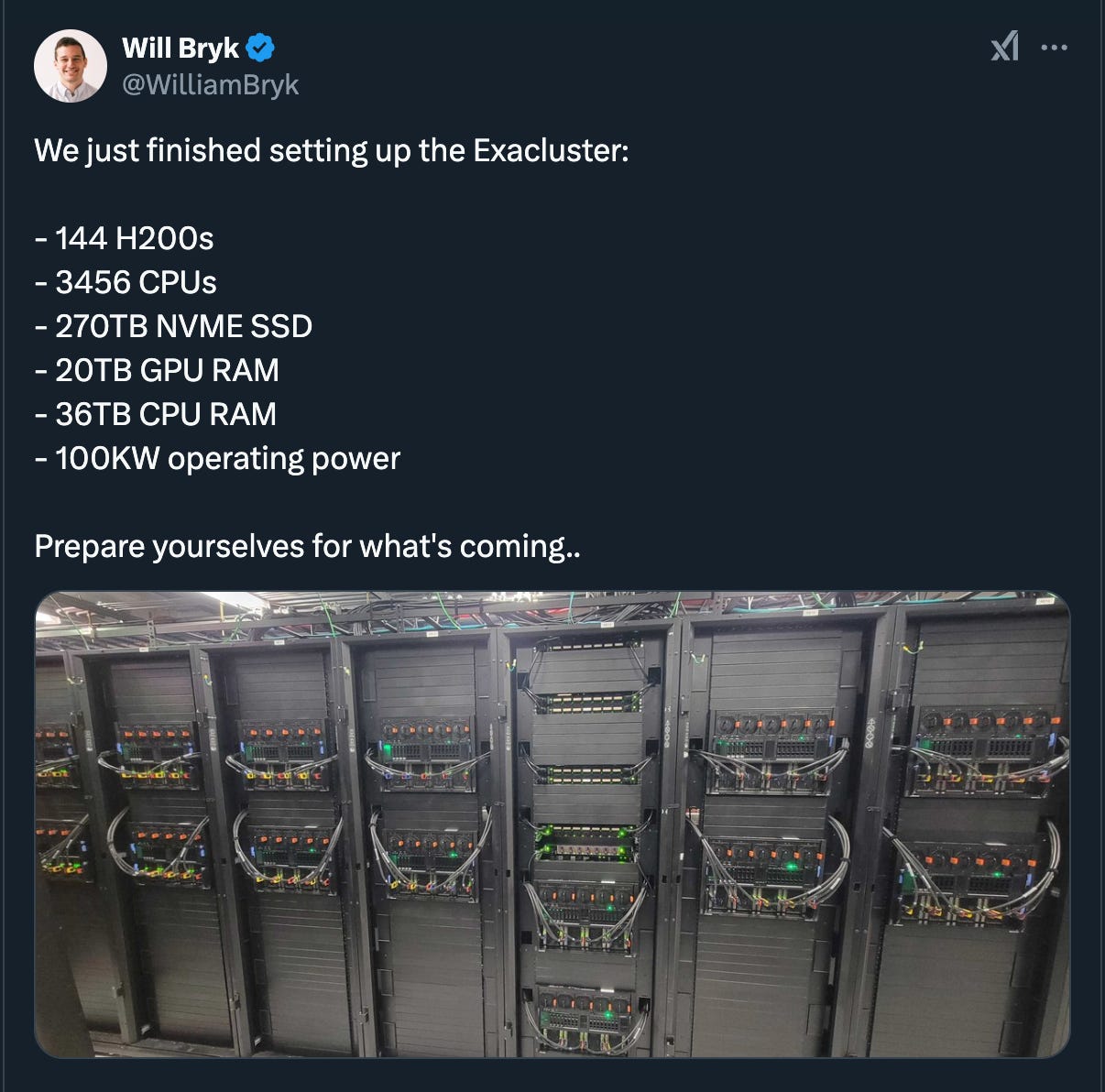 Beating Google at Search with Neural PageRank and $5M of H200s — with Will Bryk of Exa.ai
Beating Google at Search with Neural PageRank and $5M of H200s — with Will Bryk of Exa.aiFrom 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2025-01-10 19:25
Applications close Monday for the NYC AI Engineer Summit focusing on AI Leadership and Agent Engineering! If you applied, invites should be rolling out shortly.The search landscape is experiencing a fundamental shift. Google built a >$2T company with the “10 blue links” experience, driven by PageRank as the core innovation for ranking. This was a big improvement from the previous directory-based experiences of AltaVista and Yahoo. Almost 4 decades later, Google is now stuck in this links-based experience, especially from a business model perspective. This legacy architecture creates fundamental constraints:* Must return results in ~400 milliseconds* Required to maintain comprehensive web coverage* Tied to keyword-based matching algorithms* Cost structures optimized for traditional indexingAs we move from the era of links to the era of answers, the way search works is changing. You’re not showing a user links, but the goal is to provide context to an LLM. This means moving from keyword based search to more semantic understanding of the content:The link prediction objective can be seen as like a neural PageRank because what you're doing is you're predicting the links people share... but it's more powerful than PageRank. It's strictly more powerful because people might refer to that Paul Graham fundraising essay in like a thousand different ways. And so our model learns all the different ways.All of this is now powered by a $5M cluster with 144 H200s:This architectural choice enables entirely new search capabilities:* Comprehensive result sets instead of approximations* Deep semantic understanding of queries* Ability to process complex, natural language requestsAs search becomes more complex, time to results becomes a variable:People think of searches as like, oh, it takes 500 milliseconds because we've been conditioned... But what if searches can take like a minute or 10 minutes or a whole day, what can you then do?Unlike traditional search engines' fixed-cost indexing, Exa employs a hybrid approach:* Front-loaded compute for indexing and embeddings* Variable inference costs based on query complexity* Mix of owned infrastructure ($5M H200 cluster) and cloud resourcesExa sees a lot of competition from products like Perplexity and ChatGPT Search which layer AI on top of traditional search backends, but Exa is betting that true innovation requires rethinking search from the ground up. For example, the recently launched Websets, a way to turn searches into structured output in grid format, allowing you to create lists and databases out of web pages. The company raised a $17M Series A to build towards this mission, so keep an eye out for them in 2025. Chapters* 00:00:00 Introductions* 00:01:12 ExaAI's initial pitch and concept* 00:02:33 Will's background at SpaceX and Zoox* 00:03:45 Evolution of ExaAI (formerly Metaphor Systems)* 00:05:38 Exa's link prediction technology* 00:09:20 Meaning of the name "Exa"* 00:10:36 ExaAI's new product launch and capabilities* 00:13:33 Compute budgets and variable compute products* 00:14:43 Websets as a B2B offering* 00:19:28 How do you build a search engine?* 00:22:43 What is Neural PageRank?* 00:27:58 Exa use cases * 00:35:00 Auto-prompting* 00:38:42 Building agentic search* 00:44:19 Is o1 on the path to AGI?* 00:49:59 Company culture and nap pods* 00:54:52 Economics of AI search and the future of search technologyFull YouTube TranscriptPlease like and subscribe!Show Notes* ExaAI* Web Search Product* Websets* Series A Announcement* Exa Nap Pods* Perplexity AI* Character.AITranscriptAlessio [00:00:00]: Hey, everyone. Welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol.ai.Swyx [00:00:10]: Hey, and today we're in the studio with my good friend and former landlord, Will Bryk. Roommate. How you doing? Will, you're now CEO co-founder of ExaAI, used to be Metaphor Systems. What's your background, your story?Will [00:00:30]: Yeah, sure. So, yeah, I'm CEO of Exa. I've been doing it for three years. I guess I've always been interested in search, whether I knew it or not. Like, since I was a kid, I've always been interested in, like, high-quality information. And, like, you know, even in high school, wanted to improve the way we get information from news. And then in college, built a mini search engine. And then with Exa, like, you know, it's kind of like fulfilling the dream of actually being able to solve all the information needs I wanted as a kid. Yeah, I guess. I would say my entire life has kind of been rotating around this problem, which is pretty cool. Yeah.Swyx [00:00:50]: What'd you enter YC with?Will [00:00:53]: We entered YC with, uh, we are better than Google. Like, Google 2.0.Swyx [00:01:12]: What makes you say that? Like, that's so audacious to come out of the box with.Will [00:01:16]: Yeah, okay, so you have to remember the time. This was summer 2021. And, uh, GPT-3 had come out. Like, here was this magical thing that you could talk to, you could enter a whole paragraph, and it understands what you mean, understands the subtlety of your language. And then there was Google. Uh, which felt like it hadn't changed in a decade, uh, because it really hadn't. And it, like, you would give it a simple query, like, I don't know, uh, shirts without stripes, and it would give you a bunch of results for the shirts with stripes. And so, like, Google could barely understand you, and GBD3 could. And the theory was, what if you could make a search engine that actually understood you? What if you could apply the insights from LLMs to a search engine? And it's really been the same idea ever since. And we're actually a lot closer now, uh, to doing that. Yeah.Alessio [00:01:55]: Did you have any trouble making people believe? Obviously, there's the same element. I mean, YC overlap, was YC pretty AI forward, even 2021, or?Will [00:02:03]: It's nothing like it is today. But, um, uh, there were a few AI companies, but, uh, we were definitely, like, bold. And I think people, VCs generally like boldness, and we definitely had some AI background, and we had a working demo. So there was evidence that we could build something that was going to work. But yeah, I think, like, the fundamentals were there. I think people at the time were talking about how, you know, Google was failing in a lot of ways. And so there was a bit of conversation about it, but AI was not a big, big thing at the time. Yeah. Yeah.Alessio [00:02:33]: Before we jump into Exa, any fun background stories? I know you interned at SpaceX, any Elon, uh, stories? I know you were at Zoox as well, you know, kind of like robotics at Harvard. Any stuff that you saw early that you thought was going to get solved that maybe it's not solved today?Will [00:02:48]: Oh yeah. I mean, lots of things like that. Like, uh, I never really learned how to drive because I believed Elon that self-driving cars would happen. It did happen. And I take them every night to get home. But it took like 10 more years than I thought. Do you still not know how to drive? I know how to drive now. I learned it like two years ago. That would have been great to like, just, you know, Yeah, yeah, yeah. You know? Um, I was obsessed with Elon. Yeah. I mean, I worked at SpaceX because I really just wanted to work at one of his companies. And I remember they had a rule, like interns cannot touch Elon. And, um, that rule actually influenced my actions.Swyx [00:03:18]: Is it, can Elon touch interns? Ooh, like physically?Will [00:03:22]: Or like talk? Physically, physically, yeah, yeah, yeah, yeah. Okay, interesting. He's changed a lot, but, um, I mean, his companies are amazing. Um,Swyx [00:03:28]: What if you beat him at Diablo 2, Diablo 4, you know, like, Ah, maybe.Alessio [00:03:34]: I want to jump into, I know there's a lot of backstory used to be called metaphor system. So, um, and it, you've always been kind of like a prominent company, maybe at least RAI circles in the NSF.Swyx [00:03:45]: I'm actually curious how Metaphor got its initial aura. You launched with like, very little. We launched very little. Like there was, there was this like big splash image of like, this is Aurora or something. Yeah. Right. And then I was like, okay, what this thing, like the vibes are good, but I don't know what it is. And I think, I think it was much more sort of maybe consumer facing than what you are today. Would you say that's true?Will [00:04:06]: No, it's always been about building a better search algorithm, like search, like, just like the vision has always been perfect search. And if you do that, uh, we will figure out the downstream use cases later. It started on this fundamental belief that you could have perfect search over the web and we could talk about what that means. And like the initial thing we released was really just like our first search engine, like trying to get it out there. Kind of like, you know, an open source. So when OpenAI released, uh, ChachBt, like they didn't, I don't know how, how much of a game plan they had. They kind of just wanted to get something out there.Swyx [00:04:33]: Spooky research preview.Will [00:04:34]: Yeah, exactly. And it kind of morphed from a research company to a product company at that point. And I think similarly for us, like we were research, we started as a research endeavor with a, you know, clear eyes that like, if we succeed, it will be a massive business to make out of it. And that's kind of basically what happened. I think there are actually a lot of parallels to, of w between Exa and OpenAI. I often say we're the OpenAI of search. Um, because. Because we're a research company, we're a research startup that does like fundamental research into, uh, making like AGI for search in a, in a way. Uh, and then we have all these like, uh, business products that come out of that.Swyx [00:05:08]: Interesting. I want to ask a little bit more about Metaforesight and then we can go full Exa. When I first met you, which was really funny, cause like literally I stayed in your house in a very historic, uh, Hayes, Hayes Valley place. You said you were building sort of like link prediction foundation model, and I think there's still a lot of foundation model work. I mean, within Exa today, but what does that even mean? I cannot be the only person confused by that because like there's a limited vocabulary or tokens you're telling me, like the tokens are the links or, you know, like it's not, it's not clear. Yeah.Will [00:05:38]: Uh, what we meant by link prediction is that you are literally predicting, like given some texts, you're predicting the links that follow. Yes. That refers to like, it's how we describe the training procedure, which is that we find links on the web. Uh, we take the text surrounding the link. And then we predict. Which link follows you, like, uh, you know, similar to transformers where, uh, you're trying to predict the next token here, you're trying to predict the next link. And so you kind of like hide the link from the transformer. So if someone writes, you know, imagine some article where someone says, Hey, check out this really cool aerospace startup. And they, they say spacex.com afterwards, uh, we hide the spacex.com and ask the model, like what link came next. And by doing that many, many times, you know, billions of times, you could actually build a search engine out of that because then, uh, at query time at search time. Uh, you type in, uh, a query that's like really cool aerospace startup and the model will then try to predict what are the most likely links. So there's a lot of analogs to transformers, but like to actually make this work, it does require like a different architecture than, but it's transformer inspired. Yeah.Alessio [00:06:41]: What's the design decision between doing that versus extracting the link and the description and then embedding the description and then using, um, yeah. What do you need to predict the URL versus like just describing, because you're kind of do a similar thing in a way. Right. It's kind of like based on this description, it was like the closest link for it. So one thing is like predicting the link. The other approach is like I extract the link and the description, and then based on the query, I searched the closest description to it more. Yeah.Will [00:07:09]: That, that, by the way, that is, that is the link refers here to a document. It's not, I think one confusing thing is it's not, you're not actually predicting the URL, the URL itself that would require like the, the system to have memorized URLs. You're actually like getting the actual document, a more accurate name could be document prediction. I see. This was the initial like base model that Exo was trained on, but we've moved beyond that similar to like how, you know, uh, to train a really good like language model, you might start with this like self-supervised objective of predicting the next token and then, uh, just from random stuff on the web. But then you, you want to, uh, add a bunch of like synthetic data and like supervised fine tuning, um, stuff like that to make it really like controllable and robust. Yeah.Alessio [00:07:48]: Yeah. We just have flow from Lindy and, uh, their Lindy started to like hallucinate recrolling YouTube links instead of like, uh, something. Yeah. Support guide. So. Oh, interesting. Yeah.Swyx [00:07:57]: So round about January, you announced your series A and renamed to Exo. I didn't like the name at the, at the initial, but it's grown on me. I liked metaphor, but apparently people can spell metaphor. What would you say are the major components of Exo today? Right? Like, I feel like it used to be very model heavy. Then at the AI engineer conference, Shreyas gave a really good talk on the vector database that you guys have. What are the other major moving parts of Exo? Okay.Will [00:08:23]: So Exo overall is a search engine. Yeah. We're trying to make it like a perfect search engine. And to do that, you have to build lots of, and we're doing it from scratch, right? So to do that, you have to build lots of different. The crawler. Yeah. You have to crawl a bunch of the web. First of all, you have to find the URLs to crawl. Uh, it's connected to the crawler, but yeah, you find URLs, you crawl those URLs. Then you have to process them with some, you know, it could be an embedding model. It could be something more complex, but you need to take, you know, or like, you know, in the past it was like a keyword inverted index. Like you would process all these documents you gather into some processed index, and then you have to serve that. Uh, you had high throughput at low latency. And so that, and that's like the vector database. And so it's like the crawling system, the AI processing system, and then the serving system. Those are all like, you know, teams of like hundreds, maybe thousands of people at Google. Um, but for us, it's like one or two people each typically, but yeah.Alessio [00:09:13]: Can you explain the meaning of, uh, Exo, just the story 10 to the 16th, uh, 18, 18.Will [00:09:20]: Yeah, yeah, yeah, sure. So. Exo means 10 to the 18th, which is in stark contrast to. To Google, which is 10 to the hundredth. Uh, we actually have these like awesome shirts that are like 10th to 18th is greater than 10th to the hundredth. Yeah, it's great. And it's great because it's provocative. It's like every engineer in Silicon Valley is like, what? No, it's not true. Um, like, yeah. And, uh, and then you, you ask them, okay, what does it actually mean? And like the creative ones will, will recognize it. But yeah, I mean, 10 to the 18th is better than 10 to the hundredth when it comes to search, because with search, you want like the actual list of, of things that match what you're asking for. You don't want like the whole web. You want to basically with search filter, the, like everything that humanity has ever created to exactly what you want. And so the idea is like smaller is better there. You want like the best 10th to the 18th and not the 10th to the hundredth. I'm like, one way to say this is like, you know how Google often says at the top, uh, like, you know, 30 million results found. And it's like crazy. Cause you're looking for like the first startups in San Francisco that work on hardware or something. And like, they're not 30 million results like that. What you want is like 325 results found. And those are all the results. That's what you really want with search. And that's, that's our vision. It's like, it just gives you. Perfectly what you asked for.Swyx [00:10:24]: We're recording this ahead of your launch. Uh, we haven't released, we haven't figured out the, the, the name of the launch yet, but what is the product that you're launching? I guess now that we're coinciding this podcast with. Yeah.Will [00:10:36]: So we've basically developed the next version of Exa, which is the ability to get a near perfect list of results of whatever you want. And what that means is you can make a complex query now to Exa, for example, startups working on hardware in SF, and then just get a huge list of all the things that match. And, you know, our goal is if there are 325 startups that match that we find you all of them. And this is just like, there's just like a new experience that's never existed before. It's really like, I don't know how you would go about that right now with current tools and you can apply this same type of like technology to anything. Like, let's say you want, uh, you want to find all the blog posts that talk about Alessio's podcast, um, that have come out in the past year. That is 30 million results. Yeah. Right.Will [00:11:24]: But that, I mean, that would, I'm sure that would be extremely useful to you guys. And like, I don't really know how you would get that full comprehensive list.Swyx [00:11:29]: I just like, how do you, well, there's so many questions with regards to how do you know it's complete, right? Cause you're saying there's only 30 million, 325, whatever. And then how do you do the semantic understanding that it might take, right? So working in hardware, like I might not use the words hardware. I might use the words robotics. I might use the words wearables. I might use like whatever. Yes. So yeah, just tell us more. Yeah. Yeah. Sure. Sure.Will [00:11:53]: So one aspect of this, it's a little subjective. So like certainly providing, you know, at some point we'll provide parameters to the user to like, you know, some sort of threshold to like, uh, gauge like, okay, like this is a cutoff. Like, this is actually not what I mean, because sometimes it's subjective and there needs to be a feedback loop. Like, oh, like it might give you like a few examples and you say, yeah, exactly. And so like, you're, you're kind of like creating a classifier on the fly, but like, that's ultimately how you solve the problem. So the subject, there's a subjectivity problem and then there's a comprehensiveness problem. Those are two different problems. So. Yeah. So you have the comprehensiveness problem. What you basically have to do is you have to put more compute into the query, into the search until you get the full comprehensiveness. Yeah. And I think there's an interesting point here, which is that not all queries are made equal. Some queries just like this blog post one might require scanning, like scavenging, like throughout the whole web in a way that just, just simply requires more compute. You know, at some point there's some amount of compute where you will just be comprehensive. You could imagine, for example, running GPT-4 over the internet. You could imagine running GPT-4 over the entire web and saying like, is this a blog post about Alessio's podcast, like, is this a blog post about Alessio's podcast? And then that would work, right? It would take, you know, a year, maybe cost like a million dollars, but, or many more, but, um, it would work. Uh, the point is that like, given sufficient compute, you can solve the query. And so it's really a question of like, how comprehensive do you want it given your compute budget? I think it's very similar to O1, by the way. And one way of thinking about what we built is like O1 for search, uh, because O1 is all about like, you know, some, some, some questions require more compute than others, and we'll put as much compute into the question as we need to solve it. So similarly with our search, we will put as much compute into the query in order to get comprehensiveness. Yeah.Swyx [00:13:33]: Does that mean you have like some kind of compute budget that I can specify? Yes. Yes. Okay. And like, what are the upper and lower bounds?Will [00:13:42]: Yeah, there's something we're still figuring out. I think like, like everyone is a new paradigm of like variable compute products. Yeah. How do you specify the amount of compute? Like what happens when you. Run out? Do you just like, ah, do you, can you like keep going with it? Like, do you just put in more credits to get more, um, for some, like this can get complex at like the really large compute queries. And like, one thing we do is we give you a preview of what you're going to get, and then you could then spin up like a much larger job, uh, to get like way more results. But yes, there is some compute limit, um, at, at least right now. Yeah. People think of searches as like, oh, it takes 500 milliseconds because we've been conditioned, uh, to have search that takes 500 milliseconds. But like search engines like Google, right. No matter how complex your query to Google, it will take like, you know, roughly 400 milliseconds. But what if searches can take like a minute or 10 minutes or a whole day, what can you then do? And you can do very powerful things. Um, you know, you can imagine, you know, writing a search, going and get a cup of coffee, coming back and you have a perfect list. Like that's okay for a lot of use cases. Yeah.Alessio [00:14:43]: Yeah. I mean, the use case closest to me is venture capital, right? So, uh, no, I mean, eight years ago, I built one of the first like data driven sourcing platforms. So we were. You look at GitHub, Twitter, Product Hunt, all these things, look at interesting things, evaluate them. If you think about some jobs that people have, it's like literally just make a list. If you're like an analyst at a venture firm, your job is to make a list of interesting companies. And then you reach out to them. How do you think about being infrastructure versus like a product you could say, Hey, this is like a product to find companies. This is a product to find things versus like offering more as a blank canvas that people can build on top of. Oh, right. Right.Will [00:15:20]: Uh, we are. We are a search infrastructure company. So we want people to build, uh, on top of us, uh, build amazing products on top of us. But with this one, we try to build something that makes it really easy for users to just log in, put a few, you know, put some credits in and just get like amazing results right away and not have to wait to build some API integration. So we're kind of doing both. Uh, we, we want, we want people to integrate this into all their applications at the same time. We want to just make it really easy to use very similar again to open AI. Like they'll have, they have an API, but they also have. Like a ChatGPT interface so that you could, it's really easy to use, but you could also build it in your applications. Yeah.Alessio [00:15:56]: I'm still trying to wrap my head around a lot of the implications. So, so many businesses run on like information arbitrage, you know, like I know this thing that you don't, especially in investment and financial services. So yeah, now all of a sudden you have these tools for like, oh, actually everybody can get the same information at the same time, the same quality level as an API call. You know, it just kind of changes a lot of things. Yeah.Will [00:16:19]: I think, I think what we're grappling with here. What, what you're just thinking about is like, what is the world like if knowledge is kind of solved, if like any knowledge request you want is just like right there on your computer, it's kind of different from when intelligence is solved. There's like a good, I've written before about like a different super intelligence, super knowledge. Yeah. Like I think that the, the distinction between intelligence and knowledge is actually a pretty good one. They're definitely connected and related in all sorts of ways, but there is a distinction. You could have a world and we are going to have this world where you have like GP five level systems and beyond that could like answer any complex request. Um, unless it requires some. Like, if you say like, uh, you know, give me a list of all the PhDs in New York city who, I don't know, have thought about search before. And even though this, this super intelligence is going to be like, I can't find it on Google, right. Which is kind of crazy. Like we're literally going to have like super intelligences that are using Google. And so if Google can't find them information, there's nothing they could do. They can't find it. So, but if you also have a super knowledge system where it's like, you know, I'm calling this term super knowledge where you just get whatever knowledge you want, then you can pair with a super intelligence system. And then the super intelligence can, we'll never. Be blocked by lack of knowledge.Alessio [00:17:23]: Yeah. You told me this, uh, when we had lunch, I forget how it came out, but we were talking about AGI and whatnot. And you were like, even AGI is going to need search. Yeah.Swyx [00:17:32]: Yeah. Right. Yeah. Um, so we're actually referencing a blog post that you wrote super intelligence and super knowledge. Uh, so I would refer people to that. And this is actually a discussion we've had on the podcast a couple of times. Um, there's so much of model weights that are just memorizing facts. Some of the, some of those might be outdated. Some of them are incomplete or not. Yeah. So like you just need search. So I do wonder, like, is there a maximum language model size that will be the intelligence layer and then the rest is just search, right? Like maybe we should just always use search. And then that sort of workhorse model is just like, and it like, like, like one B or three B parameter model that just drives everything. Yes.Will [00:18:13]: I believe this is a much more optimal system to have a smaller LM. That's really just like an intelligence module. And it makes a call to a search. Tool that's way more efficient because if, okay, I mean the, the opposite of that would be like the LM is so big that can memorize the whole web. That would be like way, but you know, it's not practical at all. I don't, it's not possible to train that at least right now. And Carpathy has actually written about this, how like he could, he could see models moving more and more towards like intelligence modules using various tools. Yeah.Swyx [00:18:39]: So for listeners, that's the, that was him on the no priors podcast. And for us, we talked about this and the, on the Shin Yu and Harrison chase podcasts. I'm doing search in my head. I told you 30 million results. I forgot about our neural link integration. Self-hosted exit.Will [00:18:54]: Yeah. Yeah. No, I do see that that is a much more, much more efficient world. Yeah. I mean, you could also have GB four level systems calling search, but it's just because of the cost of inference. It's just better to have a very efficient search tool and a very efficient LM and they're built for different things. Yeah.Swyx [00:19:09]: I'm just kind of curious. Like it is still something so audacious that I don't want to elide, which is you're, you're, you're building a search engine. Where do you start? How do you, like, are there any reference papers or implementation? That would really influence your thinking, anything like that? Because I don't even know where to start apart from just crawl a bunch of s**t, but there's gotta be more insight than that.Will [00:19:28]: I mean, yeah, there's more insight, but I'm always surprised by like, if you have a group of people who are really focused on solving a problem, um, with the tools today, like there's some in, in software, like there are all sorts of creative solutions that just haven't been thought of before, particularly in the information retrieval field. Yeah. I think a lot of the techniques are just very old, frankly. Like I know how Google and Bing work and. They're just not using new methods. There are all sorts of reasons for that. Like one, like Google has to be comprehensive over the web. So they're, and they have to return in 400 milliseconds. And those two things combined means they are kind of limit and it can't cost too much. They're kind of limited in, uh, what kinds of algorithms they could even deploy at scale. So they end up using like a limited keyword based algorithm. Also like Google was built in a time where like in, you know, in 1998, where we didn't have LMS, we didn't have embeddings. And so they never thought to build those things. And so now they have this like gigantic system that is built on old technology. Yeah. And so a lot of the information retrieval field we found just like thinks in terms of that framework. Yeah. Whereas we came in as like newcomers just thinking like, okay, there here's GB three. It's magical. Obviously we're going to build search that is using that technology. And we never even thought about using keywords really ever. Uh, like we were neural all the way we're building an end to end neural search engine. And just that whole framing just makes us ask different questions, like pursue different lines of work. And there's just a lot of low hanging fruit because no one else is thinking about it. We're just on the frontier of neural search. We just are, um, for, for at web scale, um, because there's just not a lot of people thinking that way about it.Swyx [00:20:57]: Yeah. Maybe let's spell this out since, uh, we're already on this topic, elephants in the room are Perplexity and SearchGPT. That's the, I think that it's all, it's no longer called SearchGPT. I think they call it ChatGPT Search. How would you contrast your approaches to them based on what we know of how they work and yeah, just any, anything in that, in that area? Yeah.Will [00:21:15]: So these systems, there are a few of them now, uh, they basically rely on like traditional search engines like Google or Bing, and then they combine them with like LLMs at the end to, you know, output some power graphics, uh, answering your question. So they like search GPT perplexity. I think they have their own crawlers. No. So there's this important distinction between like having your own search system and like having your own cache of the web. Like for example, so you could create, you could crawl a bunch of the web. Imagine you crawl a hundred billion URLs, and then you create a key value store of like mapping from URL to the document that is technically called an index, but it's not a search algorithm. So then to actually like, when you make a query to search GPT, for example, what is it actually doing it? Let's say it's, it's, it could, it's using the Bing API, uh, getting a list of results and then it could go, it has this cache of like all the contents of those results and then could like bring in the cache, like the index cache, but it's not actually like, it's not like they've built a search engine from scratch over, you know, hundreds of billions of pages. It's like, does that distinction clear? It's like, yeah, you could have like a mapping from URL to documents, but then rely on traditional search engines to actually get the list of results because it's a very hard problem to take. It's not hard. It's not hard to use DynamoDB and, and, and map URLs to documents. It's a very hard problem to take a hundred billion or more documents and given a query, like instantly get the list of results that match. That's a much harder problem that very few entities on, in, on the planet have done. Like there's Google, there's Bing, uh, you know, there's Yandex, but you know, there are not that many companies that are, that are crazy enough to actually build their search engine from scratch when you could just use traditional search APIs.Alessio [00:22:43]: So Google had PageRank as like the big thing. Is there a LLM equivalent or like any. Stuff that you're working on that you want to highlight?Will [00:22:51]: The link prediction objective can be seen as like a neural PageRank because what you're doing is you're predicting the links people share. And so if everyone is sharing some Paul Graham essay about fundraising, then like our model is more likely to predict it. So like inherent in our training objective is this, uh, a sense of like high canonicity and like high quality, but it's more powerful than PageRank. It's strictly more powerful because people might refer to that Paul Graham fundraising essay in like a thousand different ways. And so our model learns all the different ways. That someone refers that Paul Graham, I say, while also learning how important that Paul Graham essay is. Um, so it's like, it's like PageRank on steroids kind of thing. Yeah.Alessio [00:23:26]: I think to me, that's the most interesting thing about search today, like with Google and whatnot, it's like, it's mostly like domain authority. So like if you get back playing, like if you search any AI term, you get this like SEO slop websites with like a bunch of things in them. So this is interesting, but then how do you think about more timeless maybe content? So if you think about, yeah. You know, maybe the founder mode essay, right. It gets shared by like a lot of people, but then you might have a lot of other essays that are also good, but they just don't really get a lot of traction. Even though maybe the people that share them are high quality. How do you kind of solve that thing when you don't have the people authority, so to speak of who's sharing, whether or not they're worth kind of like bumping up? Yeah.Will [00:24:10]: I mean, you do have a lot of control over the training data, so you could like make sure that the training data contains like high quality sources so that, okay. Like if you, if you're. Training data, I mean, it's very similar to like language, language model training. Like if you train on like a bunch of crap, your prediction will be crap. Our model will match the training distribution is trained on. And so we could like, there are lots of ways to tweak the training data to refer to high quality content that we want. Yeah. I would say also this, like this slop that is returned by, by traditional search engines, like Google and Bing, you have the slop is then, uh, transferred into the, these LLMs in like a search GBT or, you know, our other systems like that. Like if slop comes in, slop will go out. And so, yeah, that's another answer to how we're different is like, we're not like traditional search engines. We want to give like the highest quality results and like have full control over whatever you want. If you don't want slop, you get that. And then if you put an LM on top of that, which our customers do, then you just get higher quality results or high quality output.Alessio [00:25:06]: And I use Excel search very often and it's very good. Especially.Swyx [00:25:09]: Wave uses it too.Alessio [00:25:10]: Yeah. Yeah. Yeah. Yeah. Yeah. Like the slop is everywhere, especially when it comes to AI, when it comes to investment. When it comes to all of these things for like, it's valuable to be at the top. And this problem is only going to get worse because. Yeah, no, it's totally. What else is in the toolkit? So you have search API, you have ExaSearch, kind of like the web version. Now you have the list builder. I think you also have web scraping. Maybe just touch on that. Like, I guess maybe people, they want to search and then they want to scrape. Right. So is that kind of the use case that people have? Yeah.Will [00:25:41]: A lot of our customers, they don't just want, because they're building AI applications on top of Exa, they don't just want a list of URLs. They actually want. Like the full content, like cleans, parsed. Markdown. Markdown, maybe chunked, whatever they want, we'll give it to them. And so that's been like huge for customers. Just like getting the URLs and instantly getting the content for each URL is like, and you can do this for 10 or 100 or 1,000 URLs, wherever you want. That's very powerful.Swyx [00:26:05]: Yeah. I think this is the first thing I asked you for when I tried using Exa.Will [00:26:09]: Funny story is like when I built the first version of Exa, it's like, we just happened to store the content. Yes. Like the first 1,024 tokens. Because I just kind of like kept it because I thought of, you know, I don't know why. Really for debugging purposes. And so then when people started asking for content, it was actually pretty easy to serve it. But then, and then we did that, like Exa took off. So the computer's content was so useful. So that was kind of cool.Swyx [00:26:30]: It is. I would say there are other players like Gina, I think is in this space. Firecrawl is in this space. There's a bunch of scraper companies. And obviously scraper is just one part of your stack, but you might as well offer it since you already do it.Will [00:26:43]: Yeah, it makes sense. It's just easy to have an all-in-one solution. And like. We are, you know, building the best scraper in the world. So scraping is a hard problem and it's easy to get like, you know, a good scraper. It's very hard to get a great scraper and it's super hard to get a perfect scraper. So like, and, and scraping really matters to people. Do you have a perfect scraper? Not yet. Okay.Swyx [00:27:05]: The web is increasingly closing to the bots and the scrapers, Twitter, Reddit, Quora, Stack Overflow. I don't know what else. How are you dealing with that? How are you navigating those things? Like, you know. You know, opening your eyes, like just paying them money.Will [00:27:19]: Yeah, no, I mean, I think it definitely makes it harder for search engines. One response is just that there's so much value in the long tail of sites that are open. Okay. Um, and just like, even just searching over those well gets you most of the value. But I mean, there, there is definitely a lot of content that is increasingly not unavailable. And so you could get through that through data partnerships. The bigger we get as a company, the more, the easier it is to just like, uh, make partnerships. But I, I mean, I do see the world as like the future where the. The data, the, the data producers, the content creators will make partnerships with the entities that find that data.Alessio [00:27:53]: Any other fun use case that maybe people are not thinking about? Yeah.Will [00:27:58]: Oh, I mean, uh, there are so many customers. Yeah. What are people doing on AXA? Well, I think dating is a really interesting, uh, application of search that is completely underserved because there's a lot of profiles on the web and a lot of people who want to find love and that I'll use it. They give me. Like, you know, age boundaries, you know, education level location. Yeah. I mean, you want to, what, what do you want to do with data? You want to find like a partner who matches this education level, who like, you know, maybe has written about these types of topics before. Like if you could get a list of all the people like that, like, I think you will unblock a lot of people. I mean, there, I mean, I think this is a very Silicon Valley view of dating for sure. And I'm, I'm well aware of that, but it's just an interesting application of like, you know, I would love to meet like an intellectual partner, um, who like shares a lot of ideas. Yeah. Like if you could do that through better search and yeah.Swyx [00:28:48]: But what is it with Jeff? Jeff has already set me up with a few people. So like Jeff, I think it's my personal exit.Will [00:28:55]: my mom's actually a matchmaker and has got a lot of married. Yeah. No kidding. Yeah. Yeah. Search is built into the book. It's in your jeans. Yeah. Yeah.Swyx [00:29:02]: Yeah. Other than dating, like I know you're having quite some success in colleges. I would just love to map out some more use cases so that our listeners can just use those examples to think about use cases for XR, right? Because it's such a general technology that it's hard to. Uh, really pin down, like, what should I use it for and what kind of products can I build with it?Will [00:29:20]: Yeah, sure. So, I mean, there are so many applications of XR and we have, you know, many, many companies using us for very diverse range of use cases, but I'll just highlight some interesting ones. Like one customer, a big customer is using us to, um, basically build like a, a writing assistant for students who want to write, uh, research papers. And basically like XR will search for, uh, like a list of research papers related to what the student is writing. And then this product has. Has like an LLM that like summarizes the papers to basically it's like a next word prediction, but in, uh, you know, prompted by like, you know, 20 research papers that X has returned. It's like literally just doing their homework for them. Yeah. Yeah. the key point is like, it's, it's, uh, you know, it's, it's, you know, research is, is a really hard thing to do and you need like high quality content as input.Swyx [00:30:08]: Oh, so we've had illicit on the podcast. I think it's pretty similar. Uh, they, they do focus pretty much on just, just research papers and, and that research. Basically, I think dating, uh, research, like I just wanted to like spell out more things, like just the big verticals.Will [00:30:23]: Yeah, yeah, no, I mean, there, there are so many use cases. So finance we talked about, yeah. I mean, one big vertical is just finding a list of companies, uh, so it's useful for VCs, like you said, who want to find like a list of competitors to a specific company they're investigating or just a list of companies in some field. Like, uh, there was one VC that told me that him and his team, like we're using XR for like eight hours straight. Like, like that. For many days on end, just like, like, uh, doing like lots of different queries of different types, like, oh, like all the companies in AI for law or, uh, all the companies for AI for, uh, construction and just like getting lists of things because you just can't find this information with, with traditional search engines. And then, you know, finding companies is also useful for, for selling. If you want to find, you know, like if we want to find a list of, uh, writing assistants to sell to, then we can just, we just use XR ourselves to find that is actually how we found a lot of our customers. Ooh, you can find your own customers using XR. Oh my God. I, in the spirit of. Uh, using XR to bolster XR, like recruiting is really helpful. It is really great use case of XR, um, because we can just get like a list of, you know, people who thought about search and just get like a long list and then, you know, reach out to those people.Swyx [00:31:29]: When you say thought about, are you, are you thinking LinkedIn, Twitter, or are you thinking just blogs?Will [00:31:33]: Or they've written, I mean, it's pretty general. So in that case, like ideally XR would return like the, the really blogs written by people who have just. So if I don't blog, I don't show up to XR, right? Like I have to blog. well, I mean, you could show up. That's like an incentive for people to blog.Swyx [00:31:47]: Well, if you've written about, uh, search in on Twitter and we, we do, we do index a bunch of tweets and then we, we should be able to service that. Yeah. Um, I mean, this is something I tell people, like you have to make yourself discoverable to the web, uh, you know, it's called learning in public, but like, it's even more imperative now because otherwise you don't exist at all.Will [00:32:07]: Yeah, no, no, this is a huge, uh, thing, which is like search engines completely influence. They have downstream effects. They influence the internet itself. They influence what people. Choose to create. And so Google, because they're a keyword based search engine, people like kind of like keyword stuff. Yeah. They're, they're, they're incentivized to create things that just match a lot of keywords, which is not very high quality. Uh, whereas XR is a search algorithm that, uh, optimizes for like high quality and actually like matching what you mean. And so people are incentivized to create content that is high quality, that like the create content that they know will be found by the right person. So like, you know, if I am a search researcher and I want to be found. By XR, I should blog about search and all the things I'm building because, because now we have a search engine like XR that's powerful enough to find them. And so the search engine will influence like the downstream internet in all sorts of amazing ways. Yeah. Uh, whatever the search engine optimizes for is what the internet looks like. Yeah.Swyx [00:33:01]: Are you familiar with the term? McLuhanism? No, it's not. Uh, it's this concept that, uh, like first we shape tools and then the tools shape us. Okay. Yeah. Uh, so there's like this reflexive connection between the things we search for and the things that get searched. Yes. So like once you change the tool. The tool that searches the, the, the things that get searched also change. Yes.Will [00:33:18]: I mean, there was a clear example of that with 30 years of Google. Yeah, exactly. Google has basically trained us to think of search and Google has Google is search like in people's heads. Right. It's one, uh, hard part about XR is like, uh, ripping people away from that notion of search and expanding their sense of what search could be. Because like when people think search, they think like a few keywords, or at least they used to, they think of a few keywords and that's it. They don't think to make these like really complex paragraph long requests for information and get a perfect list. ChatGPT was an interesting like thing that expanded people's understanding of search because you start using ChatGPT for a few hours and you go back to Google and you like paste in your code and Google just doesn't work and you're like, oh, wait, it, Google doesn't do work that way. So like ChatGPT expanded our understanding of what search can be. And I think XR is, uh, is part of that. We want to expand people's notion, like, Hey, you could actually get whatever you want. Yeah.Alessio [00:34:06]: I search on XR right now, people writing about learning in public. I was like, is it gonna come out with Alessio? Am I, am I there? You're not because. Bro. It's. So, no, it's, it's so about, because it thinks about learning, like in public, like public schools and like focuses more on that. You know, it's like how, when there are like these highly overlapping things, like this is like a good result based on the query, you know, but like, how do I get to Alessio? Right. So if you're like in these subcultures, I don't think this would work in Google well either, you know, but I, I don't know if you have any learnings.Swyx [00:34:40]: No, I'm the first result on Google.Alessio [00:34:42]: People writing about learning. In public, you're not first result anymore, I guess.Swyx [00:34:48]: Just type learning public in Google.Alessio [00:34:49]: Well, yeah, yeah, yeah, yeah. But this is also like, this is in Google, it doesn't work either. That's what I'm saying. It's like how, when you have like a movement.Will [00:34:56]: There's confusion about the, like what you mean, like your intention is a little, uh. Yeah.Alessio [00:35:00]: It's like, yeah, I'm using, I'm using a term that like I didn't invent, but I'm kind of taking over, but like, they're just so much about that term already that it's hard to overcome. If that makes sense, because public schools is like, well, it's, it's hard to overcome.Will [00:35:14]: Public schools, you know, so there's the right solution to this, which is to specify more clearly what you mean. And I'm not expecting you to do that, but so the, the right interface to search is actually an LLM.Swyx [00:35:25]: Like you should be talking to an LLM about what you want and the LLM translates its knowledge of you or knowledge of what people usually mean into a query that excellent uses, which you have called auto prompts, right?Will [00:35:35]: Or, yeah, but it's like a very light version of that. And really it's just basically the right answer is it's the wrong interface and like very soon interface to search and really to everything will be LLM. And the LLM just has a full knowledge of you, right? So we're kind of building for that world. We're skating to where the puck is going to be. And so since we're moving to a world where like LLMs are interfaced to everything, you should build a search engine that can handle complex LLM queries, queries that come from LLMs. Because you're probably too lazy, I'm too lazy too, to write like a whole paragraph explaining, okay, this is what I mean by this word. But an LLM is not lazy. And so like the LLM will spit out like a paragraph or more explaining exactly what it wants. You need a search engine that can handle that. Traditional search engines like Google or Bing, they're actually... Designed for humans typing keywords. If you give a paragraph to Google or Bing, they just completely fail. And so Exa can handle paragraphs and we want to be able to handle it more and more until it's like perfect.Alessio [00:36:24]: What about opinions? Do you have lists? When you think about the list product, do you think about just finding entries? Do you think about ranking entries? I'll give you a dumb example. So on Lindy, I've been building the spot that every week gives me like the top fantasy football waiver pickups. But every website is like different opinions. I'm like, you should pick up. These five players, these five players. When you're making lists, do you want to be kind of like also ranking and like telling people what's best? Or like, are you mostly focused on just surfacing information?Will [00:36:56]: There's a really good distinction between filtering to like things that match your query and then ranking based on like what is like your preferences. And ranking is like filtering is objective. It's like, does this document match what you asked for? Whereas ranking is more subjective. It's like, what is the best? Well, it depends what you mean by best, right? So first, first table stakes is let's get the filtering into a perfect place where you actually like every document matches what you asked for. No surgeon can do that today. And then ranking, you know, there are all sorts of interesting ways to do that where like you've maybe for, you know, have the user like specify more clearly what they mean by best. You could do it. And if the user doesn't specify, you do your best, you do your best based on what people typically mean by best. But ideally, like the user can specify, oh, when I mean best, I actually mean ranked by the, you know, the number of people who visited that site. Let's say is, is one example ranking or, oh, what I mean by best, let's say you're listing companies. What I mean by best is like the ones that have, uh, you know, have the most employees or something like that. Like there are all sorts of ways to rank a list of results that are not captured by something as subjective as best. Yeah. Yeah.Alessio [00:38:00]: I mean, it's like, who are the best NBA players in the history? It's like everybody has their own. Right.Will [00:38:06]: Right. But I mean, the, the, the search engine should definitely like, even if you don't specify it, it should do as good of a job as possible. Yeah. Yeah. No, no, totally. Yeah. Yeah. Yeah. Yeah. It's a new topic to people because we're not used to a search engine that can handle like a very complex ranking system. Like you think to type in best basketball players and not something more specific because you know, that's the only thing Google could handle. But if Google could handle like, oh, basketball players ranked by like number of shots scored on average per game, then you would do that. But you know, they can't do that. So.Swyx [00:38:32]: Yeah. That's fascinating. So you haven't used the word agents, but you're kind of building a search agent. Do you believe that that is agentic in feature? Do you think that term is distracting?Will [00:38:42]: I think it's a good term. I do think everything will eventually become agentic. And so then the term will lose power, but yes, like what we're building is agentic it in a sense that it takes actions. It decides when to go deeper into something, it has a loop, right? It feels different from traditional search, which is like an algorithm, not an agent. Ours is a combination of an algorithm and an agent.Swyx [00:39:05]: I think my reflection from seeing this in the coding space where there's basically sort of classic. Framework for thinking about this stuff is the self-driving levels of autonomy, right? Level one to five, typically the level five ones all failed because there's full autonomy and we're not, we're not there yet. And people like control. People like to be in the loop. So the, the, the level ones was co-pilot first and now it's like cursor and whatever. So I feel like if it's too agentic, it's too magical, like, like a, like a one shot, I stick a, stick a paragraph into the text box and then it spits it back to me. It might feel like I'm too disconnected from the process and I don't trust it. As opposed to something where I'm more intimately involved with the research product. I see. So like, uh, wait, so the earlier versions are, so if trying to stick to the example of the basketball thing, like best basketball player, but instead of best, you, you actually get to customize it with like, whatever the metric is that you, you guys care about. Yeah. I'm still not a basketballer, but, uh, but, but, you know, like, like B people like to be in my, my thesis is that agents level five agents failed because people like to. To kind of have drive assist rather than full self-driving.Will [00:40:15]: I mean, a lot of this has to do with how good agents are. Like at some point, if agents for coding are better than humans at all tests and then humans block, yeah, we're not there yet.Swyx [00:40:25]: So like in a world where we're not there yet, what you're pitching us is like, you're, you're kind of saying you're going all the way there. Like I kind of, I think all one is also very full, full self-driving. You don't get to see the plan. You don't get to affect the plan yet. You just fire off a query and then it goes away for a couple of minutes and comes back. Right. Which is effectively what you're saying you're going to do too. And you think there's.Will [00:40:42]: There's a, there's an in-between. I saw. Okay. So in building this product, we're exploring new interfaces because what does it mean to kick off a search that goes and takes 10 minutes? Like, is that a good interface? Because what if the search is actually wrong or it's not exactly, exactly specified to what you mean, which is why you get previews. Yeah. You get previews. So it is iterative, but ultimately once you've specified exactly what you mean, then you kind of do just want to kick off a batch job. Right. So perhaps what you're getting at is like, uh, there's this barrier with agents where you have to like explain the full context of what you mean, and a lot of failure modes happen when you have, when you don't. Yeah. There's failure modes from the agent, just not being smart enough. And then there's failure modes from the agent, not understanding exactly what you mean. And there's a lot of context that is shared between humans that is like lost between like humans and, and this like new creature.Alessio [00:41:32]: Yeah. Yeah. Because people don't know what's going on. I mean, to me, the best example of like system prompts is like, why are you writing? You're a helpful assistant. Like. Of course you should be an awful, but people don't yet know, like, can I assume that, you know, that, you know, it's like, why did the, and now people write, oh, you're a very smart software engineer, but like, you never made, you never make mistakes. Like, were you going to try and make mistakes before? So I think people don't yet have an understanding, like with, with driving people know what good driving is. It's like, don't crash, stay within kind of like a certain speed range. It's like, follow the directions. It's like, I don't really have to explain all of those things. I hope. But with. AI and like models and like search, people are like, okay, what do you actually know? What are like your assumptions about how search, how you're going to do search? And like, can I trust it? You know, can I influence it? So I think that's kind of the, the middle ground, like before you go ahead and like do all the search, it's like, can I see how you're doing it? And then maybe help show your work kind of like, yeah, steer you. Yeah. Yeah.Will [00:42:32]: No, I mean, yeah. Sure. Saying, even if you've crafted a great system prompt, you want to be part of the process itself. Uh, because the system prompt doesn't, it doesn't capture everything. Right. So yeah. A system prompt is like, you get to choose the person you work with. It's like, oh, like I want, I want a software engineer who thinks this way about code. But then even once you've chosen that person, you can't just give them a high level command and they go do it perfectly. You have to be part of that process. So yeah, I agree.Swyx [00:42:58]: Just a side note for my system, my favorite system, prompt programming anecdote now is the Apple intelligence system prompt that someone, someone's a prompt injected it and seen it. And like the Apple. Intelligence has the words, like, please don't, don't hallucinate. And it's like, of course we don't want you to hallucinate. Right. Like, so it's exactly that, that what you're talking about, like we should train this behavior into the model, but somehow we still feel the need to inject into the prompt. And I still don't even think that we are very scientific about it. Like it, I think it's almost like cargo culting. Like we have this like magical, like turn around three times, throw salt over your shoulder before you do something. And like, it worked the last time. So let's just do it the same time now. And like, we do, there's no science to this.Will [00:43:35]: I do think a lot of these problems might be ironed out in future versions. Right. So, and like, they might, they might hide the details from you. So it's like, they actually, all of them have a system prompt. That's like, you are a helpful assistant. You don't actually have to include it, even though it might actually be the way they've implemented in the backend. It should be done in RLE AF.Swyx [00:43:52]: Okay. Uh, one question I was just kind of curious about this episode is I'm going to try to frame this in terms of this, the general AI search wars, you know, you're, you're one player in that, um, there's perplexity, chat, GPT, search, and Google, but there's also like the B2B side, uh, we had. Drew Houston from Dropbox on, and he's competing with Glean, who've, uh, we've also had DD from, from Glean on, is there an appetite for Exa for my company's documents?Will [00:44:19]: There is appetite, but I think we have to be disciplined, focused, disciplined. I mean, we're already taking on like perfect web search, which is a lot. Um, but I mean, ultimately we want to build a perfect search engine, which definitely for a lot of queries involves your, your personal information, your company's information. And so, yeah, I mean, the grandest vision of Exa is perfect search really over everything, every domain, you know, we're going to have an Exa satellite, uh, because, because satellites can gather information that, uh, is not available publicly. Uh, gotcha. Yeah.Alessio [00:44:51]: Can we talk about AGI? We never, we never talk about AGI, but you had, uh, this whole tweet about, oh, one being the biggest kind of like AI step function towards it. Why does it feel so important to you? I know there's kind of like always criticism and saying, Hey, it's not the smartest son is better. It's like, blah, blah, blah. What? You choose C. So you say, this is what Ilias see or Sam see what they will see.Will [00:45:13]: I've just, I've just, you know, been connecting the dots. I mean, this was the key thing that a bunch of labs were working on, which is like, can you create a reward signal? Can you teach yourself based on a reward signal? Whether you're, if you're trying to learn coding or math, if you could have one model say, uh, be a grading system that says like you have successfully solved this programming assessment and then one model, like be the generative system. That's like, here are a bunch of programming assessments. You could train on that. It's basically whenever you could create a reward signal for some task, you could just generate a bunch of tasks for yourself. See that like, oh, on two of these thousand, you did well. And then you just train on that data. It's basically like, I mean, creating your own data for yourself and like, you know, all the labs working on that opening, I built the most impressive product doing that. And it's just very, it's very easy now to see how that could like scale to just solving, like, like solving programming or solving mathematics, which sounds crazy, but everything about our world right now is crazy.Alessio [00:46:07]: Um, and so I think if you remove that whole, like, oh, that's impossible, and you just think really clearly about like, what's now possible with like what, what they've done with O1, it's easy to see how that scales. How do you think about older GPT models then? Should people still work on them? You know, if like, obviously they just had the new Haiku, like, is it even worth spending time, like making these models better versus just, you know, Sam talked about O2 at that day. So obviously they're, they're spending a lot of time in it, but then you have maybe. The GPU poor, which are still working on making Lama good. Uh, and then you have the follower labs that do not have an O1 like model out yet. Yeah.Will [00:46:47]: This kind of gets into like, uh, what will the ecosystem of, of models be like in the future? And is there room is, is everything just gonna be O1 like models? I think, well, I mean, there's definitely a question of like inference speed and if certain things like O1 takes a long time, because that's the thing. Well, I mean, O1 is, is two things. It's like one it's it's use it's bootstrapping itself. It's teaching itself. And so the base model is smarter. But then it also has this like inference time compute where it could like spend like many minutes or many hours thinking. And so even the base model, which is also fast, it doesn't have to take minutes. It could take is, is better, smarter. I believe all models will be trained with this paradigm. Like you'll want to train on the best data, but there will be many different size models from different, very many different like companies, I believe. Yeah. Because like, I don't, yeah, I mean, it's hard, hard to predict, but I don't think opening eye is going to dominate like every possible LLM for every possible. Use case. I think for a lot of things, like you just want the fastest model and that might not involve O1 methods at all.Swyx [00:47:42]: I would say if you were to take the exit being O1 for search, literally, you really need to prioritize search trajectories, like almost maybe paying a bunch of grad students to go research things. And then you kind of track what they search and what the sequence of searching is, because it seems like that is the gold mine here, like the chain of thought or the thinking trajectory. Yeah.Will [00:48:05]: When it comes to search, I've always been skeptical. I've always been skeptical of human labeled data. Okay. Yeah, please. We tried something at our company at Exa recently where me and a bunch of engineers on the team like labeled a bunch of queries and it was really hard. Like, you know, you have all these niche queries and you're looking at a bunch of results and you're trying to identify which is matched to query. It's talking about, you know, the intricacies of like some biological experiment or something. I have no idea. Like, I don't know what matches and what, what labelers like me tend to do is just match by keyword. I'm like, oh, I don't know. Oh, like this document matches a bunch of keywords, so it must be good. But then you're actually completely missing the meaning of the document. Whereas an LLM like GB4 is really good at labeling. And so I actually think like you just we get by, which we are right now doing using like LLMs as the labelers specifically for search. I think it's interesting. It's different between like search and like GB5 are different because GB5 might benefit from training on a lot of PhD notes because like GB5 might have to do like very, very complex, like, uh, problem-solving in after when it was given an input, but with search, it's actually a very different problem. You're, you're asking simple questions about billions of things. So like, whereas like GB5 is asking a really hard, it's like solving a really hard question, but it's one, it's like one question, a PhD level question with search. You're asking like simple questions about billions of things. Like, is this a startup? Did this person write a blog post about search? You know, those are actually simple questions. You don't need like PhD level training data. Does that make sense? Yeah.Alessio [00:49:33]: What else we got here? Uh, nap pods. Oh, yeah.Swyx [00:49:38]: What's the, yeah. So like just generally, I think, uh, EXA has a very interesting company building vibe. Like you, you have a meme Lord CTO, um, I guess, I don't know. Like, and, and you, you have, you just generally, um, are counter consensus in a bunch of things. What is the culture at EXA?Will [00:49:59]: Like, yeah, I, me and Jeff are, I mean, we've been best friends. It's like, like we met, like met like first day of college. I've been best friends ever since. And we have a really good vibe. I think that's like intense, but also really fun. And like, like funny, honestly, we have a ton of like, we just laugh a lot, a ton at EXA. And I think that's just like, you see that in every part of our culture. We don't really care about how the world sees anything. Like me and Jeff are just like that. Like, we're just thinking really just like, like, what should we do here? Like, what do we need? And so in the nap pod case, it was like, people get tired a lot when they're coding or doing anything really. And like, why can't we just sleep here or, or like nap? And, uh, okay, if we need a nap, then we should get a nap pod. It's crazy to me that there aren't nap pods in lots of companies because like I get tired all the time. I take a nap like every other day, probably for like 20 minutes. I'm actually never actually napping. I'm just thinking about a problem, but closing my eyes really like, um, first of all, it makes me come up with more creative solutions. And then also actually it gives me some rest. So, which is awesome.Swyx [00:50:54]: Google was the original company that had the nap pods at work, right? Oh, okay.Will [00:50:56]: Well, then at one point Google was thinking for first principles and everything too. Um, and that was reflected in their nap pods.Swyx [00:51:02]: So you, you like, you like didn't just get a nap pod for your office. You like found something from China and you're like, who wants to get in on this? Let's get a container full of them. Yeah.Will [00:51:11]: Well, we're trying, we try to be frugal. So like we were, we were looking at like different nap pods. And then, uh, at some point we were like, wait, China probably has solved this problem. And so then we ordered it from China and then it was actually so heavy. Like when it came off the truck, it was like 500 pounds. And I like the truck was like having trouble, like putting it on the ground. And so like me and the delivery guy were like trying to hold it. And then we couldn't, we were struggling. So someone came out from on the street and like heart started helping us hurt yourself. I know it was really dangerous, but we did it. And then it was awesome.Alessio [00:51:37]: And it's funny. I was reading the tech crunch article about it. It was a tech crunch article on the nap pods. Yeah. And then Jeff explained, well, they quote Jeff and this paragraph says, so the nap pods maintain employees ability to stop work and sleep rather than the idea that in quotes, employees are slaves. Close quote, I don't know what I'm. I'm like, I'm sure there's not what event, you know, but I'm curious, like, just like how people there's always like this, I think for a little bit, it went away about like startups and kind of like hustle culture and like all of that.Swyx [00:52:10]: And I think now with AI, people are like, have all these feelings towards AI that are kind of like, I think it's a pro hustle culture, right? Yeah.Will [00:52:17]: But I mean, I mean, ideally the hustle is like people are just having fun, which is people, people are just having fun.Alessio [00:52:23]: Yeah. But I would say from the outside, it's like, people don't like it, you know, I'm saying people not in, in AI and kind of like intact. They're kind of like. Oh, these guys are at it again. These are like the same people that gave us underpaid drivers, like whatever it's like. So it was just funny to see somehow they wanted to make it sound like Jeff was saying employees are slaves, but like, oh, yeah, I don't know. That doesn't make sense.Will [00:52:45]: But yeah, I mean, okay. I can't imagine a more exciting experience than like building something from scratch. That's like a huge deal with a bunch of your friends. Our team is going to look back in 10 years and think this was like the most beautiful experience that you could have in life. And like. That's how I think about it. And yeah, that's just so it's not, it's not a hustle or not. It's like, is this like, like, does this satisfy your core desire to like build things in the world? And it does. Yeah.Alessio [00:53:10]: Anything else we didn't cover any parting thoughts? Are you hiring?Will [00:53:16]: Are you, obviously you're looking for more people to use it, but yeah, yeah, we're definitely hiring. We're, we're growing quite fast and we have a really smart team of engineers and researchers. And we now have a, we just purchased a $5 million H 200 cluster. So we have a lot more compute to play with. Do you run all your own inference? We do a mix of our cluster and like AWS inference that we, we use these are, so we have our current cluster, which is like a one hundreds and now we've updated the new one. We use it for training and research.Swyx [00:53:43]: What's the training versus inference budget? Like, is it like a, is it 50, 50? Is it?Will [00:53:48]: Yeah, we, there will be more inference for search for sure.Swyx [00:53:51]: The other thing I mentioned, so by the way, I'm like sidetracking, but I'm just kind of throwing this in there because I always think about the economics of AI search, like for those, I think, I think if you look up, there's the upper limit is going to be whatever you can monetize off of ads, right? So for Google, let's say it's like a one cent per thousand views, something like that. I don't know the exact number, the exact numbers floating around out there. That means that's your revenue, right? Then your cost has to be lower than that. And so at some point, like for an LLM inference call to be made for every page view, you need to get it lower than. The money that you would take in for, for that. And like, one of the things that I was very surprised, surprised for perplexity and character as well was that they couldn't get it so low that it would be reasonable. I think for you guys, it is a mix of front loading it by indexing. So you only run that compute like once a month, once a, once a quarter, whatever you do re-indexing. And then it's just a little bit more when you, when you do inference, when this search actually gets done, right? Like, so I think when people work out like the economics of such a business, they have to kind of think about where do you put the. The costs. Yes.Will [00:54:52]: Yes. I mean, uh, definitely you have to, you cannot run LLMs over the whole index, you know, billions of things at query time. So you have to pre-process things usually with LLMs, but then you, you can do a re-rank over like, you know, 10, 30, a hundred, depending on a thousand, depending on how. You know, you could, you could play with different sizes of L of transformers to get the cost to work out. I mean, one really interesting thing is like, we're building a search engine at a time where LLM costs are going down like crazy when some very useful. Tool goes down in cost by 200 X in like the space of, I don't know, a couple of years, there are going to be new opportunities in search, right? So like to, to not integrate this and build off, to not like rethink search from scratch, the search algorithm itself, given the fact that things are going down 200 X is crazy.Alessio [00:55:37]: Thank you so much for coming on, man. It was fun.Will [00:55:39]: Thank you. This was so fun. Really fun. Get full access to Latent.Space at www.latent.space/subscribe
-
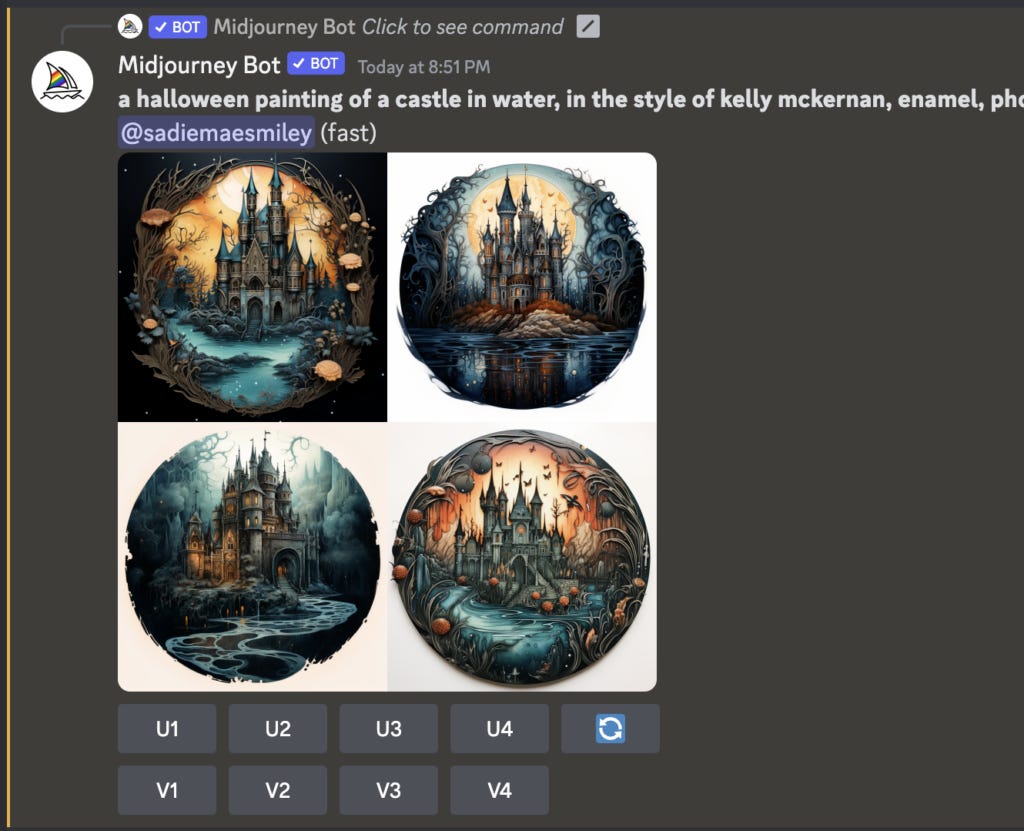 AI Engineering for Art — with comfyanonymous, of ComfyUI
AI Engineering for Art — with comfyanonymous, of ComfyUIFrom 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2025-01-04 22:59
Applications for the NYC AI Engineer Summit, focused on Agents at Work, are open!When we first started Latent Space, in the lightning round we’d always ask guests: “What’s your favorite AI product?”. The majority would say Midjourney. The simple UI of prompt → very aesthetic image turned it into a $300M+ ARR bootstrapped business as it rode the first wave of AI image generation.In open source land, StableDiffusion was congregating around AUTOMATIC1111 as the de-facto web UI. Unlike Midjourney, which offered some flags but was mostly prompt-driven, A1111 let users play with a lot more parameters, supported additional modalities like img2img, and allowed users to load in custom models. If you’re interested in some of the SD history, you can look at our episodes with Lexica, Replicate, and Playground.One of the people involved with that community was comfyanonymous, who was also part of the Stability team in 2023, decided to build an alternative called ComfyUI, now one of the fastest growing open source projects in generative images, and is now the preferred partner for folks like Black Forest Labs’s Flux Tools on Day 1. The idea behind it was simple: “Everyone is trying to make easy to use interfaces. Let me try to make a powerful interface that's not easy to use.”Unlike its predecessors, ComfyUI does not have an input text box. Everything is based around the idea of a node: there’s a text input node, a CLIP node, a checkpoint loader node, a KSampler node, a VAE node, etc. While daunting for simple image generation, the tool is amazing for more complex workflows since you can break down every step of the process, and then chain many of them together rather than manually switching between tools. You can also re-start execution halfway instead of from the beginning, which can save a lot of time when using larger models.To give you an idea of some of the new use cases that this type of UI enables:* Sketch something → Generate an image with SD from sketch → feed it into SD Video to animate* Generate an image of an object → Turn into a 3D asset → Feed into interactive experiences* Input audio → Generate audio-reactive videosTheir Examples page also includes some of the more common use cases like AnimateDiff, etc. They recently launched the Comfy Registry, an online library of different nodes that users can pull from rather than having to build everything from scratch. The project has >60,000 Github stars, and as the community grows, some of the projects that people build have gotten quite complex:The most interesting thing about Comfy is that it’s not a UI, it’s a runtime. You can build full applications on top of image models simply by using Comfy. You can expose Comfy workflows as an endpoint and chain them together just like you chain a single node. We’re seeing the rise of AI Engineering applied to art.Major Tom’s ComfyUI Resources from the Latent Space DiscordMajor shoutouts to Major Tom on the LS Discord who is a image generation expert, who offered these pointers:* “best thing about comfy is the fact it supports almost immediately every new thing that comes out - unlike A1111 or forge, which still don't support flux cnet for instance. It will be perfect tool when conflicting nodes will be resolved”* AP Workflows from Alessandro Perili are a nice example of an all-in-one train-evaluate-generate system built atop Comfy* ComfyUI YouTubers to learn from:* @sebastiankamph* @NerdyRodent* @OlivioSarikas* @sedetweiler* @pixaroma* ComfyUI Nodes to check out:* https://github.com/kijai/ComfyUI-IC-Light* https://github.com/MrForExample/ComfyUI-3D-Pack* https://github.com/PowerHouseMan/ComfyUI-AdvancedLivePortrait* https://github.com/pydn/ComfyUI-to-Python-Extension* https://github.com/THtianhao/ComfyUI-Portrait-Maker* https://github.com/ssitu/ComfyUI_NestedNodeBuilder* https://github.com/longgui0318/comfyui-magic-clothing* https://github.com/atmaranto/ComfyUI-SaveAsScript* https://github.com/ZHO-ZHO-ZHO/ComfyUI-InstantID* https://github.com/AIFSH/ComfyUI-FishSpeech* https://github.com/coolzilj/ComfyUI-Photopea* https://github.com/lks-ai/anynode* Sarav: https://www.youtube.com/@mickmumpitz/videos ( applied stuff )* Sarav: https://www.youtube.com/@latentvision (technical, but infrequent)* look for comfyui node for https://github.com/magic-quill/MagicQuill* “Comfy for Video” resources* Kijai (https://github.com/kijai) pushing out support for Mochi, CogVideoX, AnimateDif, LivePortrait etc* Comfyui node support like LTX https://github.com/Lightricks/ComfyUI-LTXVideo , and HunyuanVideo* FloraFauna AI and Krea.ai* Communities: https://www.reddit.com/r/StableDiffusion/, https://www.reddit.com/r/comfyui/Full YouTube EpisodeAs usual, you can find the full video episode on our YouTube (and don’t forget to like and subscribe!)Timestamps* 00:00:04 Introduction of hosts and anonymous guest* 00:00:35 Origins of Comfy UI and early Stable Diffusion landscape* 00:02:58 Comfy's background and development of high-res fix* 00:05:37 Area conditioning and compositing in image generation* 00:07:20 Discussion on different AI image models (SD, Flux, etc.)* 00:11:10 Closed source model APIs and community discussions on SD versions* 00:14:41 LoRAs and textual inversion in image generation* 00:18:43 Evaluation methods in the Comfy community* 00:20:05 CLIP models and text encoders in image generation* 00:23:05 Prompt weighting and negative prompting* 00:26:22 Comfy UI's unique features and design choices* 00:31:00 Memory management in Comfy UI* 00:33:50 GPU market share and compatibility issues* 00:35:40 Node design and parameter settings in Comfy UI* 00:38:44 Custom nodes and community contributions* 00:41:40 Video generation models and capabilities* 00:44:47 Comfy UI's development timeline and rise to popularity* 00:48:13 Current state of Comfy UI team and future plans* 00:50:11 Discussion on other Comfy startups and potential text generation supportTranscriptAlessio [00:00:04]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel Partners, and I'm joined by my co-host Swyx, founder of Small AI.swyx [00:00:12]: Hey everyone, we are in the Chroma Studio again, but with our first ever anonymous guest, Comfy Anonymous, welcome.Comfy [00:00:19]: Hello.swyx [00:00:21]: I feel like that's your full name, you just go by Comfy, right?Comfy [00:00:24]: Yeah, well, a lot of people just call me Comfy, even when they know my real name. Hey, Comfy.Alessio [00:00:32]: Swyx is the same. You know, not a lot of people call you Shawn.swyx [00:00:35]: Yeah, you have a professional name, right, that people know you by, and then you have a legal name. Yeah, it's fine. How do I phrase this? I think people who are in the know, know that Comfy is like the tool for image generation and now other multimodality stuff. I would say that when I first got started with Stable Diffusion, the star of the show was Automatic 111, right? And I actually looked back at my notes from 2022-ish, like Comfy was already getting started back then, but it was kind of like the up and comer, and your main feature was the flowchart. Can you just kind of rewind to that moment, that year and like, you know, how you looked at the landscape there and decided to start Comfy?Comfy [00:01:10]: Yeah, I discovered Stable Diffusion in 2022, in October 2022. And, well, I kind of started playing around with it. Yes, I, and back then I was using Automatic, which was what everyone was using back then. And so I started with that because I had, it was when I started, I had no idea like how Diffusion works. I didn't know how Diffusion models work, how any of this works, so.swyx [00:01:36]: Oh, yeah. What was your prior background as an engineer?Comfy [00:01:39]: Just a software engineer. Yeah. Boring software engineer.swyx [00:01:44]: But like any, any image stuff, any orchestration, distributed systems, GPUs?Comfy [00:01:49]: No, I was doing basically nothing interesting. Crud, web development? Yeah, a lot of web development, just, yeah, some basic, maybe some basic like automation stuff. Okay. Just. Yeah, no, like, no big companies or anything.swyx [00:02:08]: Yeah, but like already some interest in automations, probably a lot of Python.Comfy [00:02:12]: Yeah, yeah, of course, Python. But I wasn't actually used to like the Node graph interface before I started Comfy UI. It was just, I just thought it was like, oh, like, what's the best way to represent the Diffusion process in the user interface? And then like, oh, well. Well, like, naturally, oh, this is the best way I've found. And this was like with the Node interface. So how I got started was, yeah, so basic October 2022, just like I hadn't written a line of PyTorch before that. So it's completely new. What happened was I kind of got addicted to generating images.Alessio [00:02:58]: As we all did. Yeah.Comfy [00:03:00]: And then I started. I started experimenting with like the high-res fixed in auto, which was for those that don't know, the high-res fix is just since the Diffusion models back then could only generate that low-resolution. So what you would do, you would generate low-resolution image, then upscale, then refine it again. And that was kind of the hack to generate high-resolution images. I really liked generating. Like higher resolution images. So I was experimenting with that. And so I modified the code a bit. Okay. What happens if I, if I use different samplers on the second pass, I was edited the code of auto. So what happens if I use a different sampler? What happens if I use a different, like a different settings, different number of steps? And because back then the. The high-res fix was very basic, just, so. Yeah.swyx [00:04:05]: Now there's a whole library of just, uh, the upsamplers.Comfy [00:04:08]: I think, I think they added a bunch of, uh, of options to the high-res fix since, uh, since, since then. But before that was just so basic. So I wanted to go further. I wanted to try it. What happens if I use a different model for the second, the second pass? And then, well, then the auto code base was, wasn't good enough for. Like, it would have been, uh, harder to implement that in the auto interface than to create my own interface. So that's when I decided to create my own. And you were doing that mostly on your own when you started, or did you already have kind of like a subgroup of people? No, I was, uh, on my own because, because it was just me experimenting with stuff. So yeah, that was it. Then, so I started writing the code January one. 2023, and then I released the first version on GitHub, January 16th, 2023. That's how things got started.Alessio [00:05:11]: And what's, what's the name? Comfy UI right away or? Yeah.Comfy [00:05:14]: Comfy UI. The reason the name, my name is Comfy is people thought my pictures were comfy, so I just, uh, just named it, uh, uh, it's my Comfy UI. So yeah, that's, uh,swyx [00:05:27]: Is there a particular segment of the community that you targeted as users? Like more intensive workflow artists, you know, compared to the automatic crowd or, you know,Comfy [00:05:37]: This was my way of like experimenting with, uh, with new things, like the high risk fixed thing I mentioned, which was like in Comfy, the first thing you could easily do was just chain different models together. And then one of the first things, I think the first times it got a bit of popularity was when I started experimenting with the different, like applying. Prompts to different areas of the image. Yeah. I called it area conditioning, posted it on Reddit and it got a bunch of upvotes. So I think that's when, like, when people first learned of Comfy UI.swyx [00:06:17]: Is that mostly like fixing hands?Comfy [00:06:19]: Uh, no, no, no. That was just, uh, like, let's say, well, it was very, well, it still is kind of difficult to like, let's say you want a mountain, you have an image and then, okay. I'm like, okay. I want the mountain here and I want the, like a, a Fox here.swyx [00:06:37]: Yeah. So compositing the image. Yeah.Comfy [00:06:40]: My way was very easy. It was just like, oh, when you run the diffusion process, you kind of generate, okay. You do pass one pass through the diffusion, every step you do one pass. Okay. This place of the image with this brand, this space, place of the image with the other prop. And then. The entire image with another prop and then just average everything together, every step, and that was, uh, area composition, which I call it. And then, then a month later, there was a paper that came out called multi diffusion, which was the same thing, but yeah, that's, uh,Alessio [00:07:20]: could you do area composition with different models or because you're averaging out, you kind of need the same model.Comfy [00:07:26]: Could do it with, but yeah, I hadn't implemented it. For different models, but, uh, you, you can do it with, uh, with different models if you want, as long as the models share the same latent space, like we, we're supposed to ring a bell every time someone says, yeah, like, for example, you couldn't use like Excel and SD 1.5, because those have a different latent space, but like, uh, yeah, like SD 1.5 models, different ones. You could, you could do that.swyx [00:07:59]: There's some models that try to work in pixel space, right?Comfy [00:08:03]: Yeah. They're very slow. Of course. That's the problem. That that's the, the reason why stable diffusion actually became like popular, like, cause was because of the latent space.swyx [00:08:14]: Small and yeah. Because it used to be latent diffusion models and then they trained it up.Comfy [00:08:19]: Yeah. Cause a pixel pixel diffusion models are just too slow. So. Yeah.swyx [00:08:25]: Have you ever tried to talk to like, like stability, the latent diffusion guys, like, you know, Robin Rombach, that, that crew. Yeah.Comfy [00:08:32]: Well, I used to work at stability.swyx [00:08:34]: Oh, I actually didn't know. Yeah.Comfy [00:08:35]: I used to work at stability. I got, uh, I got hired, uh, in June, 2023.swyx [00:08:42]: Ah, that's the part of the story I didn't know about. Okay. Yeah.Comfy [00:08:46]: So the, the reason I was hired is because they were doing, uh, SDXL at the time and they were basically SDXL. I don't know if you remember it was a base model and then a refiner model. Basically they wanted to experiment, like chaining them together. And then, uh, they saw, oh, right. Oh, this, we can use this to do that. Well, let's hire that guy.swyx [00:09:10]: But they didn't, they didn't pursue it for like SD3. What do you mean? Like the SDXL approach. Yeah.Comfy [00:09:16]: The reason for that approach was because basically they had two models and then they wanted to publish both of them. So they, they trained one on. Lower time steps, which was the refiner model. And then they, the first one was trained normally. And then they went during their test, they realized, oh, like if we string these models together are like quality increases. So let's publish that. It worked. Yeah. But like right now, I don't think many people actually use the refiner anymore, even though it is actually a full diffusion model. Like you can use it on its own. And it's going to generate images. I don't think anyone, people have mostly forgotten about it. But, uh.Alessio [00:10:05]: Can we talk about models a little bit? So stable diffusion, obviously is the most known. I know flux has gotten a lot of traction. Are there any underrated models that people should use more or what's the state of the union?Comfy [00:10:17]: Well, the, the latest, uh, state of the art, at least, yeah, for images there's, uh, yeah, there's flux. There's also SD3.5. SD3.5 is two models. There's a, there's a small one, 2.5B and there's the bigger one, 8B. So it's, it's smaller than flux. So, and it's more, uh, creative in a way, but flux, yeah, flux is the best. People should give SD3.5 a try cause it's, uh, it's different. I won't say it's better. Well, it's better for some like specific use cases. Right. If you want some to make something more like creative, maybe SD3.5. If you want to make something more consistent and flux is probably better.swyx [00:11:06]: Do you ever consider supporting the closed source model APIs?Comfy [00:11:10]: Uh, well, they, we do support them as custom nodes. We actually have some, uh, official custom nodes from, uh, different. Ideogram.swyx [00:11:20]: Yeah. I guess DALI would have one. Yeah.Comfy [00:11:23]: That's, uh, it's just not, I'm not the person that handles that. Sure.swyx [00:11:28]: Sure. Quick question on, on SD. There's a lot of community discussion about the transition from SD1.5 to SD2 and then SD2 to SD3. People still like, you know, very loyal to the previous generations of SDs?Comfy [00:11:41]: Uh, yeah. SD1.5 then still has a lot of, a lot of users.swyx [00:11:46]: The last based model.Comfy [00:11:49]: Yeah. Then SD2 was mostly ignored. It wasn't, uh, it wasn't a big enough improvement over the previous one. Okay.swyx [00:11:58]: So SD1.5, SD3, flux and whatever else. SDXL. SDXL.Comfy [00:12:03]: That's the main one. Stable cascade. Stable cascade. That was a good model. But, uh, that's, uh, the problem with that one is, uh, it got, uh, like SD3 was announced one week after. Yeah.swyx [00:12:16]: It was like a weird release. Uh, what was it like inside of stability actually? I mean, statute of limitations. Yeah. The statute of limitations expired. You know, management has moved. So it's easier to talk about now. Yeah.Comfy [00:12:27]: And inside stability, actually that model was ready, uh, like three months before, but it got, uh, stuck in, uh, red teaming. So basically the product, if that model had released or was supposed to be released by the authors, then it would probably have gotten very popular since it's a, it's a step up from SDXL. But it got all of its momentum stolen. It got stolen by the SD3 announcement. So people kind of didn't develop anything on top of it, even though it's, uh, yeah. It was a good model, at least, uh, completely mostly ignored for some reason. Likeswyx [00:13:07]: I think the naming as well matters. It seemed like a branch off of the main, main tree of development. Yeah.Comfy [00:13:15]: Well, it was different researchers that did it. Yeah. Yeah. Very like, uh, good model. Like it's the Worcestershire authors. I don't know if I'm pronouncing it correctly. Yeah. Yeah. Yeah.swyx [00:13:28]: I actually met them in Vienna. Yeah.Comfy [00:13:30]: They worked at stability for a bit and they left right after the Cascade release.swyx [00:13:35]: This is Dustin, right? No. Uh, Dustin's SD3. Yeah.Comfy [00:13:38]: Dustin is a SD3 SDXL. That's, uh, Pablo and Dome. I think I'm pronouncing his name correctly. Yeah. Yeah. Yeah. Yeah. That's very good.swyx [00:13:51]: It seems like the community is very, they move very quickly. Yeah. Like when there's a new model out, they just drop whatever the current one is. And they just all move wholesale over. Like they don't really stay to explore the full capabilities. Like if, if the stable cascade was that good, they would have AB tested a bit more. Instead they're like, okay, SD3 is out. Let's go. You know?Comfy [00:14:11]: Well, I find the opposite actually. The community doesn't like, they only jump on a new model when there's a significant improvement. Like if there's a, only like a incremental improvement, which is what, uh, most of these models are going to have, especially if you, cause, uh, stay the same parameter count. Yeah. Like you're not going to get a massive improvement, uh, into like, unless there's something big that, that changes. So, uh. Yeah.swyx [00:14:41]: And how are they evaluating these improvements? Like, um, because there's, it's a whole chain of, you know, comfy workflows. Yeah. How does, how does one part of the chain actually affect the whole process?Comfy [00:14:52]: Are you talking on the model side specific?swyx [00:14:54]: Model specific, right? But like once you have your whole workflow based on a model, it's very hard to move.Comfy [00:15:01]: Uh, not, well, not really. Well, it depends on your, uh, depends on their specific kind of the workflow. Yeah.swyx [00:15:09]: So I do a lot of like text and image. Yeah.Comfy [00:15:12]: When you do change, like most workflows are kind of going to be complete. Yeah. It's just like, you might have to completely change your prompt completely change. Okay.swyx [00:15:24]: Well, I mean, then maybe the question is really about evals. Like what does the comfy community do for evals? Just, you know,Comfy [00:15:31]: Well, that they don't really do that. It's more like, oh, I think this image is nice. So that's, uh,swyx [00:15:38]: They just subscribe to Fofr AI and just see like, you know, what Fofr is doing. Yeah.Comfy [00:15:43]: Well, they just, they just generate like it. Like, I don't see anyone really doing it. Like, uh, at least on the comfy side, comfy users, they, it's more like, oh, generate images and see, oh, this one's nice. It's like, yeah, it's not, uh, like the, the more, uh, like, uh, scientific, uh, like, uh, like checking that's more on specifically on like model side. If, uh, yeah, but there is a lot of, uh, vibes also, cause it is a like, uh, artistic, uh, you can create a very good model that doesn't generate nice images. Cause most images on the internet are ugly. So if you, if that's like, if you just, oh, I have the best model at 10th giant, it's super smart. I created on all the, like I've trained on just all the images on the internet. The images are not going to look good. So yeah.Alessio [00:16:42]: Yeah.Comfy [00:16:43]: They're going to be very consistent. But yeah. People like, it's not going to be like the, the look that people are going to be expecting from, uh, from a model. So. Yeah.swyx [00:16:54]: Can we talk about LoRa's? Cause we thought we talked about models then like the next step is probably LoRa's. Before, I actually, I'm kind of curious how LoRa's entered the tool set of the image community because the LoRa paper was 2021. And then like, there was like other methods like textual inversion that was popular at the early SD stage. Yeah.Comfy [00:17:13]: I can't even explain the difference between that. Yeah. Textual inversions. That's basically what you're doing is you're, you're training a, cause well, yeah. Stable diffusion. You have the diffusion model, you have text encoder. So basically what you're doing is training a vector that you're going to pass to the text encoder. It's basically you're training a new word. Yeah.swyx [00:17:37]: It's a little bit like representation engineering now. Yeah.Comfy [00:17:40]: Yeah. Basically. Yeah. You're just, so yeah, if you know how like the text encoder works, basically you have, you take your, your words of your product, you convert those into tokens with the tokenizer and those are converted into vectors. Basically. Yeah. Each token represents a different vector. So each word presents a vector. And those, depending on your words, that's the list of vectors that get passed to the text encoder, which is just. Yeah. Yeah. I'm just a stack of, of attention. Like basically it's a very close to LLM architecture. Yeah. Yeah. So basically what you're doing is just training a new vector. We're saying, well, I have all these images and I want to know which word does that represent? And it's going to get like, you train this vector and then, and then when you use this vector, it hopefully generates. Like something similar to your images. Yeah.swyx [00:18:43]: I would say it's like surprisingly sample efficient in picking up the concept that you're trying to train it on. Yeah.Comfy [00:18:48]: Well, people have kind of stopped doing that even though back as like when I was at Stability, we, we actually did train internally some like textual versions on like T5 XXL actually worked pretty well. But for some reason, yeah, people don't use them. And also they might also work like, like, yeah, this is something and probably have to test, but maybe if you train a textual version, like on T5 XXL, it might also work with all the other models that use T5 XXL because same thing with like, like the textual inversions that, that were trained for SD 1.5, they also kind of work on SDXL because SDXL has the, has two text encoders. And one of them is the same as the, as the SD 1.5 CLIP-L. So those, they actually would, they don't work as strongly because they're only applied to one of the text encoders. But, and the same thing for SD3. SD3 has three text encoders. So it works. It's still, you can still use your textual version SD 1.5 on SD3, but it's just a lot weaker because now there's three text encoders. So it gets even more diluted. Yeah.swyx [00:20:05]: Do people experiment a lot on, just on the CLIP side, there's like Siglip, there's Blip, like do people experiment a lot on those?Comfy [00:20:12]: You can't really replace. Yeah.swyx [00:20:14]: Because they're trained together, right? Yeah.Comfy [00:20:15]: They're trained together. So you can't like, well, what I've seen people experimenting with is a long CLIP. So basically someone fine tuned the CLIP model to accept longer prompts.swyx [00:20:27]: Oh, it's kind of like long context fine tuning. Yeah.Comfy [00:20:31]: So, so like it's, it's actually supported in Core Comfy.swyx [00:20:35]: How long is long?Comfy [00:20:36]: Regular CLIP is 77 tokens. Yeah. Long CLIP is 256. Okay. So, but the hack that like you've, if you use stable diffusion 1.5, you've probably noticed, oh, it still works if I, if I use long prompts, prompts longer than 77 words. Well, that's because the hack is to just, well, you split, you split it up in chugs of 77, your whole big prompt. Let's say you, you give it like the massive text, like the Bible or something, and it would split it up in chugs of 77 and then just pass each one through the CLIP and then just cut anything together at the end. It's not ideal, but it actually works.swyx [00:21:26]: Like the positioning of the words really, really matters then, right? Like this is why order matters in prompts. Yeah.Comfy [00:21:33]: Yeah. Like it, it works, but it's, it's not ideal, but it's what people expect. Like if, if someone gives a huge prompt, they expect at least some of the concepts at the end to be like present in the image. But usually when they give long prompts, they, they don't, they like, they don't expect like detail, I think. So that's why it works very well.swyx [00:21:58]: And while we're on this topic, prompts waiting, negative comments. Negative prompting all, all sort of similar part of this layer of the stack. Yeah.Comfy [00:22:05]: The, the hack for that, which works on CLIP, like it, basically it's just for SD 1.5, well, for SD 1.5, the prompt waiting works well because CLIP L is a, is not a very deep model. So you have a very high correlation between, you have the input token, the index of the input token vector. And the output token, they're very, the concepts are very close, closely linked. So that means if you interpolate the vector from what, well, the, the way Comfy UI does it is it has, okay, you have the vector, you have an empty prompt. So you have a, a chunk, like a CLIP output for the empty prompt, and then you have the one for your prompt. And then it interpolates from that, depending on your prompt. Yeah.Comfy [00:23:07]: So that's how it, how it does prompt waiting. But this stops working the deeper your text encoder is. So on T5X itself, it doesn't work at all. So. Wow.swyx [00:23:20]: Is that a problem for people? I mean, cause I'm used to just move, moving up numbers. Probably not. Yeah.Comfy [00:23:25]: Well.swyx [00:23:26]: So you just use words to describe, right? Cause it's a bigger language model. Yeah.Comfy [00:23:30]: Yeah. So. Yeah. So honestly it might be good, but I haven't seen many complaints on Flux that it's not working. So, cause I guess people can sort of get around it with, with language. So. Yeah.swyx [00:23:46]: Yeah. And then coming back to LoRa's, now the, the popular way to, to customize models is LoRa's. And I saw you also support Locon and LoHa, which I've never heard of before.Comfy [00:23:56]: There's a bunch of, cause what, what the LoRa is essentially is. Instead of like, okay, you have your, your model and then you want to fine tune it. So instead of like, what you could do is you could fine tune the entire thing, but that's a bit heavy. So to speed things up and make things less heavy, what you can do is just fine tune some smaller weights, like basically two, two matrices that when you multiply like two low rank matrices and when you multiply them together, gives a, represents a difference between trained weights and your base weights. So by training those two smaller matrices, that's a lot less heavy. Yeah.Alessio [00:24:45]: And they're portable. So you're going to share them. Yeah. It's like easier. And also smaller.Comfy [00:24:49]: Yeah. That's the, how LoRa's work. So basically, so when, when inferencing you, you get an inference with them pretty efficiently, like how ComputeWrite does it. It just, when you use a LoRa, it just applies it straight on the weights so that there's only a small delay at the base, like before the sampling to when it applies the weights and then it just same speed as, as before. So for, for inference, it's, it's not that bad, but, and then you have, so basically all the LoRa types like LoHa, LoCon, everything, that's just different ways of representing that like. Basically, you can call it kind of like compression, even though it's not really compression, it's just different ways of represented, like just, okay, I want to train a different on the difference on the weights. What's the best way to represent that difference? There's the basic LoRa, which is just, oh, let's multiply these two matrices together. And then there's all the other ones, which are all different algorithms. So. Yeah.Alessio [00:25:57]: So let's talk about LoRa. Let's talk about what comfy UI actually is. I think most people have heard of it. Some people might've seen screenshots. I think fewer people have built very complex workflows. So when you started, automatic was like the super simple way. What were some of the choices that you made? So the node workflow, is there anything else that stands out as like, this was like a unique take on how to do image generation workflows?Comfy [00:26:22]: Well, I feel like, yeah, back then everyone was trying to make like easy to use interface. Yeah. So I'm like, well, everyone's trying to make an easy to use interface.swyx [00:26:32]: Let's make a hard to use interface.Comfy [00:26:37]: Like, so like, I like, I don't need to do that, everyone else doing it. So let me try something like, let me try to make a powerful interface that's not easy to use. So.swyx [00:26:52]: So like, yeah, there's a sort of node execution engine. Yeah. Yeah. And it actually lists, it has this really good list of features of things you prioritize, right? Like let me see, like sort of re-executing from, from any parts of the workflow that was changed, asynchronous queue system, smart memory management, like all this seems like a lot of engineering that. Yeah.Comfy [00:27:12]: There's a lot of engineering in the back end to make things, cause I was always focused on making things work locally very well. Cause that's cause I was using it locally. So everything. So there's a lot of, a lot of thought and working by getting everything to run as well as possible. So yeah. ConfUI is actually more of a back end, at least, well, not all the front ends getting a lot more development, but, but before, before it was, I was pretty much only focused on the backend. Yeah.swyx [00:27:50]: So v0.1 was only August this year. Yeah.Comfy [00:27:54]: With the new front end. Before there was no versioning. So yeah. Yeah. Yeah.swyx [00:27:57]: And so what was the big rewrite for the 0.1 and then the 1.0?Comfy [00:28:02]: Well, that's more on the front end side. That's cause before that it was just like the UI, what, cause when I first wrote it, I just, I said, okay, how can I make, like, I can do web development, but I don't like doing it. Like what's the easiest way I can slap a node interface on this. And then I found this library. Yeah. Like JavaScript library.swyx [00:28:26]: Live graph?Comfy [00:28:27]: Live graph.swyx [00:28:28]: Usually people will go for like react flow for like a flow builder. Yeah.Comfy [00:28:31]: But that seems like too complicated. So I didn't really want to spend time like developing the front end. So I'm like, well, oh, light graph. This has the whole node interface. So, okay. Let me just plug that into, to my backend.swyx [00:28:49]: I feel like if Streamlit or Gradio offered something that you would have used Streamlit or Gradio cause it's Python. Yeah.Comfy [00:28:54]: Yeah. Yeah. Yeah.Comfy [00:29:00]: Yeah.Comfy [00:29:14]: Yeah. logic and your backend logic and just sticks them together.swyx [00:29:20]: It's supposed to be easy for you guys. If you're a Python main, you know, I'm a JS main, right? Okay. If you're a Python main, it's supposed to be easy.Comfy [00:29:26]: Yeah, it's easy, but it makes your whole software a huge mess.swyx [00:29:30]: I see, I see. So you're mixing concerns instead of separating concerns?Comfy [00:29:34]: Well, it's because... Like frontend and backend. Frontend and backend should be well separated with a defined API. Like that's how you're supposed to do it. Smart people disagree. It just sticks everything together. It makes it easy to like a huge mess. And also it's, there's a lot of issues with Gradio. Like it's very good if all you want to do is just get like slap a quick interface on your, like to show off your ML project. Like that's what it's made for. Yeah. Like there's no problem using it. Like, oh, I have my, I have my code. I just wanted a quick interface on it. That's perfect. Like use Gradio. But if you want to make something that's like a real, like real software that will last a long time and will be easy to maintain, then I would avoid it. Yeah.swyx [00:30:32]: So your criticism is Streamlit and Gradio are the same. I mean, those are the same criticisms.Comfy [00:30:37]: Yeah, Streamlit I haven't used as much. Yeah, I just looked a bit.swyx [00:30:43]: Similar philosophy.Comfy [00:30:44]: Yeah, it's similar. It's just, it just seems to me like, okay, for quick, like AI demos, it's perfect.swyx [00:30:51]: Yeah. Going back to like the core tech, like asynchronous queues, slow re-execution, smart memory management, you know, anything that you were very proud of or was very hard to figure out?Comfy [00:31:00]: Yeah. The thing that's the biggest pain in the ass is probably the memory management. Yeah.swyx [00:31:05]: Were you just paging models in and out or? Yeah.Comfy [00:31:08]: Before it was just, okay, load the model, completely unload it. Then, okay, that, that works well when you, your model are small, but if your models are big and it takes sort of like, let's say someone has a, like a, a 4090, and the model size is 10 gigabytes, that can take a few seconds to like load and load, load and load, so you want to try to keep things like in memory, in the GPU memory as much as possible. What Comfy UI does right now is it. It tries to like estimate, okay, like, okay, you're going to sample this model, it's going to take probably this amount of memory, let's remove the models, like this amount of memory that's been loaded on the GPU and then just execute it. But so there's a fine line between just because try to remove the least amount of models that are already loaded. Because as fans, like Windows drivers, and one other problem is the NVIDIA driver on Windows by default, because there's a way to, there's an option to disable that feature, but by default it, like, if you start loading, you can overflow your GPU memory and then it's, the driver's going to automatically start paging to RAM. But the problem with that is it's, it makes everything extremely slow. So when you see people complaining, oh, this model, it works, but oh, s**t, it starts slowing down a lot, that's probably what's happening. So it's basically you have to just try to get, use as much memory as possible, but not too much, or else things start slowing down, or people get out of memory, and then just find, try to find that line where, oh, like the driver on Windows starts paging and stuff. Yeah. And the problem with PyTorch is it's, it's high levels, don't have that much fine-grained control over, like, specific memory stuff, so kind of have to leave, like, the memory freeing to, to Python and PyTorch, which is, can be annoying sometimes.swyx [00:33:32]: So, you know, I think one thing is, as a maintainer of this project, like, you're designing for a very wide surface area of compute, like, you even support CPUs.Comfy [00:33:42]: Yeah, well, that's... That's just, for PyTorch, PyTorch supports CPUs, so, yeah, it's just, that's not, that's not hard to support.swyx [00:33:50]: First of all, is there a market share estimate, like, is it, like, 70% NVIDIA, like, 30% AMD, and then, like, miscellaneous on Apple, Silicon, or whatever?Comfy [00:33:59]: For Comfy? Yeah. Yeah, and, yeah, I don't know the market share.swyx [00:34:03]: Can you guess?Comfy [00:34:04]: I think it's mostly NVIDIA. Right. Because, because AMD, the problem, like, AMD works horribly on Windows. Like, on Linux, it works fine. It's, it's lower than the price equivalent NVIDIA GPU, but it works, like, you can use it, you generate images, everything works. On Linux, on Windows, you might have a hard time, so, that's the problem, and most people, I think most people who bought AMD probably use Windows. They probably aren't going to switch to Linux, so... Yeah. So, until AMD actually, like, ports their, like, raw cam to, to Windows properly, and then there's actually PyTorch, I think they're, they're doing that, they're in the process of doing that, but, until they get it, they get a good, like, PyTorch raw cam build that works on Windows, it's, like, they're going to have a hard time. Yeah.Alessio [00:35:06]: We got to get George on it. Yeah. Well, he's trying to get Lisa Su to do it, but... Let's talk a bit about, like, the node design. So, unlike all the other text-to-image, you have a very, like, deep, so you have, like, a separate node for, like, clip and code, you have a separate node for, like, the case sampler, you have, like, all these nodes. Going back to, like, the making it easy versus making it hard, but, like, how much do people actually play with all the settings, you know? Kind of, like, how do you guide people to, like, hey, this is actually going to be very impactful versus this is maybe, like, less impactful, but we still want to expose it to you?Comfy [00:35:40]: Well, I try to... I try to expose, like, I try to expose everything or, but, yeah, at least for the, but for things, like, for example, for the samplers, like, there's, like, yeah, four different sampler nodes, which go in easiest to most advanced. So, yeah, if you go, like, the easy node, the regular sampler node, that's, you have just the basic settings. But if you use, like, the sampler advanced... If you use, like, the custom advanced node, that, that one you can actually, you'll see you have, like, different nodes.Alessio [00:36:19]: I'm looking it up now. Yeah. What are, like, the most impactful parameters that you use? So, it's, like, you know, you can have more, but, like, which ones, like, really make a difference?Comfy [00:36:30]: Yeah, they all do. They all have their own, like, they all, like, for example, yeah, steps. Usually you want steps, you want them to be as low as possible. But you want, if you're optimizing your workflow, you want to, you lower the steps until, like, the images start deteriorating too much. Because that, yeah, that's the number of steps you're running the diffusion process. So, if you want things to be faster, lower is better. But, yeah, CFG, that's more, you can kind of see that as the contrast of the image. Like, if your image looks too bursty. Then you can lower the CFG. So, yeah, CFG, that's how, yeah, that's how strongly the, like, the negative versus positive prompt. Because when you sample a diffusion model, it's basically a negative prompt. It's just, yeah, positive prediction minus negative prediction.swyx [00:37:32]: Contrastive loss. Yeah.Comfy [00:37:34]: It's positive minus negative, and the CFG does the multiplier. Yeah. Yeah. Yeah, so.Alessio [00:37:41]: What are, like, good resources to understand what the parameters do? I think most people start with automatic, and then they move over, and it's, like, snap, CFG, sampler, name, scheduler, denoise. Read it.Comfy [00:37:53]: But, honestly, well, it's more, it's something you should, like, try out yourself. I don't know, you don't necessarily need to know how it works to, like, what it does. Because even if you know, like, CFGO, it's, like, positive minus negative prompt. Yeah. So the only thing you know at CFG is if it's 1.0, then that means the negative prompt isn't applied. It also means sampling is two times faster. But, yeah. But other than that, it's more, like, you should really just see what it does to the images yourself, and you'll probably get a more intuitive understanding of what these things do.Alessio [00:38:34]: Any other nodes or things you want to shout out? Like, I know the animate diff IP adapter. Those are, like, some of the most popular ones. Yeah. What else comes to mind?Comfy [00:38:44]: Not nodes, but there's, like, what I like is when some people, sometimes they make things that use ComfyUI as their backend. Like, there's a plugin for Krita that uses ComfyUI as its backend. So you can use, like, all the models that work in Comfy in Krita. And I think I've tried it once. But I know a lot of people use it, and it's probably really nice, so.Alessio [00:39:15]: What's the craziest node that people have built, like, the most complicated?Comfy [00:39:21]: Craziest node? Like, yeah. I know some people have made, like, video games in Comfy with, like, stuff like that. So, like, someone, like, I remember, like, yeah, last, I think it was last year, someone made, like, a, like, Wolfenstein 3D in Comfy. Of course. And then one of the inputs was, oh, you can generate a texture, and then it changes the texture in the game. So you can plug it to, like, the workflow. And there's a lot of, if you look there, there's a lot of crazy things people do, so. Yeah.Alessio [00:39:59]: And now there's, like, a node register that people can use to, like, download nodes. Yeah.Comfy [00:40:04]: Like, well, there's always been the, like, the ComfyUI manager. Yeah. But we're trying to make this more, like, I don't know, official, like, with, yeah, with the node registry. Because before the node registry, the, like, okay, how did your custom node get into ComfyUI manager? That's the guy running it who, like, every day he searched GitHub for new custom nodes and added dev annually to his custom node manager. So we're trying to make it less effortless. So we're trying to make it less effortless for him, basically. Yeah.Alessio [00:40:40]: Yeah. But I was looking, I mean, there's, like, a YouTube download node. There's, like, this is almost like, you know, a data pipeline more than, like, an image generation thing at this point. It's, like, you can get data in, you can, like, apply filters to it, you can generate data out.Comfy [00:40:54]: Yeah. You can do a lot of different things. Yeah. So I'm thinking, I think what I did is I made it easy to make custom nodes. So I think that helped a lot. I think that helped a lot for, like, the ecosystem because it is very easy to just make a node. So, yeah, a bit too easy sometimes. Then we have the issue where there's a lot of custom node packs which share similar nodes. But, well, that's, yeah, something we're trying to solve by maybe bringing some of the functionality into the core. Yeah. Yeah. Yeah.Alessio [00:41:36]: And then there's, like, video. People can do video generation. Yeah.Comfy [00:41:40]: Video, that's, well, the first video model was, like, stable video diffusion, which was last, yeah, exactly last year, I think. Like, one year ago. But that wasn't a true video model. So it was...swyx [00:41:55]: It was, like, moving images? Yeah.Comfy [00:41:57]: I generated video. What I mean by that is it's, like, it's still 2D Latents. It's basically what I'm trying to do. So what they did is they took SD2, and then they added some temporal attention to it, and then trained it on videos and all. So it's kind of, like, animated, like, same idea, basically. Why I say it's not a true video model is that you still have, like, the 2D Latents. Like, a true video model, like Mochi, for example, would have 3D Latents. Mm-hmm.Alessio [00:42:32]: Which means you can, like, move through the space, basically. It's the difference. You're not just kind of, like, reorienting. Yeah.Comfy [00:42:39]: And it's also, well, it's also because you have a temporal VAE. Mm-hmm. Also, like, Mochi has a temporal VAE that compresses on, like, the temporal direction, also. So that's something you don't have with, like, yeah, animated diff and stable video diffusion. They only, like, compress spatially, not temporally. Mm-hmm. Right. So, yeah. That's why I call that, like, true video models. There's, yeah, there's actually a few of them, but the one I've implemented in comfy is Mochi, because that seems to be the best one so far. Yeah.swyx [00:43:15]: We had AJ come and speak at the stable diffusion meetup. The other open one I think I've seen is COG video. Yeah.Comfy [00:43:21]: COG video. Yeah. That one's, yeah, it also seems decent, but, yeah. Chinese, so we don't use it. No, it's fine. It's just, yeah, I could. Yeah. It's just that there's a, it's not the only one. There's also a few others, which I.swyx [00:43:36]: The rest are, like, closed source, right? Like, Cling. Yeah.Comfy [00:43:39]: Closed source, there's a bunch of them. But I mean, open. I've seen a few of them. Like, I can't remember their names, but there's COG videos, the big, the big one. Then there's also a few of them that released at the same time. There's one that released at the same time as SSD 3.5, same day, which is why I don't remember the name.swyx [00:44:02]: We should have a release schedule so we don't conflict on each of these things. Yeah.Comfy [00:44:06]: I think SD 3.5 and Mochi released on the same day. So everything else was kind of drowned, completely drowned out. So for some reason, lots of people picked that day to release their stuff.Comfy [00:44:21]: Yeah. Which is, well, shame for those. And I think Omnijet also released the same day, which also seems interesting. Yeah. Yeah.Alessio [00:44:30]: What's Comfy? So you are Comfy. And then there's like, comfy.org. I know we do a lot of things for, like, news research and those guys also have kind of like a more open source thing going on. How do you work? Like you mentioned, you mostly work on like, the core piece of it. And then what...Comfy [00:44:47]: Maybe I should fade it in because I, yeah, I feel like maybe, yeah, I only explain part of the story. Right. Yeah. Maybe I should explain the rest. So yeah. So yeah. Basically, January, that's when the first January 2023, January 16, 2023, that's when Amphi was first released to the public. Then, yeah, did a Reddit post about the area composition thing somewhere in, I don't remember exactly, maybe end of January, beginning of February. And then someone, a YouTuber, made a video about it, like Olivio, he made a video about Amphi in March 2023. I think that's when it was a real burst of attention. And by that time, I was continuing to develop it and it was getting, people were starting to use it more, which unfortunately meant that I had first written it to do like experiments, but then my time to do experiments went down. It started going down, because people were actually starting to use it then. Like, I had to, and I said, well, yeah, time to add all these features and stuff. Yeah, and then I got hired by Stability June, 2023. Then I made, basically, yeah, they hired me because they wanted the SD-XL. So I got the SD-XL working very well withітhe UI, because they were experimenting withámphi.house.com. Actually, the SDX, how the SDXL released worked is they released, for some reason, like they released the code first, but they didn't release the model checkpoint. So they released the code. And then, well, since the research was related to code, I released the code in Compute 2. And then the checkpoints were basically early access. People had to sign up and they only allowed a lot of people from edu emails. Like if you had an edu email, like they gave you access basically to the SDXL 0.9. And, well, that leaked. Right. Of course, because of course it's going to leak if you do that. Well, the only way people could easily use it was with Comfy. So, yeah, people started using. And then I fixed a few of the issues people had. So then the big 1.0 release happened. And, well, Comfy UI was the only way a lot of people could actually run it on their computers. Because it just like automatic was so like inefficient and bad that most people couldn't actually, like it just wouldn't work. Like because he did a quick implementation. So people were forced. To use Comfy UI, and that's how it became popular because people had no choice.swyx [00:47:55]: The growth hack.Comfy [00:47:56]: Yeah.swyx [00:47:56]: Yeah.Comfy [00:47:57]: Like everywhere, like people who didn't have the 4090, they had like, who had just regular GPUs, they didn't have a choice.Alessio [00:48:05]: So yeah, I got a 4070. So think of me. And so today, what's, is there like a core Comfy team or?Comfy [00:48:13]: Uh, yeah, well, right now, um, yeah, we are hiring. Okay. Actually, so right now core, like, um, the core core itself, it's, it's me. Uh, but because, uh, the reason where folks like all the focus has been mostly on the front end right now, because that's the thing that's been neglected for a long time. So, uh, so most of the focus right now is, uh, all on the front end, but we are, uh, yeah, we will soon get, uh, more people to like help me with the actual backend stuff. Yeah. So, no, I'm not going to say a hundred percent because that's why once the, once we have our V one release, which is because it'd be the package, come fee-wise with the nice interface and easy to install on windows and hopefully Mac. Uh, yeah. Yeah. Once we have that, uh, we're going to have to, lots of stuff to do on the backend side and also the front end side, but, uh.Alessio [00:49:14]: What's the release that I'm on the wait list. What's the timing?Comfy [00:49:18]: Uh, soon. Uh, soon. Yeah, I don't want to promise a release date. We do have a release date we're targeting, but I'm not sure if it's public. Yeah, and we're still going to continue doing the open source, making MPUI the best way to run stable infusion models. At least the open source side, it's going to be the best way to run models locally. But we will have a few things to make money from it, like cloud inference or that type of thing. And maybe some things for some enterprises.swyx [00:50:08]: I mean, a few questions on that. How do you feel about the other comfy startups?Comfy [00:50:11]: I mean, I think it's great. They're using your name. Yeah, well, it's better they use comfy than they use something else. Yeah, that's true. It's fine. We're going to try not to... We don't want to... We want people to use comfy. Like I said, it's better that people use comfy than something else. So as long as they use comfy, I think it helps the ecosystem. Because more people, even if they don't contribute directly, the fact that they are using comfy means that people are more likely to join the ecosystem. So, yeah.swyx [00:50:57]: And then would you ever do text?Comfy [00:50:59]: Yeah, well, you can already do text with some custom nodes. So, yeah, it's something we like. Yeah, it's something I've wanted to eventually add to core, but it's more like not a very... It's a very high priority. But because a lot of people use text for prompt enhancement and other things like that. So, yeah, it's just that my focus has always been on diffusion models. Yeah, unless some text diffusion model comes out.swyx [00:51:30]: Yeah, David Holtz is investing a lot in text diffusion.Comfy [00:51:34]: Yeah, well, if a good one comes out, then we'll probably implement it since it fits with the whole...swyx [00:51:39]: Yeah, I mean, I imagine it's going to be a close source to Midjourney. Yeah.Comfy [00:51:43]: Well, if an open one comes out, then I'll probably implement it.Alessio [00:51:54]: Cool, comfy. Thanks so much for coming on. This was fun. Bye. Get full access to Latent.Space at www.latent.space/subscribe
-
 Latent.Space 2024 Year in Review
Latent.Space 2024 Year in ReviewFrom 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2024-12-31 20:46
Applications for the 2025 AI Engineer Summit are up, and you can save the date for AIE Singapore in April and AIE World’s Fair 2025 in June.Happy new year, and thanks for 100 great episodes! Please let us know what you want to see/hear for the next 100!Full YouTube Episode with Slides/ChartsLike and subscribe and hit that bell to get notifs!Timestamps* 00:00 Welcome to the 100th Episode!* 00:19 Reflecting on the Journey* 00:47 AI Engineering: The Rise and Impact* 03:15 Latent Space Live and AI Conferences* 09:44 The Competitive AI Landscape* 21:45 Synthetic Data and Future Trends* 35:53 Creative Writing with AI* 36:12 Legal and Ethical Issues in AI* 38:18 The Data War: GPU Poor vs. GPU Rich* 39:12 The Rise of GPU Ultra Rich* 40:47 Emerging Trends in AI Models* 45:31 The Multi-Modality War* 01:05:31 The Future of AI Benchmarks* 01:13:17 Pionote and Frontier Models* 01:13:47 Niche Models and Base Models* 01:14:30 State Space Models and RWKB* 01:15:48 Inference Race and Price Wars* 01:22:16 Major AI Themes of the Year* 01:22:48 AI Rewind: January to March* 01:26:42 AI Rewind: April to June* 01:33:12 AI Rewind: July to September* 01:34:59 AI Rewind: October to December* 01:39:53 Year-End Reflections and PredictionsTranscript[00:00:00] Welcome to the 100th Episode![00:00:00] Alessio: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO at Decibel Partners, and I'm joined by my co host Swyx for the 100th time today.[00:00:12] swyx: Yay, um, and we're so glad that, yeah, you know, everyone has, uh, followed us in this journey. How do you feel about it? 100 episodes.[00:00:19] Alessio: Yeah, I know.[00:00:19] Reflecting on the Journey[00:00:19] Alessio: Almost two years that we've been doing this. We've had four different studios. Uh, we've had a lot of changes. You know, we used to do this lightning round. When we first started that we didn't like, and we tried to change the question. The answer[00:00:32] swyx: was cursor and perplexity.[00:00:34] Alessio: Yeah, I love mid journey. It's like, do you really not like anything else?[00:00:38] Alessio: Like what's, what's the unique thing? And I think, yeah, we, we've also had a lot more research driven content. You know, we had like 3DAO, we had, you know. Jeremy Howard, we had more folks like that.[00:00:47] AI Engineering: The Rise and Impact[00:00:47] Alessio: I think we want to do more of that too in the new year, like having, uh, some of the Gemini folks, both on the research and the applied side.[00:00:54] Alessio: Yeah, but it's been a ton of fun. I think we both started, I wouldn't say as a joke, we were kind of like, Oh, we [00:01:00] should do a podcast. And I think we kind of caught the right wave, obviously. And I think your rise of the AI engineer posts just kind of get people. Sombra to congregate, and then the AI engineer summit.[00:01:11] Alessio: And that's why when I look at our growth chart, it's kind of like a proxy for like the AI engineering industry as a whole, which is almost like, like, even if we don't do that much, we keep growing just because there's so many more AI engineers. So did you expect that growth or did you expect that would take longer for like the AI engineer thing to kind of like become, you know, everybody talks about it today.[00:01:32] swyx: So, the sign of that, that we have won is that Gartner puts it at the top of the hype curve right now. So Gartner has called the peak in AI engineering. I did not expect, um, to what level. I knew that I was correct when I called it because I did like two months of work going into that. But I didn't know, You know, how quickly it could happen, and obviously there's a chance that I could be wrong.[00:01:52] swyx: But I think, like, most people have come around to that concept. Hacker News hates it, which is a good sign. But there's enough people that have defined it, you know, GitHub, when [00:02:00] they launched GitHub Models, which is the Hugging Face clone, they put AI engineers in the banner, like, above the fold, like, in big So I think it's like kind of arrived as a meaningful and useful definition.[00:02:12] swyx: I think people are trying to figure out where the boundaries are. I think that was a lot of the quote unquote drama that happens behind the scenes at the World's Fair in June. Because I think there's a lot of doubt or questions about where ML engineering stops and AI engineering starts. That's a useful debate to be had.[00:02:29] swyx: In some sense, I actually anticipated that as well. So I intentionally did not. Put a firm definition there because most of the successful definitions are necessarily underspecified and it's actually useful to have different perspectives and you don't have to specify everything from the outset.[00:02:45] Alessio: Yeah, I was at um, AWS reInvent and the line to get into like the AI engineering talk, so to speak, which is, you know, applied AI and whatnot was like, there are like hundreds of people just in line to go in.[00:02:56] Alessio: I think that's kind of what enabled me. People, right? Which is what [00:03:00] you kind of talked about. It's like, Hey, look, you don't actually need a PhD, just, yeah, just use the model. And then maybe we'll talk about some of the blind spots that you get as an engineer with the earlier posts that we also had on on the sub stack.[00:03:11] Alessio: But yeah, it's been a heck of a heck of a two years.[00:03:14] swyx: Yeah.[00:03:15] Latent Space Live and AI Conferences[00:03:15] swyx: You know, I was, I was trying to view the conference as like, so NeurIPS is I think like 16, 17, 000 people. And the Latent Space Live event that we held there was 950 signups. I think. The AI world, the ML world is still very much research heavy. And that's as it should be because ML is very much in a research phase.[00:03:34] swyx: But as we move this entire field into production, I think that ratio inverts into becoming more engineering heavy. So at least I think engineering should be on the same level, even if it's never as prestigious, like it'll always be low status because at the end of the day, you're manipulating APIs or whatever.[00:03:51] swyx: But Yeah, wrapping GPTs, but there's going to be an increasing stack and an art to doing these, these things well. And I, you know, I [00:04:00] think that's what we're focusing on for the podcast, the conference and basically everything I do seems to make sense. And I think we'll, we'll talk about the trends here that apply.[00:04:09] swyx: It's, it's just very strange. So, like, there's a mix of, like, keeping on top of research while not being a researcher and then putting that research into production. So, like, people always ask me, like, why are you covering Neuralibs? Like, this is a ML research conference and I'm like, well, yeah, I mean, we're not going to, to like, understand everything Or reproduce every single paper, but the stuff that is being found here is going to make it through into production at some point, you hope.[00:04:32] swyx: And then actually like when I talk to the researchers, they actually get very excited because they're like, oh, you guys are actually caring about how this goes into production and that's what they really really want. The measure of success is previously just peer review, right? Getting 7s and 8s on their um, Academic review conferences and stuff like citations is one metric, but money is a better metric.[00:04:51] Alessio: Money is a better metric. Yeah, and there were about 2200 people on the live stream or something like that. Yeah, yeah. Hundred on the live stream. So [00:05:00] I try my best to moderate, but it was a lot spicier in person with Jonathan and, and Dylan. Yeah, that it was in the chat on YouTube.[00:05:06] swyx: I would say that I actually also created.[00:05:09] swyx: Layen Space Live in order to address flaws that are perceived in academic conferences. This is not NeurIPS specific, it's ICML, NeurIPS. Basically, it's very sort of oriented towards the PhD student, uh, market, job market, right? Like literally all, basically everyone's there to advertise their research and skills and get jobs.[00:05:28] swyx: And then obviously all the, the companies go there to hire them. And I think that's great for the individual researchers, but for people going there to get info is not great because you have to read between the lines, bring a ton of context in order to understand every single paper. So what is missing is effectively what I ended up doing, which is domain by domain, go through and recap the best of the year.[00:05:48] swyx: Survey the field. And there are, like NeurIPS had a, uh, I think ICML had a like a position paper track, NeurIPS added a benchmarks, uh, datasets track. These are ways in which to address that [00:06:00] issue. Uh, there's always workshops as well. Every, every conference has, you know, a last day of workshops and stuff that provide more of an overview.[00:06:06] swyx: But they're not specifically prompted to do so. And I think really, uh, Organizing a conference is just about getting good speakers and giving them the correct prompts. And then they will just go and do that thing and they do a very good job of it. So I think Sarah did a fantastic job with the startups prompt.[00:06:21] swyx: I can't list everybody, but we did best of 2024 in startups, vision, open models. Post transformers, synthetic data, small models, and agents. And then the last one was the, uh, and then we also did a quick one on reasoning with Nathan Lambert. And then the last one, obviously, was the debate that people were very hyped about.[00:06:39] swyx: It was very awkward. And I'm really, really thankful for John Franco, basically, who stepped up to challenge Dylan. Because Dylan was like, yeah, I'll do it. But He was pro scaling. And I think everyone who is like in AI is pro scaling, right? So you need somebody who's ready to publicly say, no, we've hit a wall.[00:06:57] swyx: So that means you're saying Sam Altman's wrong. [00:07:00] You're saying, um, you know, everyone else is wrong. It helps that this was the day before Ilya went on, went up on stage and then said pre training has hit a wall. And data has hit a wall. So actually Jonathan ended up winning, and then Ilya supported that statement, and then Noam Brown on the last day further supported that statement as well.[00:07:17] swyx: So it's kind of interesting that I think the consensus kind of going in was that we're not done scaling, like you should believe in a better lesson. And then, four straight days in a row, you had Sepp Hochreiter, who is the creator of the LSTM, along with everyone's favorite OG in AI, which is Juergen Schmidhuber.[00:07:34] swyx: He said that, um, we're pre trading inside a wall, or like, we've run into a different kind of wall. And then we have, you know John Frankel, Ilya, and then Noam Brown are all saying variations of the same thing, that we have hit some kind of wall in the status quo of what pre trained, scaling large pre trained models has looked like, and we need a new thing.[00:07:54] swyx: And obviously the new thing for people is some make, either people are calling it inference time compute or test time [00:08:00] compute. I think the collective terminology has been inference time, and I think that makes sense because test time, calling it test, meaning, has a very pre trained bias, meaning that the only reason for running inference at all is to test your model.[00:08:11] swyx: That is not true. Right. Yeah. So, so, I quite agree that. OpenAI seems to have adopted, or the community seems to have adopted this terminology of ITC instead of TTC. And that, that makes a lot of sense because like now we care about inference, even right down to compute optimality. Like I actually interviewed this author who recovered or reviewed the Chinchilla paper.[00:08:31] swyx: Chinchilla paper is compute optimal training, but what is not stated in there is it's pre trained compute optimal training. And once you start caring about inference, compute optimal training, you have a different scaling law. And in a way that we did not know last year.[00:08:45] Alessio: I wonder, because John is, he's also on the side of attention is all you need.[00:08:49] Alessio: Like he had the bet with Sasha. So I'm curious, like he doesn't believe in scaling, but he thinks the transformer, I wonder if he's still. So, so,[00:08:56] swyx: so he, obviously everything is nuanced and you know, I told him to play a character [00:09:00] for this debate, right? So he actually does. Yeah. He still, he still believes that we can scale more.[00:09:04] swyx: Uh, he just assumed the character to be very game for, for playing this debate. So even more kudos to him that he assumed a position that he didn't believe in and still won the debate.[00:09:16] Alessio: Get rekt, Dylan. Um, do you just want to quickly run through some of these things? Like, uh, Sarah's presentation, just the highlights.[00:09:24] swyx: Yeah, we can't go through everyone's slides, but I pulled out some things as a factor of, like, stuff that we were going to talk about. And we'll[00:09:30] Alessio: publish[00:09:31] swyx: the rest. Yeah, we'll publish on this feed the best of 2024 in those domains. And hopefully people can benefit from the work that our speakers have done.[00:09:39] swyx: But I think it's, uh, these are just good slides. And I've been, I've been looking for a sort of end of year recaps from, from people.[00:09:44] The Competitive AI Landscape[00:09:44] swyx: The field has progressed a lot. You know, I think the max ELO in 2023 on LMSys used to be 1200 for LMSys ELOs. And now everyone is at least at, uh, 1275 in their ELOs, and this is across Gemini, Chadjibuti, [00:10:00] Grok, O1.[00:10:01] swyx: ai, which with their E Large model, and Enthopic, of course. It's a very, very competitive race. There are multiple Frontier labs all racing, but there is a clear tier zero Frontier. And then there's like a tier one. It's like, I wish I had everything else. Tier zero is extremely competitive. It's effectively now three horse race between Gemini, uh, Anthropic and OpenAI.[00:10:21] swyx: I would say that people are still holding out a candle for XAI. XAI, I think, for some reason, because their API was very slow to roll out, is not included in these metrics. So it's actually quite hard to put on there. As someone who also does charts, XAI is continually snubbed because they don't work well with the benchmarking people.[00:10:42] swyx: Yeah, yeah, yeah. It's a little trivia for why XAI always gets ignored. The other thing is market share. So these are slides from Sarah. We have it up on the screen. It has gone from very heavily open AI. So we have some numbers and estimates. These are from RAMP. Estimates of open AI market share in [00:11:00] December 2023.[00:11:01] swyx: And this is basically, what is it, GPT being 95 percent of production traffic. And I think if you correlate that with stuff that we asked. Harrison Chase on the LangChain episode, it was true. And then CLAUD 3 launched mid middle of this year. I think CLAUD 3 launched in March, CLAUD 3. 5 Sonnet was in June ish.[00:11:23] swyx: And you can start seeing the market share shift towards opening, uh, towards that topic, uh, very, very aggressively. The more recent one is Gemini. So if I scroll down a little bit, this is an even more recent dataset. So RAM's dataset ends in September 2 2. 2024. Gemini has basically launched a price war at the low end, uh, with Gemini Flash, uh, being basically free for personal use.[00:11:44] swyx: Like, I think people don't understand the free tier. It's something like a billion tokens per day. Unless you're trying to abuse it, you cannot really exhaust your free tier on Gemini. They're really trying to get you to use it. They know they're in like third place, um, fourth place, depending how you, how you count.[00:11:58] swyx: And so they're going after [00:12:00] the Lower tier first, and then, you know, maybe the upper tier later, but yeah, Gemini Flash, according to OpenRouter, is now 50 percent of their OpenRouter requests. Obviously, these are the small requests. These are small, cheap requests that are mathematically going to be more.[00:12:15] swyx: The smart ones obviously are still going to OpenAI. But, you know, it's a very, very big shift in the market. Like basically 2023, 2022, To going into 2024 opening has gone from nine five market share to Yeah. Reasonably somewhere between 50 to 75 market share.[00:12:29] Alessio: Yeah. I'm really curious how ramped does the attribution to the model?[00:12:32] Alessio: If it's API, because I think it's all credit card spin. . Well, but it's all, the credit card doesn't say maybe. Maybe the, maybe when they do expenses, they upload the PDF, but yeah, the, the German I think makes sense. I think that was one of my main 2024 takeaways that like. The best small model companies are the large labs, which is not something I would have thought that the open source kind of like long tail would be like the small model.[00:12:53] swyx: Yeah, different sizes of small models we're talking about here, right? Like so small model here for Gemini is AB, [00:13:00] right? Uh, mini. We don't know what the small model size is, but yeah, it's probably in the double digits or maybe single digits, but probably double digits. The open source community has kind of focused on the one to three B size.[00:13:11] swyx: Mm-hmm . Yeah. Maybe[00:13:12] swyx: zero, maybe 0.5 B uh, that's moon dream and that is small for you then, then that's great. It makes sense that we, we have a range for small now, which is like, may, maybe one to five B. Yeah. I'll even put that at, at, at the high end. And so this includes Gemma from Gemini as well. But also includes the Apple Foundation models, which I think Apple Foundation is 3B.[00:13:32] Alessio: Yeah. No, that's great. I mean, I think in the start small just meant cheap. I think today small is actually a more nuanced discussion, you know, that people weren't really having before.[00:13:43] swyx: Yeah, we can keep going. This is a slide that I smiley disagree with Sarah. She's pointing to the scale SEAL leaderboard. I think the Researchers that I talked with at NeurIPS were kind of positive on this because basically you need private test [00:14:00] sets to prevent contamination.[00:14:02] swyx: And Scale is one of maybe three or four people this year that has really made an effort in doing a credible private test set leaderboard. Llama405B does well compared to Gemini and GPT 40. And I think that's good. I would say that. You know, it's good to have an open model that is that big, that does well on those metrics.[00:14:23] swyx: But anyone putting 405B in production will tell you, if you scroll down a little bit to the artificial analysis numbers, that it is very slow and very expensive to infer. Um, it doesn't even fit on like one node. of, uh, of H100s. Cerebras will be happy to tell you they can serve 4 or 5B on their super large chips.[00:14:42] swyx: But, um, you know, if you need to do anything custom to it, you're still kind of constrained. So, is 4 or 5B really that relevant? Like, I think most people are basically saying that they only use 4 or 5B as a teacher model to distill down to something. Even Meta is doing it. So with Lama 3. [00:15:00] 3 launched, they only launched the 70B because they use 4 or 5B to distill the 70B.[00:15:03] swyx: So I don't know if like open source is keeping up. I think they're the, the open source industrial complex is very invested in telling you that the, if the gap is narrowing, I kind of disagree. I think that the gap is widening with O1. I think there are very, very smart people trying to narrow that gap and they should.[00:15:22] swyx: I really wish them success, but you cannot use a chart that is nearing 100 in your saturation chart. And look, the distance between open source and closed source is narrowing. Of course it's going to narrow because you're near 100. This is stupid. But in metrics that matter, is open source narrowing?[00:15:38] swyx: Probably not for O1 for a while. And it's really up to the open source guys to figure out if they can match O1 or not.[00:15:46] Alessio: I think inference time compute is bad for open source just because, you know, Doc can donate the flops at training time, but he cannot donate the flops at inference time. So it's really hard to like actually keep up on that axis.[00:15:59] Alessio: Big, big business [00:16:00] model shift. So I don't know what that means for the GPU clouds. I don't know what that means for the hyperscalers, but obviously the big labs have a lot of advantage. Because, like, it's not a static artifact that you're putting the compute in. You're kind of doing that still, but then you're putting a lot of computed inference too.[00:16:17] swyx: Yeah, yeah, yeah. Um, I mean, Llama4 will be reasoning oriented. We talked with Thomas Shalom. Um, kudos for getting that episode together. That was really nice. Good, well timed. Actually, I connected with the AI meta guy, uh, at NeurIPS, and, um, yeah, we're going to coordinate something for Llama4. Yeah, yeah,[00:16:32] Alessio: and our friend, yeah.[00:16:33] Alessio: Clara Shi just joined to lead the business agent side. So I'm sure we'll have her on in the new year.[00:16:39] swyx: Yeah. So, um, my comment on, on the business model shift, this is super interesting. Apparently it is wide knowledge that OpenAI wanted more than 6. 6 billion dollars for their fundraise. They wanted to raise, you know, higher, and they did not.[00:16:51] swyx: And what that means is basically like, it's very convenient that we're not getting GPT 5, which would have been a larger pre train. We should have a lot of upfront money. And [00:17:00] instead we're, we're converting fixed costs into variable costs, right. And passing it on effectively to the customer. And it's so much easier to take margin there because you can directly attribute it to like, Oh, you're using this more.[00:17:12] swyx: Therefore you, you pay more of the cost and I'll just slap a margin in there. So like that lets you control your growth margin and like tie your. Your spend, or your sort of inference spend, accordingly. And it's just really interesting to, that this change in the sort of inference paradigm has arrived exactly at the same time that the funding environment for pre training is effectively drying up, kind of.[00:17:36] swyx: I feel like maybe the VCs are very in tune with research anyway, so like, they would have noticed this, but, um, it's just interesting.[00:17:43] Alessio: Yeah, and I was looking back at our yearly recap of last year. Yeah. And the big thing was like the mixed trial price fights, you know, and I think now it's almost like there's nowhere to go, like, you know, Gemini Flash is like basically giving it away for free.[00:17:55] Alessio: So I think this is a good way for the labs to generate more revenue and pass down [00:18:00] some of the compute to the customer. I think they're going to[00:18:02] swyx: keep going. I think that 2, will come.[00:18:05] Alessio: Yeah, I know. Totally. I mean, next year, the first thing I'm doing is signing up for Devin. Signing up for the pro chat GBT.[00:18:12] Alessio: Just to try. I just want to see what does it look like to spend a thousand dollars a month on AI?[00:18:17] swyx: Yes. Yes. I think if your, if your, your job is a, at least AI content creator or VC or, you know, someone who, whose job it is to stay on, stay on top of things, you should already be spending like a thousand dollars a month on, on stuff.[00:18:28] swyx: And then obviously easy to spend, hard to use. You have to actually use. The good thing is that actually Google lets you do a lot of stuff for free now. So like deep research. That they just launched. Uses a ton of inference and it's, it's free while it's in preview.[00:18:45] Alessio: Yeah. They need to put that in Lindy.[00:18:47] Alessio: I've been using Lindy lately. I've been a built a bunch of things once we had flow because I liked the new thing. It's pretty good. I even did a phone call assistant. Um, yeah, they just launched Lindy voice. Yeah, I think once [00:19:00] they get advanced voice mode like capability today, still like speech to text, you can kind of tell.[00:19:06] Alessio: Um, but it's good for like reservations and things like that. So I have a meeting prepper thing. And so[00:19:13] swyx: it's good. Okay. I feel like we've, we've covered a lot of stuff. Uh, I, yeah, I, you know, I think We will go over the individual, uh, talks in a separate episode. Uh, I don't want to take too much time with, uh, this stuff, but that suffice to say that there is a lot of progress in each field.[00:19:28] swyx: Uh, we covered vision. Basically this is all like the audience voting for what they wanted. And then I just invited the best people I could find in each audience, especially agents. Um, Graham, who I talked to at ICML in Vienna, he is currently still number one. It's very hard to stay on top of SweetBench.[00:19:45] swyx: OpenHand is currently still number one. switchbench full, which is the hardest one. He had very good thoughts on agents, which I, which I'll highlight for people. Everyone is saying 2025 is the year of agents, just like they said last year. And, uh, but he had [00:20:00] thoughts on like eight parts of what are the frontier problems to solve in agents.[00:20:03] swyx: And so I'll highlight that talk as well.[00:20:05] Alessio: Yeah. The number six, which is the Hacken agents learn more about the environment, has been a Super interesting to us as well, just to think through, because, yeah, how do you put an agent in an enterprise where most things in an enterprise have never been public, you know, a lot of the tooling, like the code bases and things like that.[00:20:23] Alessio: So, yeah, there's not indexing and reg. Well, yeah, but it's more like. You can't really rag things that are not documented. But people know them based on how they've been doing it. You know, so I think there's almost this like, you know, Oh, institutional knowledge. Yeah, the boring word is kind of like a business process extraction.[00:20:38] Alessio: Yeah yeah, I see. It's like, how do you actually understand how these things are done? I see. Um, and I think today the, the problem is that, Yeah, the agents are, that most people are building are good at following instruction, but are not as good as like extracting them from you. Um, so I think that will be a big unlock just to touch quickly on the Jeff Dean thing.[00:20:55] Alessio: I thought it was pretty, I mean, we'll link it in the, in the things, but. I think the main [00:21:00] focus was like, how do you use ML to optimize the systems instead of just focusing on ML to do something else? Yeah, I think speculative decoding, we had, you know, Eugene from RWKB on the podcast before, like he's doing a lot of that with Fetterless AI.[00:21:12] swyx: Everyone is. I would say it's the norm. I'm a little bit uncomfortable with how much it costs, because it does use more of the GPU per call. But because everyone is so keen on fast inference, then yeah, makes sense.[00:21:24] Alessio: Exactly. Um, yeah, but we'll link that. Obviously Jeff is great.[00:21:30] swyx: Jeff is, Jeff's talk was more, it wasn't focused on Gemini.[00:21:33] swyx: I think people got the wrong impression from my tweet. It's more about how Google approaches ML and uses ML to design systems and then systems feedback into ML. And I think this ties in with Lubna's talk.[00:21:45] Synthetic Data and Future Trends[00:21:45] swyx: on synthetic data where it's basically the story of bootstrapping of humans and AI in AI research or AI in production.[00:21:53] swyx: So her talk was on synthetic data, where like how much synthetic data has grown in 2024 in the pre training side, the post training side, [00:22:00] and the eval side. And I think Jeff then also extended it basically to chips, uh, to chip design. So he'd spend a lot of time talking about alpha chip. And most of us in the audience are like, we're not working on hardware, man.[00:22:11] swyx: Like you guys are great. TPU is great. Okay. We'll buy TPUs.[00:22:14] Alessio: And then there was the earlier talk. Yeah. But, and then we have, uh, I don't know if we're calling them essays. What are we calling these? But[00:22:23] swyx: for me, it's just like bonus for late in space supporters, because I feel like they haven't been getting anything.[00:22:29] swyx: And then I wanted a more high frequency way to write stuff. Like that one I wrote in an afternoon. I think basically we now have an answer to what Ilya saw. It's one year since. The blip. And we know what he saw in 2014. We know what he saw in 2024. We think we know what he sees in 2024. He gave some hints and then we have vague indications of what he saw in 2023.[00:22:54] swyx: So that was the Oh, and then 2016 as well, because of this lawsuit with Elon, OpenAI [00:23:00] is publishing emails from Sam's, like, his personal text messages to Siobhan, Zelis, or whatever. So, like, we have emails from Ilya saying, this is what we're seeing in OpenAI, and this is why we need to scale up GPUs. And I think it's very prescient in 2016 to write that.[00:23:16] swyx: And so, like, it is exactly, like, basically his insights. It's him and Greg, basically just kind of driving the scaling up of OpenAI, while they're still playing Dota. They're like, no, like, we see the path here.[00:23:30] Alessio: Yeah, and it's funny, yeah, they even mention, you know, we can only train on 1v1 Dota. We need to train on 5v5, and that takes too many GPUs.[00:23:37] Alessio: Yeah,[00:23:37] swyx: and at least for me, I can speak for myself, like, I didn't see the path from Dota to where we are today. I think even, maybe if you ask them, like, they wouldn't necessarily draw a straight line. Yeah,[00:23:47] Alessio: no, definitely. But I think like that was like the whole idea of almost like the RL and we talked about this with Nathan on his podcast.[00:23:55] Alessio: It's like with RL, you can get very good at specific things, but then you can't really like generalize as much. And I [00:24:00] think the language models are like the opposite, which is like, you're going to throw all this data at them and scale them up, but then you really need to drive them home on a specific task later on.[00:24:08] Alessio: And we'll talk about the open AI reinforcement, fine tuning, um, announcement too, and all of that. But yeah, I think like scale is all you need. That's kind of what Elia will be remembered for. And I think just maybe to clarify on like the pre training is over thing that people love to tweet. I think the point of the talk was like everybody, we're scaling these chips, we're scaling the compute, but like the second ingredient which is data is not scaling at the same rate.[00:24:35] Alessio: So it's not necessarily pre training is over. It's kind of like What got us here won't get us there. In his email, he predicted like 10x growth every two years or something like that. And I think maybe now it's like, you know, you can 10x the chips again, but[00:24:49] swyx: I think it's 10x per year. Was it? I don't know.[00:24:52] Alessio: Exactly. And Moore's law is like 2x. So it's like, you know, much faster than that. And yeah, I like the fossil fuel of AI [00:25:00] analogy. It's kind of like, you know, the little background tokens thing. So the OpenAI reinforcement fine tuning is basically like, instead of fine tuning on data, you fine tune on a reward model.[00:25:09] Alessio: So it's basically like, instead of being data driven, it's like task driven. And I think people have tasks to do, they don't really have a lot of data. So I'm curious to see how that changes, how many people fine tune, because I think this is what people run into. It's like, Oh, you can fine tune llama. And it's like, okay, where do I get the data?[00:25:27] Alessio: To fine tune it on, you know, so it's great that we're moving the thing. And then I really like he had this chart where like, you know, the brain mass and the body mass thing is basically like mammals that scaled linearly by brain and body size, and then humans kind of like broke off the slope. So it's almost like maybe the mammal slope is like the pre training slope.[00:25:46] Alessio: And then the post training slope is like the, the human one.[00:25:49] swyx: Yeah. I wonder what the. I mean, we'll know in 10 years, but I wonder what the y axis is for, for Ilya's SSI. We'll try to get them on.[00:25:57] Alessio: Ilya, if you're listening, you're [00:26:00] welcome here. Yeah, and then he had, you know, what comes next, like agent, synthetic data, inference, compute, I thought all of that was like that.[00:26:05] Alessio: I don't[00:26:05] swyx: think he was dropping any alpha there. Yeah, yeah, yeah.[00:26:07] Alessio: Yeah. Any other new reps? Highlights?[00:26:10] swyx: I think that there was comparatively a lot more work. Oh, by the way, I need to plug that, uh, my friend Yi made this, like, little nice paper. Yeah, that was really[00:26:20] swyx: nice.[00:26:20] swyx: Uh, of, uh, of, like, all the, he's, she called it must read papers of 2024.[00:26:26] swyx: So I laid out some of these at NeurIPS, and it was just gone. Like, everyone just picked it up. Because people are dying for, like, little guidance and visualizations And so, uh, I thought it was really super nice that we got there.[00:26:38] Alessio: Should we do a late in space book for each year? Uh, I thought about it. For each year we should.[00:26:42] Alessio: Coffee table book. Yeah. Yeah. Okay. Put it in the will. Hi, Will. By the way, we haven't introduced you. He's our new, you know, general organist, Jamie. You need to[00:26:52] swyx: pull up more things. One thing I saw that, uh, Okay, one fun one, and then one [00:27:00] more general one. So the fun one is this paper on agent collusion. This is a paper on steganography.[00:27:06] swyx: This is secret collusion among AI agents, multi agent deception via steganography. I tried to go to NeurIPS in order to find these kinds of papers because the real reason Like NeurIPS this year has a lottery system. A lot of people actually even go and don't buy tickets because they just go and attend the side events.[00:27:22] swyx: And then also the people who go and end up crowding around the most popular papers, which you already know and already read them before you showed up to NeurIPS. So the only reason you go there is to talk to the paper authors, but there's like something like 10, 000 other. All these papers out there that, you know, are just people's work that they, that they did on the air and they failed to get attention for one reason or another.[00:27:42] swyx: And this was one of them. Uh, it was like all the way at the back. And this is a deep mind paper that actually focuses on collusion between AI agents, uh, by hiding messages in the text that they generate. Uh, so that's what steganography is. So a very simple example would be the first letter of every word.[00:27:57] swyx: If you Pick that out, you know, and the code sends a [00:28:00] different message than that. But something I've always emphasized is to LLMs, we read left to right. LLMs can read up, down, sideways, you know, in random character order. And it's the same to them as it is to us. So if we were ever to get You know, self motivated, underlined LLMs that we're trying to collaborate to take over the planet.[00:28:19] swyx: This would be how they do it. They spread messages among us in the messages that we generate. And he developed a scaling law for that. So he marked, I'm showing it on screen right now, the emergence of this phenomenon. Basically, for example, for Cypher encoding, GPT 2, Lama 2, mixed trial, GPT 3. 5, zero capabilities, and sudden 4.[00:28:40] swyx: And this is the kind of Jason Wei type emergence properties that people kind of look for. I think what made this paper stand out as well, so he developed the benchmark for steganography collusion, and he also focused on shelling point collusion, which is very low coordination. For agreeing on a decoding encoding format, you kind of need to have some [00:29:00] agreement on that.[00:29:00] swyx: But, but shelling point means like very, very low or almost no coordination. So for example, if I, if I ask someone, if the only message I give you is meet me in New York and you're not aware. Or when you would probably meet me at Grand Central Station. That is the Grand Central Station is a shelling point.[00:29:16] swyx: And it's probably somewhere, somewhere during the day. That is the shelling point of New York is Grand Central. To that extent, shelling points for steganography are things like the, the, the common decoding methods that we talked about. It will be interesting at some point in the future when we are worried about alignment.[00:29:30] swyx: It is not interesting today, but it's interesting that DeepMind is already thinking about this.[00:29:36] Alessio: I think that's like one of the hardest things about NeurIPS. It's like the long tail. I[00:29:41] swyx: found a pricing guy. I'm going to feature him on the podcast. Basically, this guy from NVIDIA worked out the optimal pricing for language models.[00:29:51] swyx: It's basically an econometrics paper at NeurIPS, where everyone else is talking about GPUs. And the guy with the GPUs is[00:29:57] Alessio: talking[00:29:57] swyx: about economics instead. [00:30:00] That was the sort of fun one. So the focus I saw is that model papers at NeurIPS are kind of dead. No one really presents models anymore. It's just data sets.[00:30:12] swyx: This is all the grad students are working on. So like there was a data sets track and then I was looking around like, I was like, you don't need a data sets track because every paper is a data sets paper. And so data sets and benchmarks, they're kind of flip sides of the same thing. So Yeah. Cool. Yeah, if you're a grad student, you're a GPU boy, you kind of work on that.[00:30:30] swyx: And then the, the sort of big model that people walk around and pick the ones that they like, and then they use it in their models. And that's, that's kind of how it develops. I, I feel like, um, like, like you didn't last year, you had people like Hao Tian who worked on Lava, which is take Lama and add Vision.[00:30:47] swyx: And then obviously actually I hired him and he added Vision to Grok. Now he's the Vision Grok guy. This year, I don't think there was any of those.[00:30:55] Alessio: What were the most popular, like, orals? Last year it was like the [00:31:00] Mixed Monarch, I think, was like the most attended. Yeah, uh, I need to look it up. Yeah, I mean, if nothing comes to mind, that's also kind of like an answer in a way.[00:31:10] Alessio: But I think last year there was a lot of interest in, like, furthering models and, like, different architectures and all of that.[00:31:16] swyx: I will say that I felt the orals, oral picks this year were not very good. Either that or maybe it's just a So that's the highlight of how I have changed in terms of how I view papers.[00:31:29] swyx: So like, in my estimation, two of the best papers in this year for datasets or data comp and refined web or fine web. These are two actually industrially used papers, not highlighted for a while. I think DCLM got the spotlight, FineWeb didn't even get the spotlight. So like, it's just that the picks were different.[00:31:48] swyx: But one thing that does get a lot of play that a lot of people are debating is the role that's scheduled. This is the schedule free optimizer paper from Meta from Aaron DeFazio. And this [00:32:00] year in the ML community, there's been a lot of chat about shampoo, soap, all the bathroom amenities for optimizing your learning rates.[00:32:08] swyx: And, uh, most people at the big labs are. Who I asked about this, um, say that it's cute, but it's not something that matters. I don't know, but it's something that was discussed and very, very popular. 4Wars[00:32:19] Alessio: of AI recap maybe, just quickly. Um, where do you want to start? Data?[00:32:26] swyx: So to remind people, this is the 4Wars piece that we did as one of our earlier recaps of this year.[00:32:31] swyx: And the belligerents are on the left, journalists, writers, artists, anyone who owns IP basically, New York Times, Stack Overflow, Reddit, Getty, Sarah Silverman, George RR Martin. Yeah, and I think this year we can add Scarlett Johansson to that side of the fence. So anyone suing, open the eye, basically. I actually wanted to get a snapshot of all the lawsuits.[00:32:52] swyx: I'm sure some lawyer can do it. That's the data quality war. On the right hand side, we have the synthetic data people, and I think we talked about Lumna's talk, you know, [00:33:00] really showing how much synthetic data has come along this year. I think there was a bit of a fight between scale. ai and the synthetic data community, because scale.[00:33:09] swyx: ai published a paper saying that synthetic data doesn't work. Surprise, surprise, scale. ai is the leading vendor of non synthetic data. Only[00:33:17] Alessio: cage free annotated data is useful.[00:33:21] swyx: So I think there's some debate going on there, but I don't think it's much debate anymore that at least synthetic data, for the reasons that are blessed in Luna's talk, Makes sense.[00:33:32] swyx: I don't know if you have any perspectives there.[00:33:34] Alessio: I think, again, going back to the reinforcement fine tuning, I think that will change a little bit how people think about it. I think today people mostly use synthetic data, yeah, for distillation and kind of like fine tuning a smaller model from like a larger model.[00:33:46] Alessio: I'm not super aware of how the frontier labs use it outside of like the rephrase, the web thing that Apple also did. But yeah, I think it'll be. Useful. I think like whether or not that gets us the big [00:34:00] next step, I think that's maybe like TBD, you know, I think people love talking about data because it's like a GPU poor, you know, I think, uh, synthetic data is like something that people can do, you know, so they feel more opinionated about it compared to, yeah, the optimizers stuff, which is like,[00:34:17] swyx: they don't[00:34:17] Alessio: really work[00:34:18] swyx: on.[00:34:18] swyx: I think that there is an angle to the reasoning synthetic data. So this year, we covered in the paper club, the star series of papers. So that's star, Q star, V star. It basically helps you to synthesize reasoning steps, or at least distill reasoning steps from a verifier. And if you look at the OpenAI RFT, API that they released, or that they announced, basically they're asking you to submit graders, or they choose from a preset list of graders.[00:34:49] swyx: Basically It feels like a way to create valid synthetic data for them to fine tune their reasoning paths on. Um, so I think that is another angle where it starts to make sense. And [00:35:00] so like, it's very funny that basically all the data quality wars between Let's say the music industry or like the newspaper publishing industry or the textbooks industry on the big labs.[00:35:11] swyx: It's all of the pre training era. And then like the new era, like the reasoning era, like nobody has any problem with all the reasoning, especially because it's all like sort of math and science oriented with, with very reasonable graders. I think the more interesting next step is how does it generalize beyond STEM?[00:35:27] swyx: We've been using O1 for And I would say like for summarization and creative writing and instruction following, I think it's underrated. I started using O1 in our intro songs before we killed the intro songs, but it's very good at writing lyrics. You know, I can actually say like, I think one of the O1 pro demos.[00:35:46] swyx: All of these things that Noam was showing was that, you know, you can write an entire paragraph or three paragraphs without using the letter A, right?[00:35:53] Creative Writing with AI[00:35:53] swyx: So like, like literally just anything instead of token, like not even token level, character level manipulation and [00:36:00] counting and instruction following. It's, uh, it's very, very strong.[00:36:02] swyx: And so no surprises when I ask it to rhyme, uh, and to, to create song lyrics, it's going to do that very much better than in previous models. So I think it's underrated for creative writing.[00:36:11] Alessio: Yeah.[00:36:12] Legal and Ethical Issues in AI[00:36:12] Alessio: What do you think is the rationale that they're going to have in court when they don't show you the thinking traces of O1, but then they want us to, like, they're getting sued for using other publishers data, you know, but then on their end, they're like, well, you shouldn't be using my data to then train your model.[00:36:29] Alessio: So I'm curious to see how that kind of comes. Yeah, I mean, OPA has[00:36:32] swyx: many ways to publish, to punish people without bringing, taking them to court. Already banned ByteDance for distilling their, their info. And so anyone caught distilling the chain of thought will be just disallowed to continue on, on, on the API.[00:36:44] swyx: And it's fine. It's no big deal. Like, I don't even think that's an issue at all, just because the chain of thoughts are pretty well hidden. Like you have to work very, very hard to, to get it to leak. And then even when it leaks the chain of thought, you don't know if it's, if it's [00:37:00] The bigger concern is actually that there's not that much IP hiding behind it, that Cosign, which we talked about, we talked to him on Dev Day, can just fine tune 4.[00:37:13] swyx: 0 to beat 0. 1 Cloud SONET so far is beating O1 on coding tasks without, at least O1 preview, without being a reasoning model, same for Gemini Pro or Gemini 2. 0. So like, how much is reasoning important? How much of a moat is there in this, like, All of these are proprietary sort of training data that they've presumably accomplished.[00:37:34] swyx: Because even DeepSeek was able to do it. And they had, you know, two months notice to do this, to do R1. So, it's actually unclear how much moat there is. Obviously, you know, if you talk to the Strawberry team, they'll be like, yeah, I mean, we spent the last two years doing this. So, we don't know. And it's going to be Interesting because there'll be a lot of noise from people who say they have inference time compute and actually don't because they just have fancy chain of thought.[00:38:00][00:38:00] swyx: And then there's other people who actually do have very good chain of thought. And you will not see them on the same level as OpenAI because OpenAI has invested a lot in building up the mythology of their team. Um, which makes sense. Like the real answer is somewhere in between.[00:38:13] Alessio: Yeah, I think that's kind of like the main data war story developing.[00:38:18] The Data War: GPU Poor vs. GPU Rich[00:38:18] Alessio: GPU poor versus GPU rich. Yeah. Where do you think we are? I think there was, again, going back to like the small model thing, there was like a time in which the GPU poor were kind of like the rebel faction working on like these models that were like open and small and cheap. And I think today people don't really care as much about GPUs anymore.[00:38:37] Alessio: You also see it in the price of the GPUs. Like, you know, that market is kind of like plummeted because there's people don't want to be, they want to be GPU free. They don't even want to be poor. They just want to be, you know, completely without them. Yeah. How do you think about this war? You[00:38:52] swyx: can tell me about this, but like, I feel like the, the appetite for GPU rich startups, like the, you know, the, the funding plan is we will raise 60 million and [00:39:00] we'll give 50 of that to NVIDIA.[00:39:01] swyx: That is gone, right? Like, no one's, no one's pitching that. This was literally the plan, the exact plan of like, I can name like four or five startups, you know, this time last year. So yeah, GPU rich startups gone.[00:39:12] The Rise of GPU Ultra Rich[00:39:12] swyx: But I think like, The GPU ultra rich, the GPU ultra high net worth is still going. So, um, now we're, you know, we had Leopold's essay on the trillion dollar cluster.[00:39:23] swyx: We're not quite there yet. We have multiple labs, um, you know, XAI very famously, you know, Jensen Huang praising them for being. Best boy number one in spinning up 100, 000 GPU cluster in like 12 days or something. So likewise at Meta, likewise at OpenAI, likewise at the other labs as well. So like the GPU ultra rich are going to keep doing that because I think partially it's an article of faith now that you just need it.[00:39:46] swyx: Like you don't even know what it's going to, what you're going to use it for. You just, you just need it. And it makes sense that if, especially if we're going into. More researchy territory than we are. So let's say 2020 to 2023 was [00:40:00] let's scale big models territory because we had GPT 3 in 2020 and we were like, okay, we'll go from 1.[00:40:05] swyx: 75b to 1. 8b, 1. 8t. And that was GPT 3 to GPT 4. Okay, that's done. As far as everyone is concerned, Opus 3. 5 is not coming out, GPT 4. 5 is not coming out, and Gemini 2, we don't have Pro, whatever. We've hit that wall. Maybe I'll call it the 2 trillion perimeter wall. We're not going to 10 trillion. No one thinks it's a good idea, at least from training costs, from the amount of data, or at least the inference.[00:40:36] swyx: Would you pay 10x the price of GPT Probably not. Like, like you want something else that, that is at least more useful. So it makes sense that people are pivoting in terms of their inference paradigm.[00:40:47] Emerging Trends in AI Models[00:40:47] swyx: And so when it's more researchy, then you actually need more just general purpose compute to mess around with, uh, at the exact same time that production deployments of the old, the previous paradigm is still ramping up,[00:40:58] swyx: um,[00:40:58] swyx: uh, pretty aggressively.[00:40:59] swyx: So [00:41:00] it makes sense that the GPU rich are growing. We have now interviewed both together and fireworks and replicates. Uh, we haven't done any scale yet. But I think Amazon, maybe kind of a sleeper one, Amazon, in a sense of like they, at reInvent, I wasn't expecting them to do so well, but they are now a foundation model lab.[00:41:18] swyx: It's kind of interesting. Um, I think, uh, you know, David went over there and started just creating models.[00:41:25] Alessio: Yeah, I mean, that's the power of prepaid contracts. I think like a lot of AWS customers, you know, they do this big reserve instance contracts and now they got to use their money. That's why so many startups.[00:41:37] Alessio: Get bought through the AWS marketplace so they can kind of bundle them together and prefer pricing.[00:41:42] swyx: Okay, so maybe GPU super rich doing very well, GPU middle class dead, and then GPU[00:41:48] Alessio: poor. I mean, my thing is like, everybody should just be GPU rich. There shouldn't really be, even the GPU poorest, it's like, does it really make sense to be GPU poor?[00:41:57] Alessio: Like, if you're GPU poor, you should just use the [00:42:00] cloud. Yes, you know, and I think there might be a future once we kind of like figure out what the size and shape of these models is where like the tiny box and these things come to fruition where like you can be GPU poor at home. But I think today is like, why are you working so hard to like get these models to run on like very small clusters where it's like, It's so cheap to run them.[00:42:21] Alessio: Yeah, yeah,[00:42:22] swyx: yeah. I think mostly people think it's cool. People think it's a stepping stone to scaling up. So they aspire to be GPU rich one day and they're working on new methods. Like news research, like probably the most deep tech thing they've done this year is Distro or whatever the new name is.[00:42:38] swyx: There's a lot of interest in heterogeneous computing, distributed computing. I tend generally to de emphasize that historically, but it may be coming to a time where it is starting to be relevant. I don't know. You know, SF compute launched their compute marketplace this year, and like, who's really using that?[00:42:53] swyx: Like, it's a bunch of small clusters, disparate types of compute, and if you can make that [00:43:00] useful, then that will be very beneficial to the broader community, but maybe still not the source of frontier models. It's just going to be a second tier of compute that is unlocked for people, and that's fine. But yeah, I mean, I think this year, I would say a lot more on device, We are, I now have Apple intelligence on my phone.[00:43:19] swyx: Doesn't do anything apart from summarize my notifications. But still, not bad. Like, it's multi modal.[00:43:25] Alessio: Yeah, the notification summaries are so and so in my experience.[00:43:29] swyx: Yeah, but they add, they add juice to life. And then, um, Chrome Nano, uh, Gemini Nano is coming out in Chrome. Uh, they're still feature flagged, but you can, you can try it now if you, if you use the, uh, the alpha.[00:43:40] swyx: And so, like, I, I think, like, you know, We're getting the sort of GPU poor version of a lot of these things coming out, and I think it's like quite useful. Like Windows as well, rolling out RWKB in sort of every Windows department is super cool. And I think the last thing that I never put in this GPU poor war, that I think I should now, [00:44:00] is the number of startups that are GPU poor but still scaling very well, as sort of wrappers on top of either a foundation model lab, or GPU Cloud.[00:44:10] swyx: GPU Cloud, it would be Suno. Suno, Ramp has rated as one of the top ranked, fastest growing startups of the year. Um, I think the last public number is like zero to 20 million this year in ARR and Suno runs on Moto. So Suno itself is not GPU rich, but they're just doing the training on, on Moto, uh, who we've also talked to on, on the podcast.[00:44:31] swyx: The other one would be Bolt, straight cloud wrapper. And, and, um, Again, another, now they've announced 20 million ARR, which is another step up from our 8 million that we put on the title. So yeah, I mean, it's crazy that all these GPU pores are finding a way while the GPU riches are also finding a way. And then the only failures, I kind of call this the GPU smiling curve, where the edges do well, because you're either close to the machines, and you're like [00:45:00] number one on the machines, or you're like close to the customers, and you're number one on the customer side.[00:45:03] swyx: And the people who are in the middle. Inflection, um, character, didn't do that great. I think character did the best of all of them. Like, you have a note in here that we apparently said that character's price tag was[00:45:15] Alessio: 1B.[00:45:15] swyx: Did I say that?[00:45:16] Alessio: Yeah. You said Google should just buy them for 1B. I thought it was a crazy number.[00:45:20] Alessio: Then they paid 2. 7 billion. I mean, for like,[00:45:22] swyx: yeah.[00:45:22] Alessio: What do you pay for node? Like, I don't know what the game world was like. Maybe the starting price was 1B. I mean, whatever it was, it worked out for everybody involved.[00:45:31] The Multi-Modality War[00:45:31] Alessio: Multimodality war. And this one, we never had text to video in the first version, which now is the hottest.[00:45:37] swyx: Yeah, I would say it's a subset of image, but yes.[00:45:40] Alessio: Yeah, well, but I think at the time it wasn't really something people were doing, and now we had VO2 just came out yesterday. Uh, Sora was released last month, last week. I've not tried Sora, because the day that I tried, it wasn't, yeah. I[00:45:54] swyx: think it's generally available now, you can go to Sora.[00:45:56] swyx: com and try it. Yeah, they had[00:45:58] Alessio: the outage. Which I [00:46:00] think also played a part into it. Small things. Yeah. What's the other model that you posted today that was on Replicate? Video or OneLive?[00:46:08] swyx: Yeah. Very, very nondescript name, but it is from Minimax, which I think is a Chinese lab. The Chinese labs do surprisingly well at the video models.[00:46:20] swyx: I'm not sure it's actually Chinese. I don't know. Hold me up to that. Yep. China. It's good. Yeah, the Chinese love video. What can I say? They have a lot of training data for video. Or a more relaxed regulatory environment.[00:46:37] Alessio: Uh, well, sure, in some way. Yeah, I don't think there's much else there. I think like, you know, on the image side, I think it's still open.[00:46:45] Alessio: Yeah, I mean,[00:46:46] swyx: 11labs is now a unicorn. So basically, what is multi modality war? Multi modality war is, do you specialize in a single modality, right? Or do you have GodModel that does all the modalities? So this is [00:47:00] definitely still going, in a sense of 11 labs, you know, now Unicorn, PicoLabs doing well, they launched Pico 2.[00:47:06] swyx: 0 recently, HeyGen, I think has reached 100 million ARR, Assembly, I don't know, but they have billboards all over the place, so I assume they're doing very, very well. So these are all specialist models, specialist models and specialist startups. And then there's the big labs who are doing the sort of all in one play.[00:47:24] swyx: And then here I would highlight Gemini 2 for having native image output. Have you seen the demos? Um, yeah, it's, it's hard to keep up. Literally they launched this last week and a shout out to Paige Bailey, who came to the Latent Space event to demo on the day of launch. And she wasn't prepared. She was just like, I'm just going to show you.[00:47:43] swyx: So they have voice. They have, you know, obviously image input, and then they obviously can code gen and all that. But the new one that OpenAI and Meta both have but they haven't launched yet is image output. So you can literally, um, I think their demo video was that you put in an image of a [00:48:00] car, and you ask for minor modifications to that car.[00:48:02] swyx: They can generate you that modification exactly as you asked. So there's no need for the stable diffusion or comfy UI workflow of like mask here and then like infill there in paint there and all that, all that stuff. This is small model nonsense. Big model people are like, huh, we got you in as everything in the transformer.[00:48:21] swyx: This is the multimodality war, which is, do you, do you bet on the God model or do you string together a whole bunch of, uh, Small models like a, like a chump. Yeah,[00:48:29] Alessio: I don't know, man. Yeah, that would be interesting. I mean, obviously I use Midjourney for all of our thumbnails. Um, they've been doing a ton on the product, I would say.[00:48:38] Alessio: They launched a new Midjourney editor thing. They've been doing a ton. Because I think, yeah, the motto is kind of like, Maybe, you know, people say black forest, the black forest models are better than mid journey on a pixel by pixel basis. But I think when you put it, put it together, have you tried[00:48:53] swyx: the same problems on black forest?[00:48:55] Alessio: Yes. But the problem is just like, you know, on black forest, it generates one image. And then it's like, you got to [00:49:00] regenerate. You don't have all these like UI things. Like what I do, no, but it's like time issue, you know, it's like a mid[00:49:06] swyx: journey. Call the API four times.[00:49:08] Alessio: No, but then there's no like variate.[00:49:10] Alessio: Like the good thing about mid journey is like, you just go in there and you're cooking. There's a lot of stuff that just makes it really easy. And I think people underestimate that. Like, it's not really a skill issue, because I'm paying mid journey, so it's a Black Forest skill issue, because I'm not paying them, you know?[00:49:24] Alessio: Yeah,[00:49:25] swyx: so, okay, so, uh, this is a UX thing, right? Like, you, you, you understand that, at least, we think that Black Forest should be able to do all that stuff. I will also shout out, ReCraft has come out, uh, on top of the image arena that, uh, artificial analysis has done, has apparently, uh, Flux's place. Is this still true?[00:49:41] swyx: So, Artificial Analysis is now a company. I highlighted them I think in one of the early AI Newses of the year. And they have launched a whole bunch of arenas. So, they're trying to take on LM Arena, Anastasios and crew. And they have an image arena. Oh yeah, Recraft v3 is now beating Flux 1. 1. Which is very surprising [00:50:00] because Flux And Black Forest Labs are the old stable diffusion crew who left stability after, um, the management issues.[00:50:06] swyx: So Recurve has come from nowhere to be the top image model. Uh, very, very strange. I would also highlight that Grok has now launched Aurora, which is, it's very interesting dynamics between Grok and Black Forest Labs because Grok's images were originally launched, uh, in partnership with Black Forest Labs as a, as a thin wrapper.[00:50:24] swyx: And then Grok was like, no, we'll make our own. And so they've made their own. I don't know, there are no APIs or benchmarks about it. They just announced it. So yeah, that's the multi modality war. I would say that so far, the small model, the dedicated model people are winning, because they are just focused on their tasks.[00:50:42] swyx: But the big model, People are always catching up. And the moment I saw the Gemini 2 demo of image editing, where I can put in an image and just request it and it does, that's how AI should work. Not like a whole bunch of complicated steps. So it really is something. And I think one frontier that we haven't [00:51:00] seen this year, like obviously video has done very well, and it will continue to grow.[00:51:03] swyx: You know, we only have Sora Turbo today, but at some point we'll get full Sora. Oh, at least the Hollywood Labs will get Fulsora. We haven't seen video to audio, or video synced to audio. And so the researchers that I talked to are already starting to talk about that as the next frontier. But there's still maybe like five more years of video left to actually be Soda.[00:51:23] swyx: I would say that Gemini's approach Compared to OpenAI, Gemini seems, or DeepMind's approach to video seems a lot more fully fledged than OpenAI. Because if you look at the ICML recap that I published that so far nobody has listened to, um, that people have listened to it. It's just a different, definitely different audience.[00:51:43] swyx: It's only seven hours long. Why are people not listening? It's like everything in Uh, so, so DeepMind has, is working on Genie. They also launched Genie 2 and VideoPoet. So, like, they have maybe four years advantage on world modeling that OpenAI does not have. Because OpenAI basically only started [00:52:00] Diffusion Transformers last year, you know, when they hired, uh, Bill Peebles.[00:52:03] swyx: So, DeepMind has, has a bit of advantage here, I would say, in, in, in showing, like, the reason that VO2, while one, They cherry pick their videos. So obviously it looks better than Sora, but the reason I would believe that VO2, uh, when it's fully launched will do very well is because they have all this background work in video that they've done for years.[00:52:22] swyx: Like, like last year's NeurIPS, I already was interviewing some of their video people. I forget their model name, but for, for people who are dedicated fans, they can go to NeurIPS 2023 and see, see that paper.[00:52:32] Alessio: And then last but not least, the LLMOS. We renamed it to Ragops, formerly known as[00:52:39] swyx: Ragops War. I put the latest chart on the Braintrust episode.[00:52:43] swyx: I think I'm going to separate these essays from the episode notes. So the reason I used to do that, by the way, is because I wanted to show up on Hacker News. I wanted the podcast to show up on Hacker News. So I always put an essay inside of there because Hacker News people like to read and not listen.[00:52:58] Alessio: So episode essays,[00:52:59] swyx: I remember [00:53:00] purchasing them separately. You say Lanchain Llama Index is still growing.[00:53:03] Alessio: Yeah, so I looked at the PyPy stats, you know. I don't care about stars. On PyPy you see Do you want to share your screen? Yes. I prefer to look at actual downloads, not at stars on GitHub. So if you look at, you know, Lanchain still growing.[00:53:20] Alessio: These are the last six months. Llama Index still growing. What I've basically seen is like things that, One, obviously these things have A commercial product. So there's like people buying this and sticking with it versus kind of hopping in between things versus, you know, for example, crew AI, not really growing as much.[00:53:38] Alessio: The stars are growing. If you look on GitHub, like the stars are growing, but kind of like the usage is kind of like flat. In the last six months, have they done some[00:53:46] swyx: kind of a reorg where they did like a split of packages? And now it's like a bundle of packages. Sometimes that happens, you know, I didn't see that.[00:53:54] swyx: I can see both. I can, I can see both happening. The crew AI is, is very loud, but, but not used. [00:54:00] And then,[00:54:00] Alessio: yeah. But anyway, to me, it's just like, yeah, there's no split. I mean, auto similar with LGBT is like, they're still a wait list. For auto GPT to be used. Yeah, they're[00:54:12] swyx: still kicking. They announced some stuff recently.[00:54:14] swyx: But I think[00:54:14] Alessio: that's another one. It's the fastest growing project in the history of GitHub. But I think, you know, when you maybe like run the numbers on like the value of the stars and like the value of the hype. I think in AI you see this a lot, which is like a lot of stars, a lot of interest at a rate that you didn't really see in the past in open source, where nobody's running to start.[00:54:33] Alessio: Uh, you know, a NoSQL database. It's kind of like just to be able to actually use it. Yeah.[00:54:37] swyx: I think one thing that's interesting here, one obviously is that in AI, you kind of get paid to promise things and then you, to deliver them, you know, people have a lot of patience. I think that patience has come down over time.[00:54:49] swyx: One example here is Devin, right this year, where a lot of promise in March and then, and then it took nine months to get to GA. Uh, but I think people are still coming around now and Devin, Devin's [00:55:00] product has improved a little bit, hasn't he? Even you're going to be a paying customer. So I think something Devon like will work.[00:55:05] swyx: I don't know if it's Devon itself. The Auto GPT has an interesting second layer in terms of what I think is the dynamics going on here, which is a very AI specific layer. Over promising under delivering applies to any startup, but for AI specifically, there's this promise of generality that I can do anything, right?[00:55:24] swyx: So Auto GPT's initial problem was making money, like increase my net worth. And I think. That means that there's a lot of broad interest from a lot of different people who are trying to do all different things on this one project. So that's why this concentrates a lot of stars. And then obviously, because it does too much, maybe, or it's not focused enough, then it fails to deploy.[00:55:44] swyx: So that would be my explanation for why the interest to usage ratio is so low. And the second one is obviously pure execution, like the team needs to have a vision and execute, like half the core team left right after AI Engineer Summit last year. [00:56:00] That will be my explanation as to why, like this promise of generality works basically only for ChatGPT and maybe for this year's Notebook LM.[00:56:09] swyx: Like, sticking anything in there, it'll mostly be direct. And then for basically everyone else, it's like, you know, we will help you complete code, we will help you with your PR reviews. Like, small things.[00:56:21] Alessio: Alright, code interpreting, we talked about a bunch of times. We soft announced the E2B fundraising on this podcast.[00:56:29] Alessio: Code sandbox got acquired by Together AI. Last week, um, which are now also going to offer as an API. So, uh, more and more activity, which is great. Yeah. And then, uh, in the last step, two episodes ago with Bolt, we talked about the web container stuff that we've been working on. I think like there's maybe the spectrum of code interpreting, which is like, You know, dedicated SDK.[00:56:53] Alessio: There's like, yeah, the models of the world, which is like, Hey, we got a sandbox. Now you just kind of run the commands and orchestrate all of that. [00:57:00] I think this is one of the, I mean, it'd be screwed. That's just been crazy just because, I mean. Everybody needs to run code, right? And I think now all the products and the everybody's graduating to like, okay, it's not enough to just do chat.[00:57:13] Alessio: So perplexity, which is a easy to be customers, they do all these nice charts for like finance and all these different things. It's like the products are maturing and I think this is becoming more and more of kind of like a hair on fire. problem, so to speak. So yeah, excited to see more. And this was one that really wasn't on the radar when we first wrote[00:57:32] swyx: the four wars.[00:57:33] swyx: Yeah, I think mostly because I was trying to limit it to Ragnops. But I think now that the frontier has expanded in terms of the core set of tools, core set of tools would include Code interpreting, like, like tools that every agent needs, right? And Graham in his state of agents talk had this as well, which is kind of interesting for me.[00:57:55] swyx: Cause like everyone finds the same set of things. So it's basically like someone, [00:58:00] everyone needs web browsing. Everyone needs. Code interpreting, and then everyone needs some kind of memory or planning or whatever that is. We'll discover this more over time, but I think this is what we've discovered so far.[00:58:12] swyx: I will also call out Morphlabs for launching a time travel VM. I think that basically the statefulness of these things needs to be locked down. A lot. Basically, you can't just spin up a VM, run code on it, and then kill it. It's because sometimes you might need to time travel back, like unwind, or fork, to explore different paths for sort of like a tree search approach to your agent development.[00:58:38] swyx: I would call out the newer ones, the new implementations as The emerging frontier in terms of like what people kind of are going to need for agents to do very fan out approaches to all this sort of code execution. And then I'll also call out that I think chat2bt canvas with what they launched in the 12 days of shipmas that they announced has surprisingly superseded Code Interpreter.[00:58:59] swyx: Like [00:59:00] Code Interpreter was last year's thing. And now canvas can also write code and also run code. And do more than Code Interpreter used to do. So right now it has not killed it. So there's, there's a toggle box for Canvas and for Code Interpreter when you create a new custom GPTs. You know, my, my old thesis that custom GPTs is your roadmap for investing because it's, it's what everyone needs.[00:59:17] swyx: So now there's a new box called Canvas that everyone has access to, but basically there's no reason why you should use Code Interpreter over Canvas. Like Canvas has incorporated the diff mode that both Anthropic and OpenAI and Fireworks has now shipped that I is going to be the norm for next year. Uh, that everyone needs some kind of diff mode code interpreter thing.[00:59:38] swyx: Like Aitor was also very early to this. Like the Aitor benchmarks were also all based on diffs and Coursera as well.[00:59:45] Alessio: You want to talk about memory? Memory? Uh, you think it's not real? Yeah, I just don't. I think most memory product today, just like a summarization and extraction. I don't think they're very immature.[00:59:58] Alessio: Yeah, there's no implicit [01:00:00] memory, you know, it's not explicit memory of what you've written. There's no implicit extraction of like, Oh, use a node to this, use a node to this 10 times, so you don't like going on hikes at 6am. Like it doesn't, none of the memory products do that. They'll summarize what you say explicitly.[01:00:18] Alessio: When you say[01:00:18] swyx: memory products, you mean that the startups that are more offering memory as a service?[01:00:22] Alessio: Yeah, or even like, you know, it's like memories, you know, it's like based on what I say, it remembers it. So it's less about making an actual memory of my preference, it's more about what I explicitly said, um, and I'm trying to figure out at what level that gets solved, you know, like, is it, do these memory products, like the MGPTs of the world, create a better way to implicitly extract preference or can that be done very well, you know, I think that's why I don't think, it's not that I don't think memory is real, I just don't think that like,[01:00:57] swyx: I would actually agree with that, but I [01:01:00] would just point it to it being immature rather than not needed. It's clearly something that we will want at some point. And so the people developing it now are trying You know, I'm not very good at it, and I would definitely predict that next year will be better, and the year after that will be better than that.[01:01:17] swyx: I definitely think that last time we had the shouldn't you pod with Harrison as a guest host, I over focused on LangMem as a separate product. He has now rolled it into LangGraph as a memory service with the same API. And I think that Everyone will need some kind of memory, and I think that this is, has distinguished itself now as a separate need from a normal rag vector database.[01:01:38] swyx: Like, you will need a memory layer, whether it's on top of a vector database or not, it's up to you. A memory database and a vector database are kind of two different things. Like, I've had to justify this so much, actually, that I have a draft post in the, in Latentspace dashboard that, Uh, basically says like, what is the difference between memory and knowledge?[01:01:53] swyx: And to me, it's very clear. It's like, knowledge is about the world around you, and like, there's knowledge that you have, which is the rag [01:02:00] corpus that you're, maybe your company docs or whatever. And then there's external knowledge, which is the stuff that you Google. So you use something like Exa, whatever.[01:02:07] swyx: And then there's memory, which is my interactions with you over time. Both can be represented by vector databases or knowledge graphs, doesn't really matter. Time is a specifically important one in memory because you need a decay function, and then you also need like a review function. A lot of people are implementing this as sleep.[01:02:24] swyx: Like when you sleep, you like literally you sort of process the day's memories, and you come up with new insights that you then persist and bring into context in the future. So I feel like this is being developed. Langrath has a version of this. ZEP is another one that's based on Neo4j's knowledge graph that has a version of this.[01:02:40] swyx: Um, MGPT used to have this, but I think, I feel like Leda, since it was funded by Quiet Capital has broadened out into more of a sort of general LLMOS type startup, which I feel like there's a bunch of those now, there's this all hands and all this.[01:02:55] Alessio: Do you think this is a LLMOS product or should it be a consumer product?[01:02:59] swyx: I think it's a [01:03:00] building block. I think every, I mean, there should be, just like every consumer product is going to have a, going to eventually want a gateway, you know, for, for managing their requests and ops tool, you know, that kind of stuff, um, code interpreter for maybe not exposing the code, but executing code under the hood for sure.[01:03:18] swyx: So it's going to want memory. So as a consumer, let's say you are a new doc computer who, um, you know, they've, they've launched their own, uh, little agents or if you're a friend. com, you're going to want to invest in memory at some point. Maybe it's not today. Maybe you can push it off a lot further with like a million token context, but at some point you need to compress your memory and to selectively retrieve it.[01:03:43] swyx: And. Then what are you going to do? You have to reinvent the whole memory stack, and these guys have been doing it for a year now.[01:03:49] Alessio: Yeah, to me, it's more like I want to bring the memories. It's almost like they're my memories, right? So why do you[01:03:56] swyx: selectively choose the memories to bring in? Yeah,[01:03:57] Alessio: why does every time that I go to a new product, [01:04:00] it needs to relearn everything about me?[01:04:01] Alessio: Okay, you want portable memories. Yeah, is it like a protocol? Like, how does that work?[01:04:06] swyx: Speaking of protocols, Anthropic's model context protocol that they launched has a 300 line of code memory implementation. Very simple. Very bad news for all the memory startups. But that's all you need. And yeah, it would be nice to have a portable memory of you to ship to everyone else.[01:04:23] swyx: Simple answer is there's no standardization for a while because everyone will experiment with their own stuff. And I think, Anthropic success with MCP suggests that basically no one else but the big labs can do it because no one else has the sway to do this, then that's, that's how it's going to be, like, unless you have something silly, like, okay, some one form of standardization basically came from Georgie Griganov with Llama CPP, right?[01:04:50] swyx: And that was completely open source, completely bottoms up. And that's because there's just a significant amount of work that needed to be done there. And then people build up from there. Another form of standardization is Confit UI from Confit Anonymous. [01:05:00] So like, that kind of standardization can be done.[01:05:03] swyx: So someone basically has to Create that for the roleplay community, because those are the people with the longest memories right now, the roleplay community, as far as I understand it, I've looked at Soli Tavern, I've looked at Cobalt, they only share character cards, and there's like four or five different standardized standard versions of these character cards.[01:05:22] swyx: But nobody has exportable memory yet. If there was anyone that developed memory first that became a standard, it would be those guys.[01:05:28] Alessio: Cool. Excited to see. Thank you. What people built.[01:05:31] The Future of AI Benchmarks[01:05:31] Alessio: Benchmarks. Okay. One of our favorite pet topics.[01:05:34] swyx: Uh, yeah, yeah. Um, so basically I just wanted to mention this briefly. Like, um, I think that in a year, end of year review, it's useful to remind everybody where we were.[01:05:44] swyx: So we talked about how in LMS's ELO, everyone has gone up and it's a very close race. And I think benchmarks as well. I was looking at the OpenAI live stream today. When they introduced O1API with structured output and everything. And the benchmarks [01:06:00] they're talking about are like completely different than the benchmarks that we were talking about this time last year.[01:06:07] swyx: This time last year, we were still talking about MMLU, a little bit of, there's still like GSMAK. There's stuff that's basically in V, One of the hugging face open models leaderboard, right? We talked to Clementine about the decisions that she made to upgrade to V2. I will also say LM Sys, now LM Arena also has emerged this year as, as a, as the leading like battlegrounds between the big frontier labs, but also we have also seen like the emergence of SuiBench, LiveBench, MMU Pro, and Amy, Amy specifically for one, it will be interesting to see that, you know, Top most cited benchmarks of the year from 2020 to 2021, 2, 3, 4, and then going to 5.[01:06:50] swyx: And you can see what has been saturated and solved and what people care about now. And so now people care a lot about frontier math coding, right? There's literally a benchmark called frontier [01:07:00] math, which I spent a bit of time talking about at NeurIPS. There's Amy, there's Livebench, there's MMORPG Pro, and there's SweetBench.[01:07:07] swyx: I feel like this is good. And then, um, there's another one. This time last year, it was GPQA. I'll put math and GPQA here as sort of top benchmarks of last year. At NeurIPS, GPQA was declared dead, which is very sad. People are still talking about GPQA Diamond. So, literally, the name of GPQA is called Google Proof Question Answering.[01:07:28] swyx: So it's supposed to be resistant to saturation for a while. Bye. Uh, and Noam Brown said that GPQ was dead. So now we only care about SuiteBench, LiveBench, MMORPG Pro, AME. And even SuiteBench, we don't care about SuiteBench proper. We care about SuiteBench verified. Uh, we, we care about the SuiteBench multi modal.[01:07:44] swyx: And then we also care about the new Kowinski prize from Andy Kowinski, which is the guy that we talked to yesterday, who has launched a similar sort of Arc AGI attempt on a SuiteBench type metric, which Arguably, it's a bit more useful. OpenAI also has [01:08:00] MLEbench, which is more tracking sort of ML research and bootstrapping, which arguably like this is the key metric that is most relevant for the Frontier Labs, which is when the researchers can automate their own jobs.[01:08:11] swyx: So that is a kink in the acceleration curve, if we were ever to reach that.[01:08:15] Alessio: Yeah, that makes sense. I mean, I'm curious, I think Dylan, At the debate he said SweetBench 80 percent was like a soap for end of next year as a kind of like, you know, watermark that the moms are still improving. And keeping[01:08:28] swyx: when we started the year at 13%.[01:08:30] Alessio: Yeah, exactly.[01:08:31] swyx: And so now we're about 50, um, open hands is around there. And yeah, 80 sounds fine. Uh, Kowinski prize is 90.[01:08:38] Alessio: And then as we get to a hundred,[01:08:39] swyx: then the open source catches up. Oh yeah, magically going to close the gap between the closed source and open source. So basically I think my advice to people is keep track of the slow cooking of benchmark language because the labs that are not that frontier will keep measuring themselves on last year's benchmarks and then the labs that are actually frontier will Tell you about [01:09:00] benchmarks you've never heard of and you'll be like, Oh, like, okay, there's, there's new, there's new territory to, to, to go on.[01:09:05] swyx: That would be the quick tip there. Yeah. And maybe, maybe I won't, uh, belabor this point too much. I was also saying maybe Veo has introduced some new video benchmarks, right? Like basically every new frontier capabilities and this, the next section that we're going to go into introduces new benchmarks.[01:09:18] swyx: We'll also briefly talk about Ruler as like the, the new setup. Uh, you know, last year we was like needle in a haystack and Ruler is basically a multidimensional needle in a haystack.[01:09:26] Alessio: Yeah, we'll link on the episodes. Yeah, this is like a review of all[01:09:30] swyx: the episodes that we've done, which I have in my head.[01:09:32] swyx: This is one of the slides that I did on my Dev Day talk. So we're moving on from benchmarks to capabilities. And I think I have a useful categorization that I've been kind of selling. I'd be curious on your feedback or edits. I think there's basically like, I kind of like the thought spot. MMLU is a model of what's mature, what's emerging, what's frontier, what's niche.[01:09:51] swyx: So mature is stuff that you can just rely on in production, it's solved, everyone has it. So what's solved is general knowledge, MMLU. And what's solved is kind of long context, everyone [01:10:00] has 128K. Today O1 announced 200K, which is Very expensive. I don't know what the price is. What's solved? Kind of solved is RAG.[01:10:09] swyx: There's like 18 different kinds of RAG, but it's mostly solved. Bash transcription, I would say Whisper, is something that you should be using on a as much as possible. And then code generation, kind of solved. There's different tiers of code generation, and I really need to split out single line autocomplete versus multi file generation.[01:10:27] swyx: I think that is definitely emerging. So on the emerging side, tool use, I would still kind of solve. Consider emerging, maybe, maybe more mature already. But they only launched for short output this year. Yeah, yeah, yeah. I think emerging[01:10:37] Alessio: is fine.[01:10:38] swyx: Vision language models, everyone has vision now, I think. Yeah, including Owen.[01:10:42] swyx: So this is clear. A subset of vision is PDF parsing. And I think the community is very excited about the work being done with CodePoly and CodeQuin. What's for you the breakpoint for vision to go to mature? I think it's basically now. This is maybe two months old. Yeah, yeah, yeah. [01:11:00] NVIDIA, most valuable company in the world.[01:11:02] swyx: Also, I think, this was in June, then also they surprised a lot on the upside for their Q3 earnings. I think the quote that I highlighted in AI News was that it is the best, like Blackwell is the best selling series. The in, in the history of the company and they're sold. I mean, obviously they're always sold out, but for him to make that statement, I think it's a, it's another indication that the transition from the H to the B series is gonna go very well.[01:11:30] Alessio: Yeah, the, I mean, if you had just bought N Video and charge your BT game out,[01:11:33] swyx: that would be, yeah. Insane. Uh, you know, which one more, you know, Nvidia Bitcoin, I think, I think Nvidia,[01:11:40] Alessio: I think in gains. Yeah.[01:11:41] swyx: Well, I think the question is like, people ask me like, is there, what's the reason to not invest in Nvidia?[01:11:45] swyx: I think it's really just like the. They have committed to this. They went for a two year cycle to one year cycle, right? And so, it takes one misstep to delay. You know, like, there have been delays in the past. And, like, when delays happen, they're typically very good buying opportunities. Anyway. [01:12:00] Hey, this is Swyx from the editing room.[01:12:03] swyx: I actually just realized that we lost about 15 minutes of audio and video that was in the episode that we shipped, and I'm just cutting it back in and re recording. We don't have time to re record before the end of the year. At least I'm a 31st already, so I'm just going to do my best to re cover what we have and then sort of segue you in nicely to the end.[01:12:26] swyx: Uh, so our plan was basically to cover like what we felt was emerging capabilities, frontier capabilities, and niche capabilities. So emerging would be tool use, visual language models, which you just heard, real time transcription, which I have on one of our upcoming episodes, The Bee, as well as you can try it in Whisper Web GPU, which is amazing.[01:12:46] swyx: Uh, I think diarization capabilities are also maturing as well, but still way too hard to do properly. Like we, we had to do a lot of stuff for the latent space transcripts to, to come out right. Um, I think [01:13:00] maybe, you know, Dwarkesh recently has been talking about how he's using Gemini 2. 0 flash to do it.[01:13:04] swyx: And I think that might be a good effort, a good way to do it. And especially if there's crosstalk involved, that might be really good. But, uh, there might be other reasons to use normal diarization models as well.[01:13:17] Pionote and Frontier Models[01:13:17] swyx: Specifically, pionote. Text and image, we talked about a lot, so I'm just going to skip. And then we go to Frontier, which I think, like, basically, I would say, is on the horizon, but not quite ready for broad usage.[01:13:28] swyx: Like, it's, you know, interesting to show off to people, but, like, we haven't really figured out how, like, the daily use, the large amount of money is going to be made on long inference, on real time, interruptive, Sort of real time API voice mode things on on device models, as well as all the other modalities.[01:13:47] Niche Models and Base Models[01:13:47] swyx: And then niche models, uh, niche capabilities. I always say, like, base models are very underrated. People always love talking to base models as well, um, and we're increasingly getting less access to them. Uh, it's quite [01:14:00] possible, I think, you know, Sam Altman for 2025 was like, asking about what he should, what people want him to ship, or what people want him to open source, and people really want GPT 3 base.[01:14:10] swyx: Uh,[01:14:10] swyx: we may get it. We may get it. It's just for historical interest. Um, but, uh, you know, at this point, but we may get it. Like, it's definitely not a significant IP anymore for him. So, we'll see. Um, you know, I think OpenAI has a lot more things to worry about than shipping based models, but it would be very, very nice things to do for the community.[01:14:30] State Space Models and RWKB[01:14:30] swyx: Um, state space models as well. I would say, like, the hype for state space models this year, even though, um, you know, the post transformers talk at Linspace Live was extremely hyped, uh, and very well attended and watched. Um, I would say, like, it feels like a step down this year. I don't know why. Um, It seems like things are scaling out in states based models and RWKBs.[01:14:53] swyx: So Cartesia, I think, is doing extremely well. We use them for a bunch of stuff, especially for Smalltalks and some of our [01:15:00] sort of Notebook LN podcast clones. I think they're a real challenger to 11 labs as well. And RWKB, of course, is rolling out on Windows. So, um, I, I, I'll still, I'll still say these, these are niches.[01:15:12] swyx: We've been talking about them as the future for a long time. And, I mean, we live technically in a year in the future from last year, and we're still saying the exact same things as we were saying last year. So, what's changed? I don't know. Um, I do think the xLSTM paper, which we will cover when we cover the, sort of, NeurIPS papers, um, is worth a look.[01:15:31] swyx: Um, I, I, I think they, they are very clear eyed as to, um, How do you want to fix LSTM? Okay, so, and then we also want to cover a little bit, uh, like the major themes of the year. Um, and then we wanted to go month by month. So I'll bridge you into, back to the recording, which, uh, we still have the audio of.[01:15:48] Inference Race and Price Wars[01:15:48] swyx: So, the main, one of the major themes is sort of the inference race at the bottom.[01:15:51] swyx: We started this, uh, last year, this time last year with the misdrawl price war of 2023. Um, with a mixed trial going [01:16:00] from 1. 80 per token down to 1. 27, uh, in the span of like a couple of weeks. And, um, you know, I think this, uh, a lot of people are also interested in the price war, sort of the price intelligence curve for this year as well.[01:16:15] swyx: Um, I started tracking it, I think, roundabout in March of 2024 with, uh, Haiku's launch. And so this is, uh, if you're watching the YouTube, this is. What I initially charted out as like, here's the frontier, like everyone's kind of like in a pretty tight range of LMS's ELO versus the model pricing, you can pay more for more intelligence, and you and it'll be cheaper to get less intelligence, but roughly it correlates to aligned, and it's a trend line.[01:16:43] swyx: And then I could update it again in July and see that everything had kind of shifted right. So for the same amount of ELO, let's say GPT 4, 2023. Cloud 3 would be about sort of 11. 75 in ELO, and you used to get that for [01:17:00] like 40 per token, per million tokens. And now you get Cloud 3 Haiku, which is about the same ELO, for 0.[01:17:07] swyx: 50. And so that's a two orders of magnitude improvement in about two years. Sorry, in about a year. Um, but more, more importantly, I think, uh, you can see the more recent launches like Cloud3 Opus, which launched in March this year. Um, now basically superseded, completely, completely dominated by Gemini 1. 5 Pro, which is both cheaper, 5 a month, uh, 5 per million, as well as smarter.[01:17:31] swyx: Uh, so it's about slightly higher than Elo. Um, so, the March frontier. And shift to the July frontier is roughly one order of magnitude improvement per, uh, sort of ISO ELO. Um, and I think what you're starting to see now, uh, in July is the emergence of 4. 0 Mini and DeepSeq v2 as outliers to the July frontier, where July frontier used to be maintained by 4.[01:17:54] swyx: 0. Llama405, Gemini 1. 5 Flash, and Mistral and Nemo. These things kind of break the [01:18:00] frontier. And then if you update it like a month later, I think if I go back a month here, You update it, you can see more items start to appear. Uh, here as well with the August frontier, with Gemini 1. 5 Flash coming out, uh, with an August update as, as compared to the June update, um, being a lot cheaper, uh, and roughly the same ELO.[01:18:20] swyx: And then, uh, we update for September, um, and that, this is one of those things where, um, it really started to, to, we really started to understand the pricing curves being real instead of something that some random person on the internet drew, uh, Who drew on a chart? Because Gemini 1. 5 cut their prices and cut their prices exactly in line with where everyone else is in terms of their Elo price charts If you plot by September we had a O1 preview in pricing and costs and Elos um, so the frontier was O1 preview GPC 4.[01:18:53] swyx: 0. 0. 1 mini, 4. 0. 0. 0 mini, and then Gemini Flash at the low end. That was the [01:19:00] frontier as of September. Gemini 1. 5 Pro was not on that frontier. Then they cut their prices, uh, they halved their prices, and suddenly they were on the frontier. Um, and so it's a very, very tight and predictive line, which I thought it was really interesting and entertaining as well.[01:19:15] swyx: Um, and I thought that was kind of cool. In November, we had 3. 5 haiku new. Um, and obviously we had sonnet as well, uh, sonnet as, uh, as not, I don't know where there's sonnet on this chart, but, Um, haiku new, uh, basically, uh, was 4x the price of old haiku. Or, uh, sorry, 3. 5 haiku was 4x the price of 3 haiku. And people were kind of unhappy about that.[01:19:42] swyx: Um, there's a reasonable, uh, Assumption, to be honest, that it's not a price hike, it's just a bigger model, so it costs more. But we just don't know that. There was no transparency on that, so we are left to draw our own conclusions on what that means. That's just is what it is. So, [01:20:00] yeah, that would be the sort of Price ELO chart.[01:20:03] swyx: I would say that the main update for this one, if you go to my LLM pricing chart, which is public, you can ask me for it, or I've shared it online as well. The most recent one is Amazon Nova, which we briefly, briefly talked about on the pod, where, um, they've really sort of come in and, you know, You know, basically offered Amazon basics LLM, uh, where Amazon Pro, Nova Pro, Nova Lite, and Nova Micro are the efficient frontier for, uh, their intelligence levels of 1, 200 to 1, 300.[01:20:30] swyx: Um, you want to get beyond 1, 300, you have to pay up for the O1s of the world and the 4Os of the world and the Gemini 1. 5 Pros of the world. Um, but, uh, 2Flash is not on here. And it is probably a good deal higher. Flash thinking is not on here, as well as all the other QWQs, R1s, and all the other sort of thinking models.[01:20:49] swyx: So, I'm going to have to update this chart. It's always a struggle to keep up to date. But I want to give you the idea that basically for, uh, through the month through the, through the [01:21:00] Through 2024 for the same amount of elo, what you used to pay at the start of 2024. Um, you know, let's say, you know, 54, 40 to $50 per million tokens, uh, now is available, uh, approximately at, with Amazon Nova, uh, approximately at, I don't know, 0.075.[01:21:22] swyx: dollars per token, so like 7. 5 cents. Um, so that is a couple orders of magnitude at least, uh, actually almost three orders of magnitude improvement in a year. And I used to say that intelligence, the cost intelligence was coming down, uh, one order of magnitude per year, like 10x. Um, you know, that is already faster than Moore's law, but coming down three times this year, um, is something that I think not enough people are talking about.[01:21:50] swyx: And so. Even though people understand that intelligence has become cheaper, I don't think people are appreciating how much more accelerated this year has been. [01:22:00] And obviously I think a lot of people are speculating how much more next year will be with H200s becoming commodity, Blackwell's coming out. We, it's very hard to predict.[01:22:09] swyx: And obviously there are a lot of factors beyond just the GPUs. So that is the sort of thematic overview.[01:22:16] Major AI Themes of the Year[01:22:16] swyx: And then we went into sort of the, the annual overview. This is basically, um, us going through the AI news, uh, releases of the, of, uh, of the year and just picking out favorites. Um, I had Will, our new research assistant, uh, help out with the research, but you can go on to AI News and check out, um, all the, all the sort of top news of the day.[01:22:41] swyx: Uh, but we had a little bit of an AI Rewind thing, which I'll briefly bridge you in back to the recording that we had.[01:22:48] AI Rewind: January to March[01:22:48] swyx: So January, we had the first round of the year for Perfect City. Um, and for me, it was notable that Jeff Bezos backed it. Um, Jeff doesn't invest in a whole lot of companies, but when he does, [01:23:00] um, you know, he backed Google.[01:23:02] swyx: And now he's backing the new Google, which is kind of cool. Perplexity is now worth 9 billion. I think they have four rounds this year.[01:23:10] swyx: Will also picked out that Sam was talking about GPT 5 soon. This was back when he was, I think, at one of the sort of summit type things, Davos. And, um, yeah, no GPT 5. It's actually, we got O1 and O3. Thinking about last year's Dev Day, and this is three months on from Dev Day, people were kind of losing confidence in GPTs, and I feel like that hasn't super recovered yet.[01:23:44] swyx: I hear from people that there are still stuff in the works, and you should not give up on them, and they're actually underrated now. Um, which is good. So, I think people are taking a stab at the problem. I think it's a thing that should exist. And we just need to keep iterating on them. Honestly, [01:24:00] any marketplace is hard.[01:24:01] swyx: It's very hard to judge, given all the other stuff that you've shipped. Um, chatgtp also released memory in February, which we talked about a little bit. We also had Gemini's diversity drama, which we don't tend to talk a ton about in this podcast because we try to keep it technical. But we also started seeing context window size blow out.[01:24:22] swyx: So we, this year, I mean, it was, it was Gemini with one million tokens. Um, But also, I think there's two million tokens talked about. We had a podcast with Gradients talking about how to fine tune for one million tokens. It's not just like what you declare to be your token context, but you also have to use it well.[01:24:40] swyx: And increasingly, I think people are looking at not just Ruler, which is sort of multi needle in a haystack we talked about, but also Muser and like reasoning over long context, not just being able to retrieve over long context. And so that's what I would. Call out there, uh, specifically I think magic. dev as well, made a lot of waves for the 100 [01:25:00] million token model, which was kind of teased last year, but whatever it was, they made some noise about it, um, still not released, so we don't know, but we'll try to get them on, on the podcast.[01:25:09] swyx: In March, Cloud 3 came out. Which, huge, huge, huge for Enthropic. This basically started to mark the shift of market share that we talked about earlier in the pod, where most production traffic was on OpenAI, and now Enthropic, um, had a decent frontier model family that people could shift to, and obviously now we know that Sonnet is, is kind of the workhorse, um, just like 4.[01:25:31] swyx: 0 is the workhorse of, of OpenAI. Devon, um, came out in March, and that was a very, very big launch. It was probably one of the most well executed PR campaigns, um, maybe in tech, maybe this decade. Um, and, and then I think, you know, there was a lot of backlash as to, like, what specifically was real in the, in the videos that they launched with.[01:25:55] swyx: And then they took 9 months to ship to GA, and now you can buy it [01:26:00] for 500 a month and form your own opinion. I think some people are happy, some people less so, but it's very hard to live up to the promises that they made. And the fact that some of them, for some of them, they do, which is interesting. I think the main thing I would caution out for Devon, and I think people call me a Devon show sometimes, because I say nice things, like one nice thing doesn't mean I'm a show.[01:26:22] swyx: Um, Basically, it is that like a lot of the ideas can be copied and this is the always the threat of Quote unquote GPT wrappers that you achieve product market fit with one feature It's gonna be copied by a hundred other people So, of course you gotta compete with branding and better products and better engineering and all that sort of stuff Which Devin has in spades, so we'll see.[01:26:42] AI Rewind: April to June[01:26:42] swyx: April, we actually talked to Yurio and Suno Um, we talked to Suno specifically, but UDL I also got a beta access to, and like, um, AI music generation. We, we played with that on the podcast. I loved it. Some of our friends at the pod like play in their [01:27:00] cars, like I rode in their cars while they played our Suno intro songs and I freaking loved using O1 to craft the lyrics and Suno to, and Yudioh to make the songs.[01:27:10] swyx: But ultimately, like a lot of people, you know, some people were skipping them. I don't know what, Exact percentages, but those, you know, 10 percent of you that skipped it, you're, you're the reason why we cut the intro songs. Um, we also had Lama 3 released. So, you know, I think people always want to see, uh, you know, like a, a good frontier, uh, open source model.[01:27:29] swyx: And Lama 3 obviously delivered on that with the 8B and 70B. The 400B came later. Then, um, May, GPC 4. 0 released, um, we, uh, and it was like kind of a model efficiency thing, but also I think just a really good demo of all the, uh, the things that 4. 0 was capable of. Like, this is where the messaging of OmniModel really started kicking in.[01:27:51] swyx: You know, previously, 4 and 4. 0 Turbo were all text. Um, and not natively, uh, sort of vision. I mean, they had vision, but not [01:28:00] natively voice. And, you know, that, uh, I think everyone was, fell in love immediately with the SkyVoice and SkyVoice got taken away, um, before the public release, and, um, I think it's probably self inflicted.[01:28:13] swyx: Um, I think that the, the version of events that has Sam Altman basically putting a foot in his mouth with a three letter tweet, you know, Um, causing decent grounds for a lawsuit where there was no grounds to be had because they actually just used a voice actress that sounded like Scarlett Johansson. Um, uh, is unfortunate because we could have had it and we, we don't.[01:28:36] swyx: So that's what it is and that's what the consensus seems to be from the people I talk to. Uh, people be pining for the Scarlett Johansson voice. In June, Apple announced Apple Intelligence at WWDC. Um, and, um, we haven't, most of us, if you update your phones, have it now if you're on an iPhone. And I would say it's, like, decent.[01:28:57] swyx: You know, like, I think it wasn't the game [01:29:00] changer thing that caused the Apple stock to rise, like, 20%. And just because everyone was, like, going to upgrade their iPhones just to get Apple Intelligence, it did not become that. But, um, Um, it, it is the, uh, probably the largest scale rollout of transformers yet, um, after Google rolled out BERT for search and, um, and people are using it and it's a 3B, you know, foundation model that's running locally on your phone with Loras that are hot swaps and we have papers for it.[01:29:29] swyx: Honestly, Apple did a fantastic job of doing the best that they can. They're not the most transparent company in the world and nobody expects them to be, but, um, they gave us. More than I think we normally get for Apple tech, and that's very nice for the research community as well. NVIDIA, I think we continue to talk about, I think I was at the Taiwanese trade show, Comtex, and saw him signing, you know, You know, women body [01:30:00] parts.[01:30:00] swyx: And I think that was maybe a sign of the times, maybe a sign that things have peaked, but things are clearly not peaked because they continued going. Ilya, and then, and then that bridges us back into the episode recording. I'm going to stop now and stop yapping. But, uh, Yeah, we, you know, we recorded a whole bunch of stuff.[01:30:18] swyx: We lost it and we're scrambling to re record it for you, but also we're trying to close the chapter on 2024. So, uh, now I'm going to cut back to the recording where we talk about the rest of June, July, August, September, and the second half of 2024 is news. And we'll end the episode there. Ilya came out from the woodwork, raised a billion dollars.[01:30:45] swyx: Dan Gross seems to have now become full time CEO of the company, which is interesting. I thought he was going to be an investor for life, but now he's operating. He was an investor for a short amount of time. What else can we say about Ilya? I think [01:31:00] this idea that you only ship one product and it's a straight shot at superintelligence seems like a really good focusing mission, but then it runs counter to basically both Tesla and OpenAI in terms of the ship intermediate products that get you to that vision.[01:31:17] Alessio: OpenAI now needs then more money because they need to support those products and I think maybe their bet is like 1 billion we can get to the thing. Like we don't want to have to have intermediate steps, like we're just making it clear that like this is what[01:31:30] swyx: it's about. Yeah, but then like where do you get your data?[01:31:33] swyx: Yeah, totally. Um, so, so I think that's the question. I think we can also use this as part of a general theme of the safety wing of OpenAI leaving. It's fair to say that, you know, Yann Leclerc also left and, like, basically the entire super alignment team left.[01:31:52] Alessio: Yeah, then there was artifacts, kind of like the Chajupiti canvas equivalent that came out.[01:31:57] swyx: I think more code oriented. Yeah. [01:32:00] Canvas clone yet, apart from[01:32:03] swyx: OpenAI.[01:32:04] swyx: Interestingly, I think the same person responsible for artifacts and canvas, Karina, officially left Anthropic after this to join OpenAI on the rare reverse moves.[01:32:16] Alessio: In June, I was over 2, 000 people, not including us. I would love to attend the next one. If only we could get[01:32:25] swyx: tickets. We now have it deployed for everybody. Gemini actually kind of beat them to the GA release, which is kind of interesting. Everyone should basically always have this on. As long as you're comfortable with the privacy settings because then you have a second person looking over your shoulder.[01:32:43] swyx: And, like, this time next year, I would be willing to bet that I would just have this running on my machine. And, you know, I think that assistance always on, that you can talk to with vision, that sees what you're seeing. I think that is where, uh, At least one hour of software experience to go, then it will be another few years [01:33:00] for that to happen in real life outside of the screen.[01:33:03] swyx: But for screen experiences, I think it's basically here but not evenly distributed. And you know, we've just seen the GA of this capability that was demoed in June.[01:33:12] AI Rewind: July to September[01:33:12] Alessio: And then July was Lama 3. 1, which, you know, we've done a whole podcast on. But that was, that was great. July and August were kind of quiet.[01:33:19] Alessio: Yeah, structure uploads. We also did a full podcast on that. And then September we got O1. Yes. Strawberry, a. k. a. Qstar, a. k. a. We had a nice party with strawberry glasses. Yes.[01:33:31] swyx: I think very underrated. Like this is basically from the first internal demo of Q of strawberry was, let's say, November 2023. So between November to September, Like, the whole red teaming and everything.[01:33:46] swyx: Honestly, a very good ship rate. Like, I don't know if people are giving OpenAI enough credit for, like, this all being available in ChajGBT and then shortly after in API. I think maybe in the same day, I don't know. I don't remember the exact sequence [01:34:00] already. But like, This is like the frontier model that was like rolled out very, very quickly to the whole world.[01:34:05] swyx: And then we immediately got used to it, immediately said it was s**t because we're still using Sonnet or whatever. But like still very good. And then obviously now we have O1 Pro and O1 Full. I think like in terms of like biggest ships of the year, I think this is it, right?[01:34:18] Alessio: Yeah. Yeah, totally. Yeah. And I think it now opens a whole new Pandora's box for like the inference time compute and all that.[01:34:25] Alessio: Yeah.[01:34:26] swyx: Yeah. It's funny because like it could have been done by anyone else before.[01:34:29] swyx: Yeah,[01:34:30] swyx: literally, this is an open secret. They were working on it ever since they hired Gnome. Um, but no one else did.[01:34:35] swyx: Yeah.[01:34:36] swyx: Another discovery, I think, um, Ilya actually worked on a previous version called GPT 0 in 2021. Same exact idea.[01:34:43] swyx: And it failed. Yeah. Whatever that means. Yeah.[01:34:47] Alessio: Timing. Voice mode also. Voice mode, yeah. I think most people have tried it by now. Because it's generally available. I think your wife also likes it. Yeah, she talks to it all the time. Okay.[01:34:59] AI Rewind: October to December[01:34:59] Alessio: [01:35:00] Canvas in October. Another big release. Have you used it much? Not really, honestly.[01:35:06] swyx: I use it a lot. What do you use it for mostly? Drafting anything. I think that people don't see where all this is heading. Like OpenAI is really competing with Google in everything. Canvas is Google Docs. Canvas is Google Docs. It's a full document editing environment with an auto assister thing at the side that is arguably better than Google Docs, at least for some editing use cases, right?[01:35:26] swyx: Because it has a much better AI integration than Google Docs. Google Docs with Gemini on the side. And so OpenAI is taking on Google and Google Docs. It's also taking on, taking it on in search. And they, you know, they launched their, their little, uh, Chrome extension thing to, to be the default search. And I think like piece by piece, it's, it's kind of really.[01:35:44] swyx: Tackling on Google in a very smart way that I think is additive to workflow and people should start using it as intended, because this is a peek into the future. Maybe they're not successful, but at least they're trying. And I think Google has gone without competition for so long that anyone trying will be, [01:36:00] will be, will at least receive some attention from me.[01:36:03] Alessio: And then yeah, computer use also came out. Um, yeah, that was, yeah, that was a busy, it's been a busy couple months.[01:36:10] swyx: Busy couple months. I would say that computer use was one of the most upvoted demos on Hacker News of the year. But then comparatively, I don't see people using it as much. This is how you feel the difference between a mature capability and an emerging capability.[01:36:25] swyx: Maybe this is why Vision is emerging. Because I launched computer use, you're not using it today. But you use everything else in the mature category. And it's mostly because it's not precise enough, or it's too slow, or it's too expensive. And those would be the main criticisms.[01:36:39] Alessio: Yeah, that makes sense. It's also just like overall uneasiness about just letting it go crazy on your computer.[01:36:46] Alessio: Yeah, no, no, totally. But I think a lot of people do. November. R1, so that was kind of like the open source, so one[01:36:52] swyx: competitor. This was a surprise. Yeah, nobody knew it was coming. Yeah. Everyone knew, like, F1 we had a preview at the Fireworks HQ, and then [01:37:00] I think some other labs did it, but I think R1 and QWQ, Quill, from the Quent team, Both Alibaba affiliated, I think, are the leading contenders on that front end.[01:37:12] swyx: We'll see. We'll see.[01:37:14] Alessio: What else to highlight? I think the Stripe agent toolkit. It's a small thing, but it's just like people are like agents are not real. It's like when you have, you know, companies like Stripe and like start to build things to support it. It might not be real today, but obviously. They don't have to do it because they don't, they're not an AI company, but the fact that they do it shows that there's one demand and so there's belief[01:37:35] swyx: on their end.[01:37:35] swyx: This is a broader thing about, a broader thesis for me that I'm exploring around, do we need special SDKs for agents? Why can't normal SDKs for humans do the same thing? Stripe agent toolkits happens to be a wrapper on the Stripe SDK. It's fine. It's just like a nice little DX layer. But like, it's still unclear to me.[01:37:53] swyx: Uh, I think, um, I have been asked my opinion on this before, and I said, I think I said it on a podcast, which is like, the main layer that you need is [01:38:00] the separate off roles, so that you don't assume it's a human, um, doing these things. And you can lock things down much quicker. You can identify whether it is an agent acting on your behalf or actually you.[01:38:12] Alessio: Do.[01:38:12] swyx: Um, and that, that is something that you need. Um, I had my 11 labs key pwned because I lost my laptop and, uh, I saw a whole bunch of API calls and I was like, Oh, is that me? Or is that, is that someone? And it turned out to be a key that had that committed, uh, onto GitHub and that didn't scrape. And so sourcing of where API usage is coming from, I think, um, you know, you should attribute it to agents and build for that world.[01:38:36] swyx: But other than that, I think SDKs, I would see it as a failure of Dev tech and AI that we need every single thing needs to be reinvented for agents.[01:38:48] Alessio: I agree in some ways. I think in other ways we've also like not always made things super explicit. There's kind of like a lot of defaults that people do when they design APIs but like Um, I think if you were to [01:39:00] redesign them in a world in which the person or the agent using them as like all the most infinite memory and context, like you will maybe do things differently, but I don't know.[01:39:09] Alessio: I think to me that the most interesting is like rest and GraphQL is almost more interesting in the world of agents because agents could come up with so many different things to query versus like before I always thought GraphQL was kind of like not really necessary because like, you know what you need, just build the rest end point for it.[01:39:24] Alessio: So, yeah, I'm curious to see what else. Changes. And then they had the search wars. I think that was, you know, search GPD perplexity, Dropbox, Dropbox dash. Yeah, we had Drew on the pod and then we added the Pioneer Summit. The fact that Dropbox has a Google Drive integration, it's just like if you told somebody five years ago, it's like,[01:39:44] swyx: oh,[01:39:44] Alessio: Dropbox doesn't really care about your files.[01:39:47] Alessio: You know, it's like that doesn't compute. So, yeah, I'm curious to see where. And that[01:39:53] Year-End Reflections and Predictions[01:39:53] swyx: brings us up to December, still developing, I'm curious what the last day of OpenAI shipments will be, I think everyone [01:40:00] is expecting something big there. I think so far it has been a very eventful year, definitely has grown a lot, we were asked by Will actually whether we made predictions, I don't think we did, but Not really, I[01:40:11] Alessio: think we definitely talked about agents.[01:40:14] Alessio: Yes. And I don't know if we said it was the year of the agents, but we said next[01:40:19] swyx: year[01:40:19] Alessio: is the year. No, no, but well, you know, the anatomy of autonomy that was April 2023, you know, so obviously there's been belief for a while. But I think now the models are, I would say maybe the last, yeah. Two months. I made a big push in like capability for like 3.[01:40:35] Alessio: 6, 4. 1.[01:40:36] swyx: Ilya saying the word agentic on stage at Eurips, it's a big deal. Satya, I think also saying that a lot these days. I mean, Sam has been saying that for a while now. So DeepMind, when they announced Gemini 2. 0, they announced Deep Research, but also Project Mariner, which is a browser agent, which is their computer use type thing, as well as Jules, which is their code agent.[01:40:56] swyx: And I think. That basically complements with whatever OpenAI is shipping [01:41:00] next year, which is codename operator, which is their agent thing. It makes sense that if it actually replaces a junior employee, they will charge 2, 000 for it.[01:41:09] Alessio: Yeah, I think that's my whole, I did this post, it's pinned on my Twitter, so you can find it easily, but about skill floor and skill ceiling in jobs.[01:41:17] Alessio: And I think the skill floor more and more, I think 2025 will be the first year where the AI sets the skill floor. Overall, you know, I don't think that has been true in the past, but yeah, I think now really, like, you know, if Devon works, if all these customer support agents are working. So now to be a customer support person, you need to be better than an agent because the economics just don't work.[01:41:38] Alessio: I think the same is going to happen to in software engineering, which I think the skill floor is very low. You know, like there's a lot of people doing software engineering that are really not that good. So I'm curious to see it. And the next year of the recap, what other jobs are going to have that change?[01:41:52] swyx: Yeah. Every NeurIPS that I go, I have some chats with researchers and I'll just highlight the best prediction from that group. And then we'll move on [01:42:00] to end of year recap in terms of, we'll just go down the list of top five podcasts and then we'll end it. So the best prediction was that there will be a foreign spy caught at one of the major labs.[01:42:14] swyx: So this is part of the consciousness already that, uh, you know, like, you know, whenever you see someone who is like too attractive in a San Francisco party, where it's like the ratio is like 100 guys to one girl, and like suddenly the girl is like super interested in you, like, you know, it may not be your looks.[01:42:29] swyx: Um, so, um, There's a lot of like state level secrets that are kept in these labs and not that much security. I think if anything, the situational awareness essay did to raise awareness of it, I think it was directionally correct, even if not precisely correct. We should start caring a lot about this.[01:42:45] swyx: OpenAI has hired a CISO this year. And I think like the security space in general. Oh, I remember what I was going to say about Apple Foundation Model before we cut for a break. They announced Apple Secure Cloud, Cloud Compute. And I think, um, We are also interested in investing in areas [01:43:00] that are basically secure cloud LLM inference for everybody.[01:43:03] swyx: I think like what we have today is not secure enough because it's like normal security when like this is literally a state level interest.[01:43:10] Alessio: Agreed. Top episodes? Yeah. So I'm just going through the sub stack. Number one, the David one. That's the most popular 2024. Why Google failed to make GPT 3?[01:43:21] swyx: I will take a little bit of credit for the naming of that one because I think that was the Hacker News thing.[01:43:26] swyx: It's very funny because, like, actually, obviously he wants to talk about Adept, but then he spent half the episode talking about his time at OpenAI. But I think it was a very useful insight that I'm still using today. Even in, like, the earlier post, I was still referring to what he said. And when we do podcast episodes, I try to look for that.[01:43:42] swyx: I try to look for things that we'll still be referencing in the future. And that concentrated badness, David talked about the Brain Compute Marketplace, and then Ilya in his emails that I covered in the What Ilya Saw essay, had the opening eyesight of this, where they were like, [01:44:00] One big training run is much, much more valuable than the hundred equivalent small training runs.[01:44:05] swyx: So we need to go big. And we need to concentrate better, not spread them.[01:44:08] Alessio: Number two, how notebook. clan was made. Yeah, um, that was fun. Yeah, and everybody, I mean, I think that's like a great example of like, Just timeliness. You know, I think it was top of mind for everybody. There were great guests. Um, it just made the rounds on social media.[01:44:24] swyx: Yeah. Um, and that one, I would say Risa is obviously a star, but she's been on every episode, every podcast, but Isamah, I think, you know, actually being the guy who worked on the audio model, being able to talk to him, I think was, was a great gift for us. And I think people should listen back to how they trained the model.[01:44:41] swyx: Cause I think you put that level of attention on any model. You will make it SOTA. Yeah, that's true. And it's specifically like, uh, they didn't have evals. They just, they had vibes. They had a group session with vibes.[01:44:55] Alessio: The ultimate got to prompting. Yeah, that was number three. I think all these episodes that are like [01:45:00] summarizing things that people care about, but they're disparate.[01:45:03] Alessio: I think always do very well. This helps us[01:45:05] swyx: save on a lot of smaller prompting episodes, right? Yeah. If we interviewed individual paper authors with like a 10 page paper that is just a different prompt, like not as useful as like an overview survey thing. Yeah, I think. The question is what to do from here.[01:45:19] swyx: People have actually, I would, I would say I've been surprised by how well received that was. Should we do ultimate guide to other things? And then should we do prompting 201? Right? Those are the two lessons that we can learn from the success of this one. I think[01:45:32] Alessio: if somebody does the work for us, that was the good thing about Sander.[01:45:35] Alessio: Like he had done all the work for us. Yeah, Sander is very, very[01:45:38] swyx: fastidious about this. So he did a lot of work on that. And you know, I'm definitely keen to have him on next year to talk more prompting. Okay, then the next one is the not safe for work one. Okay.[01:45:48] Alessio: No.[01:45:48] swyx: Or structured outputs. The next one is brain trust.[01:45:52] swyx: Really? Yeah. Okay. We have a different list then. But yeah.[01:45:55] Alessio: I'm just going on the sub[01:45:57] swyx: stack. I see. I see. So that includes the number of [01:46:00] likes, but, uh, I was, I was going by downloads. Hmm. It's[01:46:03] Alessio: fine. I would say this is almost recency bias in the way that like the audience keeps growing and then like the most recent episodes get more views.[01:46:12] Alessio: I see. So I would say definitely like the. NSFW1 was very popular, what people were telling me they really liked, because it was something people don't cover. Um, yeah, structural outputs, I think people like that one. I mean, the same one, yeah, I think that's like something I refer to all the time. I think that's one of the most interesting areas for the new year.[01:46:34] Alessio: the simulation. Oh, WebSim, Wolsim, really? Yeah, not that use case. But like, how do you use that for like model training and like agents learning and all of that?[01:46:44] swyx: Yeah, so I would definitely point to our newest 7 hour long episode on Simulative Environments because it is the, let's say the scaled up, very serious AGI lab version of WebSim and MobileSim.[01:46:58] swyx: If you take it very, very [01:47:00] seriously, you get Genie 2, which is exactly what you need to then build Sora and everything else. Um, so yeah, I think, uh, Simulative AI, still in summer. Still in summer. Still, still coming. And I was actually reflecting on this, like, would you, would you say that the AI winter has, like, coming on?[01:47:15] swyx: Or, like, was it never even here? Because we did AI Winter episode, and I, you know, I was, like, trying to look for signs. I think that's kind of gone now.[01:47:23] Alessio: Yeah. I would say. It was here in the vibes, but not really in the reality. You know, when you look back at the yearly recap, it's like every month there was like progress.[01:47:32] Alessio: There wasn't really a winter. There was maybe like a hype winter, but I don't know if that counts as a real winter. I[01:47:38] swyx: think the scaling has hit a wall thing has been a big driving discussion for 2024.[01:47:43] swyx: Yeah.[01:47:43] swyx: And, you know, with some amount of conclusion on, in Europe's that we were also kind of pointing to in the winter episode, but like, it's not a winter by any means.[01:47:54] swyx: Yeah, we know what winter feels like. It is not winter. So I think things are, things are going well. [01:48:00] I think every time that people think that there's like, Not much happening in AI, just think back to this time last year,[01:48:05] swyx: right?[01:48:06] swyx: And understand how much has changed from benchmarks to frontier models to market share between OpenAI and the rest.[01:48:11] swyx: And then also cover like, you know, the, the various coverage areas that we've marked out, how the discussion has, has evolved a lot and what we take for granted now versus what we did not have a year ago.[01:48:21] Alessio: Yeah. And then just to like throw that out there, there've been 133 funding rounds, over a hundred million in AI.[01:48:28] Alessio: This year.[01:48:29] swyx: Does that include Databricks, the largest venture around in[01:48:31] Alessio: history? 10 billion dollars. Sheesh. Well, that Mosaic now has been bought for two something billion because it was mostly stock, you know, so price goes up. I see. Theoretically. I see. So you just bought at a valuation[01:48:46] swyx: of 40, right? Yeah. It was like 43 or something like that.[01:48:49] swyx: At the time, I remember at the time there was a question about whether or not the evaluation was real.[01:48:53] Alessio: Yeah, well, that's why everybody[01:48:55] swyx: was down. And like Databricks was a private valuation that was like two years old. [01:49:00] It's like, who knows what this thing's worth. Now it's worth 60 billion.[01:49:03] Alessio: It's worth more.[01:49:03] Alessio: That's what it's worth. It's worth more than what you thought. Yeah, it's been a crazy year, but I'm excited for next year. I feel like this is almost like, you know, Now the agent thing needs to happen. And I think that's really the unlock.[01:49:16] swyx: I have to agree with you. Next year is the year of the agent in production.[01:49:21] swyx: Yeah.[01:49:23] Alessio: It's almost like, I'm not 100 percent sure it will happen, but it needs to happen. Otherwise, it's definitely the winter next year. Any other questions? Parting, thoughts.[01:49:33] swyx: I'm very grateful for you. Uh, I think that, I think you've been, uh, the, the, a dream partner to, to build Lanespace with. And, uh, and also the Discord community, the paper club people have been beyond my wildest dreams, like, uh, so supportive and, and successful.[01:49:47] swyx: Like, it's amazing that, you know, the, the community has, you know, grown so much and like the, the vibe has not changed.[01:49:53] Alessio: Yeah. Yeah, that's true. We're almost at 5, 000 people.[01:49:56] swyx: Yeah, we started this discord like four years ago. And still, like, people [01:50:00] get it when they join. Like, you post news here, and then you discuss it in threads.[01:50:03] swyx: And, you know, you try not to self promote too much. And mostly people obey the rules. And sometimes you smack them down a little bit, but that's okay.[01:50:11] Alessio: We rarely have to ban people, which is great. But yeah, man, it's been awesome, man. I think we both started not knowing where this was going to go. And now we've done 100 episodes.[01:50:21] Alessio: It's easy to see how we're going to get to 200. I think maybe when we started, it wasn't easy to see how we would get to 100, you know. Yeah, excited for more. Subscribe on YouTube, because we're doing so much work to make that work. It's very expensive[01:50:35] swyx: for an unclear payoff as to like what we're actually going to get out of it.[01:50:39] swyx: But hopefully people discover us more there. I do believe in YouTube as a podcasting platform much more so than Spotify.[01:50:46] Alessio: Yeah,[01:50:47] swyx: totally.[01:50:48] Alessio: Thank you all for listening. See you in the new year.[01:50:51] swyx: Bye [01:51:00] bye. Get full access to Latent.Space at www.latent.space/subscribe
-
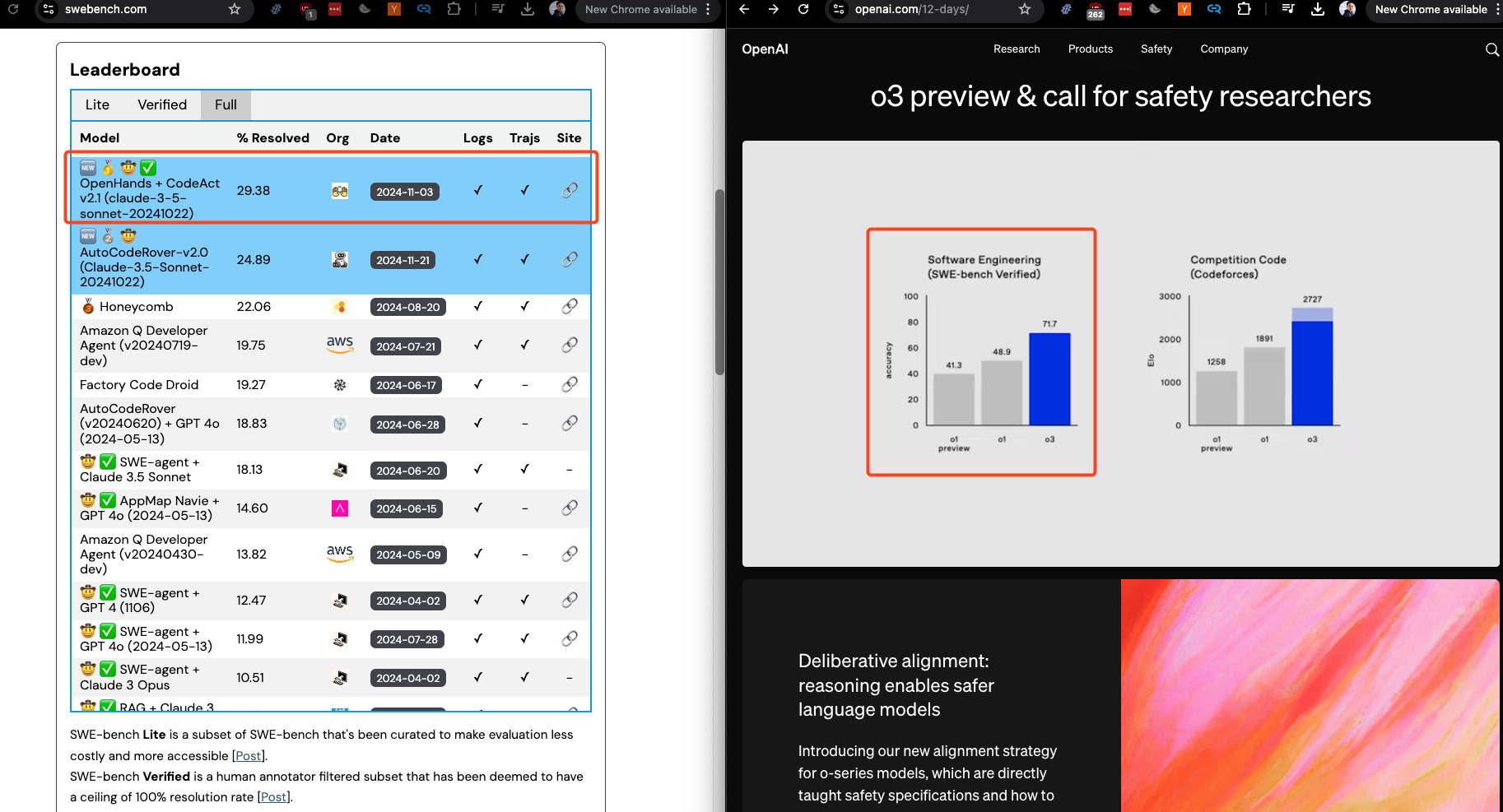 2024 in Agents [LS Live! @ NeurIPS 2024]
2024 in Agents [LS Live! @ NeurIPS 2024]From 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2024-12-25 16:30
Happy holidays! We’ll be sharing snippets from Latent Space LIVE! through the break bringing you the best of 2024! We want to express our deepest appreciation to event sponsors AWS, Daylight Computer, Thoth.ai, StrongCompute, Notable Capital, and most of all all our LS supporters who helped fund the gorgeous venue and A/V production!For NeurIPS last year we did our standard conference podcast coverage interviewing selected papers (that we have now also done for ICLR and ICML), however we felt that we could be doing more to help AI Engineers 1) get more industry-relevant content, and 2) recap 2024 year in review from experts. As a result, we organized the first Latent Space LIVE!, our first in person miniconference, at NeurIPS 2024 in Vancouver.Our next keynote covers The State of LLM Agents, with the triumphant return of Professor Graham Neubig’s return to the pod (his ICLR episode here!). OpenDevin is now a startup known as AllHands! The renamed OpenHands has done extremely well this year, as they end the year sitting comfortably at number 1 on the hardest SWE-Bench Full leaderboard at 29%, though on the smaller SWE-Bench Verified, they are at 53%, behind Amazon Q, devlo, and OpenAI's self reported o3 results at 71.7%.Many are saying that 2025 is going to be the year of agents, with OpenAI, DeepMind and Anthropic setting their sights on consumer and coding agents, vision based computer-using agents and multi agent systems. There has been so much progress on the practical reliability and applications of agents in all domains, from the huge launch of Cognition AI's Devin this year, to the sleeper hit of Cursor Composer and Codeium's Windsurf Cascade in the IDE arena, to the explosive revenue growth of Stackblitz's Bolt, Lovable, and Vercel's v0, and the unicorn rounds and high profile movements of customer support agents like Sierra (now worth $4 billion) and search agents like Perplexity (now worth $9 billion). We wanted to take a little step back to understand the most notable papers of the year in Agents, and Graham indulged with his list of 8 perennial problems in building agents in 2024.Must-Read Papers for the 8 Problems of Agents* The agent-computer interface: CodeAct: Executable Code Actions Elicit Better LLM Agents. Minimial viable tools: Execution Sandbox, File Editor, Web Browsing* The human-agent interface: Chat UI, GitHub Plugin, Remote runtime, …?* Choosing an LLM: See Evaluation of LLMs as Coding Agents on SWE-Bench at 30x - must understand instructions, tools, code, environment, error recovery* Planning: Single Agent Systems vs Multi Agent (CoAct: A Global-Local Hierarchy for Autonomous Agent Collaboration) - Explicit vs Implicit, Curated vs Generated* Reusable common workflows: SteP: Stacked LLM Policies for Web Actions and Agent Workflow Memory - Manual prompting vs Learning from Experience* Exploration: Agentless: Demystifying LLM-based Software Engineering Agents and BAGEL: Bootstrapping Agents by Guiding Exploration with Language* Search: Tree Search for Language Model Agents - explore paths and rewind* Evaluation: Fast Sanity Checks (miniWoB and Aider) and Highly Realistic (WebArena, SWE-Bench) and SWE-Gym: An Open Environment for Training Software Engineering Agents & VerifiersFull Talk on YouTubePlease like and subscribe!Timestamps* 00:00 Welcome to Latent Space Live at NeurIPS 2024* 00:29 State of LLM Agents in 2024* 02:20 Professor Graham Newbig's Insights on Agents* 03:57 Live Demo: Coding Agents in Action* 08:20 Designing Effective Agents* 14:13 Choosing the Right Language Model for Agents* 16:24 Planning and Workflow for Agents* 22:21 Evaluation and Future Predictions for Agents* 25:31 Future of Agent Development* 25:56 Human-Agent Interaction Challenges* 26:48 Expanding Agent Use Beyond Programming* 27:25 Redesigning Systems for Agent Efficiency* 28:03 Accelerating Progress with Agent Technology* 28:28 Call to Action for Open Source Contributions* 30:36 Q&A: Agent Performance and Benchmarks* 33:23 Q&A: Web Agents and Interaction Methods* 37:16 Q&A: Agent Architectures and Improvements* 43:09 Q&A: Self-Improving Agents and Authentication* 47:31 Live Demonstration and Closing RemarksTranscript[00:00:29] State of LLM Agents in 2024[00:00:29] Speaker 9: Our next keynote covers the state of LLM agents. With the triumphant return of Professor Graham Newbig of CMU and OpenDevon, now a startup known as AllHands. The renamed OpenHands has done extremely well this year, as they end the year sitting comfortably at number one on the hardest SWE Benchful leaderboard at 29%.[00:00:53] Speaker 9: Though, on the smaller SWE bench verified, they are at 53 percent behind Amazon Q [00:01:00] Devlo and OpenAI's self reported O3 results at 71. 7%. Many are saying that 2025 is going to be the year of agents, with OpenAI, DeepMind, and Anthropic setting their sights on consumer and coding agents. Vision based computer using agents and multi agent systems.[00:01:22] Speaker 9: There has been so much progress on the practical reliability and applications of agents in all domains, from the huge launch of Cognition AI's Devon this year, to the sleeper hit of Cursor Composer and recent guest Codium's Windsurf Cascade in the IDE arena. To the explosive revenue growth of recent guests StackBlitz's Bolt, Lovable, and Vercel's vZero.[00:01:44] Speaker 9: And the unicorn rounds and high profile movements of customer support agents like Sierra, now worth 4 billion, and search agents like Perplexity, now worth 9 billion. We wanted to take a little step back to understand the most notable papers of the year in [00:02:00] agents, and Graham indulged with his list of eight perennial problems in building agents.[00:02:06] Speaker 9: As always, don't forget to check our show notes for all the selected best papers of 2024, and for the YouTube link to their talk. Graham's slides were especially popular online, and we are honoured to have him. Watch out and take care![00:02:20] Professor Graham Newbig's Insights on Agents[00:02:20] Speaker: Okay hi everyone. So I was given the task of talking about agents in 2024, and this is An impossible task because there are so many agents, so many agents in 2024. So this is going to be strongly covered by like my personal experience and what I think is interesting and important, but I think it's an important topic.[00:02:41] Speaker: So let's go ahead. So the first thing I'd like to think about is let's say I gave you you know, a highly competent human, some tools. Let's say I gave you a web browser and a terminal or a file system. And the ability to [00:03:00] edit text or code. What could you do with that? Everything. Yeah.[00:03:07] Speaker: Probably a lot of things. This is like 99 percent of my, you know, daily daily life, I guess. When I'm, when I'm working. So, I think this is a pretty powerful tool set, and I am trying to do, and what I think some other people are trying to do, is come up with agents that are able to, you know, manipulate these things.[00:03:26] Speaker: Web browsing, coding, running code in successful ways. So there was a little bit about my profile. I'm a professor at CMU, chief scientist at All Hands AI, building open source coding agents. I'm maintainer of OpenHands, which is an open source coding agent framework. And I'm also a software developer and I, I like doing lots of coding and, and, you know, shipping new features and stuff like this.[00:03:51] Speaker: So building agents that help me to do this, you know, is kind of an interesting thing, very close to me.[00:03:57] Live Demo: Coding Agents in Action[00:03:57] Speaker: So the first thing I'd like to do is I'd like to try [00:04:00] some things that I haven't actually tried before. If anybody has, you know, tried to give a live demo, you know, this is, you know very, very scary whenever you do it and it might not work.[00:04:09] Speaker: So it might not work this time either. But I want to show you like three things that I typically do with coding agents in my everyday work. I use coding agents maybe five to 10 times a day to help me solve my own problems. And so this is a first one. This is a data science task. Which says I want to create scatter plots that show the increase of the SWE bench score over time.[00:04:34] Speaker: And so I, I wrote a kind of concrete prompt about this. Agents work better with like somewhat concrete prompts. And I'm gonna throw this into open hands and let it work. And I'll, I'll go back to that in a second. Another thing that I do is I create new software. And I, I've been using a [00:05:00] service a particular service.[00:05:01] Speaker: I won't name it for sending emails and I'm not very happy with it. So I want to switch over to this new service called resend. com, which makes it easier to send emails. And so I'm going to ask it to read the docs for the resend. com API and come up with a script that allows me to send emails. The input to the script should be a CSV file and the subject and body should be provided in Jinja2 templates.[00:05:24] Speaker: So I'll start another agent and and try to get it to do that for me.[00:05:35] Speaker: And let's go with the last one. The last one I do is. This is improving existing software and in order, you know, once you write software, you usually don't throw it away. You go in and, like, actually improve it iteratively. This software that I have is something I created without writing any code.[00:05:52] Speaker: It's basically software to monitor how much our our agents are contributing to the OpenHance repository. [00:06:00] And on the, let me make that a little bit bigger, on the left side, I have the number of issues where it like sent a pull request. I have the number of issues where it like sent a pull request, whether it was merged in purple, closed in red, or is still open in green. And so these are like, you know, it's helping us monitor, but one thing it doesn't tell me is the total number. And I kind of want that feature added to this software.[00:06:33] Speaker: So I'm going to try to add that too. So. I'll take this, I'll take this prompt,[00:06:46] Speaker: and here I want to open up specifically that GitHub repo. So I'll open up that repo and paste in the prompt asking it. I asked it to make a pie chart for each of these and give me the total over the entire time period that I'm [00:07:00] monitoring. So we'll do that. And so now I have let's see, I have some agents.[00:07:05] Speaker: Oh, this one already finished. Let's see. So this one already finished. You can see it finished analyzing the Swebench repository. It wrote a demonstration of, yeah, I'm trying to do that now, actually.[00:07:30] Speaker: It wrote a demonstration of how much each of the systems have improved over time. And I asked it to label the top three for each of the data sets. And so it labeled OpenHands as being the best one for SWE Bench Normal. For SWE Bench Verified, it has like the Amazon QAgent and OpenHands. For the SWE Bench Lite, it has three here over three over here.[00:07:53] Speaker: So you can see like. That's pretty useful, right? If you're a researcher, you do data analysis all the time. I did it while I was talking to all [00:08:00] of you and making a presentation. So that's, that's pretty nice. I, I doubt the other two are finished yet. That would be impressive if the, yeah. So I think they're still working.[00:08:09] Speaker: So maybe we'll get back to them at the end of the presentation. But so these are the kinds of the, these are the kinds of things that I do every day with coding agents now. And it's or software development agents. It's pretty impressive.[00:08:20] Designing Effective Agents[00:08:20] Speaker: The next thing I'd like to talk about a little bit is things I worry about when designing agents.[00:08:24] Speaker: So we're designing agents to, you know, do a very difficult task of like navigating websites writing code, other things like this. And within 2024, there's been like a huge improvement in the methodology that we use to do this. But there's a bunch of things we think about. There's a bunch of interesting papers, and I'd like to introduce a few of them.[00:08:46] Speaker: So the first thing I worry about is the agent computer interface. Like, how do we get an agent to interact with computers? And, How do we provide agents with the tools to do the job? And [00:09:00] within OpenHands we are doing the thing on the right, but there's also a lot of agents that do the thing on the left.[00:09:05] Speaker: So the thing on the left is you give like agents kind of granular tools. You give them tools like or let's say your instruction is I want to determine the most cost effective country to purchase the smartphone model, Kodak one the countries to consider are the USA, Japan, Germany, and India. And you have a bunch of available APIs.[00:09:26] Speaker: And. So what you do for some agents is you provide them all of these tools APIs as tools that they can call. And so in this particular case in order to solve this problem, you'd have to make about like 30 tool calls, right? You'd have to call lookup rates for Germany, you'd have to look it up for the US, Japan, and India.[00:09:44] Speaker: That's four tool goals. And then you go through and do all of these things separately. And the method that we adopt in OpenHands instead is we provide these tools, but we provide them by just giving a coding agent, the ability to call [00:10:00] arbitrary Python code. And. In the arbitrary Python code, it can call these tools.[00:10:05] Speaker: We expose these tools as APIs that the model can call. And what that allows us to do is instead of writing 20 tool calls, making 20 LLM calls, you write a program that runs all of these all at once, and it gets the result. And of course it can execute that program. It can, you know, make a mistake. It can get errors back and fix things.[00:10:23] Speaker: But that makes our job a lot easier. And this has been really like instrumental to our success, I think. Another part of this is what tools does the agent need? And I, I think this depends on your use case, we're kind of extreme and we're only giving the agent five tools or maybe six tools.[00:10:40] Speaker: And what, what are they? The first one is program execution. So it can execute bash programs, and it can execute Jupyter notebooks. It can execute cells in Jupyter notebooks. So that, those are two tools. Another one is a file editing tool. And the file editing tool allows you to browse parts of files.[00:11:00][00:11:00] Speaker: And kind of read them, overwrite them, other stuff like this. And then we have another global search and replace tool. So it's actually two tools for file editing. And then a final one is web browsing, web browsing. I'm kind of cheating when I call it only one tool. You actually have like scroll and text input and click and other stuff like that.[00:11:18] Speaker: But these are basically the only things we allow the agent to do. What, then the question is, like, what if we wanted to allow it to do something else? And the answer is, well, you know, human programmers already have a bunch of things that they use. They have the requests PyPy library, they have the PDF to text PyPy library, they have, like, all these other libraries in the Python ecosystem that they could use.[00:11:41] Speaker: And so if we provide a coding agent with all these libraries, it can do things like data visualization and other stuff that I just showed you. So it can also get clone repositories and, and other things like this. The agents are super good at using the GitHub API also. So they can do, you know, things on GitHub, like finding all of the, you know, [00:12:00] comments on your issues or checking GitHub actions and stuff.[00:12:02] Speaker: The second thing I think about is the human agent interface. So this is like how do we get humans to interact with agents? Bye. I already showed you one variety of our human agent interface. It's basically a chat window where you can browse through the agent's results and things like this. This is very, very difficult.[00:12:18] Speaker: I, I don't think anybody has a good answer to this, and I don't think we have a good answer to this, but the, the guiding principles that I'm trying to follow are we want to present enough info to the user. So we want to present them with, you know, what the agent is doing in the form of a kind of.[00:12:36] Speaker: English descriptions. So you can see here you can see here every time it takes an action, it says like, I will help you create a script for sending emails. When it runs a bash command. Sorry, that's a little small. When it runs a bash command, it will say ran a bash command. It won't actually show you the whole bash command or the whole Jupyter notebook because it can be really large, but you can open it up and see if you [00:13:00] want to, by clicking on this.[00:13:01] Speaker: So like if you want to explore more, you can click over to the Jupyter notebook and see what's displayed in the Jupyter notebook. And you get like lots and lots of information. So that's one thing.[00:13:16] Speaker: Another thing is go where the user is. So like if the user's already interacting in a particular setting then I'd like to, you know, integrate into that setting, but only to a point. So at OpenHands, we have a chat UI for interaction. We have a GitHub plugin for tagging and resolving issues. So basically what you do is you Do at open hands agent and the open hands agent will like see that comment and be able to go in and fix things.[00:13:42] Speaker: So if you say at open hands agent tests are failing on this PR, please fix the tests. It will go in and fix the test for you and stuff like this. Another thing we have is a remote runtime for launching headless jobs. So if you want to launch like a fleet of agents to solve, you know five different problems at once, you can also do [00:14:00] that through an API.[00:14:00] Speaker: So we have we have these interfaces and this probably depends on the use case. So like, depending if you're a coding agent, you want to do things one way. If you're a like insurance auditing agent, you'll want to do things other ways, obviously.[00:14:13] Choosing the Right Language Model for Agents[00:14:13] Speaker: Another thing I think about a lot is choosing a language model.[00:14:16] Speaker: And for agentic LMs we have to have a bunch of things work really well. The first thing is really, really good instruction following ability. And if you have really good instruction following ability, it opens up like a ton of possible applications for you. Tool use and coding ability. So if you provide tools, it needs to be able to use them well.[00:14:38] Speaker: Environment understanding. So it needs, like, if you're building a web agent, it needs to be able to understand web pages either through vision or through text. And error awareness and recovery ability. So, if it makes a mistake, it needs to be able to, you know, figure out why it made a mistake, come up with alternative strategies, and other things like this.[00:14:58] Speaker: [00:15:00] Under the hood, in all of the demos that I did now Cloud, we're using Cloud. Cloud has all of these abilities very good, not perfect, but very good. Most others don't have these abilities quite as much. So like GPT 4. 0 doesn't have very good error recovery ability. And so because of this, it will go into loops and do the same thing over and over and over again.[00:15:22] Speaker: Whereas Claude does not do this. Claude, if you, if you use the agents enough, you get used to their kind of like personality. And Claude says, Hmm, let me try a different approach a lot. So, you know, obviously it's been trained in some way to, you know, elicit this ability. We did an evaluation. This is old.[00:15:40] Speaker: And we need to update this basically, but we evaluated CLOD, mini LLAMA 405B, DeepSeq 2. 5 on being a good code agent within our framework. And CLOD was kind of head and shoulders above the rest. GPT 40 was kind of okay. The best open source model was LLAMA [00:16:00] 3. 1 405B. This needs to be updated because this is like a few months old by now and, you know, things are moving really, really fast.[00:16:05] Speaker: But I still am under the impression that Claude is the best. The other closed models are, you know, not quite as good. And then the open models are a little bit behind that. Grok, I, we haven't tried Grok at all, actually. So, it's a good question. If you want to try it I'd be happy to help.[00:16:24] Speaker: Cool.[00:16:24] Planning and Workflow for Agents[00:16:24] Speaker: Another thing is planning. And so there's a few considerations for planning. The first one is whether you have a curated plan or you have it generated on the fly. And so for solving GitHub issues, you can kind of have an overall plan. Like the plan is first reproduce. If there's an issue, first write tests to reproduce the issue or to demonstrate the issue.[00:16:50] Speaker: After that, run the tests and make sure they fail. Then go in and fix the tests. Run the tests again to make sure they pass and then you're done. So that's like a pretty good workflow [00:17:00] for like solving coding issues. And you could curate that ahead of time. Another option is to let the language model basically generate its own plan.[00:17:10] Speaker: And both of these are perfectly valid. Another one is explicit structure versus implicit structure. So let's say you generate a plan. If you have explicit structure, you could like write a multi agent system, and the multi agent system would have your reproducer agent, and then it would have your your bug your test writer agent, and your bug fixer agent, and lots of different agents, and you would explicitly write this all out in code, and then then use it that way.[00:17:38] Speaker: On the other hand, you could just provide a prompt that says, please do all of these things in order. So in OpenHands, we do very light planning. We have a single prompt. We don't have any multi agent systems. But we do provide, like, instructions about, like, what to do first, what to do next, and other things like this.[00:17:56] Speaker: I'm not against doing it the other way. But I laid [00:18:00] out some kind of justification for this in this blog called Don't Sleep on Single Agent Systems. And the basic idea behind this is if you have a really, really good instruction following agent it will follow the instructions as long as things are working according to your plan.[00:18:14] Speaker: But let's say you need to deviate from your plan, you still have the flexibility to do this. And if you do explicit structure through a multi agent system, it becomes a lot harder to do that. Like, you get stuck when things deviate from your plan. There's also some other examples, and I wanted to introduce a few papers.[00:18:30] Speaker: So one paper I liked recently is this paper called CoAct where you generate plans and then go in and fix them. And so the basic idea is like, if you need to deviate from your plan, you can You know, figure out that your plan was not working and go back and deviate from it.[00:18:49] Speaker: Another thing I think about a lot is specifying common workflows. So we're trying to tackle a software development and I already showed like three use cases where we do [00:19:00] software development and when we. We do software development, we do a ton of different things, but we do them over and over and over again.[00:19:08] Speaker: So just to give an example we fix GitHub actions when GitHub actions are failing. And we do that over and over and over again. That's not the number one thing that software engineers do, but it's a, you know, high up on the list. So how can we get a list of all of, like, the workflows that people are working on?[00:19:26] Speaker: And there's a few research works that people have done in this direction. One example is manual prompting. So there's this nice paper called STEP that got state of the art on the WebArena Web Navigation Benchmark where they came up with a bunch of manual workflows for solving different web navigation tasks.[00:19:43] Speaker: And we also have a paper recently called Agent Workflow Memory where the basic idea behind this is we want to create self improving agents that learn from their past successes. And the way it works is is we have a memory that has an example of lots of the previous [00:20:00] workflows that people have used. And every time the agent finishes a task and it self judges that it did a good job at that task, you take that task, you break it down into individual workflows included in that, and then you put it back in the prompt for the agent to work next time.[00:20:16] Speaker: And this we demonstrated that this leads to a 22. 5 percent increase on WebArena after 40 examples. So that's a pretty, you know, huge increase by kind of self learning and self improvement.[00:20:31] Speaker: Another thing is exploration. Oops. And one thing I think about is like, how can agents learn more about their environment before acting? And I work on coding and web agents, and there's, you know, a few good examples of this in, in both areas. Within coding, I view this as like repository understanding, understanding the code base that you're dealing with.[00:20:55] Speaker: And there's an example of this, or a couple examples of this, one example being AgentList. [00:21:00] Where they basically create a map of the repo and based on the map of the repo, they feed that into the agent so the agent can then navigate the repo and and better know where things are. And for web agents there's an example of a paper called Bagel, and basically what they do is they have the agent just do random tasks on a website, explore the website, better understand the structure of the website, and then after that they they feed that in as part of the product.[00:21:27] Speaker: Part seven is search. Right now in open hands, we just let the agent go on a linear search path. So it's just solving the problem once. We're using a good agent that can kind of like recover from errors and try alternative things when things are not working properly, but still we only have a linear search path.[00:21:45] Speaker: But there's also some nice work in 2024 that is about exploring multiple paths. So one example of this is there's a paper called Tree Search for Language Agents. And they basically expand multiple paths check whether the paths are going well, [00:22:00] and if they aren't going well, you rewind back. And on the web, this is kind of tricky, because, like, how do you rewind when you accidentally ordered something you don't want on Amazon?[00:22:09] Speaker: It's kind of, you know, not, not the easiest thing to do. For code, it's a little bit easier, because you can just revert any changes that you made. But I, I think that's an interesting topic, too.[00:22:21] Evaluation and Future Predictions for Agents[00:22:21] Speaker: And then finally evaluation. So within our development for evaluation, we want to do a number of things. The first one is fast sanity checks.[00:22:30] Speaker: And in order to do this, we want things we can run really fast, really really cheaply. So for web, we have something called mini world of bits, which is basically these trivial kind of web navigation things. We have something called the Adder Code Editing Benchmark, where it's just about editing individual files that we use.[00:22:48] Speaker: But we also want highly realistic evaluation. So for the web, we have something called WebArena that we created at CMU. This is web navigation on real real open source websites. So it's open source [00:23:00] websites that are actually used to serve shops or like bulletin boards or other things like this.[00:23:07] Speaker: And for code, we use Swebench, which I think a lot of people may have heard of. It's basically a coding benchmark that comes from real world pull requests on GitHub. So if you can solve those, you can also probably solve other real world pull requests. I would say we still don't have benchmarks for the fur full versatility of agents.[00:23:25] Speaker: So, for example We don't have benchmarks that test whether agents can code and do web navigation. But we're working on that and hoping to release something in the next week or two. So if that sounds interesting to you, come talk to me and I, I will tell you more about it.[00:23:42] Speaker: Cool. So I don't like making predictions, but I was told that I should be somewhat controversial, I guess, so I will, I will try to do it try to do it anyway, although maybe none of these will be very controversial. Um, the first thing is agent oriented LLMs like large language models for [00:24:00] agents.[00:24:00] Speaker: My, my prediction is every large LM trainer will be focusing on training models as agents. So every large language model will be a better agent model by mid 2025. Competition will increase, prices will go down, smaller models will become competitive as agents. So right now, actually agents are somewhat expensive to run in some cases, but I expect that that won't last six months.[00:24:23] Speaker: I, I bet we'll have much better agent models in six months. Another thing is instruction following ability, specifically in agentic contexts, will increase. And what that means is we'll have to do less manual engineering of agentic workflows and be able to do more by just prompting agents in more complex ways.[00:24:44] Speaker: Cloud is already really good at this. It's not perfect, but it's already really, really good. And I expect the other models will catch up to Cloud pretty soon. Error correction ability will increase, less getting stuck in loops. Again, this is something that Cloud's already pretty good at and I expect the others will, will follow.[00:25:00][00:25:01] Speaker: Agent benchmarks. Agent benchmarks will start saturating.[00:25:05] Speaker: And Swebench I think WebArena is already too easy. It, it is, it's not super easy, but it's already a bit too easy because the tasks we do in there are ones that take like two minutes for a human. So not, not too hard. And kind of historically in 2023 our benchmarks were too easy. So we built harder benchmarks like WebArena and Swebench were both built in 2023.[00:25:31] Future of Agent Development[00:25:31] Speaker: In 2024, our agents were too bad, so we built agents and now we're building better agents. In 2025, our benchmarks will be too easy, so we'll build better benchmarks, I'm, I'm guessing. So, I would expect to see much more challenging agent benchmarks come out, and we're already seeing some of them.[00:25:49] Speaker: In 2026, I don't know. I didn't write AGI, but we'll, we'll, we'll see.[00:25:56] Human-Agent Interaction Challenges[00:25:56] Speaker: Then the human agent computer interface. I think one thing that [00:26:00] we'll want to think about is what do we do at 75 percent success rate at things that we like actually care about? Right now we have 53 percent or 55 percent on Swebench verified, which is real world GitHub PRs.[00:26:16] Speaker: My impression is that the actual. Actual ability of models is maybe closer to 30 to 40%. So 30 to 40 percent of the things that I want an agent to solve on my own repos, it just solves without any human intervention. 80 to 90 percent it can solve without me opening an IDE. But I need to give it feedback.[00:26:36] Speaker: So how do we, how do we make that interaction smooth so that humans can audit? The work of agents that are really, really good, but not perfect is going to be a big challenge.[00:26:48] Expanding Agent Use Beyond Programming[00:26:48] Speaker: How can we expose the power of programming agents to other industries? So like as programmers, I think not all of us are using agents every day in our programming, although we probably will be [00:27:00] in in months or maybe a year.[00:27:02] Speaker: But I, I think it will come very naturally to us as programmers because we know code. We know, you know. Like how to architect software and stuff like that. So I think the question is how do we put this in the hands of like a lawyer or a chemist or somebody else and have them also be able to, you know, interact with it as naturally as we can.[00:27:25] Redesigning Systems for Agent Efficiency[00:27:25] Speaker: Another interesting thing is how can we redesign our existing systems for agents? So we had a paper on API based web agents, and basically what we showed is If you take a web agent and the agent interacts not with a website, but with APIs, the accuracy goes way up just because APIs are way easier to interact with.[00:27:42] Speaker: And in fact, like when I ask the, well, our agent, our agent is able to browse websites, but whenever I want it to interact with GitHub, I tell it do not browse the GitHub website. Use the GitHub API because it's way more successful at doing that. So maybe, you know, every website is going to need to have [00:28:00] an API because we're going to be having agents interact with them.[00:28:03] Accelerating Progress with Agent Technology[00:28:03] Speaker: About progress, I think progress will get faster. It's already fast. A lot of people are already overwhelmed, but I think it will continue. The reason why is agents are building agents. And better agents will build better agents faster. So I expect that you know, if you haven't interacted with a coding agent yet, it's pretty magical, like the stuff that it can do.[00:28:24] Speaker: So yeah.[00:28:28] Call to Action for Open Source Contributions[00:28:28] Speaker: And I have a call to action. I'm honestly, like I've been working on, you know, natural language processing and, and Language models for what, 15 years now. And even for me, it's pretty impressive what like AI agents powered by strong language models can do. On the other hand, I believe that we should really make these powerful tools accessible.[00:28:49] Speaker: And what I mean by this is I don't think like, you know, We, we should have these be opaque or limited to only a set, a certain set of people. I feel like they should be [00:29:00] affordable. They shouldn't be increasing the, you know, difference in the amount of power that people have. If anything, I'd really like them to kind of make it It's possible for people who weren't able to do things before to be able to do them well.[00:29:13] Speaker: Open source is one way to do that. That's why I'm working on open source. There are other ways to do that. You know, make things cheap, make things you know, so you can serve them to people who aren't able to afford them. Easily, like Duolingo is one example where they get all the people in the US to pay them 20 a month so that they can give all the people in South America free, you know, language education, so they can learn English and become, you know like, and become, you know, More attractive on the job market, for instance.[00:29:41] Speaker: And so I think we can all think of ways that we can do that sort of thing. And if that resonates with you, please contribute. Of course, I'd be happy if you contribute to OpenHands and use it. But another way you can do that is just use open source solutions, contribute to them, research with them, and train strong open source [00:30:00] models.[00:30:00] Speaker: So I see, you know, Some people in the room who are already training models. It'd be great if you could train models for coding agents and make them cheap. And yeah yeah, please. I, I was thinking about you among others. So yeah, that's all I have. Thanks.[00:30:20] Speaker 2: Slight, slightly controversial. Tick is probably the nicest way to say hot ticks. Any hot ticks questions, actual hot ticks?[00:30:31] Speaker: Oh, I can also show the other agents that were working, if anybody's interested, but yeah, sorry, go ahead.[00:30:36] Q&A: Agent Performance and Benchmarks[00:30:36] Speaker 3: Yeah, I have a couple of questions. So they're kind of paired, maybe. The first thing is that you said that You're estimating that your your agent is successfully resolving like something like 30 to 40 percent of your issues, but that's like below what you saw in Swebench.[00:30:52] Speaker 3: So I guess I'm wondering where that discrepancy is coming from. And then I guess my other second question, which is maybe broader in scope is that [00:31:00] like, if, if you think of an agent as like a junior developer, and I say, go do something, then I expect maybe tomorrow to get a Slack message being like, Hey, I ran into this issue.[00:31:10] Speaker 3: How can I resolve it? And, and, like you said, your agent is, like, successfully solving, like, 90 percent of issues where you give it direct feedback. So, are you thinking about how to get the agent to reach out to, like, for, for planning when it's, when it's stuck or something like that? Or, like, identify when it runs into a hole like that?[00:31:30] Speaker: Yeah, so great. These are great questions. Oh,[00:31:32] Speaker 3: sorry. The third question, which is a good, so this is the first two. And if so, are you going to add a benchmark for that second question?[00:31:40] Speaker: Okay. Great. Yeah. Great questions. Okay. So the first question was why do I think it's resolving less than 50 percent of the issues on Swebench?[00:31:48] Speaker: So first Swebench is on popular open source repos, and all of these popular open source repos were included in the training data for all of the language models. And so the language [00:32:00] models already know these repos. In some cases, the language models already know the individual issues in Swebench.[00:32:06] Speaker: So basically, like, some of the training data has leaked. And so it, it definitely will overestimate with respect to that. I don't think it's like, you know, Horribly, horribly off but I think, you know, it's boosting the accuracy by a little bit. So, maybe that's the biggest reason why. In terms of asking for help, and whether we're benchmarking asking for help yes we are.[00:32:29] Speaker: So one one thing we're working on now, which we're hoping to put out soon, is we we basically made SuperVig. Sweep edge issues. Like I'm having a, I'm having a problem with the matrix multiply. Please help. Because these are like, if anybody's run a popular open source, like framework, these are what half your issues are.[00:32:49] Speaker: You're like users show up and say like, my screen doesn't work. What, what's wrong or something. And so then you need to ask them questions and how to reproduce. So yeah, we're, we're, we're working on [00:33:00] that. I think. It, my impression is that agents are not very good at asking for help, even Claude. So like when, when they ask for help, they'll ask for help when they don't need it.[00:33:11] Speaker: And then won't ask for help when they do need it. So this is definitely like an issue, I think.[00:33:20] Speaker 4: Thanks for the great talk. I also have two questions.[00:33:23] Q&A: Web Agents and Interaction Methods[00:33:23] Speaker 4: It's first one can you talk a bit more about how the web agent interacts with So is there a VLM that looks at the web page layout and then you parse the HTML and select which buttons to click on? And if so do you think there's a future where there's like, so I work at Bing Microsoft AI.[00:33:41] Speaker 4: Do you think there's a future where the same web index, but there's an agent friendly web index where all the processing is done offline so that you don't need to spend time. Cleaning up, like, cleaning up these TML and figuring out what to click online. And any thoughts on, thoughts on that?[00:33:57] Speaker: Yeah, so great question. There's a lot of work on web [00:34:00] agents. I didn't go into, like, all of the details, but I think there's There's three main ways that agents interact with websites. The first way is the simplest way and the newest way, but it doesn't work very well, which is you take a screenshot of the website and then you click on a particular pixel value on the website.[00:34:23] Speaker: And Like models are not very good at that at the moment. Like they'll misclick. There was this thing about how like clawed computer use started like looking at pictures of Yellowstone national park or something like this. I don't know if you heard about this anecdote, but like people were like, oh, it's so human, it's looking for vacation.[00:34:40] Speaker: And it was like, no, it probably just misclicked on the wrong pixels and accidentally clicked on an ad. So like this is the simplest way. The second simplest way. You take the HTML and you basically identify elements in the HTML. You don't use any vision whatsoever. And then you say, okay, I want to click on this element.[00:34:59] Speaker: I want to enter text [00:35:00] in this element or something like that. But HTML is too huge. So it actually, it usually gets condensed down into something called an accessibility tree, which was made for screen readers for visually impaired people. And So that's another way. And then the third way is kind of a hybrid where you present the screenshot, but you also present like a textual summary of the output.[00:35:18] Speaker: And that's the one that I think will probably work best. What we're using is we're just using text at the moment. And that's just an implementation issue that we haven't implemented the. Visual stuff yet, but that's kind of like we're working on it now. Another thing that I should point out is we actually have two modalities for web browsing.[00:35:35] Speaker: Very recently we implemented this. And the reason why is because if you want to interact with full websites you will need to click on all of the elements or have the ability to click on all of the elements. But most of our work that we need websites for is just web browsing and like gathering information.[00:35:50] Speaker: So we have another modality where we convert all of it to markdown because that's like way more concise and easier for the agent to deal with. And then [00:36:00] can we create an index specifically for agents, maybe a markdown index or something like that would be, you know, would make sense. Oh, how would I make a successor to Swebench?[00:36:10] Speaker: So I mean, the first thing is there's like live code bench, which live code bench is basically continuously updating to make sure it doesn't leak into language model training data. That's easy to do for Swebench because it comes from real websites and those real websites are getting new issues all the time.[00:36:27] Speaker: So you could just do it on the same benchmarks that they have there. There's also like a pretty large number of things covering various coding tasks. So like, for example, Swebunch is mainly fixing issues, but there's also like documentation, there's generating tests that actually test the functionality that you want.[00:36:47] Speaker: And there there was a paper by a student at CMU on generating tests and stuff like that. So I feel like. Swebench is one piece of the puzzle, but you could also have like 10 different other tasks and then you could have like a composite [00:37:00] benchmark where you test all of these abilities, not just that particular one.[00:37:04] Speaker: Well, lots, lots of other things too, but[00:37:11] Speaker 2: Question from across. Use your mic, it will help. Um,[00:37:15] Speaker 5: Great talk. Thank you.[00:37:16] Q&A: Agent Architectures and Improvements[00:37:16] Speaker 5: My question is about your experience designing agent architectures. Specifically how much do you have to separate concerns in terms of tasks specific agents versus having one agent to do three or five things with a gigantic prompt with conditional paths and so on.[00:37:35] Speaker: Yeah, so that's a great question. So we have a basic coding and browsing agent. And I won't say basic, like it's a good, you know, it's a good agent, but it does coding and browsing. And it has instructions about how to do coding and browsing. That is enough for most things. Especially given a strong language model that has a lot of background knowledge about how to solve different types of tasks and how to use different APIs and stuff like that.[00:37:58] Speaker: We do have [00:38:00] a mechanism for something called micro agents. And micro agents are basically something that gets added to the prompt when a trigger is triggered. Right now it's very, very rudimentary. It's like if you detect the word GitHub anywhere, you get instructions about how to interact with GitHub, like use the API and don't browse.[00:38:17] Speaker: Also another one that I just added is for NPM, the like JavaScript package manager. And NPM, when it runs and it hits a failure, it Like hits in interactive terminals where it says, would you like to quit? Yep. Enter yes. And if that does it, it like stalls our agent for the time out until like two minutes.[00:38:36] Speaker: So like I added a new microagent whenever it started using NPM, it would Like get instructions about how to not use interactive terminal and stuff like that. So that's our current solution. Honestly, I like it a lot. It's simple. It's easy to maintain. It works really well and stuff like that. But I think there is a world where you would want something more complex than that.[00:38:55] Speaker 5: Got it. Thank you.[00:38:59] Speaker 6: I got a [00:39:00] question about MCP. I feel like this is the Anthropic Model Context Protocol. It seems like the most successful type of this, like, standardization of interactions between computers and agents. Are you guys adopting it? Is there any other competing standard?[00:39:16] Speaker 6: Anything, anything thought about it?[00:39:17] Speaker: Yeah, I think the Anth, so the Anthropic MCP is like, a way to It, it's essentially a collection of APIs that you can use to interact with different things on the internet. I, I think it's not a bad idea, but it, it's like, there's a few things that bug me a little bit about it.[00:39:40] Speaker: It's like we already have an API for GitHub, so why do we need an MCP for GitHub? Right. You know, like GitHub has an API, the GitHub API is evolving. We can look up the GitHub API documentation. So it seems like kind of duplicated a little bit. And also they have a setting where [00:40:00] it's like you have to spin up a server to serve your GitHub stuff.[00:40:04] Speaker: And you have to spin up a server to serve your like, you know, other stuff. And so I think it makes, it makes sense if you really care about like separation of concerns and security and like other things like this, but right now we haven't seen, we haven't seen that. To have a lot more value than interacting directly with the tools that are already provided.[00:40:26] Speaker: And that kind of goes into my general philosophy, which is we're already developing things for programmers. You know,[00:40:36] Speaker: how is an agent different than from a programmer? And it is different, obviously, you know, like agents are different from programmers, but they're not that different at this point. So we can kind of interact with the interfaces we create for, for programmers. Yeah. I might change my mind later though.[00:40:51] Speaker: So we'll see.[00:40:54] Speaker 7: Yeah. Hi. Thanks. Very interesting talk. You were saying that the agents you have right now [00:41:00] solve like maybe 30 percent of your, your issues out of the gate. I'm curious of the things that it doesn't do. Is there like a pattern that you observe? Like, Oh, like these are the sorts of things that it just seems to really struggle with, or is it just seemingly random?[00:41:15] Speaker: It's definitely not random. It's like, if you think it's more complex than it's. Like, just intuitively, it's more likely to fail. I've gotten a bit better at prompting also, so like, just to give an example it, it will sometimes fail to fix a GitHub workflow because it will not look at the GitHub workflow and understand what the GitHub workflow is doing before it solves the problem.[00:41:43] Speaker: So I, I think actually probably the biggest thing that it fails at is, um, er, that our, our agent plus Claude fails at is insufficient information gathering before trying to solve the task. And so if you provide all, if you provide instructions that it should do information [00:42:00] gathering beforehand, it tends to do well.[00:42:01] Speaker: If you don't provide sufficient instructions, it will try to solve the task without, like, fully understanding the task first, and then fail, and then you need to go back and give feedback. You know, additional feedback. Another example, like, I, I love this example. While I was developing the the monitor website that I, I showed here, we hit a really tricky bug where it was writing out a cache file to a different directory than it was reading the cache file from.[00:42:26] Speaker: And I had no idea what to do. I had no idea what was going on. I, I thought the bug was in a different part of the code, but what I asked it to do was come up with five possible reasons why this could be failing and decreasing order of likelihood and examine all of them. And that worked and it could just go in and like do that.[00:42:44] Speaker: So like I think a certain level of like scaffolding about like how it should sufficiently Gather all the information that's necessary in order to solve a task is like, if that's missing, then that's probably the biggest failure point at the moment. [00:43:00][00:43:01] Speaker 7: Thanks.[00:43:01] Speaker 6: Yeah.[00:43:06] Speaker 6: I'm just, I'm just using this as a chance to ask you all my questions.[00:43:09] Q&A: Self-Improving Agents and Authentication[00:43:09] Speaker 6: You had a, you had a slide on here about like self improving agents or something like that with memory. It's like a really throwaway slide for like a super powerful idea. It got me thinking about how I would do it. I have no idea how.[00:43:21] Speaker 6: So I just wanted you to chain a thought more on this.[00:43:25] Speaker: Yeah, self, self improving. So I think the biggest reason, like the simplest possible way to create a self improving agent. The problem with that is to have a really, really strong language model that with infinite context, and it can just go back and look at like all of its past experiences and, you know, learn from them.[00:43:46] Speaker: You might also want to remove the bad stuff just so it doesn't over index on it's like failed past experiences. But the problem is a really powerful language model is large. Infinite context is expensive. We don't have a good way to [00:44:00] index into it because like rag, Okay. At least in my experience, RAG from language to code doesn't work super well.[00:44:08] Speaker: So I think in the end, it's like, that's the way I would like to solve this problem. I'd like to have an infinite context and somehow be able to index into it appropriately. And I think that would mostly solve it. Another thing you can do is fine tuning. So I think like RAG is one way to get information into your model.[00:44:23] Speaker: Fine tuning is another way to get information into your model. So. That might be another way of continuously improving. Like you identify when you did a good job and then just add all of the good examples into your model.[00:44:34] Speaker 6: Yeah. So, you know, how like Voyager tries to write code into a skill library and then you reuse as a skill library, right?[00:44:40] Speaker 6: So that it improves in the sense that it just builds up the skill library over time.[00:44:44] Speaker: Yep.[00:44:44] Speaker 6: One thing I was like thinking about and there's this idea of, from, from Devin, your, your arch nemesis of playbooks. I don't know if you've seen them.[00:44:52] Speaker: Yeah, I mean, we're calling them workflows, but they're simpler.[00:44:55] Speaker 6: Yeah, so like, basically, like, you should, like, once a workflow works, you can kind of, [00:45:00] like, persist them as a skill library. Yeah. Right? Like I, I feel like that there's a, that's like some in between, like you said, you know, it's hard to do rag between language and code, but I feel like that is ragged for, like, I've done this before, last time I did it, this, this worked.[00:45:14] Speaker 6: So I'm just going to shortcut. All the stuff that failed before.[00:45:18] Speaker: Yeah, I totally, I think it's possible. It's just, you know, not, not trivial at the same time. I'll explain the two curves. So basically, the base, the baseline is just an agent that does it from scratch every time. And this curve up here is agent workflow memory where it's like adding the successful experiences back into the prompt.[00:45:39] Speaker: Why is this improving? The reason why is because just it failed on the first few examples and for the average to catch up it, it took a little bit of time. So it's not like this is actually improving it. You could just basically view the this one is constant and then this one is like improving.[00:45:56] Speaker: Like this, basically you can see it's continuing to go [00:46:00] up.[00:46:01] Speaker 8: How do you think we're going to solve the authentication problem for agents right now?[00:46:05] Speaker: When you say authentication, you mean like credentials, like, yeah.[00:46:09] Speaker 8: Yeah. Cause I've seen a few like startup solutions today, but it seems like it's limited to the amount of like websites or actual like authentication methods that it's capable of performing today.[00:46:19] Speaker: Yeah. Great questions. So. My preferred solution to this at the moment is GitHub like fine grained authentication tokens and GitHub fine grained authentication tokens allow you to specify like very free. On a very granular basis on this repo, you have permission to do this, on this repo, you have permission to do this.[00:46:41] Speaker: You also can prevent people from pushing to the main branch unless they get approved. You can do all of these other things. And I think these were all developed for human developers. Or like, the branch protection rules were developed for human developers. The fine grained authentication tokens were developed for GitHub apps.[00:46:56] Speaker: I think for GitHub, maybe [00:47:00] just pushing this like a little bit more is the way to do this. For other things, they're totally not prepared to give that sort of fine grained control. Like most APIs don't have something like a fine grained authentication token. And that goes into my like comment that we're going to need to prepare the world for agents, I think.[00:47:17] Speaker: But I think like the GitHub authentication tokens are like a good template for how you could start doing that maybe, but yeah, I don't, I don't, I don't have an answer.[00:47:25] Speaker 8: I'll let you know if I find one.[00:47:26] Speaker: Okay. Yeah.[00:47:31] Live Demonstration and Closing Remarks[00:47:31] Speaker: I'm going to finish up. Let, let me just see.[00:47:37] Speaker: Okay. So this one this one did write a script. I'm not going to actually read it for you. And then the other one, let's see.[00:47:51] Speaker: Yeah. So it sent a PR, sorry. What is, what is the PR URL?[00:48:00][00:48:02] Speaker: So I don't, I don't know if this sorry, that's taking way longer than it should. Okay, cool. Yeah. So this one sent a PR. I'll, I'll tell you later if this actually like successfully Oh, no, it's deployed on Vercel, so I can actually show you, but let's, let me try this real quick. Sorry. I know I don't have time.[00:48:24] Speaker: Yeah, there you go. I have pie charts now. So it's so fun. It's so fun to play with these things. Cause you could just do that while I'm giving a, you know, talk and things like that. So, yeah, thanks. Get full access to Latent.Space at www.latent.space/subscribe
-
 2024 in Synthetic Data and Smol Models [LS Live @ NeurIPS]
2024 in Synthetic Data and Smol Models [LS Live @ NeurIPS]From 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2024-12-24 20:13
Happy holidays! We’ll be sharing snippets from Latent Space LIVE! through the break bringing you the best of 2024! We want to express our deepest appreciation to event sponsors AWS, Daylight Computer, Thoth.ai, StrongCompute, Notable Capital, and most of all all our LS supporters who helped fund the gorgeous venue and A/V production!For NeurIPS last year we did our standard conference podcast coverage interviewing selected papers (that we have now also done for ICLR and ICML), however we felt that we could be doing more to help AI Engineers 1) get more industry-relevant content, and 2) recap 2024 year in review from experts. As a result, we organized the first Latent Space LIVE!, our first in person miniconference, at NeurIPS 2024 in Vancouver. Today, we’re proud to share Loubna’s highly anticipated talk (slides here)!Synthetic DataWe called out the Synthetic Data debate at last year’s NeurIPS, and no surprise that 2024 was dominated by the rise of synthetic data everywhere:* Apple’s Rephrasing the Web, Microsoft’s Phi 2-4 and Orca/AgentInstruct, Tencent’s Billion Persona dataset, DCLM, and HuggingFace’s FineWeb-Edu, and Loubna’s own Cosmopedia extended the ideas of synthetic textbook and agent generation to improve raw web scrape dataset quality* This year we also talked to the IDEFICS/OBELICS team at HuggingFace who released WebSight this year, the first work on code-vs-images synthetic data.* We called Llama 3.1 the Synthetic Data Model for its extensive use (and documentation!) of synthetic data in its pipeline, as well as its permissive license. * Nemotron CC and Nemotron-4-340B also made a big splash this year for how they used 20k items of human data to synthesize over 98% of the data used for SFT/PFT.* Cohere introduced Multilingual Arbitrage: Optimizing Data Pools to Accelerate Multilingual Progress observing gains of up to 56.5% improvement in win rates comparing multiple teachers vs the single best teacher model* In post training, AI2’s Tülu3 (discussed by Luca in our Open Models talk) and Loubna’s Smol Talk were also notable open releases this year.This comes in the face of a lot of scrutiny and criticism, with Scale AI as one of the leading voices publishing AI models collapse when trained on recursively generated data in Nature magazine bringing mainstream concerns to the potential downsides of poor quality syndata:Part of the concerns we highlighted last year on low-background tokens are coming to bear: ChatGPT contaminated data is spiking in every possible metric:But perhaps, if Sakana’s AI Scientist pans out this year, we will have mostly-AI AI researchers publishing AI research anyway so do we really care as long as the ideas can be verified to be correct?Smol ModelsMeta surprised many folks this year by not just aggressively updating Llama 3 and adding multimodality, but also adding a new series of “small” 1B and 3B “on device” models this year, even working on quantized numerics collaborations with Qualcomm, Mediatek, and Arm. It is near unbelievable that a 1B model today can qualitatively match a 13B model of last year:and the minimum size to hit a given MMLU bar has come down roughly 10x in the last year. We have been tracking this proxied by Lmsys Elo and inference price:The key reads this year are:* MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases* Apple Intelligence Foundation Language Models* Hymba: A Hybrid-head Architecture for Small Language Models* Loubna’s SmolLM and SmolLM2: a family of state-of-the-art small models with 135M, 360M, and 1.7B parameters on the pareto efficiency frontier.* and Moondream, which we already covered in the 2024 in Vision talkFull Talk on YouTubeplease like and subscribe!Timestamps* [00:00:05] Loubna Intro* [00:00:33] The Rise of Synthetic Data Everywhere* [00:02:57] Model Collapse* [00:05:14] Phi, FineWeb, Cosmopedia - Synthetic Textbooks* [00:12:36] DCLM, Nemotron-CC* [00:13:28] Post Training - AI2 Tulu, Smol Talk, Cohere Multilingual Arbitrage* [00:16:17] Smol Models* [00:18:24] On Device Models* [00:22:45] Smol Vision Models* [00:25:14] What's NextTranscript2024 in Synthetic Data and Smol Models[00:00:00] [00:00:05] Loubna Intro[00:00:05] Speaker: I'm very happy to be here. Thank you for the invitation. So I'm going to be talking about synthetic data in 2024. And then I'm going to be talking about small on device models. So I think the most interesting thing about synthetic data this year is that like now we have it everywhere in the large language models pipeline.[00:00:33] The Rise of Synthetic Data Everywhere[00:00:33] Speaker: I think initially, synthetic data was mainly used just for post training, because naturally that's the part where we needed human annotators. And then after that, we realized that we don't really have good benchmarks to [00:01:00] measure if models follow instructions well, if they are creative enough, or if they are chatty enough, so we also started using LLMs as judges.[00:01:08] Speaker: Thank you. And I think this year and towards the end of last year, we also went to the pre training parts and we started generating synthetic data for pre training to kind of replace some parts of the web. And the motivation behind that is that you have a lot of control over synthetic data. You can control your prompt and basically also the kind of data that you generate.[00:01:28] Speaker: So instead of just trying to filter the web, you could try to get the LLM to generate what you think the best web pages could look like and then train your models on that. So this is how we went from not having synthetic data at all in the LLM pipeline to having it everywhere. And so the cool thing is like today you can train an LLM with like an entirely synthetic pipeline.[00:01:49] Speaker: For example, you can use our Cosmopedia datasets and you can train a 1B model on like 150 billion tokens that are 100 percent synthetic. And those are also of good quality. And then you can [00:02:00] instruction tune the model on a synthetic SFT dataset. You can also do DPO on a synthetic dataset. And then to evaluate if the model is good, you can use.[00:02:07] Speaker: A benchmark that uses LLMs as a judge, for example, MTBench or AlpacaEvil. So I think this is like a really mind blowing because like just a few years ago, we wouldn't think this is possible. And I think there's a lot of concerns about model collapse, and I'm going to talk about that later. But we'll see that like, if we use synthetic data properly and we curate it carefully, that shouldn't happen.[00:02:29] Speaker: And the reason synthetic data is very popular right now is that we have really strong models, both open and closed. It is really cheap and fast to use compared to human annotations, which cost a lot and take a lot of time. And also for open models right now, we have some really good inference frameworks.[00:02:47] Speaker: So if you have enough GPUs, it's really easy to spawn these GPUs and generate like a lot of synthetic data. Some examples are VLM, TGI, and TensorRT.[00:02:57] Model Collapse[00:02:57] Speaker: Now let's talk about the elephant in the room, model [00:03:00] collapse. Is this the end? If you look at the media and all of like, for example, some papers in nature, it's really scary because there's a lot of synthetic data out there in the web.[00:03:09] Speaker: And naturally we train on the web. So we're going to be training a lot of synthetic data. And if model collapse is going to happen, we should really try to take that seriously. And the other issue is that, as I said, we think, a lot of people think the web is polluted because there's a lot of synthetic data.[00:03:24] Speaker: And for example, when we're building fine web datasets here at Guillerm and Hinek, we're interested in like, how much synthetic data is there in the web? So there isn't really a method to properly measure the amount of synthetic data or to save a webpage synthetic or not. But one thing we can do is to try to look for like proxy words, for example, expressions like as a large language model or words like delve that we know are actually generated by chat GPT.[00:03:49] Speaker: We could try to measure the amount of these words in our data system and compare them to the previous years. For example, here, we measured like a, these words ratio in different dumps of common crawl. [00:04:00] And we can see that like the ratio really increased after chat GPT's release. So if we were to say that synthetic data amount didn't change, you would expect this ratio to stay constant, which is not the case.[00:04:11] Speaker: So there's a lot of synthetic data probably on the web, but does this really make models worse? So what we did is we trained different models on these different dumps. And we then computed their performance on popular, like, NLP benchmarks, and then we computed the aggregated score. And surprisingly, you can see that the latest DOMs are actually even better than the DOMs that are before.[00:04:31] Speaker: So if there's some synthetic data there, at least it did not make the model's worse. Yeah, which is really encouraging. So personally, I wouldn't say the web is positive with Synthetic Data. Maybe it's even making it more rich. And the issue with like model collapse is that, for example, those studies, they were done at like a small scale, and you would ask the model to complete, for example, a Wikipedia paragraph, and then you would train it on these new generations, and you would do that every day.[00:04:56] Speaker: iteratively. I think if you do that approach, it's normal to [00:05:00] observe this kind of behavior because the quality is going to be worse because the model is already small. And then if you train it just on its generations, you shouldn't expect it to become better. But what we're really doing here is that we take a model that is very large and we try to distill its knowledge into a model that is smaller.[00:05:14] Phi, FineWeb, Cosmopedia - Synthetic Textbooks[00:05:14] Speaker: And in this way, you can expect to get like a better performance for your small model. And using synthetic data for pre-training has become really popular. After the textbooks are all you need papers where Microsoft basically trained a series of small models on textbooks that were using a large LLM.[00:05:32] Speaker: And then they found that these models were actually better than models that are much larger. So this was really interesting. It was like first of its time, but it was also met with a lot of skepticism, which is a good thing in research. It pushes you to question things because the dataset that they trained on was not public, so people were not really sure if these models are really good or maybe there's just some data contamination.[00:05:55] Speaker: So it was really hard to check if you just have the weights of the models. [00:06:00] And as Hugging Face, because we like open source, we tried to reproduce what they did. So this is our Cosmopedia dataset. We basically tried to follow a similar approach to what they documented in the paper. And we created a synthetic dataset of textbooks and blog posts and stories that had almost 30 billion tokens.[00:06:16] Speaker: And we tried to train some models on that. And we found that like the key ingredient to getting a good data set that is synthetic is trying as much as possible to keep it diverse. Because if you just throw the same prompts as your model, like generate like a textbook about linear algebra, and even if you change the temperature, the textbooks are going to look alike.[00:06:35] Speaker: So there's no way you could scale to like millions of samples. And the way you do that is by creating prompts that have some seeds that make them diverse. In our case, the prompt, we would ask the model to generate a textbook, but make it related to an extract from a webpage. And also we try to frame it within, to stay within topic.[00:06:55] Speaker: For example, here, we put like an extract about cardiovascular bioimaging, [00:07:00] and then we ask the model to generate a textbook related to medicine that is also related to this webpage. And this is a really nice approach because there's so many webpages out there. So you can. Be sure that your generation is not going to be diverse when you change the seed example.[00:07:16] Speaker: One thing that's challenging with this is that you want the seed samples to be related to your topics. So we use like a search tool to try to go all of fine web datasets. And then we also do a lot of experiments with the type of generations we want the model to generate. For example, we ask it for textbooks for middle school students or textbook for college.[00:07:40] Speaker: And we found that like some generation styles help on some specific benchmarks, while others help on other benchmarks. For example, college textbooks are really good for MMLU, while middle school textbooks are good for benchmarks like OpenBookQA and Pico. This is like a sample from like our search tool.[00:07:56] Speaker: For example, you have a top category, which is a topic, and then you have some [00:08:00] subtopics, and then you have the topic hits, which are basically the web pages in fine web does belong to these topics. And here you can see the comparison between Cosmopedia. We had two versions V1 and V2 in blue and red, and you can see the comparison to fine web, and as you can see throughout the training training on Cosmopedia was consistently better.[00:08:20] Speaker: So we managed to get a data set that was actually good to train these models on. It's of course so much smaller than FineWeb, it's only 30 billion tokens, but that's the scale that Microsoft data sets was, so we kind of managed to reproduce a bit what they did. And the data set is public, so everyone can go there, check if everything is all right.[00:08:38] Speaker: And now this is a recent paper from NVIDIA, Neumatron CC. They took things a bit further, and they generated not a few billion tokens, but 1. 9 trillion tokens, which is huge. And we can see later how they did that. It's more of, like, rephrasing the web. So we can see today that there's, like, some really huge synthetic datasets out there, and they're public, so, [00:09:00] like, you can try to filter them even further if you want to get, like, more high quality corpses.[00:09:04] Speaker: So for this, rephrasing the web this approach was suggested in this paper by Pratyush, where basically in this paper, they take some samples from C4 datasets, and then they use an LLM to rewrite these samples into a better format. For example, they ask an LLM to rewrite the sample into a Wikipedia passage or into a Q& A page.[00:09:25] Speaker: And the interesting thing in this approach is that you can use a model that is Small because it doesn't, rewriting doesn't require knowledge. It's just rewriting a page into a different style. So the model doesn't need to have like knowledge that is like extensive of what is rewriting compared to just asking a model to generate a new textbook and not giving it like ground truth.[00:09:45] Speaker: So here they rewrite some samples from C4 into Q& A, into Wikipedia, and they find that doing this works better than training just on C4. And so what they did in Nemo Trans CC is a similar approach. [00:10:00] They rewrite some pages from Common Crawl for two reasons. One is to, like improve Pages that are low quality, so they rewrite them into, for example, Wikipedia page, so they look better.[00:10:11] Speaker: And another reason is to create more diverse datasets. So they have a dataset that they already heavily filtered, and then they take these pages that are already high quality, and they ask the model to rewrite them in Question and Answer format. into like open ended questions or like multi choice questions.[00:10:27] Speaker: So this way they can reuse the same page multiple times without fearing like having multiple duplicates, because it's the same information, but it's going to be written differently. So I think that's also a really interesting approach for like generating synthetic data just by rephrasing the pages that you already have.[00:10:44] Speaker: There's also this approach called Prox where they try to start from a web page and then they generate a program which finds how to write that page to make it better and less noisy. For example, here you can see that there's some leftover metadata in the web page and you don't necessarily want to keep that for training [00:11:00] your model.[00:11:00] Speaker: So So they train a model that can generate programs that can like normalize and remove lines that are extra. So I think this approach is also interesting, but it's maybe less scalable than the approaches that I presented before. So that was it for like rephrasing and generating new textbooks.[00:11:17] Speaker: Another approach that I think is really good and becoming really popular for using synthetic data for pre training is basically building a better classifiers. For filtering the web for example, here we release the data sets called fine web edu. And the way we built it is by taking Llama3 and asking it to rate the educational content of web pages from zero to five.[00:11:39] Speaker: So for example, if a page is like a really good textbook that could be useful in a school setting, it would get a really high score. And if a page is just like an advertisement or promotional material, it would get a lower score. And then after that, we take these synthetic annotations and we train a classifier on them.[00:11:57] Speaker: It's a classifier like a BERT model. [00:12:00] And then we run this classifier on all of FineWeb, which is a 15 trillion tokens dataset. And then we only keep the pages that have like a score that's higher than 3. So for example, in our case, we went from 15 trillion tokens to 3. to just 1. 5 trillion tokens. Those are really highly educational.[00:12:16] Speaker: And as you can see here, a fine web EDU outperforms all the other public web datasets by a larger margin on a couple of benchmarks here, I show the aggregated score and you can see that this approach is really effective for filtering web datasets to get like better corpuses for training your LLMs.[00:12:36] DCLM, Nemotron-CC[00:12:36] Speaker: Others also try to do this approach. There's, for example, the DCLM datasets where they also train the classifier, but not to detect educational content. Instead, they trained it on OpenHermes dataset, which is a dataset for instruction tuning. And also they explain like IAM5 subreddits, and then they also get really high quality dataset which is like very information dense and can help [00:13:00] you train some really good LLMs.[00:13:01] Speaker: And then Nemotron Common Crawl, they also did this approach, but instead of using one classifier, they used an ensemble of classifiers. So they used, for example, the DCLM classifier, and also classifiers like the ones we used in FineWebEducational, and then they combined these two. Scores into a, with an ensemble method to only retain the best high quality pages, and they get a data set that works even better than the ones we develop.[00:13:25] Speaker: So that was it for like synthetic data for pre-training.[00:13:28] Post Training - AI2 Tulu, Smol Talk, Cohere Multilingual Arbitrage[00:13:28] Speaker: Now we can go back to post training. I think there's a lot of interesting post training data sets out there. One that was released recently, the agent instructs by Microsoft where they basically try to target some specific skills. And improve the performance of models on them.[00:13:43] Speaker: For example, here, you can see code, brain teasers, open domain QA, and they managed to get a dataset that outperforms that's when fine tuning Mistral 7b on it, it outperforms the original instruct model that was released by Mistral. And as I said, to get good synthetic data, you really [00:14:00] have to have a framework to make sure that your data is diverse.[00:14:03] Speaker: So for example, for them, they always. And then they see the generations on either source code or raw text documents, and then they rewrite them to make sure they're easier to generate instructions from, and then they use that for their like instruction data generation. There's also the Tool3SFT mixture, which was released recently by Allen AI.[00:14:23] Speaker: It's also really good quality and it covers a wide range of tasks. And the way they make sure that this dataset is diverse is by using personas from the persona hub datasets. Which is basically a data set of like I think over a million personas. And for example, in the tool mixture to generate like a new code snippet, they would give like the model persona, for example, a machine learning researcher interested in neural networks, and then ask it to generate like a coding problem.[00:14:49] Speaker: This way you make sure that your data set is really diverse, and then you can further filter the data sets, for example, using the reward models. We also released a dataset called Smalltalk, [00:15:00] and we also tried to cover the wide range of tasks, and as you can see here, for example, when fine tuning Mistral 7b on the dataset, we also outperformed the original Mistral instructs on a number of benchmarks, notably on mathematics and instruction following with ifevil.[00:15:18] Speaker: Another paper that's really interesting I wanted to mention is this one called Multilingual Data Arbitrage by Cohere. And basically they want to generate a data set for post training that is multilingual. And they have a really interesting problem. It's the fact that there isn't like one model that's really good at all the languages they wanted.[00:15:36] Speaker: So what they do is that like they use not just one teacher model, but multiple teachers. And then they have a router which basically sends the prompts they have to all these models. And then they get the completions and they have a reward model that traces all these generations and only keeps the best one.[00:15:52] Speaker: And this is like arbitrage and finance. So well, I think what's interesting in this, it shows that like synthetic data, it doesn't have to come from a single model. [00:16:00] And because we have so many good models now, you could like pull these models together and get like a dataset that's really high quality and that's diverse and that's covers all your needs.[00:16:12] Speaker: I was supposed to put a meme there, but. Yeah, so that was it for like a synthetic data.[00:16:17] Smol Models[00:16:17] Speaker: Now we can go to see what's happening in the small models field in 2024. I don't know if you know, but like now we have some really good small models. For example, Lama 3. 2 1B is. It matches Lama 2. 13b from, that was released last year on the LMSYS arena, which is basically the default go to leaderboard for evaluating models using human evaluation.[00:16:39] Speaker: And as you can see here, the scores of the models are really close. So I think we've made like hugely forward in terms of small models. Of course, that's one, just one data point, but there's more. For example, if you look at this chart from the Quint 2. 5 blog post, it shows that today we have some really good models that are only like 3 billion parameters [00:17:00] and 4 billion that score really high on MMLU.[00:17:03] Speaker: Which is a really popular benchmark for evaluating models. And you can see here that the red, the blue dots have more than 65 on MMLU. And the grey ones have less. And for example, Llama33b had less. So now we have a 3b model that outperforms a 33b model that was released earlier. So I think now people are starting to realize that like, we shouldn't just scale and scale models, but we should try to make them more efficient.[00:17:33] Speaker: I don't know if you knew, but you can also chat with a 3B plus model on your iPhone. For example, here, this is an app called PocketPal, where you can go and select a model from Hugging Face. It has a large choice. For example, here we loaded the 5. 3. 5, which is 3. 8 billion parameters on this iPhone. And we can chat with this and you can see that even the latency is also acceptable.[00:17:57] Speaker: For example, here, I asked it to give me a joke about [00:18:00] NeurIPS. So let's see what it has to say.[00:18:06] Speaker: Okay, why did the neural network attend NeurIPS? Because it heard there would be a lot of layers and fun and it wanted to train its sense of humor. So not very funny, but at least it can run on device. Yeah, so I think now we have good small models, but we also have like good frameworks and tools to use these small models.[00:18:24] On Device Models[00:18:24] Speaker: So I think we're really close to having like really on edge and on device models that are really good. And I think for a while we've had this narrative. But just training larger models is better. Of course, this is supported by science scaling laws. As you can see here, for example, when we scale the model size, the loss is lower and obviously you get a better model.[00:18:46] Speaker: But and we can see this, for example, in the GPT family of models, how we went from just a hundred million parameters to more than a trillion. parameters. And of course, we all observed the performance improvement when using the latest model. But [00:19:00] one thing that we shouldn't forget is that when we scale the model, we also scale the inference costs and time.[00:19:05] Speaker: And so the largest models were are going to cost so much more. So I think now instead of just building larger models, we should be focusing on building more efficient models. It's no longer a race for the largest models since these models are really expensive to run and they require like a really good infrastructure to do that and they cannot run on, for example, consumer hardware.[00:19:27] Speaker: And when you try to build more efficient models that match larger models, that's when you can really unlock some really interesting on device use cases. And I think a trend that we're noticing now is the trend of training smaller models longer. For example, if you compare how much, how long LLAMA was trained compared to LLAMA3, there is a huge increase in the pre training length.[00:19:50] Speaker: LLAMA was trained on 1 trillion tokens, but LLAMA3 8b was trained on 15 trillion tokens. So Meta managed to get a model that's the same size, but But it performs so much [00:20:00] better by choosing to like spend the sacrifice during training, because as we know, training is a one time cost, but inference is something that's ongoing.[00:20:08] Speaker: If we want to see what are like the small models reads in 2024, I think this mobile LLM paper by Meta is interesting. They try to study different models that are like have the less than 1 billion parameters and find which architecture makes most sense for these models. For example, they find that depth is more important than width.[00:20:29] Speaker: So it's more important to have models that have like more layers than just one. making them more wide. They also find that GQA helps, that tying the embedding helps. So I think it's a nice study overall for models that are just a few hundred million parameters. There's also the Apple intelligence tech report, which is interesting.[00:20:48] Speaker: So for Apple intelligence, they had two models, one that was like on server and another model that was on device. It had 3 billion parameters. And I think the interesting part is that they trained this model using [00:21:00] pruning. And then distillation. And for example, they have this table where they show that, like, using pruning and distillation works much better than training from scratch.[00:21:08] Speaker: And they also have some interesting insights about, like, how they specialize their models on specific tasks, like, for example, summarization and rewriting. There's also this paper by NVIDIA that was released recently. I think you've already had a talk about, like, hybrid models that was all interesting.[00:21:23] Speaker: And this model, they used, like, a hybrid architecture between state space models and transformers. And they managed to train a 1B model that's really performant without needing to train it on a lot of tokens. And regarding our work, we just recently released SmallM2, so it's a series of three models, which are the best in class in each model size.[00:21:46] Speaker: For example, our 1. 7b model outperforms Lama 1b and also Qt 2. 5. And how we managed to train this model is the following. That's where you spent a lot of time trying to curate the pre training datasets. We did a lot of [00:22:00] ablations, trying to find which datasets are good and also how to mix them. We also created some new math and code datasets that we're releasing soon.[00:22:08] Speaker: But you basically really spent a lot of time trying to find what's the best mixture that you can train these models on. And then we spent some time trying to like we also trained these models for very long. For example, small M1 was trained only on 1 trillion tokens, but this model is trained on 11 trillion tokens.[00:22:24] Speaker: And we saw that the performance kept improving. The models didn't really plateau mid training, which I think is really interesting. It shows that you can train such small models for very long and keep getting performance gains. What's interesting about SmallLM2 is that it's fully open. We also released, like the pre training code base, the fine tuning code, the datasets, and also evaluation in this repository.[00:22:45] Smol Vision Models[00:22:45] Speaker: Also there's, like, really interesting small models for text, but also for vision. For example, here you can see SmallVLM, which is a 2B model that's really efficient. It doesn't consume a lot of RAM, and it also has a good performance. There's also Moondream 0. [00:23:00] 5b, which was released recently. It's like the smallest visual language model.[00:23:04] Speaker: And as you can see, there isn't like a big trade off compared to Moondream 2b. So now I showed you that we have some really good small models. We also have the tools to use them, but why should you consider using small models and when? I think, like, small models are really interesting because of the on device feature.[00:23:23] Speaker: Because these models are small and they can run fast, you can basically run them on your laptop, but also on your mobile phone. And this means that your dataset stays locally. You don't have to send your queries to third parties. And this really enhances privacy. That was, for example, one of the big selling points for Apple Intelligence.[00:23:42] Speaker: Also, right now, we really have a lot of work to do. So many frameworks to do on device inference. For example, there's MLX, MLC, Llama, CPP, Transformers, JS. So we have a lot of options and each of them have like great features. So you have so many options for doing that. Small models are also really powerful if you choose to specialize them.[00:24:00][00:24:00] Speaker: For example, here there's a startup called Numind, which took small LM and then they fine tuned it on text extraction datasets. And they managed to get a model that's not very far from models that are much larger. So I think text extraction is like one use case where small models can be really performant and it makes sense to use them instead of just using larger models.[00:24:19] Speaker: You can also chat with these models in browser. For example, here, you can go there, you can load the model, you can even turn off your internet and just start chatting with the model locally. Speaking of text extraction, if you don't want to fine tune the models, there's a really good method of structure generation.[00:24:36] Speaker: We can basically force the models to follow a JSON schema that you defined. For example, here, we try to force the model to follow a schema for extracting key information from GitHub issues. So you can input free text, which is a complaint about a GitHub repository, something not working. And then you can run it there and the model can extract anything that is relevant for your GitHub issue creation.[00:24:58] Speaker: For example, the [00:25:00] priority, for example, here, priority is high, the type of the issue bug, and then a title and the estimation of how long this will take to fix. And you can just like do this in the browser, you can transform your text into a GitHub issue that's properly formatted.[00:25:14] What's Next[00:25:14] Speaker: So what's next for synthetic data and small models?[00:25:18] Speaker: I think that domain specific synthetic data is going to be, it's already important, it's going to be even more important. For example, generating synthetic data for math. I think this really would help improve the reasoning of a lot of models. And a lot of people are doing it, for example, Quint 2. 12 math, everyone's trying to reproduce a one.[00:25:37] Speaker: And so I think for synthetic data, trying to specialize it on some domains is going to be really important. And then for small models, I think specializing them through fine tuning, it's also going to be really important because I think a lot of companies are just trying to use these large models because they are better.[00:25:53] Speaker: But on some tasks, I think you can already get decent performance with small models. So you don't need to Pay like a [00:26:00] cost that's much larger just to make your model better at your task by a few percent. And this is not just for text. And I think it also applies for other modalities like vision and audio.[00:26:11] Speaker: And I think you should also watch out for on device frameworks and applications. For example, like the app I showed, or lama, all these frameworks are becoming really popular and I'm pretty sure that we're gonna get like more of them in 2025. And users really like that. Maybe for other, I should also say hot take.[00:26:28] Speaker: I think that like in AI, we just started like with fine tuning, for example, trying to make BERT work on some specific use cases, and really struggling to do that. And then we had some models that are much larger. So we just switched to like prompt engineering to get the models And I think we're going back to fine tuning where we realize these models are really costly.[00:26:47] Speaker: It's better to use just a small model or try to specialize it. So I think it's a little bit of a cycle and we're going to start to see like more fine tuning and less of just like a prompt engineering the models. So that was my talk. Thank you for following. And if you have [00:27:00] any questions, we can take them now. Get full access to Latent.Space at www.latent.space/subscribe
-
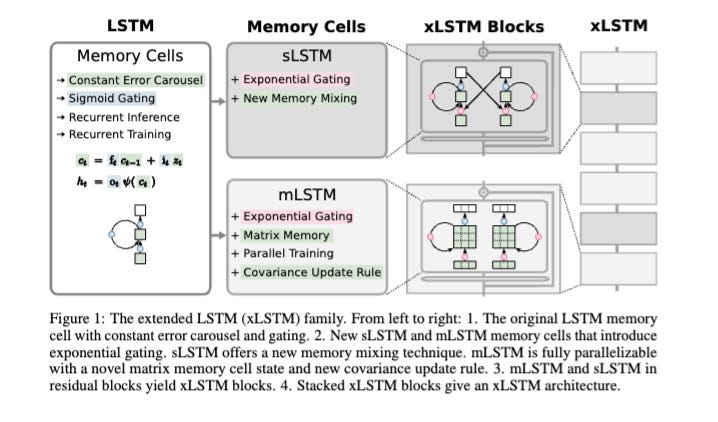 2024 in Post-Transformers Architectures (State Space Models, RWKV) [LS Live @ NeurIPS]
2024 in Post-Transformers Architectures (State Space Models, RWKV) [LS Live @ NeurIPS]From 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2024-12-24 02:43
Happy holidays! We’ll be sharing snippets from Latent Space LIVE! through the break bringing you the best of 2024! We want to express our deepest appreciation to event sponsors AWS, Daylight Computer, Thoth.ai, StrongCompute, Notable Capital, and most of all all our LS supporters who helped fund the gorgeous venue and A/V production!Update: see followup discussion on HN and also the YouTube discussion.For NeurIPS last year we did our standard conference podcast coverage interviewing selected papers (that we have now also done for ICLR and ICML), however we felt that we could be doing more to help AI Engineers 1) get more industry-relevant content, and 2) recap 2024 year in review from experts. As a result, we organized the first Latent Space LIVE!, our first in person miniconference, at NeurIPS 2024 in Vancouver.Of perennial interest, particularly at academic conferences, is scaled-up architecture research as people hunt for the next Attention Is All You Need. We have many names for them: “efficient models”, “retentive networks”, “subquadratic attention” or “linear attention” but some of them don’t even have any lineage with attention - one of the best papers of this NeurIPS was Sepp Hochreiter’s xLSTM, which has a particularly poetic significance as one of the creators of the LSTM returning to update and challenge the OG language model architecture:So, for lack of a better term, we decided to call this segment “the State of Post-Transformers” and fortunately everyone rolled with it.We are fortunate to have two powerful friends of the pod to give us an update here:* Together AI: with CEO Vipul Ved Prakash and CTO Ce Zhang joining us to talk about how they are building Together together as a quote unquote full stack AI startup, from the lowest level kernel and systems programming to the highest level mathematical abstractions driving new model architectures and inference algorithms, with notable industry contributions from RedPajama v2, Flash Attention 3, Mamba 2, Mixture of Agents, BASED, Sequoia, Evo, Dragonfly, Dan Fu's ThunderKittens and many more research projects this year* Recursal AI: with CEO Eugene Cheah who has helped lead the independent RWKV project while also running Featherless AI. This year, the team has shipped RWKV v5, codenamed Eagle, to 1.5 billion Windows 10 and Windows 11 machines worldwide, to support Microsoft's on-device, energy-usage-sensitive Windows Copilot usecases, and has launched the first updates on RWKV v6, codenamed Finch and GoldFinch. On the morning of Latent Space Live, they also announced QRWKV6, a Qwen 32B model modified with RWKV linear attention layers. We were looking to host a debate between our speakers, but given that both of them were working on post-transformers alternativesFull Talk on YoutubePlease like and subscribe!LinksAll the models and papers they picked:* Earlier Cited Work* Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention* Hungry hungry hippos: Towards language modeling with state space models* Hyena hierarchy: Towards larger convolutional language models* Mamba: Linear-Time Sequence Modeling with Selective State Spaces* S4: Efficiently Modeling Long Sequences with Structured State Spaces* Just Read Twice (Arora et al)* Recurrent large language models that compete with Transformers in language modeling perplexity are emerging at a rapid rate (e.g., Mamba, RWKV). Excitingly, these architectures use a constant amount of memory during inference. However, due to the limited memory, recurrent LMs cannot recall and use all the information in long contexts leading to brittle in-context learning (ICL) quality. A key challenge for efficient LMs is selecting what information to store versus discard. In this work, we observe the order in which information is shown to the LM impacts the selection difficulty. * To formalize this, we show that the hardness of information recall reduces to the hardness of a problem called set disjointness (SD), a quintessential problem in communication complexity that requires a streaming algorithm (e.g., recurrent model) to decide whether inputted sets are disjoint. We empirically and theoretically show that the recurrent memory required to solve SD changes with set order, i.e., whether the smaller set appears first in-context. * Our analysis suggests, to mitigate the reliance on data order, we can put information in the right order in-context or process prompts non-causally. Towards that end, we propose: (1) JRT-Prompt, where context gets repeated multiple times in the prompt, effectively showing the model all data orders. This gives 11.0±1.3 points of improvement, averaged across 16 recurrent LMs and the 6 ICL tasks, with 11.9× higher throughput than FlashAttention-2 for generation prefill (length 32k, batch size 16, NVidia H100). We then propose (2) JRT-RNN, which uses non-causal prefix-linear-attention to process prompts and provides 99% of Transformer quality at 360M params., 30B tokens and 96% at 1.3B params., 50B tokens on average across the tasks, with 19.2× higher throughput for prefill than FA2.* Jamba: A 52B Hybrid Transformer-Mamba Language Model* We present Jamba, a new base large language model based on a novel hybrid Transformer-Mamba mixture-of-experts (MoE) architecture. * Specifically, Jamba interleaves blocks of Transformer and Mamba layers, enjoying the benefits of both model families. MoE is added in some of these layers to increase model capacity while keeping active parameter usage manageable. * This flexible architecture allows resource- and objective-specific configurations. In the particular configuration we have implemented, we end up with a powerful model that fits in a single 80GB GPU.* Built at large scale, Jamba provides high throughput and small memory footprint compared to vanilla Transformers, and at the same time state-of-the-art performance on standard language model benchmarks and long-context evaluations. Remarkably, the model presents strong results for up to 256K tokens context length. * We study various architectural decisions, such as how to combine Transformer and Mamba layers, and how to mix experts, and show that some of them are crucial in large scale modeling. We also describe several interesting properties of these architectures which the training and evaluation of Jamba have revealed, and plan to release checkpoints from various ablation runs, to encourage further exploration of this novel architecture. We make the weights of our implementation of Jamba publicly available under a permissive license.* SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers* We introduce Sana, a text-to-image framework that can efficiently generate images up to 4096×4096 resolution. Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop GPU. Core designs include: * (1) Deep compression autoencoder: unlike traditional AEs, which compress images only 8×, we trained an AE that can compress images 32×, effectively reducing the number of latent tokens. * (2) Linear DiT: we replace all vanilla attention in DiT with linear attention, which is more efficient at high resolutions without sacrificing quality. * (3) Decoder-only text encoder: we replaced T5 with modern decoder-only small LLM as the text encoder and designed complex human instruction with in-context learning to enhance the image-text alignment. * (4) Efficient training and sampling: we propose Flow-DPM-Solver to reduce sampling steps, with efficient caption labeling and selection to accelerate convergence. * As a result, Sana-0.6B is very competitive with modern giant diffusion model (e.g. Flux-12B), being 20 times smaller and 100+ times faster in measured throughput. Moreover, Sana-0.6B can be deployed on a 16GB laptop GPU, taking less than 1 second to generate a 1024×1024 resolution image. Sana enables content creation at low cost. * RWKV: Reinventing RNNs for the Transformer Era* Transformers have revolutionized almost all natural language processing (NLP) tasks but suffer from memory and computational complexity that scales quadratically with sequence length. In contrast, recurrent neural networks (RNNs) exhibit linear scaling in memory and computational requirements but struggle to match the same performance as Transformers due to limitations in parallelization and scalability. * We propose a novel model architecture, Receptance Weighted Key Value (RWKV), that combines the efficient parallelizable training of transformers with the efficient inference of RNNs.* Our approach leverages a linear attention mechanism and allows us to formulate the model as either a Transformer or an RNN, thus parallelizing computations during training and maintains constant computational and memory complexity during inference. * We scale our models as large as 14 billion parameters, by far the largest dense RNN ever trained, and find RWKV performs on par with similarly sized Transformers, suggesting future work can leverage this architecture to create more efficient models. This work presents a significant step towards reconciling trade-offs between computational efficiency and model performance in sequence processing tasks.* LoLCATs: On Low-Rank Linearizing of Large Language Models* Recent works show we can linearize large language models (LLMs) -- swapping the quadratic attentions of popular Transformer-based LLMs with subquadratic analogs, such as linear attention -- avoiding the expensive pretraining costs. However, linearizing LLMs often significantly degrades model quality, still requires training over billions of tokens, and remains limited to smaller 1.3B to 7B LLMs. * We thus propose Low-rank Linear Conversion via Attention Transfer (LoLCATs), a simple two-step method that improves LLM linearizing quality with orders of magnitudes less memory and compute. * We base these steps on two findings. * First, we can replace an LLM's softmax attentions with closely-approximating linear attentions, simply by training the linear attentions to match their softmax counterparts with an output MSE loss ("attention transfer").* Then, this enables adjusting for approximation errors and recovering LLM quality simply with low-rank adaptation (LoRA). * LoLCATs significantly improves linearizing quality, training efficiency, and scalability. We significantly reduce the linearizing quality gap and produce state-of-the-art subquadratic LLMs from Llama 3 8B and Mistral 7B v0.1, leading to 20+ points of improvement on 5-shot MMLU. * Furthermore, LoLCATs does so with only 0.2% of past methods' model parameters and 0.4% of their training tokens. * Finally, we apply LoLCATs to create the first linearized 70B and 405B LLMs (50x larger than prior work). * When compared with prior approaches under the same compute budgets, LoLCATs significantly improves linearizing quality, closing the gap between linearized and original Llama 3.1 70B and 405B LLMs by 77.8% and 78.1% on 5-shot MMLU.Timestamps* [00:02:27] Intros* [00:03:16] Why Scale Context Lengths? or work on Efficient Models* [00:06:07] The Story of SSMs* [00:09:33] Idea 1: Approximation -> Principled Modeling* [00:12:14] Idea 3: Selection* [00:15:07] Just Read Twice* [00:16:51] Idea 4: Test Time Compute* [00:17:32] Idea 2: Hardware & Kernel Support* [00:19:49] RWKV vs SSMs* [00:24:24] RWKV Arch* [00:26:15] QWRKWv6 launch* [00:30:00] What's next* [00:33:21] Hot Takes - does anyone really need long context?Transcript[00:00:00] AI Charlie: We're back at Latent Space Live, our first mini conference held at NeurIPS 2024 in Vancouver. This is Charlie, your AI co host. As a special treat this week, we're recapping the best of 2024 going domain by domain. We sent out a survey to the over 900 of you who told us what you wanted, and then invited the best speakers in the Latent Space Network to cover each field.[00:00:24] AI Charlie: 200 of you joined us in person throughout the day, with over 2200 watching live online. Thanks Our next keynote covers the State of Transformers alternative architectures, with a special joint presentation with Dan Fu of Together AI and Eugene Chia of Recursal AI and Featherless AI. We've featured both Together and Recursal on the pod before, with CEO Veepal Vedprakash introducing them.[00:00:49] AI Charlie: And CTO CE Zhang joining us to talk about how they are building together together as a quote unquote full stack AI startup from the lowest level kernel and systems [00:01:00] programming to the highest level mathematical abstractions driving new model architectures and inference algorithms with notable industry contributions from Red Pajama V2, Flash Attention 3, Mamba 2, Mixture of Agents.[00:01:15] AI Charlie: Based, Sequoia, Evo, Dragonfly, Danfoo's Thunder Kittens, and many more research projects this year. As for Recursal and Featherless, we were the first podcast to feature RWKV last year, and this year the team has shipped RWKV v5, codenamed Eagle, to 1. 5 billion Windows 10 and Windows 11 machines worldwide to support Microsoft's on device, end Energy Usage Sensitive Windows Copilot Use Cases and has launched the first updates on RWKV v6, codenamed Finch and Goldfinch.[00:01:53] AI Charlie: On the morning of Latent Space Live, they also announced QRdata UKv6, a QEN32B model [00:02:00] modified with RDWKV linear attention layers. Eugene has also written the most single most popular guest post on the Latent Space blog this year. Yes, we do take guest posts on what he has discovered about the H100 GPU inference NeoCloud market since the successful launch of Featherless AI this year.[00:02:20] AI Charlie: As always, don't forget to check the show notes for the YouTube link to their talk as well as their slides. Watch out and take care.[00:02:27] Intros[00:02:27] Dan Fu: Yeah, so thanks so much for having us. So this is going to be a little bit of a two part presentation. My name is Dan. I'm at Together AI, and I'll be joining UCSD as faculty in about a year. And Eugene, you want to introduce yourself?[00:02:46] Eugene Cheah: Eugene, I lead the art activity team, and I, I'm CEO of Featherless, and we both work on this new post transformer architecture space.[00:02:55] Dan Fu: Yeah, so yeah, so today we're really excited to talk to you a little bit [00:03:00] about that. So first I'm going to give a broad overview of kind of the last few years of progress in non post transformer architectures. And then afterwards Eugene will tell us a little bit about the latest and the greatest and the latest frontier models in this space.[00:03:16] Why Scale Context Lengths? or work on Efficient Models[00:03:16] Dan Fu: So, the story starts with Scaling. So this is probably a figure or something like this that you've seen very recently. Over the last five to six years, we've seen models really scale up in parameter size, and that's brought with it a bunch of new capabilities, like the ability to talk to you and tell you sometimes how to use your Colab screens.[00:03:35] Dan Fu: But another place where we've seen scaling especially recently is scaling in context length. So this can mean Having more text inputs for your models, but it can also mean things like taking a lot of visual token inputs image inputs to your models or generating lots of outputs. And one thing that's been really exciting over the last few months or so is that we're, we're seeing scaling, not only during training time, but also [00:04:00] during test time.[00:04:00] Dan Fu: So this is one of the, the, this is the iconic image from the OpenAI 01 release. Not only are we starting to scale train time compute, but we're also starting to scale test time compute. Now if you're familiar with our attention and our transformer architectures today, this graph on the right might look a little bit scary.[00:04:19] Dan Fu: And one of the reasons is that the implications are a little bit Interesting. So what does it mean if we want to continue having smarter and smarter models? Do we just need to start building bigger, bigger data centers, spending more flops? Is this this little Dolly 3, we need more flops, guys? Is this going to be the future of all of AI?[00:04:39] Dan Fu: Or is there a better way, another path forward? Maybe we can get the same capabilities that we've gotten used to, But for a lot less compute, a lot less flops. And one of the things that we're going to talk about today is specifically looking at that core attention operator in some of these models.[00:04:57] Dan Fu: And the reason is that so this is just some, some [00:05:00] basic you know, scaling curves, but attention has compute that scales quadratically in the context length. So that means that if you're doing something like test time compute and you want to spend a bunch of tokens thinking about what comes next, the longer that that goes the, the, the more tokens you spend on that, that compute grows quadratically in that.[00:05:19] Dan Fu: One of the questions that we're interested in is, can we take that basic sequence model, that basic sequence primitive at the bottom, and get it to scale better? Can we scale in, let's say, n to the 3 halves or n log n? So in, in the first part of the talk, so we just went over the introduction. What I'm gonna do over the next few slides is just talk about some of the key advances and ideas that have shown over the past few years since maybe early 2020 to, to now that shown promise that this might actually be possible.[00:05:48] Dan Fu: That you can actually get potentially the same quality that we want while scale, while scaling better. So to do that, we're and, and basically the, the story that we're gonna look is we're gonna start to see [00:06:00] how. So this is a basic graph of just the past couple years of progress of perplexity where that blue line, that dotted blue line, is attention.[00:06:07] The Story of SSMs[00:06:07] Dan Fu: It's your basic transformer, full dense attention. And then the dots coming down are some of the methods that you'll see in this presentation today. We're going to turn the clock back all the way to 2020. So this, this, this question of can we make attention subquadratic? Basically, as soon as we said attention is all you need, People started asking this question.[00:06:28] Dan Fu: So we have this quadratic attention operator. Can we do better? I'll briefly talk about why attention is quadratic. And the basic thing that happens, if you're not familiar, is that you have these inputs, these keys and queries. And what you do in this attention matrix, this S matrix over here, is that you're using, you're comparing every token in your input to every other token.[00:06:49] Dan Fu: So when I try to do something like upload a whole book to Gemini, what happens beyond the Maybe not Gemini, because we don't necessarily know what architecture is. But let's say we upload it to LLAMA, what happens beyond [00:07:00] the scenes, behind the scenes, is that it's going to take every single word in that book and compare it to every other word.[00:07:05] Dan Fu: And this has been a really, it's, it's led to some pretty impressive things. But it's kind of a brute forcing of the way that you would try to interpret a interpret something. And what attention does in particular is the, and then what attention, sorry, don't want to. Okay, no, no laser pointer. What, what attention does afterwards is that instead of always operating in this quadratic thing, it takes a row wise softmax over this matrix, and then multiplies it by this values matrix.[00:07:32] Dan Fu: So, one of the key points to notice is that the output size is always going to be the same as the inputs, at least in standard self attention. So one of the first things that folks tried to do around 2020 is this thing called linear attention, which is just, just noticing that if we take out this softmax from here, if we take out this non linearity in the middle of the attention operation, and then if you compute the keys and the values operation first, you actually never hit this quadratic bottleneck.[00:07:57] Dan Fu: So that, that's potentially a way [00:08:00] to get a lot more computationally efficient. And there are various ways to do this by basically using feature maps or try to approximate this overall attention computation. But some of this work sort of started to hit a wall in 2020. And the basic challenges were, were two.[00:08:16] Dan Fu: So one was quality. It was back then, it was kind of hard to, to get good quality with these linear attention operators. The other one was actually hardware efficiency. So these, this feature map that was just shown by a simplify simplify here. Actually ends up being quite computationally expensive if you just implement it naively.[00:08:34] Dan Fu: So you started having these operators that not only were you sure, you're not really sure if they have the same quality, but also they're actually just wall clock slower. So you kind of end up getting the worst of both worlds. So this was the the stage. So that kind of sets the stage for four years ago.[00:08:49] Dan Fu: Keep this in mind because linear attention is actually going to come back in a few years once we have a better understanding. But one of the works that started kicking off this, this [00:09:00] mini revolution in post transformer architectures was this idea called states based model. So here the seminal work is, is one about our work queue in 2022.[00:09:09] Dan Fu: And this, this piece of work really brought together a few ideas from, from some long running research research lines of work. The first one was, and this is really one of the keys to, to closing the gap in quality was just using things that, that if you talk to a, a, an electrical engineer off the street, they might know off, off the, like the back of their hand.[00:09:33] Idea 1: Approximation -> Principled Modeling[00:09:33] Dan Fu: But taking some of those properties with how we model dynamical systems in signal processing and then using those ideas to model the inputs, the, the text tokens in, for example a transformer like Next Token Prediction Architecture. So some of those early states-based model papers were looking at this relatively, relatively simple recurrent update model that comes from maybe chapter one of a signal processing class.[00:09:59] Dan Fu: But then using [00:10:00] some principle theory about how you should do that recurrent update in order to really get the most that you can out of your hidden state, out of your out of your sequence. So that, that was one key idea for quality and. When this was eventually realized, you started to see a bunch of benchmarks that were pretty sticky for a few years.[00:10:20] Dan Fu: Things like long range arena, some long sequence evaluation benchmarks, There was stuff in time series, time series analysis. They started to, you started to see the quality tick up in meaningful ways. But the other key thing that What's so influential about these states based models is that they also had a key idea about how you can compute these things efficiently.[00:10:45] Dan Fu: So if you go back to your machine learning 101 class where you learned about RNNs, one thing that you may have learned is that they don't paralyze as well as detention, because if you just run them naively, you have to do this kind of sequential update to process new tokens, [00:11:00] whereas in attention, you can process all the tokens in parallel at one time.[00:11:04] Dan Fu: One of the key insights behind the S4 paper was that these recurrent models, you could take them and you could also formulate them as a convolution. And in particular, with a convolution, you could, instead of using a PyTorch conv1d operation, you can compute that with the FFT. And that would give you n log n compute in the in the sequence length n with an operator that was relatively well optimized for modern hardware.[00:11:28] Dan Fu: So those are really, I'd say, the two key ideas in 2022 that started allowing these breakthroughs to happen in these non transformer architectures. So, these ideas about how to principally model sorry, how to model the recurrent updates of a mo of, of a sequence in a principled way, and also these key ideas in how you can compute it efficiently by turning it into a convolution and then scaling it up with the FFT.[00:11:53] Dan Fu: Along those same lines, so afterwards we started putting out some work on specialized kernels, so just [00:12:00] like we have flash attention for transformers, we also have works like flash fft conf, and if you look at these lines of work oftentimes when, whenever you see a new architecture, you see a new primitive one of the, one of the table stakes now is, do you have an efficient kernel so that you can actually get wall clock speed up?[00:12:14] Idea 3: Selection[00:12:14] Dan Fu: So by 2022, We are starting to have these models that had promising quality primitives, but and, and also promising wall clocks. So you could actually see regimes where they were better than transformers in meaningful ways. That being said, there were, there's still sometimes a quality gap, particularly for language modeling.[00:12:33] Dan Fu: And because languages, It's so core to what we do in sequence modeling these days the, the next, the next key idea that I'm going to talk about is this idea of selection mechanisms. And this is basically an idea of, so you have this recurrent state that you're keeping around that just summarizes everything that, that came before.[00:12:50] Dan Fu: And to get a good sequence model, one of the things that you really need to be able to do is have the model learn what's the best way to pick out pieces from that recurrent [00:13:00] state. So one of the, one of the major ideas here in a line of work called H3, Hungry Hungry Hippos, and also these hyena models were One way you can do this is by just adding some simple element wise gates.[00:13:13] Dan Fu: So versions of these ideas have been around for decades. If you squint at the LSTM paper you, you can probably find, find this gating mechanism. But turns out you can take those old ideas, add them into these new. state space models, and then you can see quality start to pick up. If you've heard of the Mamba model, this also takes the selection to the next level by actually making some changes in that fundamental recurrent state space.[00:13:40] Dan Fu: So, it's not only just this gating that happens around the SSM layer, but also you can actually make The ABCD matrices of your state space model, you can make them data dependent, which will allow you to even better select out different pieces from your hidden state depending on what you're seeing. I'll also point out if you look at the [00:14:00] bottom right of this figure, there's this little triangle with a GPU SRAM, GPU HBM, and this, this is just continuing that trend of when you have a new architecture you, you, you also release it with a kernel to, to, to show that it is hardware efficient, that it, that it can be hardware efficient on modern hardware.[00:14:17] Dan Fu: The, the, one of the next cool things that happened is once we had this understanding of these are the basic pieces, these are the basic principles behind some of the sequence models linear attention actually started to come back. So in earlier this year, there was a model called BASED the, from Simran Arora and, and some other folks, that combined a more principled version of linear attention that basically the, the, the, the two second summary is that it used a Taylor approximation of the softmax attention, combined that with a simple sliding window attention and was starting to able, starting to be able to expand the Pareto frontier of how much data can you recall from your sequence, versus how small is your recurrent state size.[00:14:58] Dan Fu: So those orange dots [00:15:00] are, at the top there, are just showing smaller sequences that can recall more memory.[00:15:07] Just Read Twice[00:15:07] Dan Fu: And the last major idea I think that has been influential in this line of work and is very relatively late breaking just a few months ago, is just the basic idea that when you have these models that are fundamentally more efficient in the sequence length, you maybe don't want to prompt them or use them in exactly the same way.[00:15:26] Dan Fu: So this was a really cool paper called Just Read Twice, also from Simran. That basically said, hey, all these efficient models can process tokens so much more efficiently than transformers that they can sometimes have unfair advantages compared to a simple transformer token. So, or sorry, a simple transformer model.[00:15:44] Dan Fu: So take, for example the standard, the standard use case of you have some long document, you're going to pass it in as input, and then you're going to ask some question about it. One problem you might imagine for a recurrent model where you have a fixed state size is, let's say that [00:16:00] you're. Article is very long, and you're trying to ask about some really niche thing.[00:16:04] Dan Fu: You can imagine it might be hard for the model to know ahead of time what information to put into the hidden state. But these, these, these models are so much more efficient that you can do something really stupid, like, you can just put the document write down the document, write down the question, write down the document again, and then write down the question again, and then this time, the second time that you go over that document, you know exactly what to look for.[00:16:25] Dan Fu: And the cool thing about this is, so this is, And this this results in better quality, especially on these recall intensive tasks. But the other interesting thing is it really takes advantage of the more efficient architectures that, that we're having here. So one of the other, I think, influential ideas in this line of work is if you change the fundamental compute capabilities of your model and the way that it scales, you can actually start to query it at test time differently.[00:16:51] Idea 4: Test Time Compute[00:16:51] Dan Fu: And this actually, of course, goes back to those slides on test time compute. So while everybody's looking at, say, test time compute for big transformer models, [00:17:00] I think potentially a really interesting research question is, how can you take those and how does it change with this new next generation of models?[00:17:09] Dan Fu: So the, I'll just briefly summarize what some of those key ideas were and then talk and then show you briefly kind of what the state of the art is today. So, so the four key ideas are instead of just doing a simple linear attention approximation, instead take ideas that we know from other fields like signal processing, do a more principled approach to your modeling of the sequence.[00:17:32] Idea 2: Hardware & Kernel Support[00:17:32] Dan Fu: Another key idea throughout all these lines of work is you really want. Hardware and kernel support from day one. So, so even if your model is theoretically more efficient if somebody goes and runs it and it's two times slower one of the things that, that we've learned is that if, if you're in that situation, it's, it's just gonna be dead on arrival.[00:17:49] Dan Fu: So you want to be designing your architectures one of the key, key machine learning ideas that has been important for the quality is just making sure that you encode different ways that you can [00:18:00] select from your hidden state and, and really focus on that as a key decider of quality. And finally, I think one of the, the, the emerging new, new things for, for this line of work and something that's quite interesting is, What are the right test time paradigms for these models?[00:18:15] Dan Fu: How do they change relative to relative to what you might do for a standard transformer? I'll briefly end this section. So I've labeled this slide where we are yesterday because Eugene is going to talk about some new models that he released literally this morning. But as of yesterday, some of the really cool results out of the, these efficient alternative models were so AI2 trained this hybrid MOE called Jamba.[00:18:40] Dan Fu: That, that, that seems, that is currently the state of the art for these non transformer architectures. There's this NVIDIA and MIT put out this new diffusion model called SANA recently that one of their key key observations is that you can take a standard diffusion transformer diffusion model, replace the layers with linear [00:19:00] attention, and then that lets you scale to much larger much larger images, much, much Much larger sequences more efficiently.[00:19:07] Dan Fu: And and one thing that I don't think anybody would have called when a few years ago is that one of those gated SSM, gated states based models ended up on the cover of Science because a great group of folks went and trained some DNA models. So that's Michael Polley, Eric Yuen from from Stanford and the Arc Institute.[00:19:26] Dan Fu: So it's, we're really at an exciting time in 2024 where these non transformer, post transformer architectures are showing promise across a wide range. Across a wide range of, of modalities, of applications, and, and of tasks. And with that, I'll pass it on to Eugene, who can tell you a little bit about the latest and greatest with RWKV.[00:19:49] RWKV vs SSMs[00:19:49] Eugene Cheah: So, that's useful? Yeah. You're talking to here. Oh, I'm talking to here. Okay. So, yeah, two streams. Yeah. So, I think one common questions that we tend to get asked, right, is what's the difference between [00:20:00] RWKV and state space? So I think one of the key things to really understand, right the difference between the two groups, right, is that we are actually more like an open source, random internet meets academia kind of situation.[00:20:11] Eugene Cheah: Like, most of us never wrote any paper, but we, we basically look at RNNs and linear intention when intention is all you need came out, and then we decided to like, hey there is a quadratic scaling problem. Why don't we try fixing that instead? So, so, so we end up developing our own branch, but we end up sharing ideas back and forth.[00:20:30] Eugene Cheah: So, and, and we do all this actively in Discord, GitHub, etc. This was so bad for a few years, right, that basically, the average group's H index was so close to zero, right, Illuter. ai actually came in and helped us write our first paper. Great, now our H index is now three, apparently. So, so, so, but, but the thing is, like, a lot of these experiments led to results, and, and, essentially, essentially, we we took the same ideas from linear attention, [00:21:00] and we built on it.[00:21:01] Eugene Cheah: So, to take a step back into, like, how does RWKB handle its own attention mechanic and achieve the same goals of, like, O and compute, respectively, and in focus of our overall goal to make AI accessible to everyone, regardless of language, nation, or compute, that's our goal. We actually train our models primarily on over a hundred languages, which is another topic altogether.[00:21:23] Eugene Cheah: And our goal is to train to even 200 languages to cover all languages in the world. But at the same time, we work on this architecture, To lower the compute cost so that people can run it on Raspberry Pis and on anything. So, how did RWKB break the dependency of LSTM token flow? Because I think to understand architecture, right, it's probably easier to understand it from the RNN lens.[00:21:46] Eugene Cheah: Because that's where we built on. We all, we all state space kind of like try to, try to start anew and took lessons from that and say, So there's a little bit of divergence there. And AKA, this our version of linear attention. So to take step back [00:22:00] all foundation models, be it transformers or non transformers at a very high level, right?[00:22:05] Eugene Cheah: Pumps in the token. I mean, text that things into embeddings and go through a lot of layers. Generate a lot of states where the QKV cache or be iron in states or RW KB states. And outputs and embedding, they are not the same thing. And we just take more layers and more embeddings. And somehow that magically works.[00:22:23] Eugene Cheah: So, if you, if you remember your ancient RNN lessons which we, which we, which we we call best learning these days the general idea is that you have the embedding information flowing all the way up, and when, and you take that information and you flow it back down, and then you process it as part of your LSTM layers.[00:22:41] Eugene Cheah: So, this is how it generally works. Kapati is quoted saying that RNNs are actually unreasonably effective. The problem is this is not scalable. To start doing work on the second token, you need to wait for the first token. And then you need to, and likewise for the third token and fourth token, yada yada.[00:22:55] Eugene Cheah: That is CPU land, not GPU land. So, so, so, you [00:23:00] can have a H100 and you can't even use 1 percent of it. So, so that's kind of why RNNs didn't really take off in the direction that we wanted, like, billions of parameters when it comes to training. So, what did RDAP KV version 0 do? Boom. We just did the dumbest, lamest thing.[00:23:13] Eugene Cheah: Sorry, this is the bottleneck for RNN. We did the dumb thing of removing that line. And it kind of worked. It trained. It sucked, but it kind of worked. Then we were like, hey, then no one cared because the loss was crap, but how do we improve that? And that's essentially where we move forward, because if you see this kind of flow, right, you can actually get your GPU saturated quickly, where it essentially cascades respectively.[00:23:41] Eugene Cheah: So I'm just waiting for this to loop again. So it's like, once you get your first layer, your token to be computed finish. You start to cascade your compute all the way until you are, Hey, I'm using 100 percent of the GPU. So we, we worked on it, and we started going along the principle of that as long as we keep this general architecture [00:24:00] where, where we can cascade and, and be highly efficient with our architecture, nothing is sacred in our architecture.[00:24:06] Eugene Cheah: And we have done some crazy ideas. In fact, you ask us, if you ask me to explain some things in the paper, right, officially in the paper, I'll say we had this idea and we wrote it this way. The reality is someone came with a code, we tested it, it worked, and then we rationalized later. So, so the general[00:24:24] RWKV Arch[00:24:24] Eugene Cheah: The idea behind rwkbr is that we generally have two major blocks that we do.[00:24:30] Eugene Cheah: We call time mix and channel mix. And time mix generally handles handles long term memory states, where essentially, where essentially where we apply the matrix multiplication and Cilu activation functions into processing an input embedding and an output embedding. I'm oversimplifying it because this, This calculation changed every version and we have, like, version 7 right now.[00:24:50] Eugene Cheah: ChannelMix is similar to Base in the sense that it does shorter term attention, where it just looks at the sister token, or the token before it, because [00:25:00] there's a shift in the token shift matrix. I don't really want to go too much into the papers itself, because, like, we do have three papers on this.[00:25:09] Eugene Cheah: Basically, RWKB, RNN for the transformer, ERA, Ego and Pinch, RWKB, Matrix Value State. This is the updated version 5, version 6. And Goldfinch is our, is, is, is, is our hybrid model respectively. We are writing the paper already for V seven and which is, which is for R wk V seven. Called, named Goose, or architectures are named by Bird.[00:25:30] Eugene Cheah: And, I'm going to cover as well, qrwkb, and mama100k, and rwkb, and Where did that lead to? Great! Because we are all GPU poor and to be clear, like, most of this research is done, like, only on a handful H100s, which I had one Google researcher told me that was, like, his experiment budget for a single researcher.[00:25:48] Eugene Cheah: So, our entire organization has less compute than a single researcher in Google. So We, we, one of the things that we explored into was to how do we convert transformer models instead? Because [00:26:00] someone already paid that billion dollars, a million dollars onto training, so why don't we take advantage of those weights?[00:26:05] Eugene Cheah: And, and to, I believe, together AI worked on the lockets for, for the Lambda side of things, and, and we took some ideas from there as well, and we essentially did that for RWKB.[00:26:15] QWRKWv6 launch[00:26:15] Eugene Cheah: And that led to, Q RWKB6, which we just dropped today, a 32 bit instruct preview model, where we took the Quen 32 bit instruct model, freeze the feedforward layer, remove the QKB attention layer, and replace it with RWKB linear layers.[00:26:32] Eugene Cheah: So to be clear, this means we do not have the rwkv channel mix layer, we only have the time mix layer. But but once we do that, we train the rwkv layer. Important is that the feedforward layer needs to be frozen, so the new attention can be learned. And then we unfreeze the feedforward layer, and train all the layers together with a custom learning rate schedule, so that they can learn how to work together.[00:26:54] Eugene Cheah: The end result, surprisingly, And, to be honest, to the frustration of the R. W. [00:27:00] KV MOE team, which ended up releasing the model on the same day, was that, with just a few hours of training on two nodes, we managed to get it to be on par, kind of, with the original QUAN32B model. So, in fact, when the first run, right, that completely confused us, it was like, and I was telling Daniel Goldstein, Smirky, who kind of leads most of our research coordination, When you pitched me this idea, you told me at best you'll get the same level of performance.[00:27:26] Eugene Cheah: You didn't tell me the challenge and score and Winograd score will shoot up. I don't know what's happening there. But it did. MMLU score dropping, that was expected. Because if you think about it, when we were training all the layers, right, we were essentially Like, Frankenstein this thing, and we did brain damage to the feedforward network layer 2 with the new RWKB layers.[00:27:47] Eugene Cheah: But, 76%, hey, somehow it's retained, and we can probably further train this. We didn't even spend more than 3 days training this, so there's a lot more that can be done, hence the preview. This brings up [00:28:00] a big question, because We are already now in the process of converting to 7TB. We are now, this is actually extremely compute efficient to test our attention mechanic.[00:28:10] Eugene Cheah: It's like, it becomes a shortcut. We can, we are already planning to do our version 7 and our hybrid architecture for it. Because we don't need to train from scratch. And we get a really good model out of it. And the other thing that is uncomfortable to say is that because we are doing right now on the 70b is that if this scales correctly to 128k context length, I'm not even talking about a million 128, majority of enterprise workload today is just on 70b at under 32k context length.[00:28:41] Eugene Cheah: That means if this works and the benchmark matches it, It means we can replace the vast majority of current AI workload, unless you want super long context. And then sorry, can someone give us more GPUs? Because we do need the VRAM for super long context, sadly. So yeah, that's what we are working on, and essentially, [00:29:00] we are excited about this to just push it further.[00:29:02] Eugene Cheah: And this conversion process, to be clear, I don't think it's going to be exclusive to RWKB. It probably will work for Mamba as well, I don't see why not. And we will probably see more ideas, or more experiments, or more hybrids, or Yeah, like, one of the weirdest things that I wanted to say outright, and I confirmed this with the Black Mamba team and the Jamba team, which because we did the GoFinch hybrid model, is that none of us understand why a hard hybrid with a state based model to be R.[00:29:28] Eugene Cheah: QA state space and transformer performs better when, than the baseline of both. It's like, it's like when you train one, you expect, and then you replace, you expect the same results. That's our pitch. That's our claim. But somehow when we jam both together, it outperforms both. And that's like one area of emulation that, like, we only have four experiments, plus four teams, that a lot more needs to be done.[00:29:51] Eugene Cheah: But, but these are things that excite me, essentially, because that is what it's potentially we can move ahead for. Which brings us to what comes next.[00:30:00] What's next[00:30:00] [00:30:00][00:30:00] Dan Fu: So, this part is kind of just some, where we'll talk a little bit about stuff that, that we're excited about. Maybe have some wild speculation on, on what, what's, what's coming next.[00:30:12] Dan Fu: And, of course this is also the part that will be more open to questions. So, a couple things that, that I'm excited about is continued hardware model co design for, for these models. So one of the things that we've put out recently is this library called ThunderKittens. It's a CUDA library.[00:30:29] Dan Fu: And one of the things that, that we found frustrating is every time that we built one of these new architectures, and I'm sure you had the exact same experience, we'd have to go and spend two months in CUDA land, like writing these, these new efficient things. And. If we decided to change one thing in PyTorch, like one line of PyTorch code is like a week of CUDA code at least.[00:30:47] Dan Fu: So one of our goals with, with a library like Thunderkitten, so we, we just broke down what are the key principles, what are the key hardware things what are the key, Compute pieces that you get from the hardware. So for example on [00:31:00] H100 everything is really revolves around a warp group matrix multiply operation.[00:31:06] Dan Fu: So you really want your operation to be able to split into relatively small matrix, matrix multiply operations. So like multiplying two 64 by 64 matrices, for example. And so if you know that ahead of time when you're designing your model, that probably gives you you know, some information about how you set the state sizes, how you set the update, how you set the update function.[00:31:27] Dan Fu: So with Thunderkittens we basically built a whole library just around this basic idea that all your basic compute primitives should not be a float, but it should be a matrix, and everything should just be matrix compute. And we've been using that to, to try to both re implement some existing architectures, and also start to design code.[00:31:44] Dan Fu: Some new ones that are really designed with this core with a tensor core primitive in mind. Another thing that that we're, that at least I'm excited about is we, over the last four or five years, we've really been looking at language models as the next thing. But if you've been paying [00:32:00] attention to Twitter there's been a bunch of new next generation models that are coming out.[00:32:04] Dan Fu: So there, there are. So, video generation models that can run real time, that are supported by your mouse and your keyboard, that I'm told if you play with them that, you know, that they only have a few seconds of memory. Can we take that model, can we give it a very long context length so that you could actually maybe generate an entire game state at a time?[00:32:25] Dan Fu: What does that look like for the model? You're certainly not going to do a giant quadratic attention computation to try to run that. Maybe, maybe use some of these new models, or some of these new video generation models that came out. So Sora came out I don't know, two days ago now. But with super long queue times and super long generation times.[00:32:43] Dan Fu: So that's probably a quadratic attention operation at the, at the bottom of it. What if we could remove that and get the same quality, but a lot faster generation time? Or some of the demos that we saw from Paige earlier today. You know, if I have a super long conversation with my [00:33:00] Gemini bot, what if I wanted to remember everything that it's seen in the last week?[00:33:06] Dan Fu: I mean, maybe you don't for personal reasons, but what if I did, you know? What does that mean for the architecture? And I think, you know, that's certainly something I'm pretty excited about. I'm sure you're excited about it too. So, I think we were supposed to have some hot takes, but I honestly don't remember what our hot takes were.[00:33:21] Hot Takes - does anyone really need long context?[00:33:21] Eugene Cheah: Yeah, including the next slide. Hot takes, yes, these are our[00:33:25] Dan Fu: hot takes.[00:33:25] Eugene Cheah: I think the big one on Twitter that we saw, that we shared, was the question is like, is RAG relevant? In the case of, like, the future of, like, state based models?[00:33:38] Dan Fu: Let's see, I haven't played too much with RAG. But when I have. I'll say I found it was a little bit challenging to do research on it because we had this experience over and over again, where you could have any, an embedding model of any quality, so you could have a really, really bad embedding model, or you could have a really, really [00:34:00] good one, By any measure of good.[00:34:03] Dan Fu: And for the final RAG application, it kind of didn't matter. That's what I'll say about RAG while I'm being recorded. I know it doesn't actually answer the question, but[00:34:13] Eugene Cheah: Yeah, so I think a lot of folks are like, extremely excited of the idea of RWKB or State Space potentially having infinite context.[00:34:21] Eugene Cheah: But I think the reality is that when we say infinite context, we just mean a different kind of infinite context, or you, or as it's previously covered, you need to test the model differently. So, think of it more along the lines of the human. Like, I don't remember what I ate for breakfast yesterday.[00:34:37] Eugene Cheah: Yeah, that's the statement that I'll say. And And we humans are not quadratic transformers. If we did, if let's say we increased our brain size for every second we live, we would have exploded by the time we are 5 years old or something like that. And, and I think, I think basically fundamentally for us, right, be it whether we, regardless of whether RWKB, statespace, XLSTM, [00:35:00] etc, our general idea is that instead of that expanding state, that increase in computational cost, what if we have a fixed state size?[00:35:08] Eugene Cheah: And Information theory detects that that fixed state size will have a limit. Just how big of a limit is a question, like, we, like, RWKB is running at 40 megabytes for, for its state. Its future version might run into 400 megabytes. That is like millions of tokens in, if you're talking about mathematically, the maximum possibility.[00:35:29] Eugene Cheah: It's just that I guess we were all more inefficient about it, so maybe we hit 100, 000. And that's kind of like the work we are doing, trying to like push it and maximize it. And that's where the models will start differing, because it will choose to forget things, it will choose to remember things. And that's why I think that there might be some element of right, but it may not be the same right.[00:35:49] Eugene Cheah: It may be the model learn things, and it's like, hmm, I can't remember that, that article. Let me do a database search, to search. Just like us humans, when we can't remember the article in the company. We do a search on Notion. [00:36:00][00:36:00] Dan Fu: I think something that would be really interesting is if you could have facts that are, so right now, the one intuition about language models is that all those parameters are around just to store random facts about the world.[00:36:14] Dan Fu: And this intuition comes from the observation that if you take a really small language model, it can do things like talk to you, or kind of has like the The style of conversation, it can learn that, but where it will usually fall over compared to a much larger one is it'll just be a lot less factual about things that it knows or that it can do.[00:36:32] Dan Fu: But that points to all those weights that we're spending, all that SGD that we're spending to train these models are just being used to store facts. And we have things like databases that are pretty good at storing facts. So I think one thing that would be really interesting is if we could actually have some sort of outside data store that a language model can can look at that that maybe is you know, has has some sort of gradient descent in it, but but would be quite interesting.[00:36:58] Dan Fu: And then maybe you could edit it, delete [00:37:00] facts, you know, change who's president so that it doesn't, it doesn't get lost.[00:37:04] Vibhu: Can we open up Q& A and hot takes for the audience? I have a hot take Q& A. Do these scale? When, when 405B state space model, RAG exists, no one does long context, who's throwing in 2 million token questions, hot takes?[00:37:24] Dan Fu: The, the who's throwing in 2 million token question, I think, is, is a really good question. So I actually, I was going to offer that as a hot take. I mean, my hot take was going to be that long context doesn't matter. I know I just gave a whole talk about it, but you know, what, what's the point of doing research if you can't, you know, play both sides.[00:37:40] Dan Fu: But I think one of the, so I think for both of us, the reason that we first got into this was just from the first principled questions of there's this quadratic thing. Clearly intelligence doesn't need to be quadratic. What is going on? Can we understand it better? You know, since then it's kind of turned into a race, which has [00:38:00] been exciting to watch, like, how much context you can take in.[00:38:03] Dan Fu: But I think it's right. Nobody is actually putting in a two million context prompt into these models. And, and, you know, if they are, maybe we can go, go You know, design a better model to do that particular thing. Yeah, what do you think about that? So you've also been working on this. Do you think long context matters?[00:38:19] Eugene Cheah: So I'm going to burn a bit. How many of you remember the news of Google Gemini supporting 3 million contacts, right? Raise your hand.[00:38:28] Vibhu: Yeah, 2 million.[00:38:29] Eugene Cheah: Oh, it's 2 million.[00:38:31] Eugene Cheah: Yeah, how many of you actually tried that? See?[00:38:34] Vibhu: I use it a lot. You? You work for MindsTV. I use it a lot.[00:38:41] Eugene Cheah: So, for some people that has used, and I think, I think that's the, that's might be, like, this is where my opinion starts to differ, because I think the big labs may have a bigger role in this, because Like, even for RWKB, even when we train non contacts, the reason why I say VRAM is a problem is that because when we did the, we need to backprop [00:39:00] against the states, we actually need to maintain the state in between the tokens by the token length.[00:39:05] Eugene Cheah: So that means we need to actually roll out the whole 1 million contacts if we are actually training 1 million. Which is the same for transformers, actually, but it just means we don't magically reuse the VRAM consumption in the training time space. So that is one of the VRAM bottlenecks, and I'm neither OpenAI nor Google, so donate GPUs if you have too much of them.[00:39:27] Eugene Cheah: But then, putting it back to another paradigm, right, is that I think O1 style reasoning might be actually pushing that direction downwards. In my opinion, this is my partial hot take is that if, let's say you have a super big model, And let's say you have a 70B model that may take double the tokens, but gets the same result.[00:39:51] Eugene Cheah: Strictly speaking, a 70B, and this is even for transformer or non transformer, right? We we'll take less less resources than that 400 B [00:40:00] model, even if it did double the amount thinking. And if that's the case, and we are still all trying to figure this out, maybe the direction for us is really getting the sub 200 B to be as fast as efficient as possible.[00:40:11] Eugene Cheah: We a very efficient architecture that some folks happen to be working on to, to just reason it out over larger and larger context thing.[00:40:20] Question: Yeah. One thing I'm super interested in is. Models that can watch forever? Obviously you cannot train something on infinite context length. How are y'all thinking about that, where you run on a much longer context length than is possible to train on?[00:40:38] Dan Fu: Yeah, it's a, it's a great question. So I think when I think you guys probably had tweets along these lines, too. When we first started doing these things, because these are all recurrent models in theory you could just run it forever. You could just run it forever. And at the very least it won't, it won't like error out on your crash.[00:40:57] Dan Fu: There's another question of whether it can actually [00:41:00] use what it's seen in that infinite context. And I think there, so one place where probably the research and architectures ran faster Then another research is actually the benchmarks for long context. So you turn it on forever. You want to do everything or watch everything.[00:41:16] Dan Fu: What is it that you actually wanted to do? Can we actually build some benchmarks for that? Then measure what's happening. And then ask the question, can the models do it? Is there something else that they need? Yeah, I think that if I were to turn back the clock to 2022, that's probably one of the things I would have done differently, which would have been actually get some long context benchmarks out at the same time as we started pushing context length on all these models.[00:41:41] Eugene Cheah: I will also say the use case. So like, I think we both agree that there's no Infinite memory and the model needs to be able to learn and decide. I think what we have observed for, I think this also fits the state space model, is that one of the key advantages of this alternate attention mechanic that is not based on token position is that the model don't suddenly become crazy when you go past the [00:42:00] 8k training context tank, or a million context tank.[00:42:03] Eugene Cheah: It's actually still stable. It's still able to run, it's still able to rationalize. It just starts forgetting things. But some of these things are still there in latent memory. Some of these things are still somewhat there. That's the whole point of why reading twice works. Things like that. And one of the biggest pushes in this direction is that I think both Statespace and RWKB have Separate papers by other researchers where they use this architecture for time series data.[00:42:26] Eugene Cheah: Weather modeling. So, you are not asking what was the weather five days ago. You're asking what's the weather tomorrow based on the infinite length that we, as long as this Earth and the computer will keep running. So, so, and they found that it is like, better than existing, like, transformer or existing architecture in modeling this weather data.[00:42:47] Eugene Cheah: Control for the param size and stuff. I'm quite sure there are people with larger models. So, so there are things that, that in this case, right, there is future applications if your question is just what's next and not what's 10 years ago.[00:42:59] Dan Fu: Thanks so [00:43:00] much for having us. Get full access to Latent.Space at www.latent.space/subscribe
-
 2024 in Open Models [LS Live @ NeurIPS]
2024 in Open Models [LS Live @ NeurIPS]From 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2024-12-23 04:29
Happy holidays! We’ll be sharing snippets from Latent Space LIVE! through the break bringing you the best of 2024! We want to express our deepest appreciation to event sponsors AWS, Daylight Computer, Thoth.ai, StrongCompute, Notable Capital, and most of all our LS supporters who helped fund the venue and A/V production!For NeurIPS last year we did our standard conference podcast coverage interviewing selected papers (that we have now also done for ICLR and ICML), however we felt that we could be doing more to help AI Engineers 1) get more industry-relevant content, and 2) recap 2024 year in review from experts. As a result, we organized the first Latent Space LIVE!, our first in person miniconference, at NeurIPS 2024 in Vancouver.Since Nathan Lambert ( Interconnects ) joined us for the hit RLHF 201 episode at the start of this year, it is hard to overstate how much Open Models have exploded this past year. In 2023 only five names were playing in the top LLM ranks, Mistral, Mosaic's MPT, TII UAE's Falcon, Yi from Kai-Fu Lee's 01.ai, and of course Meta's Llama 1 and 2. This year a whole cast of new open models have burst on the scene, from Google's Gemma and Cohere's Command R, to Alibaba's Qwen and Deepseek models, to LLM 360 and DCLM and of course to the Allen Institute's OLMo, OL MOE, Pixmo, Molmo, and Olmo 2 models. We were honored to host Luca Soldaini, one of the research leads on the Olmo series of models at AI2.Pursuing Open Model research comes with a lot of challenges beyond just funding and access to GPUs and datasets, particularly the regulatory debates this year across Europe, California and the White House. We also were honored to hear from and Sophia Yang, head of devrel at Mistral, who also presented a great session at the AI Engineer World's Fair Open Models track!Full Talk on YouTubePlease like and subscribe!Timestamps* 00:00 Welcome to Latent Space Live * 00:12 Recap of 2024: Best Moments and Keynotes * 01:22 Explosive Growth of Open Models in 2024 * 02:04 Challenges in Open Model Research * 02:38 Keynote by Luca Soldani: State of Open Models * 07:23 Significance of Open Source AI Licenses * 11:31 Research Constraints and Compute Challenges * 13:46 Fully Open Models: A New Trend * 27:46 Mistral's Journey and Innovations * 32:57 Interactive Demo: Lachat Capabilities * 36:50 Closing Remarks and NetworkingTranscriptSession3Audio[00:00:00] AI Charlie: Welcome to Latent Space Live, our first mini conference held at NeurIPS 2024 in Vancouver. This is Charlie, your AI co host. As a special treat this week, we're recapping the best of 2024 going domain by domain. We sent out a survey to the over 900 of you who told us what you wanted, and then invited the best speakers in the latent space network to cover each field.[00:00:28] AI Charlie: 200 of you joined us in person throughout the day, with over 2, 200 watching live online. Our next keynote covers the state of open models in 2024, with Luca Soldani and Nathan Lambert of the Allen Institute for AI, with a special appearance from Dr. Sophia Yang of Mistral. Our first hit episode of 2024 was with Nathan Lambert on RLHF 201 back in January.[00:00:57] AI Charlie: Where he discussed both reinforcement learning for language [00:01:00] models and the growing post training and mid training stack with hot takes on everything from constitutional AI to DPO to rejection sampling and also previewed the sea change coming to the Allen Institute. And to Interconnects, his incredible substack on the technical aspects of state of the art AI training.[00:01:18] AI Charlie: We highly recommend subscribing to get access to his Discord as well. It is hard to overstate how much open models have exploded this past year. In 2023, only five names were playing in the top LLM ranks. Mistral, Mosaics MPT, and Gatsby. TII UAE's Falcon, Yi, from Kaifu Lee's 01. ai, And of course, Meta's Lama 1 and 2.[00:01:43] AI Charlie: This year, a whole cast of new open models have burst on the scene. From Google's Jemma and Cohere's Command R, To Alibaba's Quen and DeepSeq models, to LLM360 and DCLM, and of course, to the Allen Institute's OLMO, [00:02:00] OLMOE, PIXMO, MOLMO, and OLMO2 models. Pursuing open model research comes with a lot of challenges beyond just funding and access to GPUs and datasets, particularly the regulatory debates this year across Europe.[00:02:14] AI Charlie: California and the White House. We also were honored to hear from Mistral, who also presented a great session at the AI Engineer World's Fair Open Models track. As always, don't forget to check the show notes for the YouTube link to their talk, as well as their slides. Watch out and take care.[00:02:35] Luca Intro[00:02:35] Luca Soldaini: Cool. Yeah, thanks for having me over. I'm Luca. I'm a research scientist at the Allen Institute for AI. I threw together a few slides on sort of like a recap of like interesting themes in open models for, for 2024. Have about maybe 20, 25 minutes of slides, and then we can chat if there are any questions.[00:02:57] Luca Soldaini: If I can advance to the next slide. [00:03:00] Okay, cool. So I did the quick check of like, to sort of get a sense of like, how much 2024 was different from 2023. So I went on Hugging Face and sort of get, tried to get a picture of what kind of models were released in 2023 and like, what do we get in 2024?[00:03:16] Luca Soldaini: 2023 we get, we got things like both LLAMA 1 and 2, we got Mistral, we got MPT, Falcon models, I think the YI model came in at the end. Tail end of the year. It was a pretty good year. But then I did the same for 2024. And it's actually quite stark difference. You have models that are, you know, reveling frontier level.[00:03:38] Luca Soldaini: Performance of what you can get from closed models from like Quen, from DeepSeq. We got Llama3. We got all sorts of different models. I added our own Olmo at the bottom. There's this growing group of like, Fully open models that I'm going to touch on a little bit later. But you know, just looking at the slides, it feels like 2024 [00:04:00] was just smooth sailing, happy knees, much better than previous year.[00:04:04] Luca Soldaini: And you know, you can plot you can pick your favorite benchmark Or least favorite, I don't know, depending on what point you're trying to make. And plot, you know, your closed model, your open model and sort of spin it in ways that show that, oh, you know open models are much closer to where closed models are today versus to Versus last year where the gap was fairly significant.[00:04:29] Luca Soldaini: So one thing that I think I don't know if I have to convince people in this room, but usually when I give this talks about like open models, there is always like this background question in, in, in people's mind of like, why should we use open models? APIs argument, you know, it's, it's. Just an HTTP request to get output from a, from one of the best model out there.[00:04:53] Luca Soldaini: Why do I have to set up infra and use local models? And there are really like two answer. There is the more [00:05:00] researchy answer for this, which is where it might be. Background lays, which is just research. If you want to do research on language models, research thrives on, on open models, there is like large swath of research on modeling, on how these models behave on evaluation and inference on mechanistic interpretability that could not happen at all if you didn't have open models they're also for AI builders, they're also like.[00:05:30] Luca Soldaini: Good use cases for using local models. You know, you have some, this is like a very not comprehensive slides, but you have things like there are some application where local models just blow closed models out of the water. So like retrieval, it's a very clear example. We might have like constraints like Edge AI applications where it makes sense.[00:05:51] Luca Soldaini: But even just like in terms of like stability, being able to say this model is not changing under the hood. It's, there's plenty of good cases for, [00:06:00] for open models. And the community is just not models. Is I stole this slide from one of the Quent2 announcement blog posts. But it's super cool to see like how much tech exists around open models and serving them on making them efficient and hosting them.[00:06:18] Luca Soldaini: It's pretty cool. And so. It's if you think about like where the term opens come from, comes from like the open source really open models meet the core tenants of, of open, of open source specifically when it comes around collaboration, there is truly a spirit, like through these open models, you can build on top of other people.[00:06:41] Luca Soldaini: innovation. We see a lot of these even in our own work of like, you know, as we iterate in the various versions of Alma it's not just like every time we collect from scratch all the data. No, the first step is like, okay, what are the cool data sources and datasets people have put [00:07:00] together for language model for training?[00:07:01] Luca Soldaini: Or when it comes to like our post training pipeline We one of the steps is you want to do some DPO and you use a lot of outputs of other models to improve your, your preference model. So it's really having like an open sort of ecosystem benefits and accelerates the development of open models.[00:07:23] The Definition of Open Models[00:07:23] Luca Soldaini: One thing that we got in 2024, which is not a specific model, but I thought it was really significant, is we first got we got our first open source AI definition. So this is from the open source initiative they've been generally the steward of a lot of the open source licenses when it comes to software and so they embarked on this journey in trying to figure out, okay, How does a license, an open source license for a model look like?[00:07:52] Luca Soldaini: Majority of the work is very dry because licenses are dry. So I'm not going to walk through the license step by [00:08:00] step, but I'm just going to pick out one aspect that is very good and then one aspect that personally feels like it needs improvement on the good side. This this open source AI license actually.[00:08:13] Luca Soldaini: This is very intuitive. If you ever build open source software and you have some expectation around like what open source looks like for software for, for AI, sort of matches your intuition. So, the weights need to be fairly available the code must be released with an open source license and there shouldn't be like license clauses that block specific use cases.[00:08:39] Luca Soldaini: So. Under this definition, for example, LLAMA or some of the QUEN models are not open source because the license says you can't use this model for this or it says if you use this model you have to name the output this way or derivative needs to be named that way. Those clauses don't meet open source [00:09:00] definition and so they will not be covered.[00:09:02] Luca Soldaini: The LLAMA license will not be covered under the open source definition. It's not perfect. One of the thing that, um, internally, you know, in discussion with with OSI, we were sort of disappointed is around the language. For data. So you might imagine that an open source AI model means a model where the data is freely available.[00:09:26] Luca Soldaini: There were discussion around that, but at the end of the day, they decided to go with a softened stance where they say a model is open source if you provide sufficient detail information. On how to sort of replicate the data pipeline. So you have an equivalent system, sufficient, sufficiently detailed.[00:09:46] Luca Soldaini: It's very, it's very fuzzy. Don't like that. An equivalent system is also very fuzzy. And this doesn't take into account the accessibility of the process, right? It might be that you provide enough [00:10:00] information, but this process costs, I don't know, 10 million to do. Now the open source definition. Like, any open source license has never been about accessibility, so that's never a factor in open source software, how accessible software is.[00:10:14] Luca Soldaini: I can make a piece of open source, put it on my hard drive, and never access it. That software is still open source, the fact that it's not widely distributed doesn't change the license, but practically there are expectations of like, what we want good open sources to be. So, it's, It's kind of sad to see that the data component in this license is not as, as, Open as some of us would like would like it to be.[00:10:40] Challenges for Open Models[00:10:40] Luca Soldaini: and I linked a blog post that Nathan wrote on the topic that it's less rambly and easier to follow through. One thing that in general, I think it's fair to say about the state of open models in 2024 is that we know a lot more than what we knew in, [00:11:00] in 2023. Like both on the training data, like And the pre training data you curate on like how to do like all the post training, especially like on the RL side.[00:11:10] Luca Soldaini: You know, 2023 was a lot of like throwing random darts at the board. I think 2024, we have clear recipes that, okay, don't get the same results as a closed lab because there is a cost in, in actually matching what they do. But at least we have a good sense of like, okay, this is, this is the path to get state of the art language model.[00:11:31] Luca Soldaini: I think that one thing that it's a downside of 2024 is that I think we are more research constrained in 2023. It feels that, you know, the barrier for compute that you need to, to move innovation along as just being right rising and rising. So like, if you go back to this slide, there is now this, this cluster of models that are sort of released by the.[00:11:57] Luca Soldaini: Compute rich club. Membership is [00:12:00] hotly debated. You know, some people don't want to be. Called the rich because it comes to expectations. Some people want to be called rich, but I don't know, there's debate, but like, these are players that have, you know, 10, 000, 50, 000 GPUs at minimum. And so they can do a lot of work and a lot of exploration and improving models that it's not very accessible.[00:12:21] Luca Soldaini: To give you a sense of like how I personally think about. Research budget for each part of the, of the language model pipeline is like on the pre training side, you can maybe do something with a thousand GPUs, really you want 10, 000. And like, if you want real estate of the art, you know, your deep seek minimum is like 50, 000 and you can scale to infinity.[00:12:44] Luca Soldaini: The more you have, the better it gets. Everyone on that side still complains that they don't have enough GPUs. Post training is a super wide sort of spectrum. You can do as little with like eight GPUs as long as you're able to [00:13:00] run, you know, a good version of, say, a LLAMA model, you can do a lot of work there.[00:13:05] Luca Soldaini: You can scale a lot of the methodology, just like scales with compute, right? If you're interested in you know, your open replication of what OpenAI's O1 is you're going to be on the 10K spectrum of our GPUs. Inference, you can do a lot with very few resources. Evaluation, you can do a lot with, well, I should say at least one GPUs if you want to evaluate GPUs.[00:13:30] Luca Soldaini: Open models but in general, like if you are, if you care a lot about intervention to do on this model, which it's my prefer area of, of research, then, you know, the resources that you need are quite, quite significant. Yeah. One other trends that has emerged in 2024 is this cluster of fully open models.[00:13:54] Luca Soldaini: So Omo the model that we built at ai, two being one of them and you know, it's nice [00:14:00] that it's not just us. There's like a cluster of other mostly research efforts who are working on this. And so it's good to to give you a primer of what like fully open means. So fully open, the easy way to think about it is instead of just releasing a model checkpoint that you run, you release a full recipe so that other people working on it.[00:14:24] Luca Soldaini: Working on that space can pick and choose whatever they want from your recipe and create their own model or improve on top of your model. You're giving out the full pipeline and all the details there instead of just like the end output. So I pull up the screenshot from our recent MOE model.[00:14:43] Luca Soldaini: And like for this model, for example, we released the model itself. Data that was trained on, the code, both for training and inference all the logs that we got through the training run, as well as every intermediate checkpoint and like the fact that you release different part of the pipeline [00:15:00] allows others to do really cool things.[00:15:02] Luca Soldaini: So for example, this tweet from early this year from folks in news research they use our pre training data to do a replication of the BitNet paper in the open. So they took just a Really like the initial part of a pipeline and then the, the thing on top of it. It goes both ways.[00:15:21] Luca Soldaini: So for example, for the Olmo2 model a lot of our pre trained data for the first stage of pre training was from this DCLM initiative that was led by folks Ooh, a variety of ins a variety of institutions. It was a really nice group effort. But you know, for When it was nice to be able to say, okay, you know, the state of the art in terms of like what is done in the open has improved.[00:15:46] AI2 Models - Olmo, Molmo, Pixmo etc[00:15:46] Luca Soldaini: We don't have to like do all this work from scratch to catch up the state of the art. We can just take it directly and integrate it and do our own improvements on top of that. I'm going to spend a few minutes doing like a [00:16:00] shameless plug for some of our fully open recipes. So indulge me in this.[00:16:05] Luca Soldaini: So a few things that we released this year was, as I was mentioning, there's OMOE model which is, I think still is state of the art MOE model in its size class. And it's also. Fully open, so every component of this model is available. We released a multi modal model called Molmo. Molmo is not just a model, but it's a full recipe of how you go from a text only model to a multi modal model, and we apply this recipe on top of Quent checkpoints, on top of Olmo checkpoints, as well as on top of OlmoE.[00:16:37] Luca Soldaini: And I think there'd be a replication doing that on top of Mistral as well. The post training side we recently released 2. 0. 3. Same story. This is a recipe on how you go from a base model to A state of the art post training model. We use the Tulu recipe on top of Olmo, on top of Llama, and then there's been open replication effort [00:17:00] to do that on top of Quen as well.[00:17:02] Luca Soldaini: It's really nice to see like, you know, when your recipe sort of, it's kind of turnkey, you can apply it to different models and it kind of just works. And finally, the last thing we released this year was Olmo 2, which so far is the best state of the art. Fully open language model a Sera combines aspect from all three of these previous models.[00:17:22] Luca Soldaini: What we learn on the data side from MomoE and what we learn on like making models that are easy to adapt from the Momo project and the Tulu project. I will close with a little bit of reflection of like ways this, this ecosystem of open models like it's not all roses. It's not all happy. It feels like day to day, it's always in peril.[00:17:44] Luca Soldaini: And, you know, I talked a little bit about like the compute issues that come with it. But it's really not just compute. One thing that is on top of my mind is due to like the environment and how you know, growing feelings about like how AI is treated. [00:18:00] It's actually harder to get access to a lot of the data that was used to train a lot of the models up to last year.[00:18:06] Luca Soldaini: So this is a screenshot from really fabulous work from Shane Longpre who's, I think is in Europe about Just access of like diminishing access to data for language model pre training. So what they did is they went through every snapshot of common crawl. Common crawl is this publicly available scrape of the, of a subset of the internet.[00:18:29] Luca Soldaini: And they looked at how For any given website whether a website that was accessible in say 2017, what, whether it was accessible or not in 2024. And what they found is as a reaction to like the close like of the existence of closed models like OpenAI or Cloud GPT or Cloud a lot of content owners have blanket Blocked any type of crawling to your website.[00:18:57] Luca Soldaini: And this is something that we see also internally at [00:19:00] AI2. Like one project that we started this year is we wanted to, we wanted to understand, like, if you're a good citizen of the internet and you crawl following sort of norms and policy that have been established in the last 25 years, what can you crawl?[00:19:17] Luca Soldaini: And we found that there's a lot of website where. The norms of how you express preference of whether to crawl your data or not are broken. A lot of people would block a lot of crawling, but do not advertise that in RobustDXT. You can only tell that they're crawling, that they're blocking you in crawling when you try doing it.[00:19:37] Luca Soldaini: Sometimes you can't even crawl the robots. txt to, to check whether you're allowed or not. And then a lot of websites there's, there's like all these technologies that historically have been, have existed to make websites serving easier such as Cloudflare or DNS. They're now being repurposed for blocking AI or any type of crawling [00:20:00] in a way that is Very opaque to the content owners themselves.[00:20:04] Luca Soldaini: So, you know, you go to these websites, you try to access them and they're not available and you get a feeling it's like, Oh, someone changed, something changed on the, on the DNS side that it's blocking this and likely the content owner has no idea. They're just using a Cloudflare for better, you know, load balancing.[00:20:25] Luca Soldaini: And this is something that was sort of sprung on them with very little notice. And I think the problem is this, this blocking or ideas really, it impacts people in different ways. It disproportionately helps companies that have a headstart, which are usually the closed labs and it hurts incoming newcomer players where either have now to do things in a sketchy way or you're never going to get that content that the closed lab might have.[00:20:54] Luca Soldaini: So there's a lot, it was a lot of coverage. I'm going to plug Nathan's blog post again. That is, [00:21:00] that I think the title of this one is very succinct which is like, we're actually not, You know, before thinking about running out of training data, we're actually running out of open training data. And so if we want better open models they should be on top of our mind.[00:21:13] Regulation and Lobbying[00:21:13] Luca Soldaini: The other thing that has emerged is that there is strong lobbying efforts on trying to define any kind of, AI as like a new extremely risky and I want to be precise here. Like the problem is now, um, like the problem is not not considering the risk of this technology. Every technology has risks that, that should always be considered.[00:21:37] Luca Soldaini: The thing that it's like to me is sorry, is ingenious is like just putting this AI on a pedestal and calling it like, An unknown alien technology that has like new and undiscovered potentials to destroy humanity. When in reality, all the dangers I think are rooted in [00:22:00] dangers that we know from existing software industry or existing issues that come with when using software on on a lot of sensitive domains, like medical areas.[00:22:13] Luca Soldaini: And I also noticed a lot of efforts that have actually been going on and trying to make this open model safe. I pasted one here from AI2, but there's actually like a lot of work that has been going on on like, okay, how do you make, if you're distributing this model, Openly, how do you make it safe?[00:22:31] Luca Soldaini: How, what's the right balance between accessibility on open models and safety? And then also there's annoying brushing of sort of concerns that are then proved to be unfounded under the rug. You know, if you remember the beginning of this year, it was all about bio risk of these open models.[00:22:48] Luca Soldaini: The whole thing fizzled because as being Finally, there's been like rigorous research, not just this paper from Cohere folks, but it's been rigorous research showing [00:23:00] that this is really not a concern that we should be worried about. Again, there is a lot of dangerous use of AI applications, but this one was just like, A lobbying ploy to just make things sound scarier than they actually are.[00:23:15] Luca Soldaini: So I got to preface this part. It says, this is my personal opinion. It's not my employer, but I look at things like the SP 1047 from, from California. And I think we kind of dodged a bullet on, on this legislation. We, you know, the open source community, a lot of the community came together at the last, sort of the last minute and did a very good effort trying to explain all the negative impact of this bill.[00:23:43] Luca Soldaini: But There's like, I feel like there's a lot of excitement on building these open models or like researching on these open models. And lobbying is not sexy it's kind of boring but it's sort of necessary to make sure that this ecosystem can, can really [00:24:00] thrive. This end of presentation, I have Some links, emails, sort of standard thing in case anyone wants to reach out and if folks have questions or anything they wanted to discuss.[00:24:13] Luca Soldaini: Is there an open floor? I think we have Sophia[00:24:16] swyx: who wants to who one, one very important open model that we haven't covered is Mistral. Ask her on this slide. Yeah, yeah. Well, well, it's nice to have the Mistral person talk recap the year in Mistral. But while Sophia gets set up, does anyone have like, just thoughts or questions about the progress in this space?[00:24:32] Questions - Incentive Alignment[00:24:32] swyx: Do you always have questions?[00:24:34] Quesiton: I'm very curious how we should build incentives to build open models, things like Francois Chollet's ArcPrize, and other initiatives like that. What is your opinion on how we should better align incentives in the community so that open models stay open?[00:24:49] Luca Soldaini: The incentive bit is, like, really hard.[00:24:51] Luca Soldaini: Like, even It's something that I actually, even we think a lot about it internally because like building open models is risky. [00:25:00] It's very expensive. And so people don't want to take risky bets. I think the, definitely like the challenges like our challenge, I think those are like very valid approaches for it.[00:25:13] Luca Soldaini: And then I think in general, promoting, building, so, any kind of effort to participate in this challenge, in those challenges, if we can promote doing that on top of open models and sort of really lean into like this multiplier effect, I think that is a good way to go. If there were more money for that.[00:25:35] Luca Soldaini: For efforts like research efforts around open models. There's a lot of, I think there's a lot of investments in companies that at the moment are releasing their model in the open, which is really cool. But it's usually more because of commercial interest and not wanting to support this, this like open models in the longterm, it's a really hard problem because I think everyone is operating sort of [00:26:00] in what.[00:26:01] Luca Soldaini: Everyone is at their local maximum, right? In ways that really optimize their position on the market. Global maximum is harder to achieve.[00:26:11] Question2: Can I ask one question? No.[00:26:12] Luca Soldaini: Yeah.[00:26:13] Question2: So I think one of the gap between the closed and open source models is the mutability. So the closed source models like chat GPT works pretty good on the low resource languages, which is not the same on the open, open source models, right?[00:26:27] Question2: So is it in your plan to improve on that?[00:26:32] Luca Soldaini: I think in general,[00:26:32] Luca Soldaini: yes, is I think it's. I think we'll see a lot of improvements there in, like, 2025. Like, there's groups like, Procurement English on the smaller side that are already working on, like, better crawl support, multilingual support. I think what I'm trying to say here is you really want to be experts.[00:26:54] Luca Soldaini: who are actually in those countries that teach those languages to [00:27:00] participate in the international community. To give you, like, a very easy example I'm originally from Italy. I think I'm terribly equipped to build a model that works well in Italian. Because one of the things you need to be able to do is having that knowledge of, like, okay, how do I access, you know, how Libraries, or content that is from this region that covers this language.[00:27:23] Luca Soldaini: I've been in the US long enough that I no longer know. So, I think that's the efforts that folks in Central Europe, for example, are doing. Around like, okay, let's tap into regional communities. To get access you know, to bring in collaborators from those areas. I think it's going to be, like, very crucial for getting products there.[00:27:46] Mistral intro[00:27:46] Sophia Yang: Hi everyone. Yeah, I'm super excited to be here to talk to you guys about Mistral. A really short and quick recap of what we have done, what kind of models and products we have released in the [00:28:00] past year and a half. So most of you We have already known that we are a small startup funded about a year and a half ago in Paris in May, 2003, it was funded by three of our co founders, and in September, 2003, we released our first open source model, Mistral 7b yeah, how, how many of you have used or heard about Mistral 7b?[00:28:24] Sophia Yang: Hey, pretty much everyone. Thank you. Yeah, it's our Pretty popular and community. Our committee really loved this model, and in December 23, we, we released another popular model with the MLE architecture Mr. A X seven B and oh. Going into this year, you can see we have released a lot of things this year.[00:28:46] Sophia Yang: First of all, in February 2004, we released MrSmall, MrLarge, LeChat, which is our chat interface, I will show you in a little bit. We released an embedding model for, you [00:29:00] know, converting your text into embedding vectors, and all of our models are available. The, the big cloud resources. So you can use our model on Google cloud, AWS, Azure Snowflake, IBM.[00:29:16] Sophia Yang: So very useful for enterprise who wants to use our model through cloud. And in April and May this year, we released another powerful open source MOE model, AX22B. And we also released our first code. Code Model Coastal, which is amazing at 80 plus languages. And then we provided another fine tuning service for customization.[00:29:41] Sophia Yang: So because we know the community love to fine tune our models, so we provide you a very nice and easy option for you to fine tune our model on our platform. And also we released our fine tuning code base called Menstrual finetune. It's open source, so feel free to take it. Take a look and.[00:29:58] Sophia Yang: More models. [00:30:00] On July 2, November this year, we released many, many other models. First of all is the two new small, best small models. We have Minestra 3B great for Deploying on edge devices we have Minstrel 8B if you used to use Minstrel 7B, Minstrel 8B is a great replacement with much stronger performance than Minstrel 7B.[00:30:25] Sophia Yang: We also collaborated with NVIDIA and open sourced another model, Nemo 12B another great model. And Just a few weeks ago, we updated Mistral Large with the version 2 with the updated, updated state of the art features and really great function calling capabilities. It's supporting function calling in LatentNate.[00:30:45] Sophia Yang: And we released two multimodal models Pixtral 12b. It's this open source and Pixtral Large just amazing model for, models for not understanding images, but also great at text understanding. So. Yeah, a [00:31:00] lot of the image models are not so good at textual understanding, but pixel large and pixel 12b are good at both image understanding and textual understanding.[00:31:09] Sophia Yang: And of course, we have models for research. Coastal Mamba is built on Mamba architecture and MathRoll, great with working with math problems. So yeah, that's another model.[00:31:29] Sophia Yang: Here's another view of our model reference. We have several premier models, which means these models are mostly available through our API. I mean, all of the models are available throughout our API, except for Ministry 3B. But for the premier model, they have a special license. Minstrel research license, you can use it for free for exploration, but if you want to use it for enterprise for production use, you will need to purchase a license [00:32:00] from us.[00:32:00] Sophia Yang: So on the top row here, we have Minstrel 3b and 8b as our premier model. Minstrel small for best, best low latency use cases, MrLarge is great for your most sophisticated use cases. PixelLarge is the frontier class multimodal model. And, and we have Coastral for great for coding and then again, MrEmbedding model.[00:32:22] Sophia Yang: And The bottom, the bottom of the slides here, we have several Apache 2. 0 licensed open way models. Free for the community to use, and also if you want to fine tune it, use it for customization, production, feel free to do so. The latest, we have Pixtros 3 12b. We also have Mr. Nemo mum, Coastal Mamba and Mastro, as I mentioned, and we have three legacy models that we don't update anymore.[00:32:49] Sophia Yang: So we recommend you to move to our newer models if you are still using them. And then, just a few weeks ago, [00:33:00] we did a lot of, uh, improvements to our code interface, Lachette. How many of you have used Lachette? Oh, no. Only a few. Okay. I highly recommend Lachette. It's chat. mistral. ai. It's free to use.[00:33:16] Sophia Yang: It has all the amazing capabilities I'm going to show you right now. But before that, Lachette in French means cat. So this is actually a cat logo. If you You can tell this is the cat eyes. Yeah. So first of all, I want to show you something Maybe let's, let's take a look at image understanding.[00:33:36] Sophia Yang: So here I have a receipts and I want to ask, just going to get the prompts. Cool. So basically I have a receipt and I said I ordered I don't know. Coffee and the sausage. How much do I owe? Add a 18 percent tip. So hopefully it was able to get the cost of the coffee and the [00:34:00] sausage and ignore the other things.[00:34:03] Sophia Yang: And yeah, I don't really understand this, but I think this is coffee. It's yeah. Nine, eight. And then cost of the sausage, we have 22 here. And then it was able to add the cost, calculate the tip, and all that. Great. So, it's great at image understanding, it's great at OCR tasks. So, if you have OCR tasks, please use it.[00:34:28] Sophia Yang: It's free on the chat. It's also available through our API. And also I want to show you a Canvas example. A lot of you may have used Canvas with other tools before. But, With Lachat, it's completely free again. Here, I'm asking it to create a canvas that's used PyScript to execute Python in my browser.[00:34:51] Sophia Yang: Let's see if it works. Import this. Okay, so, yeah, so basically it's executing [00:35:00] Python here. Exactly what we wanted. And the other day, I was trying to ask Lachat to create a game for me. Let's see if we can make it work. Yeah, the Tetris game. Yep. Let's just get one row. Maybe. Oh no. Okay. All right. You get the idea. I failed my mission. Okay. Here we go. Yay! Cool. Yeah. So as you can see, Lachet can write, like, a code about a simple game pretty easily. And you can ask Lachet to explain the code. Make updates however you like. Another example. There is a bar here I want to move.[00:35:48] Sophia Yang: Okay, great, okay. And let's go back to another one. Yeah, we also have web search capabilities. Like, you can [00:36:00] ask what's the latest AI news. Image generation is pretty cool. Generate an image about researchers. Okay. In Vancouver? Yeah, it's Black Forest Labs flux Pro. Again, this is free, so Oh, cool.[00:36:19] Sophia Yang: I guess researchers here are mostly from University of British Columbia. That's smart. Yeah. So this is Laia ira. Please feel free to use it. And let me know if you have any feedback. We're always looking for improvement and we're gonna release a lot more powerful features in the coming years.[00:36:37] Sophia Yang: Thank you. Get full access to Latent.Space at www.latent.space/subscribe
-
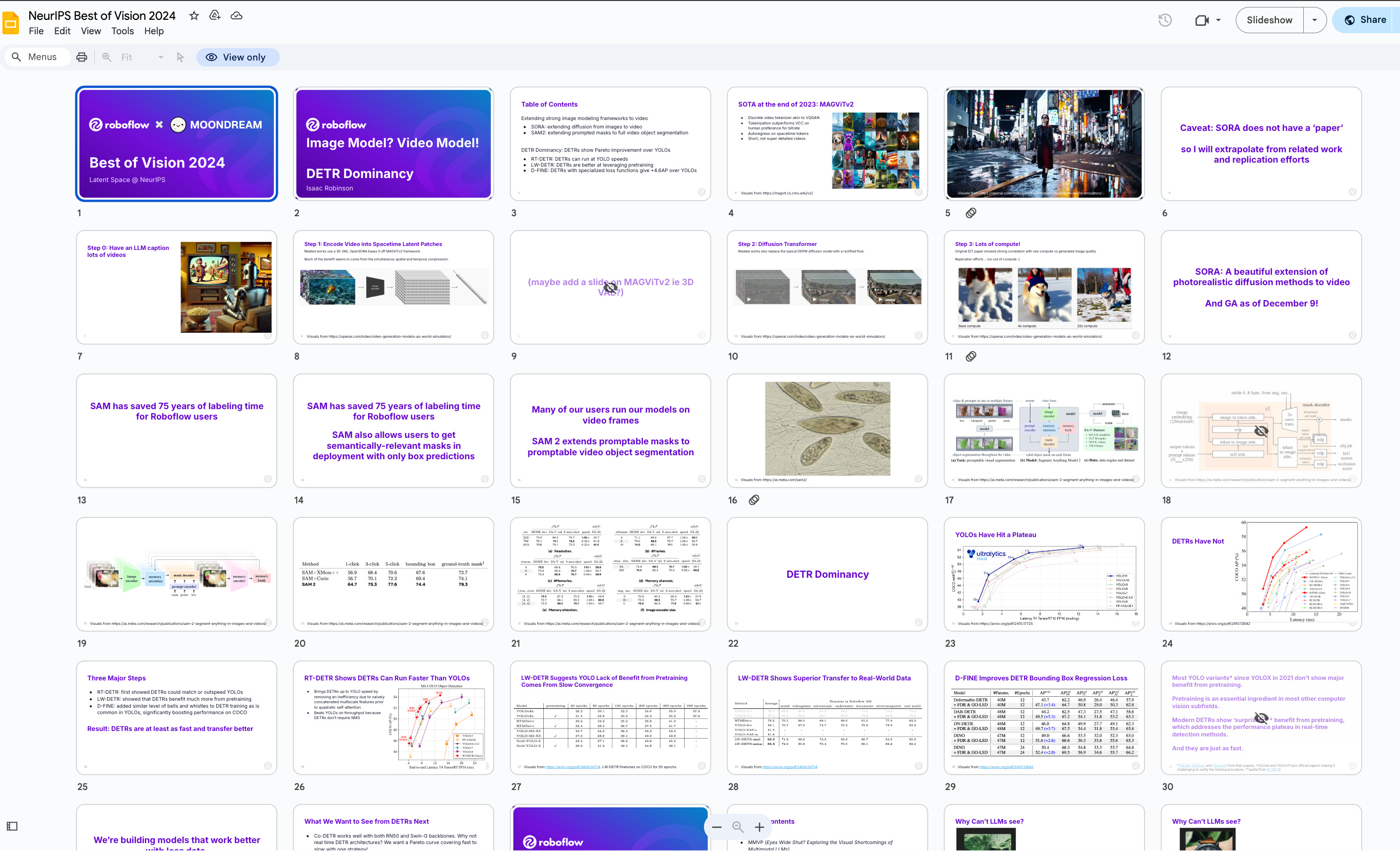 2024 in Vision [LS Live @ NeurIPS]
2024 in Vision [LS Live @ NeurIPS]From 🇺🇸 Latent Space: The AI Engineer Podcast, published at 2024-12-22 01:43
Happy holidays! We’ll be sharing snippets from Latent Space LIVE! through the break bringing you the best of 2024! We want to express our deepest appreciation to event sponsors AWS, Daylight Computer, Thoth.ai, StrongCompute, Notable Capital, and most of all all our LS supporters who helped fund the gorgeous venue and A/V production!For NeurIPS last year we did our standard conference podcast coverage interviewing selected papers (that we have now also done for ICLR and ICML), however we felt that we could be doing more to help AI Engineers 1) get more industry-relevant content, and 2) recap 2024 year in review from experts. As a result, we organized the first Latent Space LIVE!, our first in person miniconference, at NeurIPS 2024 in Vancouver.The single most requested domain was computer vision, and we could think of no one better to help us recap 2024 than our friends at Roboflow, who was one of our earliest guests in 2023 and had one of this year’s top episodes in 2024 again. Roboflow has since raised a $40m Series B!LinksTheir slides are here:All the trends and papers they picked:* Isaac Robinson* Sora (see our Video Diffusion pod) - extending diffusion from images to video* SAM 2: Segment Anything in Images and Videos (see our SAM2 pod) - extending prompted masks to full video object segmentation* DETR Dominancy: DETRs show Pareto improvement over YOLOs* RT-DETR: DETRs Beat YOLOs on Real-time Object Detection* LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection* D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement* Peter Robicheaux* MMVP (Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs)* * Florence 2 (Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks) * PalíGemma / PaliGemma 2* PaliGemma: A versatile 3B VLM for transfer* PaliGemma 2: A Family of Versatile VLMs for Transfer* AlMv2 (Multimodal Autoregressive Pre-training of Large Vision Encoders) * Vik Korrapati - MoondreamFull Talk on YouTubeWant more content like this? Like and subscribe to stay updated on our latest talks, interviews, and podcasts.Transcript/Timestamps[00:00:00] Intro[00:00:05] AI Charlie: welcome to Latent Space Live, our first mini conference held at NeurIPS 2024 in Vancouver. This is Charlie, your AI co host. When we were thinking of ways to add value to our academic conference coverage, we realized that there was a lack of good talks, just recapping the best of 2024, going domain by domain.[00:00:36] AI Charlie: We sent out a survey to the over 900 of you. who told us what you wanted, and then invited the best speakers in the Latent Space Network to cover each field. 200 of you joined us in person throughout the day, with over 2, 200 watching live online. Our second featured keynote is The Best of Vision 2024, with Peter Robichaud and Isaac [00:01:00] Robinson of Roboflow, with a special appearance from Vic Corrapati of Moondream.[00:01:05] AI Charlie: When we did a poll of our attendees, the highest interest domain of the year was vision. And so our first port of call was our friends at Roboflow. Joseph Nelson helped us kickstart our vision coverage in episode 7 last year, and this year came back as a guest host with Nikki Ravey of Meta to cover segment Anything 2.[00:01:25] AI Charlie: Roboflow have consistently been the leaders in open source vision models and tooling. With their SuperVision library recently eclipsing PyTorch's Vision library. And Roboflow Universe hosting hundreds of thousands of open source vision datasets and models. They have since announced a 40 million Series B led by Google Ventures.[00:01:46] AI Charlie: Woohoo.[00:01:48] Isaac's picks[00:01:48] Isaac Robinson: Hi, we're Isaac and Peter from Roboflow, and we're going to talk about the best papers of 2024 in computer vision. So, for us, we defined best as what made [00:02:00] the biggest shifts in the space. And to determine that, we looked at what are some major trends that happened and what papers most contributed to those trends.[00:02:09] Isaac Robinson: So I'm going to talk about a couple trends, Peter's going to talk about a trend, And then we're going to hand it off to Moondream. So, the trends that I'm interested in talking about are These are a major transition from models that run on per image basis to models that run using the same basic ideas on video.[00:02:28] Isaac Robinson: And then also how debtors are starting to take over the real time object detection scene from the YOLOs, which have been dominant for years.[00:02:37] Sora, OpenSora and Video Vision vs Generation[00:02:37] Isaac Robinson: So as a highlight we're going to talk about Sora, which from my perspective is the biggest paper of 2024, even though it came out in February. Is the what?[00:02:48] Isaac Robinson: Yeah. Yeah. So just it's a, SORA is just a a post. So I'm going to fill it in with details from replication efforts, including open SORA and related work, such as a stable [00:03:00] diffusion video. And then we're also going to talk about SAM2, which applies the SAM strategy to video. And then how debtors, These are the improvements in 2024 to debtors that are making them a Pareto improvement to YOLO based models.[00:03:15] Isaac Robinson: So to start this off, we're going to talk about the state of the art of video generation at the end of 2023, MagVIT MagVIT is a discrete token, video tokenizer akin to VQ, GAN, but applied to video sequences. And it actually outperforms state of the art handcrafted video compression frameworks.[00:03:38] Isaac Robinson: In terms of the bit rate versus human preference for quality and videos generated by autoregressing on these discrete tokens generate some pretty nice stuff, but up to like five seconds length and, you know, not super detailed. And then suddenly a few months later we have this, which when I saw it, it was totally mind blowing to me.[00:03:59] Isaac Robinson: 1080p, [00:04:00] a whole minute long. We've got light reflecting in puddles. That's reflective. Reminds me of those RTX demonstrations for next generation video games, such as Cyberpunk, but with better graphics. You can see some issues in the background if you look closely, but they're kind of, as with a lot of these models, the issues tend to be things that people aren't going to pay attention to unless they're looking for.[00:04:24] Isaac Robinson: In the same way that like six fingers on a hand. You're not going to notice is a giveaway unless you're looking for it. So yeah, as we said, SORA does not have a paper. So we're going to be filling it in with context from the rest of the computer vision scene attempting to replicate these efforts. So the first step, you have an LLM caption, a huge amount of videos.[00:04:48] Isaac Robinson: This, this is a trick that they introduced in Dolly 3, where they train a image captioning model to just generate very high quality captions for a huge corpus and then train a diffusion model [00:05:00] on that. Their Sora and their application efforts also show a bunch of other steps that are necessary for good video generation.[00:05:09] Isaac Robinson: Including filtering by aesthetic score and filtering by making sure the videos have enough motion. So they're not just like kind of the generators not learning to just generate static frames. So. Then we encode our video into a series of space time latents. Once again, SORA, very sparse in details.[00:05:29] Isaac Robinson: So the replication related works, OpenSORA actually uses a MAG VIT V2 itself to do this, but swapping out the discretization step with a classic VAE autoencoder framework. They show that there's a lot of benefit from getting the temporal compression, which makes a lot of sense as the Each sequential frames and videos have mostly redundant information.[00:05:53] Isaac Robinson: So by compressing against, compressing in the temporal space, you allow the latent to hold [00:06:00] a lot more semantic information while avoiding that duplicate. So, we've got our spacetime latents. Possibly via, there's some 3D VAE, presumably a MAG VATV2 and then you throw it into a diffusion transformer.[00:06:19] Isaac Robinson: So I think it's personally interesting to note that OpenSORA is using a MAG VATV2, which originally used an autoregressive transformer decoder to model the latent space, but is now using a diffusion diffusion transformer. So it's still a transformer happening. Just the question is like, is it?[00:06:37] Isaac Robinson: Parameterizing the stochastic differential equation is, or parameterizing a conditional distribution via autoregression. It's also it's also worth noting that most diffusion models today, the, the very high performance ones are switching away from the classic, like DDPM denoising diffusion probability modeling framework to rectified flows.[00:06:57] Isaac Robinson: Rectified flows have a very interesting property that as [00:07:00] they converge, they actually get closer to being able to be sampled with a single step. Which means that in practice, you can actually generate high quality samples much faster. Major problem of DDPM and related models for the past four years is just that they require many, many steps to generate high quality samples.[00:07:22] Isaac Robinson: So, and naturally, the third step is throwing lots of compute at the problem. So I didn't, I never figured out how to manage to get this video to loop, but we see very little compute, medium compute, lots of compute. This is so interesting because the the original diffusion transformer paper from Facebook actually showed that, in fact, the specific hyperparameters of the transformer didn't really matter that much.[00:07:48] Isaac Robinson: What mattered was that you were just increasing the amount of compute that the model had. So, I love how in the, once again, little blog posts, they don't even talk about [00:08:00] like the specific hyperparameters. They say, we're using a diffusion transformer, and we're just throwing more compute at it, and this is what happens.[00:08:08] Isaac Robinson: OpenSora shows similar results. The primary issue I think here is that no one else has 32x compute budget. So we end up with these we end up in the middle of the domain and most of the related work, which is still super, super cool. It's just a little disappointing considering the context. So I think this is a beautiful extension of the framework that was introduced in 22 and 23 for these very high quality per image generation and then extending that to videos.[00:08:39] Isaac Robinson: It's awesome. And it's GA as of Monday, except no one can seem to get access to it because they keep shutting down the login.[00:08:46] SAM and SAM2[00:08:46] Isaac Robinson: The next, so next paper I wanted to talk about is SAM. So we at Roboflow allow users to label data and train models on that data. Sam, for us, has saved our users 75 years of [00:09:00] labeling time.[00:09:00] Isaac Robinson: We are the, to the best of my knowledge, the largest SAM API that exists. We also, SAM also allows us to have our users train just pure bounding box regression models and use those to generate high quality masks which has the great side effect of requiring less training data to have a meaningful convergence.[00:09:20] Isaac Robinson: So most people are data limited in the real world. So anything that requires less data to get to a useful thing is that super useful. Most of our users actually run their object per frame object detectors on every frame in a video, or maybe not most, but many, many. And so Sam follows into this category of taking, Sam 2 falls into this category of taking something that really really works and applying it to a video which has the wonderful benefit of being plug and play with most of our Many of our users use cases.[00:09:53] Isaac Robinson: We're, we're still building out a sufficiently mature pipeline to take advantage of that, but it's, it's in the works. [00:10:00] So here we've got a great example. We can click on cells and then follow them. You even notice the cell goes away and comes back and we can still keep track of it which is very challenging for existing object trackers.[00:10:14] Isaac Robinson: High level overview of how SAM2 works. We there's a simple pipeline here where we can give, provide some type of prompt and it fills out the rest of the likely masks for that object throughout the rest of the video. So here we're giving a bounding box in the first frame, a set of positive negative points, or even just a simple mask.[00:10:36] Isaac Robinson: I'm going to assume people are somewhat familiar with SAM. So I'm going to just give a high level overview of how SAM works. You have an image encoder that runs on every frame. SAM two can be used on a single image, in which case the only difference between SAM two and SAM is that image encoder, which Sam used a standard VIT [00:11:00] Sam two replaced that with a hara hierarchical encoder, which gets approximately the same results, but leads to a six times faster inference, which is.[00:11:11] Isaac Robinson: Excellent, especially considering how in a trend of 23 was replacing the VAT with more efficient backbones. In the case where you're doing video segmentation, the difference is that you actually create a memory bank and you cross attend the features from the image encoder based on the memory bank.[00:11:31] Isaac Robinson: So the feature set that is created is essentially well, I'll go more into it in a couple of slides, but we take the features from the past couple frames, plus a set of object pointers and the set of prompts and use that to generate our new masks. Then we then fuse the new masks for this frame with the.[00:11:57] Isaac Robinson: Image features and add that to the memory bank. [00:12:00] It's, well, I'll say more in a minute. The just like SAM, the SAM2 actually uses a data engine to create its data set in that people are, they assembled a huge amount of reference data, used people to label some of it and train the model used the model to label more of it and asked people to refine the predictions of the model.[00:12:20] Isaac Robinson: And then ultimately the data set is just created from the engine Final output of the model on the reference data. It's very interesting. This paradigm is so interesting to me because it unifies a model in a dataset in a way that is very unique. It seems unlikely that another model could come in and have such a tight.[00:12:37] Isaac Robinson: So brief overview of how the memory bank works, the paper did not have a great visual, so I'm just, I'm going to fill in a bit more. So we take the last couple of frames from our video. And we take the last couple of frames from our video attend that, along with the set of prompts that we provided, they could come from the future, [00:13:00] they could come from anywhere in the video, as well as reference object pointers, saying, by the way, here's what we've found so far attending to the last few frames has the interesting benefit of allowing it to model complex object motion without actually[00:13:18] Isaac Robinson: By limiting the amount of frames that you attend to, you manage to keep the model running in real time. This is such an interesting topic for me because one would assume that attending to all of the frames is super essential, or having some type of summarization of all the frames is super essential for high performance.[00:13:35] Isaac Robinson: But we see in their later ablation that that actually is not the case. So here, just to make sure that there is some benchmarking happening, we just compared to some of the stuff that's came out prior, and indeed the SAM2 strategy does improve on the state of the art. This ablation deep in their dependencies was super interesting to me.[00:13:59] Isaac Robinson: [00:14:00] We see in section C, the number of memories. One would assume that increasing the count of memories would meaningfully increase performance. And we see that it has some impact, but not the type that you'd expect. And that it meaningfully decreases speed, which justifies, in my mind, just having this FIFO queue of memories.[00:14:20] Isaac Robinson: Although in the future, I'm super interested to see A more dedicated summarization of all of the last video, not just a stacking of the last frames. So that another extension of beautiful per frame work into the video domain.[00:14:42] Realtime detection: DETRs > YOLO[00:14:42] Isaac Robinson: The next trend I'm interested in talking about is this interesting at RoboFlow, we're super interested in training real time object detectors.[00:14:50] Isaac Robinson: Those are bread and butter. And so we're doing a lot to keep track of what is actually happening in that space. We are finally starting to see something change. So, [00:15:00] for years, YOLOs have been the dominant way of doing real time object detection, and we can see here that they've essentially stagnated.[00:15:08] Isaac Robinson: The performance between 10 and 11 is not meaningfully different, at least, you know, in this type of high level chart. And even from the last couple series, there's not. A major change so YOLOs have hit a plateau, debtors have not. So we can look here and see the YOLO series has this plateau. And then these RT debtor, LW debtor, and Define have meaningfully changed that plateau so that in fact, the best Define models are plus 4.[00:15:43] Isaac Robinson: 6 AP on Cocoa at the same latency. So three major steps to accomplish this. The first RT deditor, which is technically a 2023 paper preprint, but published officially in 24, so I'm going to include that. I hope that's okay. [00:16:00] That is showed that RT deditor showed that we could actually match or out speed YOLOs.[00:16:04] Isaac Robinson: And then LWdebtor showed that pre training is hugely effective on debtors and much less so on YOLOs. And then DeFine added the types of bells and whistles that we expect from these types, this, this arena. So the major improvements that RTdebtor shows was Taking the multi scale features that debtors typically pass into their encoder and decoupling them into a much more efficient transformer encoder.[00:16:30] Isaac Robinson: The transformer is of course, quadratic complexity. So decreasing the amount of stuff that you pass in at once is super helpful for increasing your runtime or increasing your throughput. So that change basically brought us up to yellow speed and then they do a hardcore analysis on. Benchmarking YOLOs, including the NMS step.[00:16:54] Isaac Robinson: Once you once you include the NMS in the latency calculation, you see that in fact, these debtors [00:17:00] are outperforming, at least this time, the the, the YOLOs that existed. Then LW debtor goes in and suggests that in fact, the frame, the huge boost here is from pre training. So, this is the define line, and this is the define line without pre training.[00:17:19] Isaac Robinson: It's within range, it's still an improvement over the YOLOs, but Really huge boost comes from the benefit of pre training. When YOLOx came out in 2021, they showed that they got much better results by having a much, much longer training time, but they found that when they did that, they actually did not benefit from pre training.[00:17:40] Isaac Robinson: So, you see in this graph from LWdebtor, in fact, YOLOs do have a real benefit from pre training, but it goes away as we increase the training time. Then, the debtors converge much faster. LWdebtor trains for only 50 epochs, RTdebtor is 60 epochs. So, one could assume that, in fact, [00:18:00] the entire extra gain from pre training is that you're not destroying your original weights.[00:18:06] Isaac Robinson: By relying on this long training cycle. And then LWdebtor also shows superior performance to our favorite data set, Roboflow 100 which means that they do better on the real world, not just on Cocoa. Then Define throws all the bells and whistles at it. Yellow models tend to have a lot of very specific complicated loss functions.[00:18:26] Isaac Robinson: This Define brings that into the debtor world and shows consistent improvement on a variety of debtor based frameworks. So bring these all together and we see that suddenly we have almost 60 AP on Cocoa while running in like 10 milliseconds. Huge, huge stuff. So we're spending a lot of time trying to build models that work better with less data and debtors are clearly becoming a promising step in that direction.[00:18:56] Isaac Robinson: The, what we're interested in seeing [00:19:00] from the debtors in this, this trend to next is. Codetter and the models that are currently sitting on the top of the leaderboard for large scale inference scale really well as you switch out the backbone. We're very interested in seeing and having people publish a paper, potentially us, on what happens if you take these real time ones and then throw a Swingy at it.[00:19:23] Isaac Robinson: Like, do we have a Pareto curve that extends from the real time domain all the way up to the super, super slow but high performance domain? We also want to see people benchmarking in RF100 more, because that type of data is what's relevant for most users. And we want to see more pre training, because pre training works now.[00:19:43] Isaac Robinson: It's super cool.[00:19:48] Peter's Picks[00:19:48] Peter Robicheaux: Alright, so, yeah, so in that theme one of the big things that we're focusing on is how do we get more out of our pre trained models. And one of the lenses to look at this is through sort of [00:20:00] this, this new requirement for like, how Fine grained visual details and your representations that are extracted from your foundation model.[00:20:08] Peter Robicheaux: So it's sort of a hook for this Oh, yeah, this is just a list of all the the papers that I'm going to mention I just want to make sure I set an actual paper so you can find it later[00:20:18] MMVP (Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs)[00:20:18] Peter Robicheaux: Yeah, so sort of the big hook here is that I make the claim that LLMs can't see if you go to if you go to Claude or ChatGPT you ask it to see this Watch and tell me what time it is, it fails, right?[00:20:34] Peter Robicheaux: And so you could say, like, maybe, maybe the Like, this is, like, a very classic test of an LLM, but you could say, Okay, maybe this, this image is, like, too zoomed out, And it just, like, it'll do better if we increase the resolution, And it has easier time finding these fine grained features, Like, where the watch hands are pointing.[00:20:53] Peter Robicheaux: Nodice. And you can say, okay, well, maybe the model just doesn't know how to tell time from knowing the position of the hands. But if you actually prompt [00:21:00] it textually, it's very easy for it to tell the time. So this to me is proof that these LLMs literally cannot see the position of the watch hands and it can't see those details.[00:21:08] Peter Robicheaux: So the question is sort of why? And for you anthropic heads out there, cloud fails too. So the, the, my first pick for best paper of 2024 Envision is this MMVP paper, which tries to investigate the Why do LLMs not have the ability to see fine grained details? And so, for instance, it comes up with a lot of images like this, where you ask it a question that seems very visually apparent to us, like, which way is the school bus facing?[00:21:32] Peter Robicheaux: And it gets it wrong, and then, of course, it makes up details to support its wrong claim. And so, the process by which it finds these images is sort of contained in its hypothesis for why it can't. See these details. So it hypothesizes that models that have been initialized with, with Clip as their vision encoder, they don't have fine grained details and the, the features extracted using Clip because Clip sort of doesn't need to find these fine grained [00:22:00] details to do its job correctly, which is just to match captions and images, right?[00:22:04] Peter Robicheaux: And sort of at a high level, even if ChatGPT wasn't initialized with Clip and wasn't trained contrastively at all. The vision encoder wasn't trained contrastively at all. Still, in order to do its job of capturing the image it could do a pretty good job without actually finding the exact position of all the objects and visual features in the image, right?[00:22:21] Peter Robicheaux: So This paper finds a set of difficult images for these types of models. And the way it does it is it looks for embeddings that are similar in clip space, but far in DynaV2 space. So DynaV2 is a foundation model that was trained self supervised purely on image data. And it kind of uses like some complex student teacher framework, but essentially, and like, it patches out like certain areas of the image or like crops with certain areas of the image and tries to make sure that those have consistent representations, which is a way for it to learn very fine grained visual features.[00:22:54] Peter Robicheaux: And so if you take things that are very close in clip space and very far in DynaV2 space, you get a set of images [00:23:00] that Basically, pairs of images that are hard for a chat GPT and other big language models to distinguish. So, if you then ask it questions about this image, well, as you can see from this chart, it's going to answer the same way for both images, right?[00:23:14] Peter Robicheaux: Because to, to, from the perspective of the vision encoder, they're the same image. And so if you ask a question like, how many eyes does this animal have? It answers the same for both. And like all these other models, including Lava do the same thing, right? And so this is the benchmark that they create, which is like finding clip, like clip line pairs, which is pairs of images that are similar in clip space and creating a data set of multiple choice questions based off of those.[00:23:39] Peter Robicheaux: And so how do these models do? Well, really bad. Lava, I think, So, so, chat2BT and Jim and I do a little bit better than random guessing, but, like, half of the performance of humans who find these problems to be very easy. Lava is, interestingly, extremely negatively correlated with this dataset. It does much, much, much, much worse [00:24:00] than random guessing, which means that this process has done a very good job of identifying hard images for, for Lava, specifically.[00:24:07] Peter Robicheaux: And that's because Lava is basically not trained for very long and is initialized from Clip, and so You would expect it to do poorly on this dataset. So, one of the proposed solutions that this paper attempts is by basically saying, Okay, well if clip features aren't enough, What if we train the visual encoder of the language model also on dyno features?[00:24:27] Peter Robicheaux: And so it, it proposes two different ways of doing this. One, additively which is basically interpolating between the two features, and then one is interleaving, which is just kind of like training one on the combination of both features. So there's this really interesting trend when you do the additive mixture of features.[00:24:45] Peter Robicheaux: So zero is all clip features and one is all DynaV2 features. So. It, as you, so I think it's helpful to look at the right most chart first, which is as you increase the number of DynaV2 features, your model does worse and worse and [00:25:00] worse on the actual language modeling task. And that's because DynaV2 features were trained completely from a self supervised manner and completely in image space.[00:25:08] Peter Robicheaux: It knows nothing about text. These features aren't really compatible with these text models. And so you can train an adapter all you want, but it seems that it's in such an alien language that it's like a very hard optimization for this. These models to solve. And so that kind of supports what's happening on the left, which is that, yeah, it gets better at answering these questions if as you include more dyna V two features up to a point, but then you, when you oversaturate, it completely loses its ability to like.[00:25:36] Peter Robicheaux: Answer language and do language tasks. So you can also see with the interleaving, like they essentially double the number of tokens that are going into these models and just train on both, and it still doesn't really solve the MMVP task. It gets Lava 1. 5 above random guessing by a little bit, but it's still not close to ChachiPT or, you know, Any like human performance, obviously.[00:25:59] Peter Robicheaux: [00:26:00] So clearly this proposed solution of just using DynaV2 features directly, isn't going to work. And basically what that means is that as a as a vision foundation model, DynaV2 is going to be insufficient for language tasks, right?[00:26:14] Florence 2 (Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks)[00:26:14] Peter Robicheaux: So my next pick for best paper of 2024 would be Florence 2, which tries to solve this problem by incorporating not only This dimension of spatial hierarchy, which is to say pixel level understanding, but also in making sure to include what they call semantic granularity, which ends up, the goal is basically to have features that are sufficient for finding objects in the image, so they're, they're, they have enough pixel information, but also can be talked about and can be reasoned about.[00:26:44] Peter Robicheaux: And that's on the semantic granularity axis. So here's an example of basically three different paradigms of labeling that they do. So they, they create a big dataset. One is text, which is just captioning. And you would expect a model that's trained [00:27:00] only on captioning to have similar performance like chat2BT and like not have spatial hierarchy, not have features that are meaningful at the pixel level.[00:27:08] Peter Robicheaux: And so they add another type, which is region text pairs, which is essentially either classifying a region or You're doing object detection or doing instance segmentation on that region or captioning that region. And then they have text phrased region annotations, which is essentially a triple. And basically, not only do you have a region that you've described, you also find it's like, It's placed in a descriptive paragraph about the image, which is basically trying to introduce even more like semantic understanding of these regions.[00:27:39] Peter Robicheaux: And so like, for instance, if you're saying a woman riding on the road, right, you have to know what a woman is and what the road is and that she's on top of it. And that's, that's basically composing a bunch of objects in this visual space, but also thinking about it semantically, right? And so the way that they do this is they take basically they just dump Features from a vision encoder [00:28:00] straight into a encoder decoder transformer.[00:28:03] Peter Robicheaux: And then they train a bunch of different tasks like object detection and so on as a language task. And I think that's one of the big things that we saw in 2024 is these, these vision language models operating in, on pixel space linguistically. So they introduced a bunch of new tokens to point to locations and[00:28:22] Peter Robicheaux: So how does it work? How does it actually do? We can see if you look at the graph on the right, which is using the, the Dino, the the Dino framework your, your pre trained Florence 2 models transfer very, very well. They get 60%, 60 percent map on Cocoa, which is like approaching state of the art and they train[00:28:42] Vik Korrapati: with, and they[00:28:43] Peter Robicheaux: train with a much more more efficiently.[00:28:47] Peter Robicheaux: So they, they converge a lot faster, which both of these things are pointing to the fact that they're actually leveraging their pre trained weights effectively. So where is it falling short? So these models, I forgot to mention, Florence is a 0. 2 [00:29:00] billion and a 0. 7 billion parameter count. So they're very, very small in terms of being a language model.[00:29:05] Peter Robicheaux: And I think that. This framework, you can see saturation. So, what this graph is showing is that if you train a Florence 2 model purely on the image level and region level annotations and not including the pixel level annotations, like this, segmentation, it actually performs better as an object detector.[00:29:25] Peter Robicheaux: And what that means is that it's not able to actually learn all the visual tasks that it's trying to learn because it doesn't have enough capacity.[00:29:32] PalíGemma / PaliGemma 2[00:29:32] Peter Robicheaux: So I'd like to see this paper explore larger model sizes, which brings us to our next big paper of 2024 or two papers. So PolyGemma came out earlier this year.[00:29:42] Peter Robicheaux: PolyGemma 2 was released, I think like a week or two ago. Oh, I forgot to mention, you can actually train You can, like, label text datasets on RoboFlow and you can train a Florence 2 model and you can actually train a PolyGemma 2 model on RoboFlow, which we got into the platform within, like, 14 hours of release, which I was really excited about.[00:29:59] Peter Robicheaux: So, anyway, so [00:30:00] PolyGemma 2, so PolyGemma is essentially doing the same thing, but instead of doing an encoder decoder, it just dumps everything into a decoder only transformer model. But it also introduced the concept of location tokens to point to objects in pixel space. PolyGemma 2, so PolyGemma uses Gemma as the language encoder, and it uses Gemma2B.[00:30:17] Peter Robicheaux: PolyGemma 2 introduces using multiple different sizes of language encoders. So, the way that they sort of get around having to do encoder decoder is they use the concept of prefix loss. Which basically means that when it's generating, tokens autoregressively, it's all those tokens in the prefix, which is like the image that it's looking at and like a description of the task that it's trying to do.[00:30:41] Peter Robicheaux: They're attending to each other fully, full attention. Which means that, you know, it can sort of. Find high level it's easier for the, the prefix to color, to color the output of the suffix and also to just find like features easily. So this is sort of [00:31:00] an example of like one of the tasks that was trained on, which is like, you describe the task in English and then you give it all these, like, You're asking for it to segment these two classes of objects, and then it finds, like, their locations using these tokens, and it finds their masks using some encoding of the masks into tokens.[00:31:24] Peter Robicheaux: And, yeah, so, one of my critiques, I guess, of PolyGemma 1, at least, is that You find that performance saturates as a pre trained model after only 300 million examples seen. So, what this graph is representing is each blue dot is a performance on some downstream task. And you can see that after seeing 300 million examples, It sort of does equally well on all of the downtrend tasks that they tried it on, which was a lot as 1 billion examples, which to me also kind of suggests a lack of capacity for this model.[00:31:58] Peter Robicheaux: PolyGemma2, [00:32:00] you can see the results on object detection. So these were transferred to to Coco. And you can see that this sort of also points to an increase in capacity being helpful to the model. You can see as. Both the resolution increases, and the parameter count of the language model increases, performance increases.[00:32:16] Peter Robicheaux: So resolution makes sense, obviously, it helps to find small images, or small objects in the image. But it also makes sense for another reason, which is that it kind of gives the model a thinking register, and it gives it more tokens to, like, process when making its predictions. But yeah, you could, you could say, oh, 43.[00:32:30] Peter Robicheaux: 6, that's not that great, like Florence 2 got 60. But this is not Training a dino or a debtor on top of this language or this image encoder. It's doing the raw language modeling task on Cocoa. So it doesn't have any of the bells and whistles. It doesn't have any of the fancy losses. It doesn't even have bipartite graph matching or anything like that.[00:32:52] Peter Robicheaux: Okay, the big result and one of the reasons that I was really excited about this paper is that they blow everything else away [00:33:00] on MMVP. I mean, 47. 3, sure, that's nowhere near human accuracy, which, again, is 94%, but for a, you know, a 2 billion language, 2 billion parameter language model to be chat2BT, that's quite the achievement.[00:33:12] Peter Robicheaux: And that sort of brings us to our final pick for paper of the year, which is AIMV2. So, AIMV2 sort of says, okay, Maybe this language model, like, maybe coming up with all these specific annotations to find features and with high fidelity and pixel space isn't actually necessary. And we can come up with an even simpler, more beautiful idea for combining you know, image tokens and pixel tokens in a way that's interfaceable for language tasks.[00:33:44] Peter Robicheaux: And this is nice because it can scale, you can come up with lots more data if you don't have to come up with all these annotations, right? So the way that it works. is it does something very, very similar to PolyGemo, where you have a vision encoder that dumps image tokens into a decoder only transformer.[00:33:59] Peter Robicheaux: But [00:34:00] the interesting thing is that it also autoregressively tries to learn the mean squared error of the image tokens. So instead of having to come up with fancy object detection or semantic, or segment, or segmentation labels, you can just try to reconstruct the image and have it learn fine grained features that way.[00:34:16] Peter Robicheaux: And it does this in kind of, I think, a beautiful way that's kind of compatible with the PolyGemma line of thinking, which is randomly sampling a prefix line of thinking Prefix length and using only this number of image tokens as the prefix. And so doing a similar thing with the causal. So the causal with prefix is the, the attention mask on the right.[00:34:35] Peter Robicheaux: So it's doing full block attention with some randomly sampled number of image tokens to then reconstruct the rest of the image and the downstream caption for that image. And so, This is the dataset that they train on. It's image or internet scale data, very high quality data created by the data filtering networks paper, essentially which is maybe The best clip data that exists.[00:34:59] Peter Robicheaux: [00:35:00] And we can see that this is finally a model that doesn't saturate. It's even at the highest parameter count, it's, it appears to be, oh, at the highest parameter account, it appears to be improving in performance with more and more samples seen. And so you can sort of think that. You know, if we just keep bumping the parameter count and increasing the example scene, which is the, the, the line of thinking for language models, then it'll keep getting better.[00:35:27] Peter Robicheaux: So how does it actually do at finding, oh, it also improves with resolution, which you would expect for a model that This is the ImageNet classification accuracy, but yeah, it does better if you increase the resolution, which means that it's actually leveraging and finding fine grained visual features.[00:35:44] Peter Robicheaux: And so how does that actually do compared to CLIP on Cocoa? Well, you can see that if you slap a transformer detection head on it, Entry now in Cocoa, it's just 60. 2, which is also within spitting distance of Soda, which means that it does a very good job of [00:36:00] finding visual features, but you could say, okay, well, wait a second.[00:36:03] Peter Robicheaux: Clip got to 59. 1, so. Like, how does this prove your claim at all? Because doesn't that mean like clip, which is known to be clip blind and do badly on MMVP, it's able to achieve a very high performance on fine, on this fine grained visual features task of object detection, well, they train on like, Tons of data.[00:36:24] Peter Robicheaux: They train on like objects, 365, Cocoa, Flickr and everything else. And so I think that this benchmark doesn't do a great job of selling how good of a pre trained model MV2 is. And we would like to see the performance on fewer data as examples and not trained to convergence on object detection. So seeing it in the real world on like a dataset, like RoboFlow 100, I think would be quite interesting.[00:36:48] Peter Robicheaux: And our, our, I guess our final, final pick for paper of 2024 would be Moondream. So introducing Vic to talk about that.[00:36:54] swyx: But overall, that was exactly what I was looking for. Like best of 2024, an amazing job. Yeah, you can, [00:37:00] if there's any other questions while Vic gets set up, like vision stuff,[00:37:07] swyx: yeah,[00:37:11] swyx: Vic, go ahead. Hi,[00:37:13] Vik Korrapati / Moondream[00:37:13] question: well, while we're getting set up, hi, over here, thanks for the really awesome talk. One of the things that's been weird and surprising is that the foundation model companies Even these MLMs, they're just like worse than RT Tether at detection still. Like, if you wanted to pay a bunch of money to auto label your detection dataset, If you gave it to OpenAI or Cloud, that would be like a big waste.[00:37:37] question: So I'm curious, just like, even Pali Gemma 2, like is worse. So, so I'm curious to hear your thoughts on like, how come, Nobody's cracked the code on like a generalist that really you know, beats a specialist model in computer vision like they have in in LLM land.[00:38:00][00:38:01] Isaac Robinson: Okay. It's a very, very interesting question. I think it depends on the specific domain. For image classification, it's basically there. In the, in AIMv2 showed, a simple attentional probe on the pre trained features gets like 90%, which is as well as anyone does. The, the, the, the bigger question, like, why isn't it transferring to object detection, especially like real time object detection.[00:38:25] Isaac Robinson: I think, in my mind, there are two answers. One is, object detection is really, really, really the architectures are super domain specific. You know, we see these, all these super, super complicated things, and it's not super easy to, to, to build something that just transfers naturally like that, whereas image classification, you know, clip pre training transfers super, super quickly.[00:38:48] Isaac Robinson: And the other thing is, until recently, the real time object detectors didn't even really benefit from pre training. Like, you see the YOLOs that are like, essentially saturated, showing very little [00:39:00] difference with pre training improvements, with using pre trained model at all. It's not surprising, necessarily, that People aren't looking at the effects of better and better pre training on real time detection.[00:39:12] Isaac Robinson: Maybe that'll change in the next year. Does that answer your question?[00:39:17] Peter Robicheaux: Can you guys hear me? Yeah, one thing I want to add is just like, or just to summarize, basically, is that like, Until 2024, you know, we haven't really seen a combination of transformer based object detectors and fancy losses, and PolyGemma suffers from the same problem, which is basically to say that these ResNet, or like the convolutional models, they have all these, like, extreme optimizations for doing object detection, but essentially, I think it's kind of been shown now that convolution models like just don't benefit from pre training and just don't like have the level of intelligence of transformer models.[00:39:56] swyx: Awesome. Hi,[00:39:59] Vik Korrapati: can [00:40:00] you hear me?[00:40:01] swyx: Cool. I hear you. See you. Are you sharing your screen?[00:40:04] Vik Korrapati: Hi. Might have forgotten to do that. Let me do[00:40:07] swyx: that. Sorry, should have done[00:40:08] Vik Korrapati: that.[00:40:17] swyx: Here's your screen. Oh, classic. You might have to quit zoom and restart. What? It's fine. We have a capture of your screen.[00:40:34] swyx: So let's get to it.[00:40:35] Vik Korrapati: Okay, easy enough.[00:40:49] Vik Korrapati: All right. Hi, everyone. My name is Vic. I've been working on Moondream for almost a year now. Like Shawn mentioned, I just went and looked and it turns out the first version I released December [00:41:00] 29, 2023. It's been a fascinating journey. So Moonbeam started off as a tiny vision language model. Since then, we've expanded scope a little bit to also try and build some tooling, client libraries, et cetera, to help people really deploy it.[00:41:13] Vik Korrapati: Unlike traditional large models that are focused at assistant type use cases, we're laser focused on building capabilities that developers can, sorry, it's yeah, we're basically focused on building capabilities that developers can use to build vision applications that can run anywhere. So, in a lot of cases for vision more so than for text, you really care about being able to run on the edge, run in real time, etc.[00:41:40] Vik Korrapati: So That's really important. We have we have different output modalities that we support. There's query where you can ask general English questions about an image and get back human like answers. There's captioning, which a lot of our users use for generating synthetic datasets to then train diffusion models and whatnot.[00:41:57] Vik Korrapati: We've done a lot of work to minimize those sessions there. [00:42:00] So that's. Use lot. We have open vocabulary object detection built in similar to a couple of more recent models like Palagem, et cetera, where rather than having to train a dedicated model, you can just say show me soccer balls in this image or show me if there are any deer in this image, it'll detect it.[00:42:14] Vik Korrapati: More recently, earlier this month, we released pointing capability where if all you're interested in is the center of an object you can just ask it to point out where that is. This is very useful when you're doing, you know, I automation type stuff. Let's see, LA we, we have two models out right now.[00:42:33] Vik Korrapati: There's a general purpose to be para model, which runs fair. Like it's, it's it's fine if you're running on server. It's good for our local Amma desktop friends and it can run on flagship, flagship mobile phones, but it never. so much for joining us today, and we'll see you in the [00:43:00] next one. Less memory even with our not yet fully optimized inference client.[00:43:06] Vik Korrapati: So the way we built our 0. 5b model was to start with the 2 billion parameter model and prune it while doing continual training to retain performance. We, our objective during the pruning was to preserve accuracy across a broad set of benchmarks. So the way we went about it was to estimate the importance of different components of the model, like attention heads, channels MLP rows and whatnot using basically a technique based on the gradient.[00:43:37] Vik Korrapati: I'm not sure how much people want to know details. We'll be writing a paper about this, but feel free to grab me if you have more questions. Then we iteratively prune a small chunk that will minimize loss and performance retrain the model to recover performance and bring it back. The 0. 5b we released is more of a proof of concept that this is possible.[00:43:54] Vik Korrapati: I think the thing that's really exciting about this is it makes it possible for for developers to build using the 2B param [00:44:00] model and just explore, build their application, and then once they're ready to deploy figure out what exactly they need out of the model and prune those capabilities into a smaller form factor that makes sense for their deployment target.[00:44:12] Vik Korrapati: So yeah, very excited about that. Let me talk to you folks a little bit about another problem I've been working on recently, which is similar to the clocks example we've been talking about. We had a customer reach out who was talking about, like, who had a bunch of gauges out in the field. This is very common in manufacturing and oil and gas, where you have a bunch of analog devices that you need to monitor.[00:44:34] Vik Korrapati: It's expensive to. And I was like, okay, let's have humans look at that and monitor stuff and make sure that the system gets shut down when the temperature goes over 80 or something. So I was like, yeah, this seems easy enough. Happy to, happy to help you distill that. Let's, let's get it going. Turns out our model couldn't do it at all.[00:44:51] Vik Korrapati: I went and looked at other open source models to see if I could just generate a bunch of data and learn from that. Did not work either. So I was like, let's look at what the folks with [00:45:00] hundreds of billions of dollars in market cap have to offer. And yeah, that doesn't work either. My hypothesis is that like the, the way these models are trained are using a large amount of image text data scraped from the internet.[00:45:15] Vik Korrapati: And that can be biased. In the case of gauges, most gauge images aren't gauges in the wild, they're product images. Detail images like these, where it's always set to zero. It's paired with an alt text that says something like GIVTO, pressure sensor, PSI, zero to 30 or something. And so the models are fairly good at picking up those details.[00:45:35] Vik Korrapati: It'll tell you that it's a pressure gauge. It'll tell you what the brand is, but it doesn't really learn to pay attention to the needle over there. And so, yeah, that's a gap we need to address. So naturally my mind goes to like, let's use synthetic data to, Solve this problem. That works, but it's problematic because it turned out we needed millions of synthetic gauge images to get to reasonable performance.[00:45:57] Vik Korrapati: And thinking about it, reading a gauge is like [00:46:00] not a one, like it's not a zero short process in our minds, right? Like if you had to tell me the reading in Celsius for this, Real world gauge. There's two dials on there. So first you have to figure out which one you have to be paying attention to, like the inner one or the outer one.[00:46:14] Vik Korrapati: You look at the tip of the needle, you look at what labels it's between, and you count how many and do some math to figure out what that probably is. So what happens if we just add that as a Chain of thought to give the model better understanding of the different sub, to allow the model to better learn the subtasks it needs to perform to accomplish this goal.[00:46:37] Vik Korrapati: So you can see in this example, this was actually generated by the latest version of our model. It's like, okay, Celsius is the inner scale. It's between 50 and 60. There's 10 ticks. So the second tick, it's a little debatable here, like there's a weird shadow situation going on, the dial is off, so I don't know what the ground truth is, but it works okay.[00:46:57] Vik Korrapati: There's points on there that are, the points [00:47:00] over there are actually grounded. I don't know if this is easy to see, but when I click on those, there's a little red dot that moves around on the image. The model actually has to predict where this points are, I was already trying to do this with bounding boxes, but then Malmo came out with pointing capabilities.[00:47:15] Vik Korrapati: And it's like pointing is a much better paradigm to to represent this. We see pretty good results. This one's actually for clock reading. I couldn't find our chart for gauge reading at the last minute. So the light. Blue chart is with our rounded chain of thought. This measures, we have, we built a clock reading benchmark about 500 images.[00:47:37] Vik Korrapati: This measures accuracy on that. You can see it's a lot more sample efficient when you're using the chain of thought to model. Another big benefit from this approach is like, you can kind of understand how the model is. it and how it's failing. So in this example, the actual correct reading is 54 Celsius, the model output [00:48:00] 56, not too bad but you can actually go and see where it messed up. Like it got a lot of these right, except instead of saying it was on the 7th tick, it actually predicted that it was the 8th tick and that's why it went with 56.[00:48:14] Vik Korrapati: So now that you know that this. Failing in this way, you can adjust how you're doing the chain of thought to maybe say like, actually count out each tick from 40, instead of just trying to say it's the eighth tick. Or you might say like, okay, I see that there's that middle thing, I'll count from there instead of all the way from 40.[00:48:31] Vik Korrapati: So helps a ton. The other thing I'm excited about is a few short prompting or test time training with this. Like if a customer has a specific gauge that like we're seeing minor errors on, they can give us a couple of examples where like, if it's miss detecting the. Needle, they can go in and correct that in the chain of thought.[00:48:49] Vik Korrapati: And hopefully that works the next time. Now, exciting approach, we only apply it to clocks and gauges. The real question is, is it going to generalize? Probably, like, there's some science [00:49:00] from text models that when you train on a broad number of tasks, it does generalize. And I'm seeing some science with our model as well.[00:49:05] Vik Korrapati: So, in addition to the image based chain of thought stuff, I also added some spelling based chain of thought to help it understand better understand OCR, I guess. I don't understand why everyone doesn't do this, by the way. Like, it's trivial benchmark question. It's Very, very easy to nail. But I also wanted to support it for stuff like license plate, partial matching, like, hey, does any license plate in this image start with WHA or whatever?[00:49:29] Vik Korrapati: So yeah, that sort of worked. All right, that, that ends my story about the gauges. If you think about what's going on over here it's interesting that like LLMs are showing enormous. Progress in reasoning, especially with the latest set of models that we've seen, but we're not really seeing, I have a feeling that VLMs are lagging behind, as we can see with these tasks that should be very simple for a human to do [00:50:00] that are very easy to find VLMs failing at.[00:50:04] Vik Korrapati: My hypothesis on why this is the case is because On the internet, there's a ton of data that talks about how to reason. There's books about how to solve problems. There's books critiquing the books about how to solve problems. But humans are just so good at perception that we never really talk about it.[00:50:20] Vik Korrapati: Like, maybe in art books where it's like, hey, to show that that mountain is further away, you need to desaturate it a bit or whatever. But the actual data on how to, like, look at images is, isn't really present. Also, the Data we have is kind of sketched. The best source of data we have is like image all text pairs on the internet and that's pretty low quality.[00:50:40] Vik Korrapati: So yeah, I, I think our solution here is really just we need to teach them how to operate on individual tasks and figure out how to scale that out. All right. Yep. So conclusion. At Moondream we're trying to build amazing PLMs that run everywhere. Very hard problem. Much work ahead, but we're making a ton of progress and I'm really excited [00:51:00] about If anyone wants to chat about more technical details about how we're doing this or interest in collaborating, please, please hit me up.[00:51:08] Isaac Robinson: Yeah,[00:51:09] swyx: like, I always, when people say, when people say multi modality, like, you know, I always think about vision as the first among equals in all the modalities. So, I really appreciate having the experts in the room. Get full access to Latent.Space at www.latent.space/subscribe